Data is essential to any application and is used in the design of an efficient pipeline for delivery and management of information throughout an organization. Generally, define a data pipeline when you need to process data during its life cycle. The pipeline can start where data is generated and stored in any format. The pipeline can end with data being analyzed, used as business information, stored in a data warehouse, or processed in a machine learning model.
Data is extracted, processed, and transformed in multiple steps depending on the downstream system requirements. Any processing and transformational steps are defined in a data pipeline. Depending on the requirements, the pipelines can be as simple as one step or as complex as multiple transformational and processing steps.
How to choose a design pattern?
When selecting a data pipeline design pattern, there are different design elements that must be considered. These design elements include the following:
Select data source formats.
Select which stacks to use.
Select data transformation tools.
Choose between Extract Transform Load (ETL), Extract Load Transform (ELT), or Extract Transform Load Transform (ETLT).
Determine how changed data is managed.
Determine how changes are captured.
Data sources can have a variety of data types. Knowing the technology stack and tool sets that we use is also a key element of the pipeline build process. Enterprise environments come with the challenges that require using multiple and complicated techniques to capture the changed data and to merge with the target data.
I mentioned that most of the time the downstream systems define the requirements for a pipeline and how these processes can be interconnected. The processing steps and sequences of the data flow are the major factors affecting pipeline design. Each step might include one or more data inputs, and the outputs might include one or more stages. The processing between input and output might include simple or complex transformational steps. I highly recommend keeping the design simple and modular to ensure that you clearly understand the steps and transformation taking place. Also, keeping your pipeline design simple and modular makes it easier for a team of developers to implement development and deployment cycles. It also makes debugging and troubleshooting the pipeline easier when issues occur.
The major components of a pipeline Include:
Source data
Processing
Target storage
Source data can be the transaction application, the files collected from users, and data extracted from an external API. Processing of the source data can be as simple as one step copying or as complex as multiple transformations and joining with other data sources. The target data warehousing system might require the processed data that is the result of the transformation (such as a data type change or data extraction), and lookup and updates from other systems. A simple data pipeline might be created by copying data from source to target without any changes. A complex data pipeline might include multiple transformation steps, lookup, updates, KPI calculations, and data storage into several targets for different reasons.
Source data can be presented in multiple formats. Each will need a proper architecture and tools to process and transform. There can be multiple data types required in a typical data pipeline that might be in any of the following formats:
Batch Data: A file with tabular information (CSV, JSON, AVRO, PARQUET and …) where the data is collected according to a defined threshold or frequency with conventional batch processing or micro-batch processing. Modern applications tend to generate continuous data. For this reason, micro-batch processing is a preferred design to collect the data from sources.
Transactions Data: Application data such as RDBMS (relational data), NoSQL, Big Data.
Stream Data: Real-time applications that use Kafka, Google Pub/Sub, Azure Stream Analytics, or Amazon Stream Data. Streaming data applications can communicate in real time and exchange messages to meet the requirements. In Enterprise architecture design, the real time and stream processing is a very important component of design.
Flat file – PDFs or other non-tabular formats that contain data for processing. For example, medical or legal documents that can be used to extract information.
Target data is defined based on the requirements and the downstream processing needs. It’s common to build target data to satisfy the need for multiple systems. In the Data Lake concept, the data is processed and stored in a way that Analytics systems can get insight while the AI/ML process can use the data to build predictive models.
Architectures and examples
Multiple architecture designs are covered that show how the source data is extracted and transformed to the target. The goal is to clever the general approaches, and it’s important to remember that each use case can be very different and unique to the customer and need special consideration.
The data pipeline architecture can be broken down into Logical and Platform levels. The logical design describes how the data is processed and transformed from the source into the target. The platform design focuses on implementation and tooling that each environment needs, and this depends on the provider and tooling available in the platform. Google Cloud, Azure, or Amazon have different toolsets for the transformation while the goal of the logical design remains the same (data transform) no matter which provider is used.
Here is a logical design of a Data Warehousing pipeline:
Here is the logical design for a Data Lake pipeline:
Depending on the downstream requirements, the generic architecture designs can be implemented with more details to address several use cases.
The Platform implementations can vary depending on the toolset selection and development skills. What follows are a few examples of Google Cloud implementations for the common data pipeline architectures.
A Batch ETL Pipeline in Google Cloud – The Source might be files that need to be ingested into the analytics Business Intelligence (BI) engine. The Cloud Storage is the data transfer medium inside Google Cloud and then Dataflow is used to load the data into the target BigQuery storage. The simplicity of this approach makes this pattern reusable and effective in simple transformational processes. On the other hand, if we need to build a complex pipeline, then this approach isn’t going to be efficient and effective.
A Data Analytics Pipeline is a complex process that has both batch and stream data ingestion pipelines. The processing is complex and multiple tools and services are used to transform the data into warehousing and an AL/ML access point for further processing. Enterprise solutions for data analytics are complex and require multiple steps to process the data. The complexity of the design can add to the project timeline and cost but in order to achieve the business objectives, carefully review and build each component.
Machine learning data pipeline in Google Cloud is a comprehensive design that allows customers to utilize all Google Cloud native services to build and process a machine learning process. For more information, see Creating a machine learning pipeline.
There are multiple approaches to designing and implementing data pipelines. The key is to choose the design that meets your requirements. There are new technologies emerging that are providing more robust and faster implementations for data pipelines. Google Big Lake is a new service that introduces a new approach on data ingestion. BigLake is a storage engine that unifies data warehouses by enabling BigQuery and open source frameworks such as Spark to access data with fine-grained access control. BigLake provides accelerated query performance across multi-cloud storage and open formats such as Apache Iceberg.
The other major factor in deciding the proper data pipeline architecture is the cost. Building a cost-effective solution is a major factor in deciding the design. Usually, streaming and real-time data processing pipelines are more expensive to build and run compared to using batch models. There are times that the budget runs the decision on which design to choose and how to build the platform. Knowing the details on each component and being able to do cost analysis of the solution ahead of time is important in choosing the right architecture design for your solution. Google Cloud provides a cost calculator that can be used in these cases.
Do you really need real-time analytics or will a near real-time system be sufficient? This can resolve the design decision for the streaming pipeline. Are you building cloud native solutions or migrating an existing one from on-premises? All of these questions are important in designing a proper architecture for our data pipeline.
Don’t ignore the data volume when designing a data pipeline. The scalability of the design and services used in the platform is another very important factor to consider when designing and implementing a solution. Big Data is growing more and building capacity for processing. Storing the data is a key element to data pipeline architecture. In reality, there are many variables that can help with proper platform design. The data volume and velocity or data flow rates can be very important factors.
If you are planning to build a data pipeline for a data science project, then you might consider all data sources that the ML Model requires for future engineering. The data cleansing process is mostly a big part of the data engineering team which must have adequate and sufficient transformational toolsets. Data science projects are dealing with large data sets, which will require planning for storage. Depending on how the ML Model is utilized, either real-time or batch processing must serve the users.
What Next?
Big Data and the growth of the data in general are posing new challenges for data architects and always challenging the requirements for data architecture. A constant increase of data variety, data formats, and data sources is a challenge as well. Businesses are realizing the value of the data and are automating more processes and demanding real-time access to the analytics and decision making information. This is becoming a challenge to take into consideration all variables for a scalable performance system. The data pipeline must be strong, flexible, and reliable. The data quality must be trusted by all users. Data privacy is one of the most important factors in any design consideration. I’ll cover these concepts in my next article.
I highly recommend following Google Cloud quickstart and tutorials as the next steps to learn more about the Google Cloud and experience hands-on practice.
Developing in SQL poses significant problems when compared to other languages and frameworks. It’s not easy to reuse statements across different scripts, there’s no way to write tests to ensure data consistency, and dependency management requires external software solutions. Developers will typically write thousands of lines of SQL to ensure data processing occurs in the correct order. Additionally, documentation and metadata are afterthoughts because they need to be managed in an external catalog.
Google Cloud offers Dataform and SQLX to solve these challenges.
Dataform is a service for data analysts to test, develop, and deploy complex SQL workflows for data transformation in BigQuery. Dataform lets you manage data transformation in the Extraction, Loading, and Transformation (ELT) process for data integration. After extracting raw data from source systems and loading into BigQuery, Dataform helps you transform it into a well-defined, tested, and documented suite of data tables.
SQLX is an open source extension of SQL and the primary tool used in Dataform. As it is an extension, every SQL file is also a valid SQLX file. SQLX brings additional features to SQL to make development faster, more reliable, and scalable. It includes functions including dependencies management, automated data quality testing, and data documentation
Teams should quickly transform their SQL into SQLX to gain the full suite of benefits that Dataform provides. This blog contains a high-level, introductory guide demonstrating this process.
The steps in this guide use the Dataform on Google Cloud console. You can follow along or implement these steps with your own SQL scripts!
Getting Started
Here is an example SQL script we will transform into SQLX. This script takes a source table containing reddit data. The script cleans, deduplicates, and inserts the data into a new table with a partition.
code_block[StructValue([(u’code’, u’CREATE OR REPLACE TABLE reddit_stream.comments_partitionedrnPARTITION BYrn comment_daternASrnrnWITH t1 as (rnSELECTrn comment_id,rn subreddit,rn author,rn comment_text,rn CAST(total_words AS INT64) total_words,rn CAST(reading_ease_score AS FLOAT64) reading_ease_score,rn reading_ease,rn reading_grade_level,rn CAST(sentiment_score AS FLOAT64) sentiment_score,rn CAST(censored AS INT64) censored,rn CAST(positive AS INT64) positive,rn CAST(neutral AS INT64) neutral,rn CAST(negative AS INT64) negative,rn CAST(subjectivity_score AS FLOAT64) subjectivity_score,rn CAST(subjective AS INT64) subjective,rn url,rn DATE(comment_date) comment_date,rn CAST(comment_hour AS INT64) comment_hour,rn CAST(comment_year AS INT64) comment_year,rn CAST(comment_day AS INT64) comment_dayrnFROM reddit_stream.comments_streamrn)rnSELECT k.*rnFROM (rn SELECT ARRAY_AGG(row LIMIT 1)[OFFSET(0)] krn FROM t1 rowrn GROUP BY comment_idrn)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e3968e07750>)])]
1. Create a new SQLX file and add your SQL
In this guide we’ll title our file as comments_partitioned.sqlx.
