Here at Smart Data Collective, we have blogged extensively about the changes brought on by AI technology. Over the past few months, many others have started talking about some of the changes that we blogged about for years. While the technology is not new, this is being referred to as the year for AI.
There are numerous ways that machine learning technology is changing the financial industry. We talked about the benefits of AI for consumers trying to improve their own personal financial plans. However, machine learning can also help financial professionals as well. One of the most important changes pertains to risk parity management.
We are going to provide some insights on the benefits of using machine learning for risk parity analysis. However, before we get started, we will provide an overview of the concept of risk parity. You can find a discussion on the benefits of machine learning for risk parity at the end of this article.
What is risk parity?
Risk parity is a portfolio management strategy that distributes risk benefits and disadvantages. Risk parity is a portfolio allocation approach that balances a portfolio’s risk across asset types. The objective is to construct a portfolio in which each asset type provides an equal proportion of risk to the portfolio as a whole. In contrast to conventional portfolio management methods, which concentrate on diversification among individual securities within a single asset class, this approach diversifies across asset classes.
Who invented risk parity?
In 1996, Ray Dalio of Bridgewater Associates, a prominent hedge fund, introduced the first risk parity fund under the moniker All Weather asset allocation approach. Although Bridgewater Associates brought the risk parity fund to the market, they didn’t define the word until 2005, when Edward Qian of PanAgora Asset Management used it for the first time in a white paper he published. Risk Parity was one of Andrew Zaytsev of Alan Biller and Partners’ investing categories in 2008.
The fundamental concept is to allocate money based on the risk of each asset class, as opposed to the conventional method of allocating capital based on market capitalization or other indicators. Eventually, the word was embraced by the whole asset management sector.
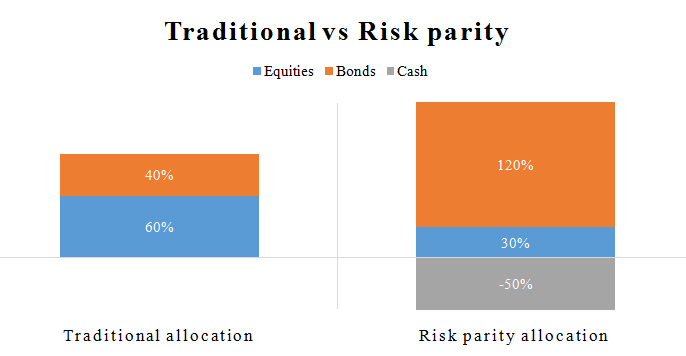
Any hazardous asset often provides more significant returns than cash. So, borrowing money and investing in risky investments (also known as financial leverage) makes sense to increase portfolio returns. This approach results in a negative cash allocation while the allocation to risky assets (bonds and equities) surpasses 100%.
Compared to the usual portfolio allocation of 60% to stocks and 40% to bonds in the 3-asset risk parity portfolio, the allocation to equities has been halved. In contrast, the allocation to bonds has been significantly boosted, resulting in a negative allocation to cash (indicating borrowed funds). Hence, the portfolio risk contribution of stocks is reduced. At the same time, that of bonds is increased to guarantee that all asset classes contribute an equivalent amount of risk (considering zero risk for cash).
Objections
One of the fundamental assumptions is that all assets display a comparable Sharpe ratio, which is the predicted return to volatility ratio. Unfortunately, it’s only sometimes valid; hence, it’s hard to leverage up assets without diminishing portfolio efficiency (Sharpe ratio). In addition, it’s often necessary to leverage the portfolio to obtain the targeted returns, which results in excess cash components.
The fundamental principle of risk parity is that investors need to diversify their portfolios across several risk categories. This is because different forms of risks have varying correlations with one another, meaning they often behave differently in various market settings. By diversifying across many risk categories, investors develop a more stable portfoliothat is less likely to suffer significant losses in any one market scenario.
The objective of risk parity is to generate more stable returns across a variety of market circumstances. By balancing the risk of several asset classes, investors lessen the effect of market volatility and prevent the risk of being overexposed to a single asset type.
To build a risk parity portfolio, investors must first identify the various categories of risks they wish to diversify. This typically encompasses four primary types of risk: stocks, bonds, commodities, and currencies. These asset classes are divided into sub-asset classes, such as U.S. equities, emerging market bonds, and gold.
After identifying the various asset classes, the following step is to calculate the risk contribution of each asset class to the portfolio. Typically, this is accomplished by evaluating the volatility of each asset type as a proxy for risk—the more an asset class volatility, the more outstanding its portfolio risk contribution.
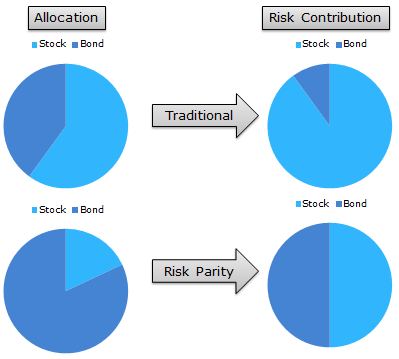
Each asset class is assigned a weight proportional to its risk contribution for a risk parity portfolio to operate. For instance, if U.S. stocks have a 40% risk contribution and bonds have a 60% risk contribution, the portfolio will be allocated 40% to U.S. equities and 60% to bonds. This guarantees that each asset type contributes the same level of risk to the portfolio as a whole.
One of the primary benefits of the risk parity method is that it assists in lowering the portfolio’s total risk. Investors build a more secure portfolio by diversifying across risks. At times of market stress, when specific asset classes possibly face huge losses, this proves to be very valuable.
Before making investment decisions, it’s essential, as with any investment plan, to thoroughly analyze the advantages and drawbacks of risk parity and to contact a financial counselor. Examine the benefits and disadvantages of risk parity.
These are some advantages of risk parity.
Diversification: Risk parity allows diversifying assets by spreading risk evenly across several asset classes, such as
Equities
Bonds
Commodities
Currencies
It reduces the total portfolio risk. This assists in lowering the entire portfolio’s risk by minimizing concentration in any asset type.
Risk management: By taking into account the unpredictability of each asset class rather than the monetary worth of each investment often assists in managing risk. This strategy helps to mitigate portfolio risk during instances of market volatility. It guarantees that the portfolio is well-diversified and every asset class contributes equally to its total risk, aiding in risk management and resulting in more consistent returns over time.
Higher return potential: Risk parity enables investors to allocate assets in a way that optimizes the anticipated gains for a given amount of risk. It leads to better returns than a standard asset allocation approach.
More dynamic than conventional asset allocation: Traditional asset allocation procedures are sometimes rigid and rely on preset asset allocation percentages. On the other hand, risk parity modifies the distribution of funds based on current market conditions.
Consistent returns: As risk parity allocates risk equitably across asset classes, the returns from various asset classes need to become more constant over time. This lowers market fluctuations and give a more steady return profile.