As you can see below, our dependency graph does not provide much information.
2. Refactor SQL to remove DDL and use only SELECT
In SQLX, you only write SELECT statements. You specify what you want the output of the script to be in the config block, like a view or a table as well as other types available. Dataform takes care of adding CREATE OR REPLACE or INSERT boilerplate statements.
3. Add a config object containing metadata
The config object will contain the output type, description, schema (dataset), tags, columns and their descriptions, and the BigQuery-related configuration. Check out the example below.
code_block[StructValue([(u’code’, u’config {rn type: “table”,rn description: “cleaned comments data and partitioned by date for faster performance”,rn schema: “demo_optimized_staging”,rn tags: [“reddit”],rn columns: {rn comment_id: “unique id for each comment”,rn subreddit: “which reddit community the comment occurred”,rn author: “which reddit user commented”,rn comment_text: “the body of text for the comment”,rn total_words: “total number of words in the comment”,rn reading_ease_score: “a float value for comment readability score”,rn reading_ease: “a plain-text english categorization of readability”,rn reading_grade_level: “a plain-text english categorization of readability by school grade level”,rn sentiment_score: “float value for sentiment of comment between -1 and 1”,rn censored: “whether the comment needed to censoring by some process upstream”,rn positive: “one-hot encoding 1 or 0 for positive”,rn neutral: “one-hot encoding 1 or 0 for neutral”,rn negative: “one-hot encoding 1 or 0 for negative”,rn subjectivity_score: “float value for comment subjectivity score”,rn subjective: “one-hot encoding 1 or 0 for subjective”,rn url: “link to the comment on reddit”,rn comment_date: “date timestamp for when the comment occurred”,rn comment_hour: “integer for hour of comment post time”,rn comment_year: “integer for year of comment post time”,rn comment_month: “integer for month of comment post time”,rn comment_day: “integer for day of comment post time”rn },rn bigquery: {rn partitionBy: “comment_date”,rn labels: {rn cost_center: “123456”rn }rn }rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e3968e02fd0>)])]
4. Create declarations for any source tables
In our SQL script, we directly write reddit_stream.comments_stream. In SQLX, we’ll want to utilize a declaration to create relationships between source data and tables created by Dataform. Add a new comments_stream.sqlx file to your project for this declaration:
code_block[StructValue([(u’code’, u’config {rn type: “declaration”,rn database: “my-project”,rn schema: “reddit_stream”,rn name: “comments_stream”,rn description: “A BigQuery table acting as a data sink for comments streaming in real-time.”rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e3968e02b50>)])]
We’ll utilize this declaration in the next step.
5. Add references to declarations, tables, and views.
This will help build the dependency graph. In our SQL script, there is a single reference to the declaration. Simply replace reddit_stream.comments_stream with ${ref(“comments_stream”)}.
Managing dependencies with the ref function has numerous advantages.
The dependency tree complexity is abstracted away. Developers simply need to use the ref function and list dependencies.
It enables us to write smaller, more reusable and more modular queries instead of thousand-line-long queries. That makes pipelines easier to debug.
You get alerted in real time about issues like missing or circular dependencies
6. Add assertions for data validation
You can define data quality tests, called assertions, directly from the config block of your SQLX file. Use assertions to check for uniqueness, null values or any custom row condition. The dependency tree adds assertions for visibility.
These assertions will pass if comment_id is a unique key, if comment_text is non-null, and if all rows have total_words greater than zero.
7. Utilize JavaScript for repeatable SQL and parameterization
Our example has a deduplication SQL block. This is a perfect opportunity to create a JavaScript function to reference this functionality in other SQLX files. For this scenario, we’ll create the includes folder and add a common.js file with the following contents:
code_block[StructValue([(u’code’, u’function dedupe(table, group_by_cols) {rn return `rnSELECT k.*rnFROM (rn SELECT ARRAY_AGG(row LIMIT 1)[OFFSET(0)] krn FROM ${table} rowrn GROUP BY ${group_by_cols}rn)rn `rn}rnrnmodule.exports = { dedupe };’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e396a289910>)])]
Now, we can replace that code block with this function call in our SQLX file as such:
${common.dedupe(“t1”, “comment_id”)}
In certain scenarios, you may want to use constants in your SQLX files. Let’s add a constants.js file to our includes folder and create a cost center dictionary.
8. Validate the final SQLX file and compiled dependency graph
After completing the above steps, let’s have a look at the final SQLX files:
comments_stream.sqlx
code_block[StructValue([(u’code’, u’config {rn type: “declaration”,rn database: “my-project”,rn schema: “reddit_stream”,rn name: “comments_stream”,rn description: “A BigQuery table acting as a data sink for comments streaming in real-time.”rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e3969628310>)])]
comments_partitioned.sqlx
code_block[StructValue([(u’code’, u’config {rn type: “table”,rn description: “cleaned comments data and partitioned by date for faster performance”,rn schema: “demo_optimized_staging”,rn tags: [“reddit”],rn columns: {rn comment_id: “unique id for each comment”,rn subreddit: “which reddit community the comment occurred”,rn author: “which reddit user commented”,rn comment_text: “the body of text for the comment”,rn total_words: “total number of words in the comment”,rn reading_ease_score: “a float value for comment readability score”,rn reading_ease: “a plain-text english categorization of readability”,rn reading_grade_level: “a plain-text english categorization of readability by school grade level”,rn sentiment_score: “float value for sentiment of comment between -1 and 1”,rn censored: “whether the comment needed to censoring by some process upstream”,rn positive: “one-hot encoding 1 or 0 for positive”,rn neutral: “one-hot encoding 1 or 0 for neutral”,rn negative: “one-hot encoding 1 or 0 for negative”,rn subjectivity_score: “float value for comment subjectivity score”,rn subjective: “one-hot encoding 1 or 0 for subjective”,rn url: “link to the comment on reddit”,rn comment_date: “date timestamp for when the comment occurred”,rn comment_hour: “integer for hour of comment post time”,rn comment_year: “integer for year of comment post time”,rn comment_month: “integer for month of comment post time”,rn comment_day: “integer for day of comment post time”rn },rn bigquery: {rn partitionBy: “comment_date”,rn labels: {rn cost_center: constants.COST_CENTERS.devrn }rn },rn assertions: {rn uniqueKey: [“comment_id”],rn nonNull: [“comment_text”],rn rowConditions: [rn “total_words > 0″rn ]rn }rn}rnrnWITH t1 as (rnSELECTrn comment_id,rn subreddit,rn author,rn comment_text,rn CAST(total_words AS INT64) total_words,rn CAST(reading_ease_score AS FLOAT64) reading_ease_score,rn reading_ease,rn reading_grade_level,rn CAST(sentiment_score AS FLOAT64) sentiment_score,rn CAST(censored AS INT64) censored,rn CAST(positive AS INT64) positive,rn CAST(neutral AS INT64) neutral,rn CAST(negative AS INT64) negative,rn CAST(subjectivity_score AS FLOAT64) subjectivity_score,rn CAST(subjective AS INT64) subjective,rn url,rn DATE(comment_date) comment_date,rn CAST(comment_hour AS INT64) comment_hour,rn CAST(comment_year AS INT64) comment_year,rn CAST(comment_month AS INT64) comment_month,rn CAST(comment_day AS INT64) comment_dayrnFROM ${ref(‘comments_stream’)}rnWHERE CAST(total_words AS INT64) > 0)rnrnrn${common.dedupe(“t1”, “comment_id”)}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e394ba4f7d0>)])]
Let’s validate the dependency graph and ensure the order of operations looks correct.
Now it’s easy to visualize where the source data is coming from, what output type comments_partitioned is, and what data quality tests will occur!
Next Steps
This guide outlines the first steps of transitioning legacy SQL solutions to SQLX and Dataform for improved metadata management, comprehensive data quality testing, and efficient development. Adopting Dataform streamlines the management of your cloud data warehouse processes allowing you to focus more on analytics and less on infrastructure management. For more information, check out Google Cloud’s Overview of Dataform. Explore our official Dataform guides and Dataform sample script library for even more hands-on experiences.
We are excited to announce that the open source Pub/Sub Lite Apache Spark connector is now compatible with Apache Spark 3.X.X distributions, and the connector is officially GA.
What is the Pub/Sub Lite Apache Spark Connector?
Pub/Sub Lite is a Google Cloud messaging service that allows users to send and receive messages asynchronously between independent applications. Publish applications send messages to Pub/Sub Lite topics, and applications subscribe to Pub/Sub Lite subscriptions to receive those messages.
Pub/Sub Lite offers both zonal and regional topics, which differ only in the way that data is replicated. Zonal topics store data in a single zone, while regional topics replicate data to two zones in a single region.
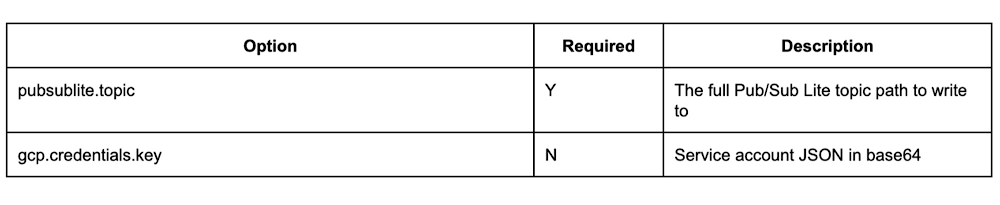
The Pub/Sub Lite Spark connector supports the use of Pub/Sub Lite as both an input and output source for Apache Spark Structured Streaming. When writing to Pub/Sub Lite, the connector supports the following configuration options:
When reading from Pub/Sub Lite, the connector supports the following configuration options:
The connector works in all Apache Spark distributions, including Databricks and Google Cloud Dataproc. The first GA release of the Pub/Sub Lite Spark connector is v1.0.0, and it is compatible with Apache Spark 3.X.X versions.