Opponents of this strategy note that not everything that glitters is gold; they argue that while the danger is reduced, it isn’t eliminated. Here are some disadvantages of risk parity.
Market timing risk: Risk parity portfolios confront market timing risk since the risk or volatility of the invested asset doesn’t always remain constant. Hence, the risk often exceeds the set limitations, and the portfolio manager must refrain from swiftly withdrawing the investment.
Monitoring: Even though active management isn’t as important as it’s in a more traditional portfolio, rebalancing and tracking are still necessary. Hence, the expenses of these portfolios are much greater than those of entirely passive portfolios, which need essentially no portfolio management.
Leverage: A greater leverage is necessary to obtain the same return as traditional portfolio management. But, there is a trade-off to reducing risk. Therefore it’s up to the investor to decide.
Increased cash allocation: The increased demand for leverage necessitates more cash to fulfill periodic payments to leverage providers and margin calls. This constraint is because cash and near-cash securities earn a negligible or nonexistent return.
Complexity: Risk parity needs an in-depth knowledge of financial environments and asset allocation methods. Lack of proper knowledge makes it more difficult for individual investors to execute alone.
Expensive: Certain risk parity strategies happen to be costly, especially for individual investors who don’t have access to institutional share classes.
Correlation sensitivity: Risk parity portfolios are often susceptible to asset class correlations, resulting in unanticipated losses in certain market situations.
Risk parity isn’t always suitable for all investors: Investors, particularly those with specified investing goals or constraints, such as a minimum or maximum exposure to specific asset classes or industries don’t find risk parity suitable for them.
Increased expenses: Using several asset classes in a risk parity portfolio often results in increased costs, such as trading costs and fees connected with the usage of exchange-traded funds (ETFs).
Reduced returns in boom times: Risk parity often outperforms alternative approaches more extensively invested in stocks during a strong bull market. This is because risk parity strategies have a reduced allocation to equities, which happen to restrict the potential for returns during times of market boom.
Risk parity strategy- A portfolio management technique
It is a technique in which the capital is divided across diverse assets to ensure the risk contribution of each asset is equal, hence the name.
Risk parity is a valuable technique for controlling risk and offering higher returns, but it’s full of obstacles and disadvantages. Before determining whether to use this strategy in their portfolios, carefully weigh the costs and rewards.
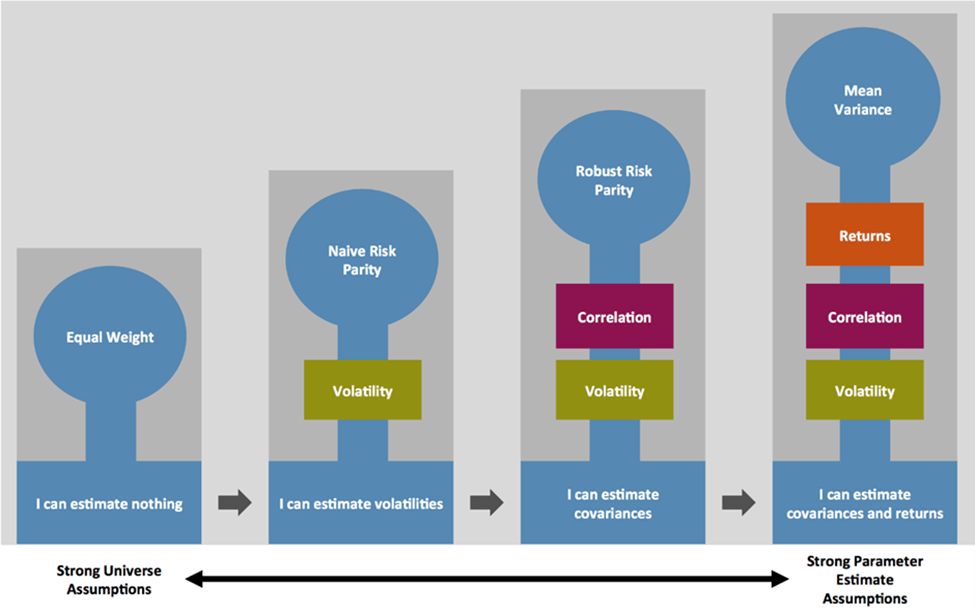
The authors used a machine learning platform to better understand different risk parity models for various financial markets. They assessed machine learning approaches for managing equities, bond, and hedge fund markets.
The research shows that machine learning can be very promising for handling risk parity calculations. However, finetuning these models is a big part of the process.
The authors stated that machine learning models with a limited number of factors appear to offer better results than those that use more complex and standard models. They believe that the best models appear to use macroeconomic indicators such as economic cycles, inflation and credit spread.
The authors state that machine learning certainly offers promise for risk parity calculations. They believe that it can be even more invaluable for projects such as “long-term investment strategies for pension funds.”
Machine Learning Opens New Doors for Financial Professionals by Improving Risk Parity Models
Machine learning technology has seriously disrupted the financial industry. A growing number of financials are using AI to improve their risk parity models and address other needs.
Data analytics technology has had a profound impact on the state of the financial industry. A growing number of financial institutions are using analytics tools to make better investing decisions and insurers are using analytics technology to improve their underwriting processes.
Small businesses need to understand the role that data analytics plays in assisting with tax compliance. They will need to know how to use analytics tools to better meet tax compliance requirements.
Ways Data Analytics is Changing the Nature of Tax Compliance for Small Businesses
Tax compliance is an integral part of running a successful business. It’s challenging to stay on top of constantly changing tax policies, but it’s essential to keep your business compliant and avoid potential penalties or other consequences from non-compliance.
The good news is that staying compliant is easier than ever in an age where data analytics tools can help you manage your finances. This post will discuss five tips that will help ensure that your organization use analytics technology to meet all government regulations regarding taxes.
Big Data Tools Make it Easier to Keep Records
Newer tax management tools use sophisticated data analytics technology to help with tax compliance. tools. According to a poll by Dbriefs, 32% of businesses feel data quality issues are the biggest obstacle to successfully using analytics to address tax compliance concerns. Fortunately, new software better stores data on transactions, which makes analytics-driven tax compliance easier.
Keeping track of all financial transactions, including receipts and invoices for goods and services that your business has purchased or sold, is essential. This will make it much easier when it comes time to file taxes, as you’ll have an organized and detailed list of your expenses.
Having everything on record will also make it easier to spot any discrepancies or errors that could lead to an audit. For streamlined record keeping, you can take advantage of accounting software such as QuickBooks or Freshbooks, designed to make tracking and to organize your finances more manageable. These applications have a number of analytics tools that can help you store information about your transactions more easily.