Getting Started with Pub/Sub Lite and Spark Structured Streaming on Dataproc
Using Pub/Sub Lite as a source with Spark Structured Streaming is simple using the Pub/Sub Lite Spark connector.
The cluster image version determines the Apache Spark version that is installed on the cluster. The Pub/Sub Lite Spark connector currently supports Spark 3.X.X, so choose a 2.X.X image version.
Enable API access to Google Cloud services by providing the ‘https://www.googleapis.com/auth/cloud-platform’ scope.
Next, create a Spark script. For writing to Pub/Sub Lite, use the writeStream API, like the following python script:
code_block[StructValue([(u’code’, u’# Ensure the DataFrame matches the required data fields and data types for writing to Pub/Sub Lite: https://github.com/googleapis/java-pubsublite-spark#data-schemarn# |– key: binaryrn# |– data: binaryrn# |– event_timestamp: timestamprn# |– attributes: maprn# | |– key: stringrn# | |– value: arrayrn# | | |– element: binaryrnsdf.printSchema()rnrn# Create the writeStream to send messages to the specified Pub/Sub Lite topicrnquery = (rn sdf.writeStream.format(“pubsublite”)rn .option(rn “pubsublite.topic”,rn f”projects/{project}/locations/{location}/topics/{topic}”,rn )rn .option(“checkpointLocation”, “/tmp/app” + uuid.uuid4().hex)rn .outputMode(“append”)rn .start()rn)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e0d1512d8d0>)])]
For reading from Pub/Sub Lite, create a script using the readStream API, like so:
code_block[StructValue([(u’code’, u’spark = SparkSession.builder.appName(“psl-read-app”).master(“yarn”).getOrCreate()rnrnsdf = (rn spark.readStream.format(“pubsublite”)rn .option(rn “pubsublite.subscription”,rn f”projects/{project}/locations/{location}/subscriptions/{subscription}”,rn )rn .load()rn)rnrn# The DataFrame should match the fixed Pub/Sub Lite data schema for reading from Pub/Sub Lite: https://github.com/googleapis/java-pubsublite-spark#data-schemarn# |– subscription: stringrn# |– partition: longrn# |– offset: longrn# |– key: binaryrn# |– data: binaryrn# |– publish_timestamp: timestamprn# |– event_timestamp: timestamprn# |– attributes: maprn# | |– key: stringrn# | |– value: arrayrn# | | |– element: binaryrnsdf.printSchema()’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e0cfe6a1890>)])]
Finally, submit the job to Dataproc. When submitting the job, the Pub/Sub Lite Spark connector must be included in the job’s Jar files. All versions of the connector are publicly available from the Maven Central repository. Choose the latest version (or >1.0.0 for GA releases), and download the ‘with-dependencies.jar’. Upload this jar to the Dataproc job, and submit!
Further reading
Get started with the Pub/Sub Lite Spark connector Quick Start
Instant access to your business insights lets you take faster actions and be fully aware of changes that impact your colleagues and your customers. Looker is Google for your business data, giving you the answers you need and empowering your team to take informed actions. Today, we are bringing Looker Alerts to our iOS mobile app, in general availability, extending the reach of these critical notifications to wherever you may be. This introduction adds to our existing options, which also include alerts by web, Slack and email.
Looker alerts are fully integrated with our iOS mobile app, connecting users to associated visualizations and charts, and alert history.
When there are changes in your data that are important to you and your business, you want to know about it, no matter what. By bringing mobile alerts to iOS, we are unshackling you from your desktop and reducing your time to respond and accelerating your decision making.
Once you have connected to your Looker instance on iOS, if you have enabled mobile alerts integration, alerts you create on the web are by default sent to the mobile app.
Looker mobile alerts on iOS in action
Alert notifications:
When an alert is triggered, users will receive a notification on their iOS device. The notification details can be hidden on the lock screen using iOS’s device notifications settings.
Notification center:
Within the iOS mobile app, users can see the last 7 days of alerts by tapping on the bell icon on the top right corner. Unread alerts are highlighted in this section for easy identification.
Alert details:
Users can tap on the notification to see the associated chart with details including the alert triggered time, latest trend of the alert metric, and options to share and view the detailed dashboard.
Alert sharing:
Users can share the alert with others by tapping on the share icon on top right. Alerts can be shared using iOS’s native built-in sharing.
Alert unfollowing:
To unfollow an alert in the mobile application, select the three-dot menu on the alert details page and click Unfollow. You can re-follow the alert from the Looker web application.
For more details on this feature, see the following alerts page in our help center.
Enabling Looker alerts for iOS
Upgrade to Looker version 22.20+
Enable the Firebase action in the Looker Action Hub. Firebase is used to send push notifications to the mobile application.
Install the latest version of iOS mobile app, 1.3.0 or later. You can get the app here
Enable push notifications on the Looker iOS app when prompted
When complete, all alerts will, by default, be delivered to iOS mobile app, along with any previously configured channels, including email or Slack.
Hardening a complex application is a challenge, more so for applications that include multiple layers with different authentication schemes. One common question is “how to integrate Cloud SQL for PostgreSQL or MySQL within your authentication flow?”
Cloud SQL has always supported password-based authentication. There are, however, many questions that come with this approach:
Where should you store the password?
How do you manage different passwords for different environments?
Who audits password complexity?
Ideally, it would be preferable to not have to worry about passwords at all. Using username and password authentication also breaks the identity chain. Whoever knows the password can impersonate a database role, effectively making it impossible to ascribe actions on an audit file to a specific person (or service account). Moreover, disabling an account requires finding out all the associated database logins and disabling them as well. But how can you be sure no one else shares the same login?
It’s clear that this approach does not scale well. As just one example, managing multiple database instances with multiple applications can quickly become a daunting task. To solve these challenges, Cloud SQL for PostgreSQL and MySQL users can use Cloud SQL Identity and Access Management (IAM)-mapped logins with Cloud SQL Proxy with Automatic Authentication.
Cloud SQL IAM-mapped logins
Cloud SQL’s IAM Database Authentication feature allows mapping preexisting Cloud IAM principals (users or service accounts) to database native roles. This means you can ask the Google Cloud Platform to create logins that match the email address of the IAM principal.
GCP will also handle the password for you (including storage and rotation). But how can you use it?
If your account has valid IAM credentials (cloudsql.instances.login), Google Cloud will give you the token that you can use to authenticate. Basically, Google Cloud will provide you with the Cloud SQL password, you can then use the password to connect directly to Cloud SQL for PostgreSQL and MySQL.
While you can do that yourself (via manual IAM database authentication), it would be best to have it handled automatically — such as when issuing gcloud sql generate-login-token. Google Cloud provides connectors for many languages that automate this task. (For an example of this, you can see the Golang driver for PostgreSQL in action here.) With these connectors, authenticating to Cloud SQL for PostgreSQL and MySQL can be secure and convenient.
Unfortunately, we don’t always have the luxury of changing the application code to make use of the new drivers. In that scenario you can use a Google Cloud-provided proxy, called Cloud SQL Auth proxy. This proxy allows your application to make use of the new Automatic IAM Database Authentication without any change to your codebase.
Cloud SQL Auth proxy
The Cloud SQL Auth proxy has the Automatic IAM Database authentication feature. It allows applications oblivious to Cloud SQL IAM principals to authenticate as a IAM principal
For example, if the Cloud SQL auth proxy runs in the context of a service account — maybe because it had inherited it from the Compute Engine it runs on — every connection that connects to the proxy will be able to authenticate as that service account.
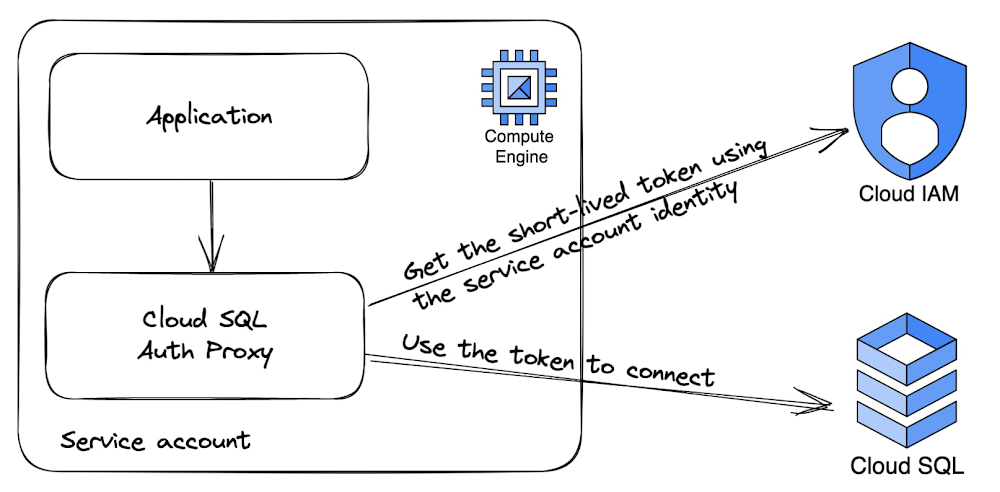
The following image shows how your application, instead of connecting to Cloud SQL directly, can connect to the Cloud SQL Auth Proxy process running in the same Compute Engine instance. The Proxy will in turn handle authentication and connection to the Cloud SQL Instance via a secure TLS connection.
It’s important to configure the Cloud SQL Auth Proxy to only accept localhost connections – either with TCP or Linux domain sockets. The application only has to specify the service account name without any password (in case of service accounts, this is the service account’s email without the .gserviceaccount.com domain suffix). The password will be added transparently by the Cloud SQL Auth proxy.