Use Data Mining Tools to Uncover Generous Tax Credits and Deductions
Taking advantage of any available tax credits or deductions when filing taxes is always a good idea, as these benefits can help reduce your overall tax liability. There are many different types of credits and deductions available depending on your business and industry, so it’s essential to review all available options. Your accountant or tax professional can advise on which credits and deductions would benefit your business.
This is one of the areas where data mining technology can come in handy. A number of web scraper tools such as Octoparse and Parsehub use data mining algorithms to scrape data from various websites. However, more advanced tools use AI to mine data from sites the user may not have thought to look for. These tools allow companies to enter keywords about the types of tax credits that they are looking for. This is one of the ways that AI can automate tax compliance.
Hire a Professional Accountant that Knows How to Leverage Analytics Properly
It’s always a good idea to hire an accountant or tax professional to help ensure that your filings are done correctly and on time. A qualified business accountant like those from atlantabusinessaccountants.com can provide valuable advice on preparing, filing, and paying taxes efficiently. You can also ask an accountant for help with any additional tax-related tasks, such as filing information returns or claiming deductions.
They can also help you detect any potential issues before they become a problem and guide how to optimize deductions and credits so that your business pays the least tax possible. If you’re starting, they can also be an excellent resource for learning about the tax rules and regulations that apply to your business.
There Are Still Some Challenges Analytics Can’t Help with
Data analytics technology can address a number of tax compliance issues. However, there are still some issues that it can’t solve yet. You still need to be proactive about dealing with tax problems, which involves taking the following steps.
Follow Tax Deadlines
Tax deadlines can be easy to overlook if you’re busy managing other aspects of your business, but they are essential to staying compliant with tax laws. Missing a filing deadline can lead to hefty penalties, so it’s important to know when all income and other taxes need to be paid.
You can find information on tax seasons in your state or country’s tax laws and on the websites of relevant government agencies. It would be best if you also kept an eye out for changes to tax policies throughout the year to stay updated with the latest requirements.
Stay Up to Date With Tax Laws
Tax laws are constantly changing, so it’s important to keep up with any new regulations or changes that may affect your business. Checking in regularly with the relevant government agencies and taxation experts is vital for staying updated on the tax news and ensuring compliance.
You can also subscribe to newsletters or blogs that update tax laws and check in regularly with your accountant. Keeping up with changes in the law will help you ensure that your business remains compliant and minimize the risk of any potential penalties or audits.
Tax compliance is necessary for any business, so staying informed and up-to-date on the latest rules and regulations is essential. From keeping accurate record keeping to taking advantage of available deductions and credits, there are many strategies that you can use to ensure your business remains compliant with all tax laws. With proper planning and guidance from a qualified accountant, you can ensure that your taxes are filed correctly and on time.
Analytics is Driving a Number of Changes for Tax Compliance
As this post from CPA Journal reports, analytics technology is significantly changing the state of tax compliance. You may want to learn how to use analytics tools to better comply with your tax obligations.
While healthcare has evolved in many keyways over the last several decades, there are still several groups of individuals who find themselves without access to appropriate healthcare resources. One of these groups is rural residents, who face a number of challenges when it comes to having access to healthcare.
Fortunately, data-driven approaches are emerging as potent solutions to this obstacle. Understanding the ways that data can be leveraged to help solve the issue of rural healthcare can give one insight into the ways healthcare is evolving in today’s modern world.
Here is the importance of data-driven approaches to improving healthcare in rural areas.
Using Data to Improve Telemedicine
Telemedicine is a practice that has been helping address the problem of healthcare access in rural areas in powerful ways. In essence, it can be described as the practice of providing healthcare services through the use of electronic technology, such as smartphones and computers. Given the fact that telemedicine has presented itself as a promising practice in rural areas, improving and advancing telemedicine is steadily becoming a priority in healthcare.
Data-driven decision-making has the power to improve telemedicine and make it more effective. Essentially, healthcare providers can use data to analyze past telemedicine practices. The insights provided by these analyses can offer insights that indicate which telemedicine treatments are most effective and which are not. With these insights, healthcare organizations can start improving telemedicine treatments that are underperforming and investing more in the ones that work well.
Using Data to Highlight Groups in Need
Though rural areas are often generalized and grouped together given their similar lack of access to healthcare resources, the truth is that each rural area has its own specific needs. Some have a greater need for healthcare resources in general while some contain specific groups of residents who are acutely underserved. Using data can help healthcare organizations pinpoint which rural communities and groups are most in need of healthcare resources and treatment.
In addition to already experiencing a marked lack of access to healthcare resources, hospital closures in rural areas became extremely common as a result of the COVID-19 pandemic. This exacerbated the need for additional healthcare resources in a plethora of rural areas.
By analyzing data on various rural populations, those with the biggest lack of access to healthcare can be made a priority. This being the case, a data-driven approach can improve healthcare in rural areas by highlighting which specific areas and groups need the most immediate focus and resources.
Using Data to Improve Health Outcomes
In rural communities, there are typically a number of ailments that are more common. Oftentimes, these arise from a lack of health literacy which causes rural residents to engage in a number of unhealthy behaviors such as excessive smoking and drinking. However, healthcare organizations have an opportunity to improve the health outcomes of rural residents by looking at data to illuminate patterns of the most common illnesses and engaging in preventative treatments.
As a result of analyzing data, healthcare organizations can identify early symptoms of common illnesses and engage in effective preventative care. This means that data can help healthcare organizations improve the health outcomes of rural residents in a significant way.
As such, taking advantage of a data-driven approach to rural healthcare can have a profound impact on the health outcomes of masses of rural residents.
Using Data to Monitor Rural Health
In many rural areas, the closest medical facility can take hours to reach. As such, many rural residents refrain from receiving consistent check-ups and medical assessments. This can result in preventable health ailments becoming more severe and sometimes even terminal. To solve this issue, many healthcare organizations are turning to health monitoring devices that rural residents can wear. In essence, these devices analyze health data and detect patterns. When these devices detect health data that seem anomalous or abnormal, medical professionals can be alerted.
Using data to monitor the health of rural residents remotely is a way that healthcare organizations can help these individuals prevent serious illnesses without having to pour large sums of money into building new medical facilities. This being the case, using the data analysis capabilities of remote monitoring devices is a powerful data-driven solution to the problem of rural healthcare access.
Data-Driven Solutions Are Transforming Rural Healthcare
While many solutions are beginning to show promise in addressing the healthcare needs of rural residents, data-driven approaches are emerging as some of the most effective remedies. From improving telemedicine to monitoring health remotely, taking advantage of data-driven tactics can help healthcare organizations become more effective in their efforts.
As such, utilizing data in effective ways is likely to solve the issue of rural healthcare in meaningful ways in the decades to come.
Communication Service providers (CSPs) are facing a new dynamic where they have a digitally savvy customer base and market competition is higher than ever before. Understanding customers and being able to present them with relevant products and services in a contextual manner has become the focus of CSPs. Digitization and hyper-personalization will be powering the growth of CSPs in the new world.