Cloud SQL Auth Proxy injection via sidecar
Cloud SQL Auth Proxy can also be used to secure GKE connections. It can be added as a sidecar container, achieving the same result as above. In this case we rely on Kubernetes network isolation to ensure only authorized connections will reach the Cloud SQL Auth Proxy.
As an example, you can refer to the following YAML Kubernetes template file that contains:
The configuration to use the GKE service account using workload identity.
An empty example deployment specification for the application connecting to Cloud SQL for PostgreSQL.
The deployment specification for the execution of the Cloud SQL proxy as a sidecar container.
The application has to be configured to access the PostgreSQL database using a localhost connection. The security is guaranteed by the fact that the application and the sidecar container share the same network. The username of the connection should be the service account email address without the .gserviceaccount.com domain suffix.
You can access the detailed documentation for Cloud SQL for PostgreSQL and MySQL and an example of Cloud SQL Proxy run as a sidecar container here.
Automatic auditing for Cloud SQL for PostgreSQL
Cloud SQL for PostgreSQL and MySQL can be configured to audit both data plane and control plane access. This can be done by enabling the relevant functionalities, as outlined here for PostgreSQL and here for MySQL.
Explore the audit trails
One very important aspect of Google Cloud’s auditing is that everything is collected centrally. The same goes for Cloud SQL for PostgreSQL audit trails, with no need for customers to manage a complex, potentially error-prone audit pipeline. This is vital for security tasks, especially for tasks that are subject to regulations.The data can be explored with Google Cloud Log Explorer or, for people who prefer SQL, we can harness the new Log Analytics engine. Log Analytics can make it easier to extract valuable information from your audit trails.
In the following example below query extracts user, database, and statement issued to configured Cloud SQL for PostgreSQL instances in the last hour:
That’s not all. Since the same query can be run by BigQuery, it’s possible to connect Looker Studio or even Looker to BigQuery and create beautiful dashboards. By leveraging Looker, it’s also possible to create automated alerts whenever specific events occur, such as an unusual access during the weekend or an abnormal number of operations in a short period of time by a specific user.
The following image depicts a demo dashboard built with Looker. Notice how dropdown filters can make exploring the data easy even for people not versed in SQL.
Conclusion
With the recent feature of Integrated IAM authentication, customers can leverage end-to-end authentication for their applications and make use of the best-in-class auditing capabilities of Google Cloud. Google Cloud offers tools you need to start using the IAM authentication right away, even if you don’t have access to the source code of your application.
As usual, Google Cloud and its partners can help you with the implementation; please reach out to us.
Today we announce new Dataplex features: automatic data quality (AutoDQ) and data profiling, available in public preview. Dataplex is an intelligent data fabric that provides a way to manage, monitor, and govern your distributed data at scale. AutoDQ offers automated rule recommendations, built-in reporting, and serveless execution to construct high-quality data. Data profiling delivers richer insight into the data by identifying its common statistical characteristics.
Reliable and consistent data presents an invaluable opportunity for organizations to innovate, make critical business decisions, and create differentiated customer experiences. But poor data quality can lead to inefficient processes and possible financial losses. Data quality used to be more manageable when the data footprint was small and data consumers were few. Data users could easily collaborate to define rules and include those in their analytics. However, organizations are now finding it challenging to scale this manual process as the data grows in volume and diversity, along with its users and use cases. They are struggling to standardize on data quality metrics as multiple data quality solutions sprawl across the organization . Very often, this leads to inconsistency and confusion.
Dataplex AutoDQ and data profiling now enable next-generation data profiling and data quality solutions that automate rule creation and at-scale deployment of data quality. The profiling capabilities also assist in improved discovery and auditability of the data.
Auto data quality and data profiling features offer:
An intelligent and integrated experience. It eliminates the learning curve by providing rule recommendations, an intuitive rule-building experience, and a zero-setup execution. It enables standardized reporting with built-in reports.
Extensibility for different data personas without creating silos. It is also extensible to accommodate the needs of different data personas. It enables data producers to own and publish the quality, while allowing data consumers to extend the reports according to their business needs.
Automation at scale. It scales transparently with the data. It will further utilize Dataplex’s attribute store mechanisms to enable at-scale definition and monitoring.
These preview features are the foundation for a future where data quality will be part of everyday data discovery and analysis.
“Reliable data is incredibly important in our decision- making to ensure we maintain customer trust. These next-generation data quality and profiling capabilities in Dataplex provide us with at-scale automation and intelligence that enables us to simplify our current processes, reduce manual toil, and standardize data quality leveraging built-in reporting and alerting.” — Jyoti Chawla, CTO and Head of Architecture, CDO, Deutsche Bank.
“We use energy data to build innovative models for power prediction, resource planning, and energy trading recommendations. To validate training and prediction data, we are actively evaluating the ‘Auto data quality’ feature from Dataplex. We have so far been impressed by its simplicity, intuitiveness, and intelligent recommendations”. — João Caldas, Head of Analytics and Innovations at Casa dos Ventos.
Flexible data model
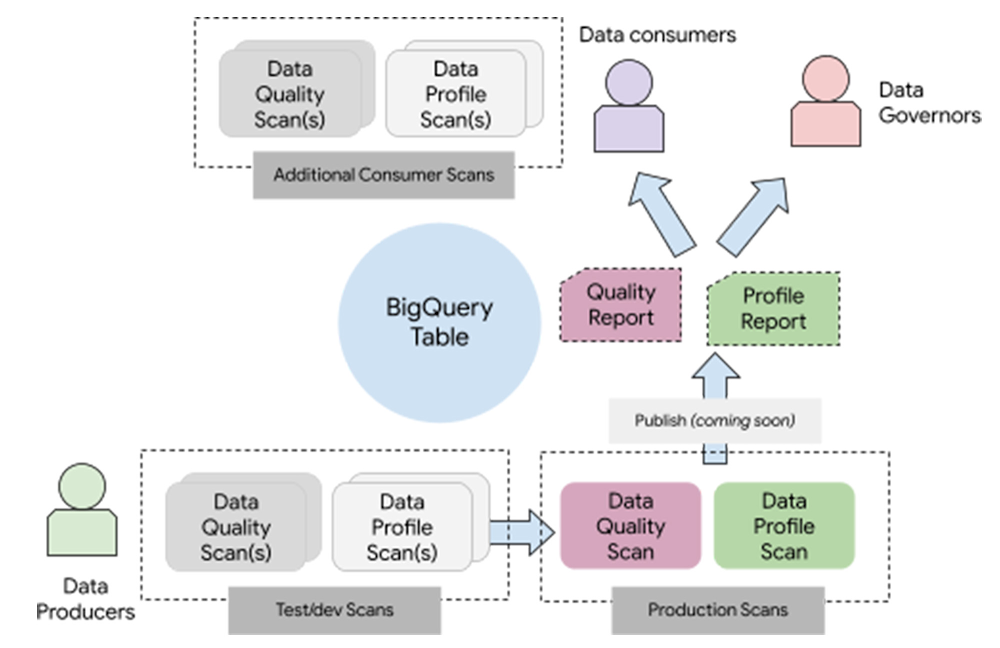
These Dataplex features offer a data model that can accommodate multiple personas and deployments. As a user of these features, you create one or more “data scans” for a table.
These data scans
are of type “data profiling” or “data quality”
are entirely serverless
can be triggered with a built-in serverless scheduler or triggered on-demand with external triggers
can be run incrementally (on the newer data) or on the entire data.
And, if you are a data producer, you can configure it to publish the results to the data catalog (coming soon!)
With this model – data producers can create and test new data scans and move them to production by publishing the results. Data consumers can consume the published results and add their data scans if required.
On top of this fundamental model – we have built intelligence and a rich UI to make it easy and intuitive to start.
To elaborate further, let’s take a sample table from BigQuery public datasets – chicago- taxi-trips (source). We will walk through the definition, execution, monitoring, and troubleshooting capabilities offered by these new features.
Profile your data with a few simple clicks
With a few clicks – you can create a data profile scan for this table in Dataplex. Data profile scan results are available in the UI and include various column statistics and graphs. Following graph shows Null %, unique %, and statistics for columns in the taxi data, along with the top-10 values in those columns.
Get recommendations for data quality rules
For building a data quality scan, we offer rule recommendations and a UI-driven rule-building experience. You can also create new rules using a few predefined rule types or your SQL code.
For recommendations – you can pick a profile scan to get recommendations from.
Note that each rule is associated with a data quality dimension and has a passing threshold.
E.g., Here is a recommended rule that recognizes payment_type should be one of the few detected values in the column.
Zero-data-copy execution
Data quality checks are executed in the most performant manner on internal Bigquery resources, and no data copy is involved when executing these queries.
View reports within Dataplex
You can schedule these checks within Dataplex or execute those through external triggers. In either of the cases – the results are available within Dataplex as a data quality report.
Scorecard to view the last seven runs:
You can also drill down into past runs. Every scan execution also preserves the rules that were used for that execution.
Set alerts through cloud logging
Data quality scan generates log entries in Google cloud logging, using which you can set alerts on failures of a particular scan or even of a particular dimension. Your email alert could look something like this.
Troubleshoot data quality issues
To troubleshoot a data quality rule failure, we assist users with a query that can generate records that triggered the failure.
There are many considerations to take into account when choosing the location type of your Cloud Storage bucket. However, as business needs change, you may find that regional storage offers lower cost and/or better performance than multi-region or dual-region storage. By design, once your data is already stored in a bucket, the location type of that bucket cannot be changed. The path forward is clear: you must create new, regional buckets and move your existing data into them.
Migrating from multi-region to regional storage
The tool for this job is the Storage Transfer Service (STS), which uses parameterization to bulk migrate files. The basic steps are as follows:
Create new buckets in the region you desire.
Use STS to transfer the objects from the original multi-region buckets to the new regional ones.
Test the objects (e.g., using Cloud Storage Insights) in the new buckets and if the test is passed, delete the old buckets.