Data shows that personalized offers drive to up to 30% increase in sales and 35% increase in customer lifetime value. In fact, over 90% of the CSPs surveyed in a Delta Partners Global Telecom Executive Survey expect sales and queries to increase digitally in the post-pandemic world, and 97% are showing a commitment to improving and investing in digital growth channels.
At Google Cloud, we are harnessing Google’s digital marketing learnings, capabilities, and technology, and combining them with our products and solutions to enable customers across industries — including CSPs — to help accelerate their digital transformation as they prepare for the next wave of growth.
Today at Mobile World Congress 2023 Barcelona, we announced Telecom Subscriber Insights, a new service designed to help CSPs accelerate subscriber growth, engagement, and retention. It does so by taking insights from CSPs’ existing permissible data sources such as usage records, subscriber plan/billing information, Customer Relationship Management (CRM), app usage statistics, and others. With access to these insights, CSPs can better recommend subscriber actions, and activate them across multiple channels.
Key use cases
Telecom Subscriber Insights is an artificial intelligence (AI) powered product that CSPs’ line of business (LOB) owners can use to improve key performance indicators (KPIs) across the subscriber lifecycle — from acquisition and engagement, to up-sell/cross-sell, and reducing customer churn.
Subscriber acquisition
Increasing the number of new acquired subscribers, while also reducing the cost of acquisition, is a key goal for CSPs. Telecom Subscriber Insights helps CSPs achieve this goal by helping to reduce friction to subscribers throughout the onboarding process, and make the experience simple and elegant with one-click provisioning.
Subscriber engagement
As CSPs have expanded beyond physical stores into the digital world, they have changed the way they engage with consumers — using digital channels to learn more about subscriber interests, needs, and to help personalize their offerings. In this new engagement model, CSPs are not only looking to increase digital engagement through their app, but also reimagine and increase the quality of that engagement.
Telecom Subscriber Insights provides contextual and personalized recommendations that can enable CSPs to interact with subscribers in their app, helping to improve key KPIs associated with digital engagement.
Up-sell/cross-sell
Quality subscriber engagement is rewarding on both sides: subscribers are delighted by more contextual and personalized offers, and business owners can improve customer loyalty and growing revenue through product cross-sell/up-sell opportunities.
Telecom Subscriber Insights supports contextual and hyper-personalized offers, and can enable CSPs to deliver targeted engagements that help meet the needs of subscribers with product and services offers, while helping to ensure subscribers are not overloaded with unwanted offers.
Reducing customer churn
Throughout the customer lifecycle, CSPs are focused on delivering quality products and services to their customers to help drive customer lifetime value and reduce potential churn.
Telecom Subscriber Insights helps CSPs identify segments of subscribers who have a high propensity for churn, and recommends the next best offers to help retain customers.
The technology driving insights
Telecom Subscriber Insights is a cloud-based AI powered first party product built on proven Google Cloud tools that ingests data from various sources to help forecast subscriber behavior, and recommend subscriber segments who are probable to upgrade, and probable to churn. The solution also recommends appropriate actions to CSPs including identifying Next Best Offers (NBOs) based on the identified segments. CSPs are provided with integrations to multiple activation channels, helping them close the engagement with subscribers based on recommended actions. Google Cloud values other Independent Software Vendors (ISVs) who continue to complement Telecom Subscriber Insights with their own offerings built using the same Google Cloud tools.
Telecom Subscriber Insights offers a variety of capabilities, as follows:
Ingesting and normalizing Telecom subscriber data
Various data sources such as CSPs’ OSS systems, CRM, and various other sources are ingested into BigQuery. Data is then normalized to pre-defined data models. The data could be ingested with simple APIs through batch upload, or streamed using standard Google Cloud technologies.
Pre-trained AI models
Predefined data models help in continuous training of various machine learning (ML) models to provide results with high efficacy. The model can be further fine-tuned on a per-deployment basis for granular performance. ML models including propensity, churn, NBO, segmentation, and many more are carefully selected to meet CSPs’ business objectives. Telecom Subscriber Insights can integrate with some other proven ML models, where applicable, with an ecosystem approach to help enrich our offering to CSPs.
Automated data pipeline
Telecom Subscriber Insights provides an automated data pipeline that stitches aspects of data processing — from data ingestion, transformation, normalization, storage, query, to visualization — helping to ensure customers need to expend near-zero effort to get started.
Multi-channel activation
Subscribers can be reached on various channels including SMS, in-app notifications, and various other interfaces. To make integration easy without introducing new interfaces to subscribers, CSPs can embed Software Development Kits (SDKs) as part of their current apps and interfaces. Telecom Subscriber Insights is built on the premise of invoking multiple activation channels using a one-click activation on the marketing dashboard, so the CSP can reach the subscriber in a contextually appropriate manner.
One-click deployment and configuration
Telecom Subscriber Insights is available as a customer-hosted and operated model. The software is packaged in an easy-to-consume Google Cloud project that is built and transferred to the customer when they purchase the product. The Google Cloud project includes the necessary software components, which Google remotely manages and upgrades over a control plane. This model helps ensure that customers have to do near zero work on an ongoing basis to have the latest AI models and software, while benefiting from operating the software on their own, with full control.
Get started with Telecom Subscriber Insights today
Telecom Subscriber Insights features a very simple pay-as-you-go pricing model that charges only for the population of subscriber data that is analyzed. This enables customers to prove value with a proof of concept (PoC) with a small subscriber footprint before rolling it out across the entire subscriber base. Find out more about Telecom Subscriber Insights by visiting the product page, and reach out to us at telecom_subscriber_insights@google.com
AI technology is one of the fastest-growing industries in the world. One poll found that 35% of companies currently use AI and another 42% intend to use it in the future. As professional and personal life becomes increasingly more digital, employers everywhere are looking for capable programmers to develop new AI algorithms that will help improve efficiency and address some of our most pressing needs
Not only are AI software developer jobs ubiquitous, but they are also well paying. Programming salaries routinely rank among the top 10-15% in the United States. In this article, we take a look at what the AI software development landscape looks like in 2023. We also touch on what it takes to get a job in this exciting field.
High Need
The need for software developers is on pace to grow by 25% over the next decade. Why? Well, there are many reasons, but the biggest is that digital technology is growing in prominence every year. Advances in AI technology have played a huge role in this trend. In October, Gaurav Tewari of the Forbes Business Council reported that AI breakthroughs have had a monumental impact on modern business and consumer life. Tewari pointed out that “OpenAI’s GPT-3 or similar autoregressive language models that use deep learning to create human-like text.”
We have also recently seen the potential of AI art, as tools like NightCafe and StarryAI have started producing incredible new images. One poll found that 40% of AI art developers spent their time looking for utilitarian images. AI is also helping with a number of other fields as well. Professional tech stacks grow more intricate. Household technologies become more sophisticated. Take the Internet of Things as an example. IoT technology fuses physical items with Bluetooth and software to automate household functions.