While there is no charge for use of the STS itself, performing a migration will incur Cloud Storage charges associated with the move — including storage charges for the data in the source and destination until you delete the source bucket; for the Class A and B operations involved in listing, reading, and writing the objects; for egress charges for moving the data across the network; and retrieval and/or early delete fees associated with migrating Nearline, Coldline and Archive objects. Please see the STS pricing documentation for more information.
Though we have focused on a multi-region to regional Cloud Storage migration, in the steps that follow, the considerations and process for any other type of location change will be much the same — for example, you might want to migrate from multi-region to dual-region, which could be a good middle ground between the options, or even migrate a regional bucket from one location to a different regional location.
Planning the migration
The first determination will be which buckets to migrate. There could be a number of reasons why you would choose not to migrate certain buckets, for example, the data inside might be stale and/or not needed anymore, or it might serve a workload that is a better fit for multi-region, for example, an image hosting service for an international user base.
If you’re transferring massive amounts of data, it is also important to consider the time it will take to complete the transfer. To prevent any one customer from overloading the service, the STS has queries per second and bandwidth limitations at a project level. If you’re planning a massive migration (say over 100PB or 1 billion objects) you should notify your Google Cloud sales team or create a support ticket to ensure that the required capacity is available in the region where you’re doing the transfer. Your sales team can also help you calculate the time the transfer will take, which is a complex process that involves many factors.
To determine if you need to be worried about how long the transfer could take, consider the following data points: A bucket with 11PB of data and 70 million objects should take around 24 hours to transfer. A bucket with 11PB of data and 84 billion objects could take 3 years to transfer if jobs are not executed concurrently. In general, if the number of objects you need to transfer is over a billion, the transfer could take prohibitively long, so you will need to work with Google Cloud technicians to reduce the transfer time by parallelizing the transfer. Note that these metrics are for cloud to cloud transfers, not HTTP transfers.
There may also be metadata that you want to transfer from your old buckets to your new buckets. Some metadata, like user-created custom fields, are automatically transferred by the STS, whereas other fields, like storage classes or CMEK, must be manually enabled via the STS API. The API or gcloud CLI must also be used if you wish to transfer all versions of your objects, as opposed to just the latest one. If you are using Cloud Storage Autoclass in the destination bucket (it must be enabled at bucket creation time), all of your objects will start out as a Standard storage class after the transfer. Refer to the Transfer between Cloud Storage buckets documentation for guidance on handling all complexities you may have to account for.
Your final decision point will be whether you want to keep the exact same names for your buckets, or whether you can work with new bucket names (e.g., no application changes with the same bucket name). As you will see in the next section, the migration plan will require an additional step if you need to keep the original names.
Steps for migration
The diagram below shows how the migration process will unfold for a single bucket.
You may decide that in order to avoid having to recode the names of the buckets in every downstream application, you want your regional buckets to have the exact same names as your original multi-region buckets did. Since bucket names are as immutable as their location types, and the names need to be globally unique, this requires transferring your data twice: once to temporary intermediate buckets, then to the new target buckets that were created after the source buckets had been deleted. While this will obviously take additional time, it should be noted that the second transfer to the new target buckets will take approximately a tenth of the time of the first transfer because you are doing a simple copy within a region.
Be sure to account for the fact that there will be downtime for your services while you are switching them to the new buckets. Also keep in mind that when you delete the original multi-region buckets, you should create the regional buckets with the same name immediately afterwards. Once you’ve deleted them, theoretically anyone can claim their names.
If you are aiming to transfer multiple buckets, you can run multiple jobs simultaneously to decrease the overall migration time. STS supports around 200 concurrent jobs per project. Additionally, if you have very large buckets, either by size or number of objects, it is possible that the job may take several days to fully transfer the data in the bucket, as each job will copy one object at a time. In these cases, you can run multiple jobs per bucket and configure each job to filter objects by prefix. If configured correctly, this can significantly reduce the overall migration time for very large buckets. This library can help with managing your STS jobs, and testing the objects that have been transferred.
What’s next?
With great flexibility of storage options comes great responsibility. To determine whether a migration is necessary, you will need to do a careful examination of your data, and the workloads that use it. You will also need to consider what data and metadata should be transferred to the buckets of the new location type. Luckily, once you’ve made the decisions, Cloud Storage and the STS make it easy to migrate your data. Once your data is transferred, there are other ways to optimize your usage of Cloud Storage, such as leveraging customizable monitoring dashboards. If you’re not using the STS, perhaps for smaller transfers or analytical workloads where you’re downloading and uploading data to a VM, consider using the gcloud storage CLI.
While there has been a lot of attention given to wildfires, floods, and hurricanes, heat-related weather events are still understudied and underreported. Every summer, heat waves pose a major threat to the health of people and ecosystems. 83% of the North American population lives in cities, where the urban heat island (UHI) effect leads to higher local temperatures compared to surrounding rural areas.
But not everyone living in US cities experiences summer heat waves and urban heat islands equally. Communities with lower incomes or people of color are more likely to be impacted by extreme heat events, both due to fewer green spaces in urban areas and not having access to air conditioning. While there have been many studies that have shed light on environmental inequities between neighborhoods of varying income levels, there has been little analysis of what it will take to provide all people with protection from severe heat.
In the summer of 2019, TC Chakraborty, then a PhD candidate at the Yale School of the Environment, and Tanushree Biswas, then Spatial Data Scientist at The Nature Conservancy, California, met at one of our Geo for Good Summits. The summits bring together policymakers, scientists, and other change-makers who use Google’s mapping tools. They wanted to share ideas in their areas of expertise (urban heat and tree cover, respectively) and explore a potential path to address urban climate change inequities using open tools and a suite of datasets. Given the ability of tree cover to help mitigate local heat in cities, they wondered how much space is actually available for trees in lower income urban neighborhoods.
If this available space were to be quantified, it would provide estimates of severalco-benefits of tree cover beyond heat mitigation, from carbon sequestration to air pollution reduction, to decreased energy demand for cooling, to possible health benefits. Chakraborty and Biswas believed that increasing the tree canopy in this available space could provide economic opportunities for green jobs as well as more equitable climate solutions. Inspired by this shared vision, they joined forces to explore the feasibility of adding trees to California’s cities.
Three years later, in June 2022, Chakraborty, Biswas, and co-authors L.S. Campbell, B. Franklin, S.S. Parker, and M. Tukman published a paper to address this challenge. The study combines medium-to-high-resolution satellite observations with census data to calculate the feasible area available for urban afforestation — planting new trees — for over 200 urban clusters in California. The paper demonstrates a systematic approach that leverages publicly available data on Google Earth Engine, Google’s planetary-scale platform for Earth science data & analysis, which is free of charge for nonprofits, academics, and research use cases. Results from the study can be explored through a Earth Engine web application: Closing Urban Tree Cover Inequity (CUTI).
California is the most populated state in the United States, the fifth largest economy in the world and frequently impacted by heat waves. This makes California a prime location to demonstrate approaches to strategically reducing surface UHI (SUHI), which has the potential to positively impact millions, especially those vulnerable to heat risk. Chakraborty et al. (2022) found that underprivileged neighborhoods in California have 5.9% less tree cover (see Fig. 1 for an illustrative example for Sacramento) and 1.7 °C higher summer SUHI intensity than more affluent neighborhoods. This disparity in tree cover can be partially closed through targeted urban afforestation.
Fig 1. Street and satellite views of an underprivileged and a more affluent neighborhood in Sacramento.
Leveraging the wealth of data for cities in California, including heat-related mortality and morbidity data, sensitivity of residential energy demand to temperature, and carbon sequestration rates of California’s forests, the researchers calculated co-benefits of several urban afforestation scenarios. For their maximum possible afforestation scenario, they found potential for an additional 36 million (1.28 million acres of) trees, which can provide economic co-benefits, estimated to be worth as much as $1.1 billion annually:
4.5 million metric tons of annual CO2 sequestration
Reduction in heat-related medical visits (~4000 over 10 years)
Energy usage and cost reductions
Stormwater runoff reduction
Property value increase
With a focus on reducing disparities in SUHI and tree cover within these cities, the study provides suitability scores for scaling urban afforestation at the census-block group level across California. By focusing on California neighborhoods with high suitability scores, the authors estimate that an annual investment of $467 million in urban afforestation would both reduce heat disparities and generate $712 million of net annual benefits. Specifically, these benefits would go to 89% of the approximately 9 million residents in the lowest income quartiles of California cities. This annual investment equates to a 20-year commitment of $9.34 billion or 10,000 Electric Vehicles annually.
Fig. 2 Maps showing a median income, b current canopy cover percentage, c summer daytime surface urban heat island (SUHI) intensity, and d available area for planting trees as percentage of total area for census block groups in the Los Angeles urban cluster (Image source: TC Chakraborty and Tanushree Biswas).
The adverse effects of climate change disproportionately impact cities, so it’s critical to start thinking about viable solutions to address environmental disparities within urban communities. Providing urban planners with data-driven tools to design climate-resilient cities is a key first step. The Chakraborty et al. study leverages Earth Engine data, tech, and cloud compute resources to provide actionable insights to address environmental disparities in cities. It’s a great example of how Earth Engine can help inform urban policy and provide a bird’s-eye view of logistical support for scalable climate solutions that enable innovation and investment opportunities. In the future, Chakraborty and Biswas hope to further scale this analysis across U.S. cities to provide baseline data that can help move us towards equitable climate adaptation for everyone.
Google wants to support this kind of research! If you are a researcher working on climate impact, apply to the Google Cloud Climate Innovation Challenge in partnership with The National Science Foundation (NSF) and AI Institute for Research on Trustworthy AI in Weather, Climate, and Coastal Oceanography (AI2ES) for free credits to fuel your research.
Thanks to TC Chakraborty and Tanushree Biswas for their help in preparing this blog post.
Preprocessing and transforming raw data into features is a critical but time consuming step in the ML process. This is especially true when a data scientist or data engineer has to move data across different platforms to do MLOps. In this blogpost, we describe how we streamline this process by adding two feature engineering capabilities in BigQuery ML
Our previous blog outlines the data to AI journey with BigQuery ML, highlighting two powerful features that simplify MLOps – data preprocessing functions for feature engineering and the ability to export BigQuery ML TRANSFORM statement as part of the model artifact. In this blog post, we share how to use these features for creating a seamless experience from BigQuery ML to Vertex AI.
Data Preprocessing Functions
Preprocessing and transforming raw data into features is a critical but time consuming step when operationalizing ML. We recently announced the public preview of advanced feature engineering functions in BigQuery ML. These functions help you impute, normalize or encode data. When this is done inside the database, BigQuery, the entire process becomes easier, faster, and more secure to preprocess data.
Here is a list of the new functions we are introducing in this release. The full list of preprocessing functions can be found here.
ML.MAX_ABS_SCALER Scale a numerical column to the range [-1, 1] without centering by dividing by the maximum absolute value.
ML.ROBUST_SCALER Scale a numerical column by centering with the median (optional) and dividing by the quantile range of choice ([25, 75] by default).
ML.NORMALIZER Turn an input numerical array into a unit norm array for any p-norm: 0, 1, >1, +inf. The default is 2 resulting in a normalized array where the sum of squares is 1.
ML.IMPUTER Replace missing values in a numerical or categorical input with the mean, median or mode (most frequent).
ML.ONE_HOT_ENCODER One-hot encode a categorical input. Also, it optionally does dummy encoding by dropping the most frequent value. It is also possible to limit the size of the encoding by specifying k for the k most frequent categories and/or a lower threshold for the frequency of categories.
ML.LABEL_ENCODER Encode a categorical input to integer values [0, n categories] where 0 represents NULL and excluded categories. You can exclude categories by specifying k for k most frequent categories and/or a lower threshold for the frequency of categories.
Model Export with TRANSFORM Statement
You can now export BigQuery ML models that include a feature TRANSFORM statement. The ability to include TRANSFORM statements makes models more portable when exporting them for online prediction. This capability also works when BigQuery ML models are registered with Vertex AI Model Registry and deployed to Vertex AI Prediction endpoints. More details about exporting models can be found in BigQuery ML Exporting models.
In this tutorial, we will use the bread recipe competition dataset to predict judges rating using linear regression and boosted tree models.
Objective: To demonstrate how to preprocess data using the new functions, register the model with Vertex AI Model Registry, and deploy the model for online prediction with Vertex AI Prediction endpoints.
Dataset: Each row represents a bread recipe with columns for each ingredient (flour, salt, water, yeast) and procedure (mixing time, mixing speed, cooking temperature, resting time). There are also columns that include judges ratings of the final product from each recipe.
Overview of the tutorial: Steps 1 and 2 show how to use the TRANSFORM statement. Steps 3 and 4 demonstrate how to manually export and register the models. Steps 5 through 7 show how to deploy a model to Vertex AI Prediction endpoint.
For the best learning experience, follow this blog post alongside the tutorial notebook.
Step 1: Transform BigQuery columns into ML features with SQL
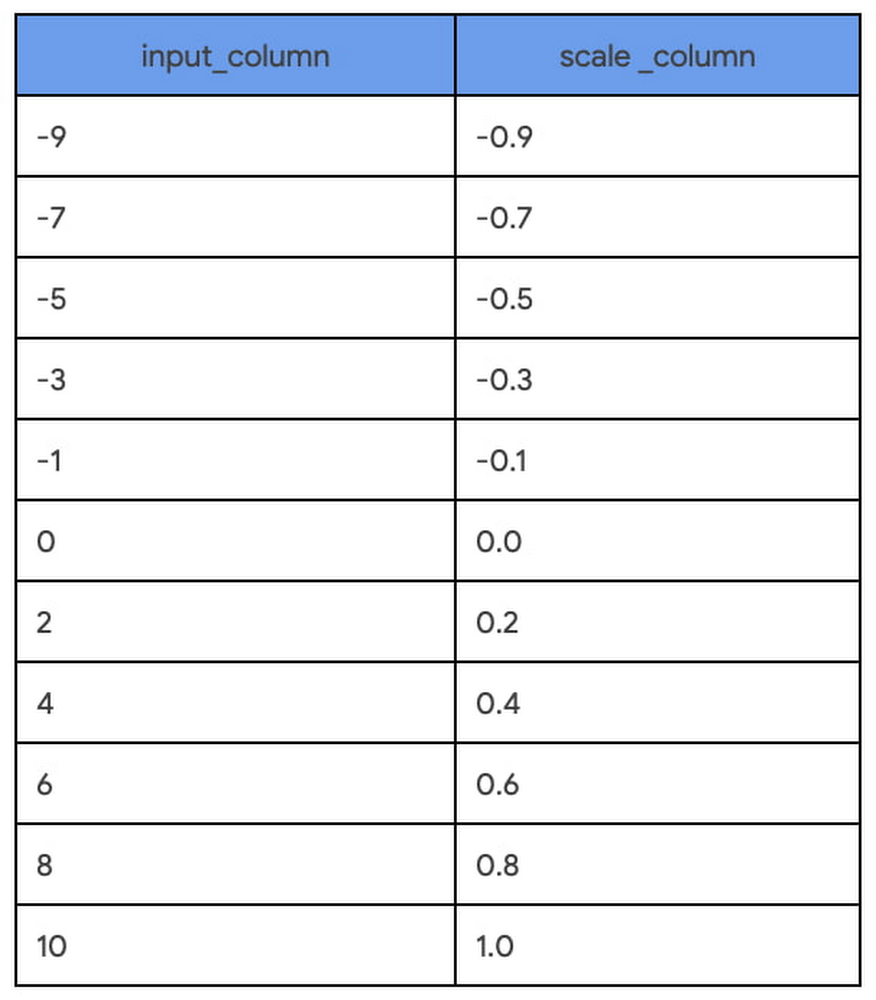
Before training an ML model, exploring the data within columns is essential to identifying the data type, distribution, scale, missing patterns, and extreme values. BigQuery ML enables this exploratory analysis with SQL. With the new preprocessing functions it is now even easier to transform BigQuery columns into ML features with SQL while iterating to find the optimal transformation. For example, when using the ML.MAX_ABS_SCALER function for an input column, each value is divided by the maximum absolute value (10 in the example):
code_block[StructValue([(u’code’, u’SELECTrn input_column,rn ML.MAX_ABS_SCALER (input_column) OVER() AS scale_columnrnFROMrn UNNEST([0, -1, 2, -3, 4, -5, 6, -7, 8, -9, 10]) as input_columnrnORDER BY input_column’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e864e54c710>)])]
Once the input columns for an ML model are identified and the feature transformations are chosen, it is enticing to apply the transformation and save the output as a view. But this has an impact on our predictions later on because these same transformations will need to be applied before requesting predictions. Step 2 shows how to prevent this separation of processing and model training.
Step 2: Iterate through multiple models with inline TRANSFORM functions
Building on the preprocessing explorations in Step 1, the chosen transformations are applied inline with model training using the TRANSFORM statement. This interlocks the model iteration with the preprocessing explorations while making any candidate ready for serving with BigQuery or beyond. This means you can immediately try multiple model types without any delayed impact of feature transformations on predictions. In this step, two models, linear regression and boosted tree, are trained side-by-side with identical TRANSFORM statements:
Training with linear regression – Model a
code_block[StructValue([(u’code’, u”CREATE OR REPLACE MODEL `statmike-mlops-349915.feature_engineering.03_feature_engineering_2a`rnTRANSFORM (rn JUDGE_A,rnrn ML.MIN_MAX_SCALER(flourAmt) OVER() as scale_flourAmt, rn ML.ROBUST_SCALER(saltAmt) OVER() as scale_saltAmt,rn ML.MAX_ABS_SCALER(yeastAmt) OVER() as scale_yeastAmt,rn ML.STANDARD_SCALER(water1Amt) OVER() as scale_water1Amt,rn ML.STANDARD_SCALER(water2Amt) OVER() as scale_water2Amt,rnrn ML.STANDARD_SCALER(waterTemp) OVER() as scale_waterTemp,rn ML.ROBUST_SCALER(bakeTemp) OVER() as scale_bakeTemp,rn ML.MIN_MAX_SCALER(ambTemp) OVER() as scale_ambTemp,rn ML.MAX_ABS_SCALER(ambHumidity) OVER() as scale_ambHumidity,rnrn ML.ROBUST_SCALER(mix1Time) OVER() as scale_mix1Time,rn ML.ROBUST_SCALER(mix2Time) OVER() as scale_mix2Time,rn ML.ROBUST_SCALER(mix1Speed) OVER() as scale_mix1Speed,rn ML.ROBUST_SCALER(mix2Speed) OVER() as scale_mix2Speed,rn ML.STANDARD_SCALER(proveTime) OVER() as scale_proveTime,rn ML.MAX_ABS_SCALER(restTime) OVER() as scale_restTime,rn ML.MAX_ABS_SCALER(bakeTime) OVER() as scale_bakeTimern)rnOPTIONS (rn model_type = ‘LINEAR_REG’,rn input_label_cols = [‘JUDGE_A’],rn enable_global_explain = TRUE,rn data_split_method = ‘AUTO_SPLIT’,rn MODEL_REGISTRY = ‘VERTEX_AI’,rn VERTEX_AI_MODEL_ID = ‘bqml_03_feature_engineering_2a’,rn VERTEX_AI_MODEL_VERSION_ALIASES = [‘run-20230112234821′]rn ) ASrnSELECT * EXCEPT(Recipe, JUDGE_B)rnFROM `statmike-mlops-349915.feature_engineering.bread`”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e863e901550>)])]
Training with boosted tree – Model b
code_block[StructValue([(u’code’, u”CREATE OR REPLACE MODEL `statmike-mlops-349915.feature_engineering.03_feature_engineering_2b`rnTRANSFORM (rn JUDGE_A,rnrn ML.MIN_MAX_SCALER(flourAmt) OVER() as scale_flourAmt, rn ML.ROBUST_SCALER(saltAmt) OVER() as scale_saltAmt,rn ML.MAX_ABS_SCALER(yeastAmt) OVER() as scale_yeastAmt,rn ML.STANDARD_SCALER(water1Amt) OVER() as scale_water1Amt,rn ML.STANDARD_SCALER(water2Amt) OVER() as scale_water2Amt,rnrn ML.STANDARD_SCALER(waterTemp) OVER() as scale_waterTemp,rn ML.ROBUST_SCALER(bakeTemp) OVER() as scale_bakeTemp,rn ML.MIN_MAX_SCALER(ambTemp) OVER() as scale_ambTemp,rn ML.MAX_ABS_SCALER(ambHumidity) OVER() as scale_ambHumidity,rnrn ML.ROBUST_SCALER(mix1Time) OVER() as scale_mix1Time,rn ML.ROBUST_SCALER(mix2Time) OVER() as scale_mix2Time,rn ML.ROBUST_SCALER(mix1Speed) OVER() as scale_mix1Speed,rn ML.ROBUST_SCALER(mix2Speed) OVER() as scale_mix2Speed,rn ML.STANDARD_SCALER(proveTime) OVER() as scale_proveTime,rn ML.MAX_ABS_SCALER(restTime) OVER() as scale_restTime,rn ML.MAX_ABS_SCALER(bakeTime) OVER() as scale_bakeTimern)rnOPTIONS (rn model_type = ‘BOOSTED_TREE_REGRESSOR’,rn booster_type = ‘GBTREE’,rn num_parallel_tree = 1,rn max_iterations = 30,rn early_stop = TRUE,rn min_rel_progress = 0.01,rn tree_method = ‘HIST’,rn subsample = 0.85, rn input_label_cols = [‘JUDGE_A’],rn enable_global_explain = TRUE,rn data_split_method = ‘AUTO_SPLIT’,rn l1_reg = 10,rn l2_reg = 10,rn MODEL_REGISTRY = ‘VERTEX_AI’,rn VERTEX_AI_MODEL_ID = ‘bqml_03_feature_engineering_2b’,rn VERTEX_AI_MODEL_VERSION_ALIASES = [‘run-20230112234926′]rn ) ASrnSELECT * EXCEPT(Recipe, JUDGE_B)rnFROM `statmike-mlops-349915.feature_engineering.bread`”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e864e9da0d0>)])]
Identical input columns that have the same preprocessing means you can easily compare the accuracy of the models. Using the BigQuery ML function ML.EVALUATE makes this comparison as simple as a single SQL query that stacks these outcomes with the UNION ALL set operator:
The results of the evaluation comparison show that using the boosted tree model results in a much better model than linear regression with drastically lower mean squared error and higher r2.