These items are growing by the BILLIONS over the next several years. Many of them are affordable and accessible to the average middle-class household.
They also all correlate with software that needs programming. And that’s just one fast-growing technology. As the world becomes increasingly digital, the need for people who understand programming will only grow. They will also discover new ways to use AI to develop software.
High Salaries
Like any supply-demand situation, the great need for software developers has increased their professional value. Salaries are on the rise, and can easily approach $200 thousand for experienced developers.
Even entry-level positions hover around six figures. It’s lucrative and rewarding work for people who usually enter the field with a burning passion for all things programming.
A Remote Possibility
It’s also worth mentioning that software developer expectations have shifted in recent years. Where once you may have needed to go to work at a physical location, it is becoming increasingly common for software developers to work from home.
This owes largely to Covid-19, which saw many business owners learning the value of getting to reduce their overhead by getting out of all their expensive office leases.
It’s good for you as well. It means that you can find work anywhere. While once you might have needed to limit your search to places that were accessible by car (or wrestle with the idea of moving) you can now search for jobs all over the world. And as an added bonus, you get to avoid commuting, which can easily save you an hour or more each day.
Accessibility
All of that is nice, you think. For my brother Steve, who is more than happy to become another one of the 71% of software developers who are male. But what about me, Stephania?
We understand your pain, Stephania. It’s true. The tech industry has overwhelmingly favored men in the past. This is true even as AI software becomes more popular. There’s no stated rule keeping women out, but the numbers don’t lie. Females are the stark minority, and reports of toxic work environments suggest that there is a deep cultural issue contributing to the problem.
The numbers are improving. Female and minority entry into AI development and other tech-related fields is at the highest it has ever been. This is thanks largely to the proliferation of outreach and scholarship opportunities. However, it is fair to say that the industry has a long way to go.
Be the change you want to see in the world, Stepania. There are a great number of scholarships that can help you start your journey to becoming a software developer today.
A Disruptive Technology?
Last year, a competitor going by the name of “AlphaCode” made headlines after performing in several coding competitions. AlphaCode consistently finished in the middle of the pack, outperforming 50% of the other competitors both in terms of accuracy and speed.
Well, this AlphaCode sounds like something of an up and comer, sure, but why hand out headlines to a C student?
Its name — AlphaCode — probably gives the reveal away. But thanks for being a good sport. AlphaCode isn’t a person.
What? You can’t be serious!
It’s an AI program designed by a team at DeepMind. And it’s true that AlphaCode’s outcomes were a mixed bag. If a human competitor entered ten competitions and finished in the middle each time, you’d probably figure them to be of average ability. Not remarkable. Not terrible. Just efficient.
But even a “just efficient,” AI program that can write code, and learn to get better could be very disruptive. Will this technology disrupt all of those exciting career forecasts we discussed in the above headlines?
Not anytime soon. In fact, DeepMind never intended for their creation to put people out of work. They openly acknowledge that AlphaCode will most likely need human supervision for many years to come.
It’s anticipated to exist as a tool. Something that speeds up coding work, allowing software developers to focus on more big-picture, creative issues.
Of course, if wishes and buts were candy and nuts, then every day would be Christmas. It’s possible that improved automation may reduce the number of developer jobs that are needed going forward.
The good news — for you at least — is that this scenario isn’t likely to play out for some time. People reading this article contemporaneous to its publication are entering a receptive job market for AI developers full of opportunities and high salaries. Software developers can even create their own AI software development businesses.
Although there are plenty of tech jobs out there at the moment thanks to the tech talent gap and the Great Resignation, for people who want to secure competitive packages and accelerate their software development career with sought-after java jobs, a knowledge of deep learning or AI could help you to stand out from the rest.
The world of technology is changing at an alarming rate, and AI is something that those in the tech world must embrace and move with in order to stay in the game. So, can using deep learning to write code help you to stand out as a software developer?
What is Deep Learning?
Deep Learning is a concept that first arose in 2006, with Geoffrey Hinton’s DNNs (Deep Neural Networks) training concept. The learning potential of deep learning was further demonstrated by AlphaGo in 2016 and, today, it is used increasingly to create high level software engineering (SE) tools. In a nutshell, deep learning teaches machines and robots to “think” like humans and to learn by example.
Deep learning is achieved when data is run through layers of neural network algorithms. At each layer, information is processed and simplified before being passed onto the next. As such, there is space for deep learning to enable a machine or robot to “learn” information about data that has a few hundred features. However, if information has a large volume of features or columns, or if data is unstructured, the process become prohibitively cumbersome.
Using deep learning to write code
Any software developer will be able to tell you that it can take years to learn to write computer code effectively. Akin to learning another language, coding requires absolute precision and a deep understanding of the task at hand, and how to achieve the desired response.
If deep learning allows a robot or machine to think and learn across a specific set of data in the same way that humans can, there is potential for the process of creating code to be vastly simplified by AI, or deep learning.
Across industries, there is a current of fear that AI will take over our jobs. From content writers to coders, murmurings that AI might one day be able to do what we do, in a fraction of the time, is either concerning or an unrealistic possibility, depending on the type of person that you are.
Exercising caution
While deep learning most certainly has its place within the advancing world of software development, at the present time, it is still vital that the process is undertaken by a software developer who uses deep learning or AI to assist in the process. As with many ground-breaking technological advances, although the potential may be clear, blind faith could lead to significant problems, including breaches in security. Just as a human can make errors in judgement, so can AI. And in the case of deep learning, the information learnt through the process is only as good as its original data source; one small anomaly or lapse in quality could lead to significant coding errors.
Another drawback of deep learning to write code is that, if the code has not been originated by a software developer, they could be at risk of committing plagiarism. After all, if your deep learning algorithms learn a set of processes, it stands to reason that, given the same data, someone else’s will, too.
Achieving the balance
In a fast-moving world, it always pays to have a knowledge of the latest advances, so that they can be explored to their limits while future proofing processes. It is possible to offset the risks of code creation via deep learning by implementing an effective review process which could include code quality testing through all stages of development or assigning a larger team to undertake review processes. What is clear is that vigilance is important; while deep learning undoubtedly has huge potential in making coding and software development more effective, unlike humans, AI isn’t accountable to a team and could make potentially catastrophic errors if entirely unsupervised.
Conclusion
When it comes to writing code, deep learning can help you to produce more accurate code, more quickly. Therefore, it is of clear benefit for a software developer to be able to, or at least open to, using deep learning to write code. Failure to do so could result in being left behind as the industry continues to move forwards at a remarkable pace. However, deep learning isn’t the be all and end all for those looking to develop their software career.
In order to secure competitive python or java jobs, it is necessary to have a strong skillset as well as a broader understanding of what the future of coding may hold. One way to determine what skills it is worth investing in gaining is to work with a tech recruiter, who will have a good feel of what organizations in the industry expect today, and what they are likely to demand of their employees in the future.
Consider the case of an organization that has accumulated a lot of data, stored in various databases and applications. Producing analytics reports takes a long time because of the complexity of the data storage. The team decides to replicate all the data to BigQuery in order to increase reporting efficiency. Traditionally this would be a large, complex and costly project that can take a long time to complete.
Instead of painstakingly setting up replication for each data source, the team can now use Datastream and Terraform. They compile a list of data sources, create a few configuration files according to the organization’s setup, and voila! Replication begins and data starts to appear in BigQuery within minutes.
Datastream is Google Cloud’s serverless and easy-to-use change data capture and replication service. If you are unfamiliar with Datastream, we recommend this post for a high-level overview, or read our latest Datastream for BigQuery launch announcement.
Terraform is a popular Infrastructure as code (IaC) tool. Terraform enables infrastructure management through configuration files, which makes management safer, more consistent and easily automatable.
Launched in mid February 23’, the Terraform support in Datastream unblocks and simplifies some exciting use cases, such as:
Policy compliance management – Terraform can be used to enforce compliance and governance policies on the resources that teams provision.
Automated replication process – Terraform can be used to automate Datastream operations. This can be useful when you need automated replication, replication from many data sources, or replication of a single data source to multiple destinations.
Using Terraform to set up Datastream replication from PostgreSQL to BigQuery
Let’s look at an example where the data source is a PostgreSQL database, and review the process step by step.
Limitations
Datastream will only replicate data to the BigQuery data warehouse configured in the same Google Cloud project as Datastream, so make sure that you create Datastream resources in the same project you want your data in.
Requirements
Datastream API needs to be enabled on the project before we continue. Go to the API & Services page in the Google Cloud console, and make sure that the Datastream API is enabled.
It’s possible to follow the steps in this blog with either a MySQL or Oracle database with a few slight modifications. Just skip the Postgres configuration section, and use our MySQL or Oracle configuration guides instead.
You will naturally need a Postgres database instance with some initial data. If you want to set up a new Postgres instance, you can follow the steps in the Cloud SQL for Postgres quickstart guide.
We will need to make sure that PostgreSQL is configured for replication with Datastream. This includes enabling logical replication and optionally creating a dedicated user for Datastream. See our PostgreSQL configuration guide. Make sure to note the replication slot and publication names from this step, as we will need them to configure the replication later on.
You will also need to set up connectivity between your database and Datastream. Check the Network connectivity options guide, and find the connectivity type that fits your setup.
Configuring the replication with Terraform
We will start by creating Datastream Connection Profiles, which store the information needed to connect to the source and destination (e.g. hostname, port, user, etc.).
To do this, we will start by creating a new .tf file in an empty directory, and adding the following configurations to it:
In this example, we create a new Connection Profile that points to a Postgres instance. Edit the configuration with your source information and save it. For other sources and configurations see the Terraform Datastream Connection Profile documentation.
Next, let’s define the Connection Profile for the BigQuery destination:
We now have the source and destination configured, and are ready to configure the replication process between them. We will do that by defining a Stream, which is a Datastream resource representing the source and destination replication.
In this configuration, we are creating a new Stream and configuring the source and destination Connection Profiles and properties. Some features to note here:
Backfill ( backfill_all ) – means that Datastream will replicate an initial snapshot of historical data. This can be configured to exclude specific tables.
Replicating a subset of the source – you can specify which data should be included or excluded from the Stream using the include / exclude lists – see more in the API docs
Edit the configuration with the source Postgres publication and replication slot that you created in the initial setup. For other sources and configurations see the Terraform Stream documentation.
Running the Terraform configuration
Now that we have our configuration ready, it’s time to run it with the Terraform CLI. For that, we can use Cloud Shell which has terraform CLI installed and configured with the permissions needed for your project.
code_block[StructValue([(u’code’, u’terraform {rn required_providers {rn google = {rn source = “hashicorp/google”rn version = “4.53.0”rn }rn }rn}rnrnprovider “google” {rn credentials = file(“PATH/TO/KEY.json”)rn project = “PRROJECT_ID”rn region = “us-central1″rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e4c8f799d10>)])]
Start by running the terraform init command to initialize terraform in your configuration directory. Then run the terraform plan command to check and validate the configuration.
Now lets run terraform apply to apply the new configuration
If all went well, you should now have a running Datastream Stream! Go to the Datastream console to manage your Streams, and to the BigQuery console and check that the appropriate data sets were created.
When you’re done, you can use terraform destroy to remove the created Datastream resources.
Something went wrong?
You can set: export TF_LOG=DEBUG flag to see debug logs for the Terraform CLI. See Debugging Terraform for more.
Automating multiple replications
To automate terraform configurations, we can make use of input variables, the count argument and the element function. A simple variable that holds a sources list can look like this:
code_block[StructValue([(u’code’, u’variable “sources” {rn type = list(object({rn name = stringrn hostname = stringrn …rn publication = stringrn replication_slot = stringrn }))rn}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e4c8f799650>)])]
Add a count field to the resources you want to automate (source, stream and maybe destination). Replace values from the variable to:
In the digital age, online brands constantly look for ways to improve their branding and stay ahead of the competition. Data mining technology is one of the most effective ways to do this. By analyzing data and extracting useful insights, brands can make informed decisions to optimize their branding strategies.
This article will explore data mining and how it can help online brands with brand optimization.
What is Data Mining?
Data mining deals with extracting useful insights and patterns from large data sets. It involves using statistical algorithms and machine learning techniques to identify trends and patterns in the data that would otherwise be difficult to detect.
Data mining can analyze various data types, including customer demographics, purchase behavior, website traffic, and social media engagement.
How Data Mining Helps Brand with Brand Optimization
Identifying customer preferences and behavior: Data mining can help brands better understand customers’ preferences and behavior. By analyzing customer data, brands can identify trends, patterns, and correlations that reveal valuable insights. For example, a brand may use data mining to determine which products are most popular among certain demographic groups or which marketing campaigns are most effective at driving sales.
1. Improving Customer Engagement
By analyzing customer data, brands can gain insights into how to improve customer engagement. For example, data mining can help identify which types of content are most effective at engaging customers or which channels are most popular for customer engagement. Brands can use this information to tailor their content and communication strategies to better engage with customers.
2. Conducting Backlink Audits for SEO Link Building
Data mining can provide a way to analyze a brand’s backlink profile, which is essential for search engine optimization (SEO). By doing backlink audits for SEO link building, brands can identify which links are helping or hurting their SEO efforts. This information can be used to conduct a backlink audit and identify opportunities to improve the brand’s backlink profile.