Both models are ready to serve predictions, but the clear choice is the boosted tree regressor. Once we decide which model to use, you can predict directly within BigQuery ML using the ML.PREDICT function. In the rest of the tutorial, we show how to export the model outside of BigQuery ML and predict using Google Cloud Vertex AI.
Using BigQuery Models for Inference Outside of BigQuery
Once your model is trained, if you want to do online inference for low latency responses in your application for online prediction, you have to deploy the model outside of BigQuery. The following steps demonstrate how to deploy the models to Vertex AI Prediction endpoints.
This can be accomplished in one of two ways:
Manually export the model from BigQuery ML and set up a Vertex AI Prediction Endpoint. To do this, you need to do steps 3 and 4 first.
Register the model and deploy from Vertex AI Model Registry automatically. The capability is not available yet but will be available in a forthcoming release. Once it’s available steps 3 and 4 can be skipped.
Step 3. Manually export models from BigQuery
BigQuery ML supports an EXPORT MODEL statement to deploy models outside of BigQuery. A manual export includes two models – a preprocessing model that reflects the TRANSFORM statement and a prediction model. Both models are exported with a single export statement in BigQuery ML.
code_block[StructValue([(u’code’, u”EXPORT MODEL `statmike-mlops-349915.feature_engineering.03_feature_engineering_2b`rn OPTIONS (URI = ‘gs://statmike-mlops-349915-us-central1-bqml-exports/03/2b/model’)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e864dabafd0>)])]
The preprocessing model that captures the TRANSFORM statement is exported as a TensorFlow SavedModel file. In this example it is exported to a GCS bucket located at ‘gs://statmike-mlops-349915-us-central1-bqml-exports/03/2b/model/transform’.
The prediction models are saved in portable formats that match the frameworks in which they were trained by BigQuery ML. The linear regression model is exported as a TensorFlow SavedModel and the boosted tree regressor is exported as Booster file (XGBoost). In this example, the boost tree model is exported to a GCS bucket located at ‘gs://statmike-mlops-349915-us-central1-bqml-exports/03/2b/model’
These export files are in a standard open format of the native model types making them completely portable to be deployed anywhere – they can be deployed to Vertex AI (Steps 4-7 below), on your own infrastructure, or even in edge applications.
Steps 4 through 7 show how to register and deploy a model to Vertex AI Prediction endpoint. These steps need to be repeated separately for the preprocessing models and the prediction models.
Step 4. Register models to Vertex AI Model Registry
To deploy the models in Vertex AI Prediction, they first need to be registered with the Vertex AI Model Registry To do this two inputs are needed – the links to the model files and a URI to a pre-built container. Go to Step 4 in the tutorial to see how exactly it’s done.
The registration can be done with the Vertex AI console or programmatically with one of the clients. In the example below, the Python client for Vertex AI is used to register the models like this:
Vertex AI includes a service forhosting models for online predictions. To host a model on a Vertex AI Prediction endpoint you first create an endpoint. This can also be done directly from the Vertex AI Model Registry console or programmatically with one of the clients. In the example below, the Python client for Vertex AI is used to create the endpoint like this:
Deploying a model from the Vertex AI Model Registry (Step 4) to a Vertex AI Prediction endpoint (Step 5) is done in a single deployment action where the model definition is supplied to the endpoint along with the type of machine to utilize. Vertex AI Prediction endpoints can automatically scale up or down to handle prediction traffic needs by providing the number of replicas to utilize (default is 1 for min and max). In the example below, the Python client for Vertex AI is being used with the deploy method for the endpoint (Step 5) using the models (Step 4):
Once the model is deployed to a Vertex AI Prediction endpoint (Step 6) it can serve predictions. Rows of data, called instances, are passed to the endpoint and results are returned that include the processed information: preprocessing result or prediction. Getting prediction results from Vertex AI Prediction endpoints can be done with any of the Vertex AI API interfaces (REST, gRPC, gcloud, Python, Java, Node.js). Here, the request is demonstrated directly with the predict method of the endpoint (Step 6) using the Python client for Vertex AI as follows:
The result of an endpoint with a preprocessing model will be identical to applying the TRANSFORM statement from BigQuery ML. The results can then be pipelined to an endpoint with the prediction model to serve predictions that match the results of the ML.PREDICT function in BigQuery ML. The results of both methods, Vertex AI Prediction endpoints and BigQuery ML with ML.PREDICT are shown side-by-side in the tutorial to show that the results of the model are replicated. Now the model can be used for online serving with extremely low latency. This even includes using private endpoints for even lower latency and secure connections with VPC Network Peering.
Conclusion
With the new preprocessing functions, you can simplify data exploration and feature preprocessing. Further, by embedding preprocessing within model training using the TRANSFORM statement, the serving process is simplified by using prepped models without needing additional steps. In other words, predictions are done right inside BigQuery or alternatively the models can be exported to any location outside of BigQuery such as Vertex AI Prediction for online serving. The tutorial demonstrated how BigQuery ML works with Vertex AI Model Registry and Prediction to create a seamless end-to-end ML experience. In the future you can expect to see more capabilities that bring BigQuery, BigQuery ML and Vertex AI together.
Click here to access the tutorial or check out the documentation to learn more about BigQuery ML
Thanks to Ian Zhao, Abhinav Khushraj, Yan Sun, Amir Hormati, Mingge Deng and Firat Tekiner from the BigQuery ML team
The Oden Technologies solution is an analytics layer for manufacturers that combines and analyzes all process information from machines and production systems to give real-time visibility to the biggest causes of inefficiency and recommendations to address them. Oden empowers front-line plant teams to make effective decisions, such as prioritizing resources more effectively, solving issues faster, and realizing optimal behavior.
Use cases: Challenges and problems solved
Manufacturing plants have limited resources and would like to use them optimally by eliminating any inefficiencies and making recommendations and providing data points as a key input for decision making. These data points are based on a torrent of data coming from multiple devices.
Oden’s customers are manufacturers with continuous and batch processes, such as in plastics extrusion, paper and pulp, and chemicals. Oden powers real-time and historical dashboards and reports necessary for this decision-making through leveraging the underlying Google Cloud Platform.
Oden’s platform aggregates streaming, time-series data from multiple devices and instruments and processes them in real-time. This data is in the form of continuously sampled real-world sensor readings (metrics) that are ingested into CloudIoT and transformed in real-time using Dataflow before being written to Oden’s time series database. Transformations include data cleaning, normalization, synchronization, smoothing, outlier removal, and multi-metric calculations that are built in collaboration with manufacturing customers. The time-series database then powers real-time and historical dashboards and reports.
One of the major challenges of working with real-time manufacturing data is handling network disruptions. Manufacturing environments are often not well served by ISPs and can experience network issues due to environmental and process conditions or other factors. When this happens, data can be backed up locally and arrive late after the connection recovers. To avoid overloading real-time dataflow jobs with this late data, BigQuery supports late data handling and recoveries.
In addition to the sensor data, Oden collects metadata about the production process and factory operation such as products manufactured on each line, their specifications and quality. Integrations provide the metadata via Oden’s Integration APIs running on Google Kubernetes Engine (GKE), which then writes it to a PostgreSQL database hosted in CloudSQL. The solution then uses this metadata to contextualize the time-series data in manufacturing applications.
Oden uses this data in several ways, including real-time monitoring and alerting, dashboards for line operators and production managers, historical query tools for quality engineers, and machine learning models trained on historical data and scored in real-time to provide live predictions, recommendations, and insights. This is all served in an easy to access and understand UI, greatly empowering employees across the factory to use data to improve their lines of business.