3. Monitoring Brand Reputation
Data mining can be used to monitor a brand’s reputation online. By analyzing social media mentions, customer reviews, and other forms of online feedback, brands can identify trends and patterns that reveal potential issues or areas for improvement. With this knowledge, a brand can know precisely where to focus resources to improve its reputation.
4. Predicting Customer Churn
Data mining can be used to predict which customers are at risk of leaving a brand. By analyzing customer behavior and engagement data, brands can identify patterns that indicate a customer is likely to churn. This information can be used to take proactive measures to retain these customers and improve the brand’s customer retention rate.
5. Social Media Listening
By data mining social media platforms, brands can gain insights into their customers’ interests, preferences, and opinions. The insights can be used to tailor marketing campaigns and develop products that align with their customers’ needs, enhancing the brand’s reputation and increasing customer loyalty.
6. Fraud Detection
Data mining can identify fraudulent activities, such as fake reviews or social media accounts. This helps brands protect their reputations by ensuring their products or services are not associated with dishonest or unethical practices.
7. Competitor Analysis
By analyzing data on competitors’ products, marketing strategies, and customer feedback, brands can identify opportunities to differentiate themselves in the market. This can include developing new products, improving customer service, or adjusting pricing strategies, which can help enhance the brand’s reputation and attract new customers.
8. Supply Chain Optimization
By mining data on the supply chain, brands can identify areas for improvement, such as reducing waste, improving efficiency, or enhancing product quality. These improvements can help enhance the brand’s reputation by ensuring its products are produced and distributed ethically and sustainably.
9. Personalized Marketing
By mining customer behavior and preference data, brands can develop personalized marketing campaigns tailored to each individual’s needs and interests. This can increase customer engagement, loyalty, and satisfaction, enhancing the brand’s reputation.
Pro Tip: Make Privacy a Priority
Data mining can help organizations make informed decisions and gain valuable insights. However, it can also expose individuals to risks if their privacy is not protected.
When an organization collects data from customers or employees, they are responsible for safeguarding that information and ensuring that it is only used for the purposes for which it was collected.
Data mining algorithms can analyze data in ways that may lead to the identification of individuals, even when steps are taken to protect their privacy during the collection process. This can lead to the misuse of personal information for purposes such as identity theft or unwanted marketing.
To address privacy concerns and ethical issues, organizations should seek the guidance of privacy and ethics experts from the beginning of any data mining project. These experts can help ensure that personal information is collected and used in ways that respect individual privacy and avoid any unintended consequences. They can also advise on the best data storage, sharing, and retention practices to minimize the risk of data breaches and other privacy violations.
Organizations that engage in data mining initiatives involving personal information should prioritize privacy concerns and involve privacy and ethics experts in their projects to protect individuals and avoid ethical problems.
Conclusion
Data mining is a powerful tool for online brands looking to optimize their branding strategies. By analyzing customer data, backlink profiles, online feedback, and other forms of data, brands can gain valuable insights that inform their decision-making processes.
Whether improving customer engagement, conducting backlink audits for SEO, or monitoring brand reputation, data mining technology can help online brands stay ahead of the competition and achieve their branding goals.
The renewable energy sector is undergoing a major transformation thanks to the power of big data. With its ability to collect, store, and analyze vast amounts of data in real-time, big data offers unprecedented insights into how we generate and use energy.
This has enabled companies in the renewable energy sector to develop innovative solutions that are helping us move toward a more sustainable future.
Let’s find out how big data is changing the renewable energy sector and what it holds for us!
Big data is a term used to refer to the massive amount of data that organizations collect and analyze to gain insights into their operations – it can be collected from various sources such as
Customer feedback
Transactional records
Sensor readings
Social media posts
Search queries, etc…
All these combined forms a data set that can be used to make informed decisions based on the analysis of correlations, trends, and patterns.
In simple words, big data is a way to turn raw data into actionable insights, which is what makes it so powerful.
Understanding how big data works
Just as we have discussed above, big data is used to collect and analyze vast amounts of data in real time. This allows companies to understand consumer behavior better and also optimize their processes as well as operations.
Also, the analysis of big data can help identify patterns that would otherwise go overlooked. This way, organizations can discover new opportunities and develop strategies accordingly.
Big data also allows organizations to get a better understanding of their operations. For example, energy companies can track energy usage and identify areas where efficiency can be improved.
For example, Tesla powerwall can collect data from their solar panels to monitor the production and consumption of electricity in real time. Tesla powerwall can then be used to optimize energy consumption by providing customers with customized recommendations.
Top 3 ways big data is changing the renewable energy sector
So now that we know one or two things about big data let’s find out how it is changing the renewable energy sector:
1. Improved Efficiency
Big data analysis can help identify areas where efficiency can be improved in renewable energy systems, such as reducing wastage and optimizing output. This will increase the overall profitability of renewable energy businesses and make them more competitive.
This helps both parties (seller and buyer) as they can save on energy costs and use the saved money to invest in other projects or initiatives.
The increasing cost of traditional energy sources has made renewable energy more attractive, and the use of big data can assist in making it even more efficient. It will not only make renewable energy more viable but also make it a much more attractive option for buyers.
2. Predicting Demand and Supply
Big data can also be used to predict the demand and supply of renewable energy.
By analyzing historical data, companies can get a better understanding of the current demand for different types of renewable energy resources and thereby adjust their production accordingly.
This way they can target a specific customer base, which will lead to more conversions and ultimately better profits. Similarly, customers will get what they want so it’s a win-win situation for everyone involved.
In addition to predicting demand and supply, big data can also be used to forecast the weather which will help companies plan their production of renewable energy resources.
For example, the Tesla powerwall can predict the weather and adjust its energy production accordingly.
3. Automation
Finally, the biggest benefit of big data in the renewable energy sector is automation. By automating certain processes, companies can save time and resources while making their operations more efficient.
For example, some solar panel systems can be connected to the internet and programmed to adjust their output based on real-time weather conditions.
This way, customers can reduce their electricity bills by producing more energy when the weather is good, and less when it isn’t.
On the other hand, companies can also use big data to automate the maintenance of their renewable energy systems. By analyzing real-time data, they can detect any issues and address them quickly before they become major problems.
Conclusion
Overall, big data is having a huge impact on the renewable energy sector. It is helping make renewable energy more efficient, predicting demand and supply better, and automating certain processes. As technology continues to develop, big data will likely become an even more important part of the renewable energy sector in the future.
Many customers build streaming data pipelines to ingest, process and then store data for later analysis. We’ll focus on a common pipeline design shown below. It consists of three steps:
1. Data sources send messages with data to a Pub/Sub topic.
2. Pub/Sub buffers the messages and forwards them to a processing component.
3. After processing, the processing component stores the data in BigQuery.
For the processing component, we’ll review three alternatives, ranging from basic to advanced:
A. BigQuery subscription.
B. Cloud Run service.
C. Dataflow pipeline.
Example use cases
Before we dive deeper into the implementation details, let’s look at a few example use cases of streaming data pipelines:
Processing ad clicks. Receiving ad clicks, running fraud prediction heuristics on a click-by-click basis, and discarding or storing them for further analysis.