The second major challenge in manufacturing systems, is achieving quality specifications on the final product for it to be sold. Typically, Quality Assurance is conducted offline: after production has completed, a sample is taken from the final product, and a test is performed to determine physical properties of the product. However, this introduces a lag between the actual time period of production, and information about the effectiveness of that production—sometimes hours (or even days) after the fact. This prevents proactive adjustments that could correct for quality failures, and results in considerable waste.
Solution architecture
At the heart of the Oden platform is Google BigQuery, which plays an important backstage role in Oden’s data-driven software. Metric data is written simultaneously to BigQuery via a BigQuery Subscription through Cloud PubSub and metadata from CloudSQL is accessible via BigQuery’s Federated Queries. This makes BigQuery an exploratory engine for all customer data allowing Oden’s data scientists and engineers to support the data pipelines and build Oden’s machine learning models.
Sometimes these queries are ad-hoc analysis that helps understand data better. For example, here’s a BigQuery query joining both the native BigQuery metrics table and a Federated Query to the metadata in PostgreSQL This query helps determine the average lag between the event time and ingest time of customer metrics by day for November:
code_block[StructValue([(u’code’, u’SELECTrn customer_id,rn metric_id,rn TIMESTAMP_TRUNC(ingest_time, DAY) AS ingest_day,rn AVG(TIMESTAMP_DIFF(ingest_time, ingest_time, MILLISECOND)) AS diff_msrnFROMrn `oden-production.metrics.metrics`rnJOINrn EXTERNAL_QUERY(“oden-production.us.metadatadb”,rn “SELECT customer_id::text, metric_id::text FROM customer_metrics”)rnWHERErn ingest_time >= ‘2022-11-01’rn AND ingest_time < ‘2022-12-01’rnGROUP BYrn customer_id,rn metric_id,rn ingest_day’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e2c879c2c90>)])]
In addition to ad-hoc queries, there are also several key features of Oden that use BigQuery as their foundation. Below, two major features that leverage BigQuery as the highly scalable source of truth for data are covered.
Use case 1: The data reliability challenge of manufacturing and the cloud
As mentioned earlier, one of the major challenges of working with real-time manufacturing data is handling network disruptions. After the connection recovers, you encounter data that has been backed up and is out of temporal sequence. To avoid overloading real-time dataflow jobs with this late data, BigQuery is used to support late data handling and recoveries.
The data transformation jobs that run on Dataflow are written in the Apache Beam framework and usually perform their transformations by reading metrics from an input Pubsub topic and writing back to an output topic. This forms a directed acyclic graph (DAG) of transformation stages before the final metrics are written to the time-series database. But the streaming jobs degrade in performance when handling large bursts of late data putting the ability at risk to meet Service Level Agreements (SLAs), which guarantee customers high availability and fast end-to-end delivery of real-time features.
A key tenet of the Apache Beam model is that transformations can be applied to both bounded and unbounded collections of data. With this in mind, Apache Beam can be used for both streaming and batch processing. Oden takes this a step further with a universal shared connector for every one of the transformation jobs which allows the entire job to switch between a regular “streaming mode” and an alternative “Batch Mode.” In “Batch Mode,” the streaming jobs can do the same transformation but use Avro files or BigQuery as their data source.
This “Batch Mode” feature started as a method of testing and running large batch recoveries after outages. But it has since evolved into a solution to late data handling problems. All data that comes in “late” to Oden bypasses the real-time Dataflow streaming jobs and is written to a special “Late Metrics” PubSub topic and then to BigQuery. Nightly, these “Batch Mode” jobs are deployed and data is queried that wasn’t processed that day out of BigQuery and results written back to the time-series database. This creates two SLAs for customers; a real-time one of seconds for “on-time” data and a batch one of 24 hours for any data that arrives late.
Occasionally, there is a need to backfill transformations of these streaming jobs due to regressions or new features to backport over old data. In these cases, batch jobs are leveraged again. Additionally, jobs specific to customer data are joined with metrics and customer configuration data hosted in CloudSQL via BigQuery’s Federated queries to CloudSQL.
By using BigQuery for recoveries, dataflow jobs continue to run smoothly, even in the face of network disruptions. This allows maintaining high accuracy and reliability in real-time data analysis and reporting. Since moving to separate BigQuery-powered late-data handling, the median system latency of calculated metrics feature for real-time metrics is under 2s which allows customers to observe and respond to their custom multi-sensor calculated metrics instantly.
Use case 2: Building and delivering predictive quality models
The next use case deals with applying machine learning to manufacturing: predicting offline quality test results using real-time process metrics. This is a challenging problem in manufacturing environments, where not only is high accuracy and reliability necessary, but the data is also collected at different sampling rates (seconds, minutes, and hours) and stored in several different systems. The merged datasets represent the comprehensive view of data to factory personnel, who use the entire set of context information to make operational decisions. This ensures Predictive Quality models access this same full picture of the manufacturing process as it provides predictions.
At Oden, BigQuery addresses the two key challenges of machine learning in the manufacturing environment:
Using time series data stored in time series database, summary aggregates are performed to construct features as input for model training and scoring.
Using federated queries to access context metadata, data is merged with the aggregates to fully characterize the production period. This allows easily combining the data from both sources and using it to train machine learning models.
Oden uses a variety of models and embeddings — ranging from linear models (Elastic Nets, Lasso), ensemble models (boosted trees, random forests) to DNNs that allow addressing the different complexity-accuracy-interpretability requirements of customers.
The chart shows out-of-sample predictions of offline quality test values, compared with the actual values that were observed after the end of production. The predicted values provide lead time of quality problems of up to one hour.
Models are trained using an automated pipeline based on Apache Airflow and scikit learn, and models are stored in Google Cloud Storage for versioning and retrieval. Once the models are trained, they can be used to predict the outcomes of quality tests in real-time via a streaming Dataflow job. This allows factory floor operators to identify and address potential problems before they become more serious or have a large impact. This improves the overall efficiency of the production process, and reduces the amount of waste that a factory generates. Factory floor operators receive up-to-date information about the quality characteristics of current production conditions, up to an hour before the actual test value is available for inspection. This gives early warning to help catch quality failures. In turn, this reduces material waste and machine downtime, metrics that are central to many manufacturers’ continuous improvement initiatives, as well as their day-to-day operations.
Operators come to rely upon predictive models to execute their roles effectively, regardless of their experience level or their familiarity with a specific type of production or machinery, and up-to-date models are critical to the success of the predictions in improving manufacturing processes. Hence, in addition to training, life-cycle management of models and ML ops are important considerations in deploying reliable models to the factory floor. Oden is focusing on leveraging Vertex AI to make the ML model lifecycle more simple and efficient.
Oden’s Predictive Quality model empowers operators to take proactive steps to optimize production on the factory floor, and allows for real-time reactions to changes in the manufacturing process. This contributes to cost reduction, energy savings, and reduced material wasted.
The future of BigQuery at Oden
Actionable data, like the processed data generated by Oden, has become such a critical part of making predictions and decisions to remain competitive in the manufacturing space. In order to use these insights to their full potential, businesses need a low barrier to access data, unify the data with other data sources, derive richer insights and make learned decisions. Oden already leads the market in having trustworthy, usable, and understandable insights from combined process, production, and machine data that is accessible from everyone within the plant to improve their line of business. There is opportunity to go beyond the Oden interface to integrate with even more business systems The data can be made available in the form of finished datasets, hosted in BigQuery. Google Cloud has launched a new service called Analytics Hub , powered by BigQuery with the intent to make data sharing easier, secure, searchable, reliable and highly scalable.
Analytics Hub is based on the Publish-Subscribe model where BigQuery datasets are enlisted into a Data exchange as a Shared dataset, which hosts hundreds of listings. It lets users share multiple BigQuery objects such as views, tables, external tables, models etc into the Data exchange. A Data exchange can be marked public or private for a dedicated sharing. On the other end, businesses can subscribe to one or more listings in their BigQuery instance, where it is consumed as a Linked dataset to run queries against. Analytics Hub sets up a real-time data pipeline with a low-code no-code approach to share data, while giving Oden complete control over what data needs to be shared for better governance.
This empowers advanced users, who have use-cases that exceed the common workflows already achievable with Oden’s configurable dashboard and query tools, to leverage the capabilities of BigQuery in their organization. This brings Oden’s internal success with BigQuery directly to advanced users. With BigQuery, they can join against datasets not in Oden, express complex BigQuery queries, load data directly with Google’s BigQuery client libraries, and integrate Oden data into third party Business Intelligence software such as Google Data Studio.
Better together
Google Cloud and Oden are forging a strong partnership in several areas, most of which are central to customers needs. Oden has developed a turnkey solution by using the best in class Google Cloud tools and technologies, delivering pre-built models to accelerate time to value and enabling manufacturers to have accessible and impactful insights without hiring a data science team. Together, Google and Oden are expanding the way manufacturers access and use data by creating a clear path to centralize production, machine, and process data into the larger enterprise data platform paving the way for energy savings, material waste reduction and cost optimization,
Click here to learn more about Oden Technologies or to request a demo.
The Built with BigQuery advantage for ISVs
Google is helping tech companies like Oden Technologies build innovative applications on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs through the Built with BigQuery initiative, launched in April ‘22 as part of the Google Data Cloud Summit. Participating companies can:
Get started fast with a Google-funded, pre-configured sandbox.
Accelerate product design and architecture through access to designated experts from the ISV Center of Excellence who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable data warehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. And with a huge partner ecosystem and support for multi-cloud, open source tools and APIs, Google provides technology companies the portability and extensibility they need to avoid data lock-in.
We thank the Google Cloud and Oden team members who co-authored the blog: Oden: Henry Linder, Staff Data Scientist & Deepak Turaga, SVP Data Science and Engineering. Google: Sujit Khasnis, Solutions Architect & Merlin Yammsi, Solutions Consultant