Canonicalizing data formats. Receiving data from different sources, canonicalizing them into a single data model, and storing them for later analysis or further processing.
Capturing telemetry. Storing user interactions and displaying real-time statistics, such as active users, or the average session length grouped by device type.
Keeping a change data capture log. Logging all database updates from a database to BigQuery through Pub/Sub.
Ingesting data with Pub/Sub
Let’s start at the beginning. You have one or multiple data sources that publish messages to a Pub/Sub topic. Pub/Sub is a fully-managed messaging service. You publish messages, and Pub/Sub takes care of delivering the messages to one or many subscribers. The most convenient way to publish messages to Pub/Sub is to use the client library.
To authenticate with Pub/Sub you need to provide credentials. If your data producer runs on Google Cloud, the client libraries take care of this for you and use the built-in service identity. If your workload doesn’t run on Google Cloud, you should use identity federation, or as a last resort, download a service account key (but make sure to have a strategy to rotate these long-lived credentials).
Three alternatives for processing
It’s important to realize that some pipelines are straightforward, and some are complex. Straightforward pipelines don’t do any (or lightweight) processing before persisting the data. Advanced pipelines aggregate groups of data to reduce data storage requirements and can have multiple processing steps.
We’ll cover how to do processing using either one of the following three options:
A BigQuery subscription, a no-code pass-through solution that stores messages unchanged in a BigQuery dataset.
A Cloud Run service, for lightweight processing of individual messages without aggregation.
A Dataflow pipeline, for advanced processing (more on that later).
Approach 1: Storing data unchanged using a BigQuery subscription
The first approach is the most straightforward one. You can stream messages from a Pub/Sub topic directly into a BigQuery dataset using a BigQuery subscription. Use it when you’re ingesting messages and don’t need to perform any processing before storing the data.
When setting up a new subscription to a topic, you select the Write to BigQuery option, as shown here:
The details of how this subscription is implemented are completely abstracted away from users. That means there is no way to execute any code on the incoming data. In essence, it is a no-code solution. That means you can’t apply filtering on data before storing.
You can also use this pattern if you want to first store, and perform processing later in BigQuery. This is commonly referred to as ELT (extract, load, transform).
Tip: One thing to keep in mind is that there are no guarantees that messages are written to BigQuery exactly once, so make sure to deduplicate the data when you’re querying it later.
Approach 2: Processing messages individually using Cloud Run
Use Cloud Run if you do need to perform some lightweight processing on the individual messages before storing them. A good example of a lightweight transformation is canonicalizing data formats – where every data source uses its own format and fields, but you want to store the data in one data format.
Cloud Run lets you run your code as a web service directly on top of Google’s infrastructure. You can configure Pub/Sub to send every message as an HTTP request using a push subscription to the Cloud Run service’s HTTPS endpoint. When a request comes in, your code does its processing and calls the BigQuery Storage Write API to insert data into a BigQuery table. You can use any programming language and framework you want on Cloud Run.
As of February 2022, push subscriptions are the recommended way to integrate Pub/Sub with Cloud Run. A push subscription automatically retries requests if they fail and you can set a dead-letter topic to receive messages that failed all delivery attempts. Refer to handling message failures to learn more.
There might be moments when no data is submitted to your pipeline. In this case, Cloud Run automatically scales the number of instances to zero. Conversely, it scales all the way up to 1,000 container instances to handle peak load. If you’re concerned about costs, you can set a maximum number of instances.
It’s easier to evolve the data schema with Cloud Run. You can use established tools to define and manage data schema migrations like Liquibase. Read more on using Liquibase with BigQuery.
For added security, set the ingress policy on your Cloud Run microservices to be internal so that they can only be reached from Pub/Sub (and other internal services), create a service account for the subscription, and only give that service account access to the Cloud Run service. Read more about setting up push subscriptions in a secure way.
Consider using Cloud Run as the processing component in your pipeline in these cases:
You can process messages individually, without requiring grouping and aggregating messages.
You prefer using a general programming model over using a specialized SDK.
You’re already using Cloud Run to serve web applications and prefer simplicity and consistency in your solution architecture.
Tip: TheStorage Write APIis more efficient than the older insertAll method because it uses gRPC streaming rather than REST over HTTP.
Approach 3: Advanced processing and aggregation of messages using Dataflow
Cloud Dataflow, a fully managed service for executing Apache Beam pipelines on Google Cloud, has long been the bedrock of building streaming pipelines on Google Cloud. It is a good choice for pipelines that aggregate groups of data to reduce data and those that have multiple processing steps. Cloud Dataflow has a UI that makes it easier to troubleshoot issues in multi-step pipelines.
In a data stream, grouping is done using windowing. Windowing functions group unbounded collections by the timestamps. There are multiple windowing strategies available, including tumbling, hopping and session windows. Refer to the documentation on data streaming to learn more.
Cloud Dataflow is geared toward massive scale data processing. Spotify notably uses it to compute its yearly personalized Wrapped playlists. Read this insightful blogpost about the 2020 Wrapped pipeline on the Spotify engineering blog.
Dataflow can autoscale its clusters both vertically and horizontally. Users can even go as far as using GPU powered instances in their clusters and Cloud Dataflow will take care of bringing new workers into the cluster to meet demand, and also destroy them afterwards when they are no longer needed.
Tip: Cap the maximum number of workers in the cluster to reduce cost and set up billing alerts.
Which approach should you choose?
The three tools have different capabilities and levels of complexity. Dataflow is the most powerful option and the most complex, requiring users to use a specialized SDK (Apache Beam) to build their pipelines. On the other end, a BigQuery subscription doesn’t allow any processing logic and can be configured using the web console. Choosing the tool that best suits your needs will help you get better results faster.
For massive (Spotify scale) pipelines, or when you need to reduce data using windowing, or have a complex multi-step pipeline, choose Dataflow. In all other cases, starting with Cloud Run is best, unless you’re looking for a no-code solution to connect Pub/Sub to BigQuery. In that case, choose the BigQuery subscription.
Cost is another factor to consider. Cloud Dataflow does apply automatic scaling, but won’t scale to zero instances when there is no incoming data. For some teams, this is a reason to choose Cloud Run over Dataflow.
This comparison table summarizes the key differences.
I’d like to thank my co-author Graham Polley from Zencore for his contributions to this post – find him on LinkedIn or Twitter. I also want to thank Mete, Sara, Jakob, Valentin, Guillaume, Sean, Kobe, Christopher, Jason, and Wei for their review feedback.






{kind=link}
{kind=link}
{kind=link}
{kind=link}