BigQuery BI Engine is a fast, in-memory analysis system for BigQuery currently processing over 2 billion queries per month and growing. BigQuery has its roots in Google’s Dremel system and is a data warehouse built with scalability as a goal. On the other hand BI Engine was envisioned with data analysts in mind and focuses on providing value on Gigabyte to sub-Terabyte datasets, with minimal tuning, for real time analytics and BI purposes.
Using BI Engine is simple – create a memory reservation on the project that runs BigQuery queries, and it will cache data and use the optimizations. This post is a deep dive into how BI Engine helps deliver blazing fast performance for your BigQuery queries and what users can do to leverage its full potential.
BI Engine optimizations
The two main pillars of BI Engine are in-memory caching of data and vectorized processing. Other optimizations include CMETA metadata pruning, single-node processing, and join optimizations for smaller tables.
Vectorized engine
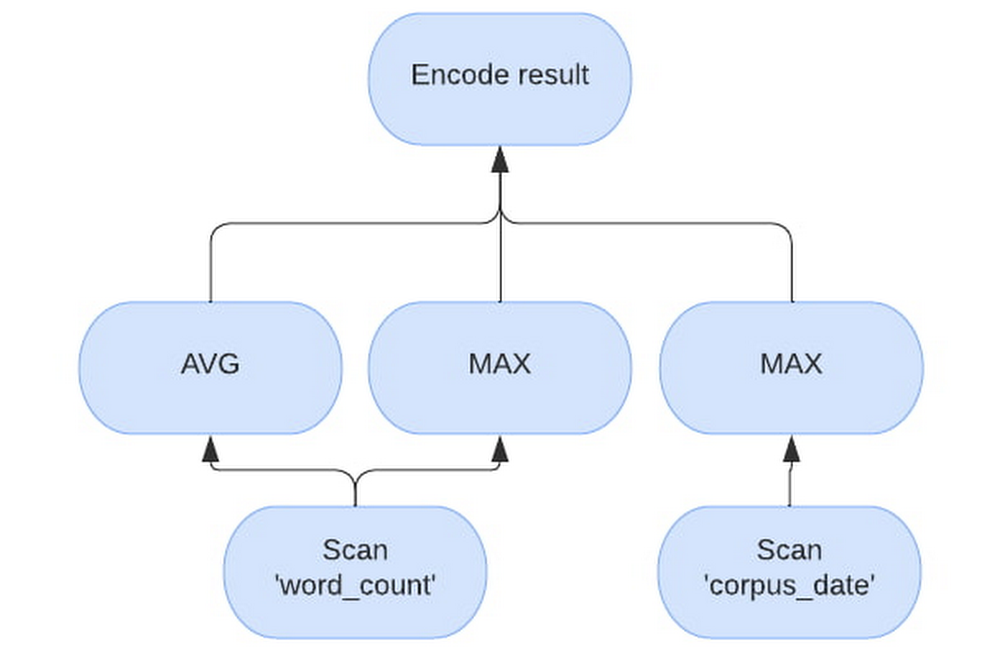
BI Engine utilizes the “Superluminal” vectorized evaluation engine which is also used for YouTube’s analytic data platform query engine – Procella. In BigQuery’s row-based evaluation, the engine will process all columns within a row for every row. The engine is potentially alternating between column types and memory locations before going to the next row. In contrast, a vectorized engine like Superluminal will process a block of values of the same type from a single column for as long as possible and only switch to the next column when necessary. This way, hardware can run multiple operations at once using SIMD, reducing both latency and infrastructure costs. BI Engine dynamically chooses block size to fit into caches and available memory.
For the example query, “SELECT AVG(word_count), MAX(word_count), MAX(corpus_date) FROM samples.shakespeare”, will have the following vectorized plan. Note how the evaluation processes “word_count” separately from “corpus_date”.
In-memory cache
BigQuery is a disaggregated storage and compute engine. Usually the data in BigQuery is stored on Google’s distributed file system – Colossus, most often in blocks in Capacitor format and the compute is represented by Borg tasks. This enables BigQuery’s scaling properties. To get the most out of vectorized processing, BI Engine needs to feed the raw data at CPU speeds, which is achievable only if the data is already in memory. BI Engine runs Borg tasks as well, but workers are more memory-heavy to be able to cache the data as it is being read from Colossus.
A single BigQuery query can be either sent to a single BI Engine worker, or sharded and sent to multiple BI Engine workers. Each worker receives a piece of a query to execute with a set of columns and rows necessary to answer it. If the data is not cached in the workers memory from the previous query, the worker loads the data from Colossus into local RAM. Subsequent requests for the same or subset of columns and rows are served from memory only. Note that workers will unload the contents if data hasn’t been used for over 24 hours. As multiple queries arrive, sometimes they might require more CPU time than available on a worker, if there is still reservation available, a new worker will be assigned to same blocks and subsequent requests for the same blocks will be load-balanced between the workers.
BI Engine can also process super-fresh data that was streamed to the BigQuery table. Therefore, there are two formats supported by BI Engine workers currently – Capacitor and streaming.
In-memory capacitor blocks
Generally, data in a capacitor block is heavily pre-processed and compressed during generation. There are a number of different ways the data from the capacitor block can be cached, some are more memory efficient, while others are more CPU efficient. BI Engine worker intelligently chooses between those preferring latency and CPU-efficient formats where possible. Thus actual reservation memory usage might not be the same as logical or physical storage usage due to the different caching formats.
In-memory streaming data
Streaming data is stored in memory as blocks of native array-columns and is lazily unloaded when blocks get extracted into Capacitor by underlying storage processes. Note that for streaming, BI workers need to either go to streaming storage every time to potentially obtain new blocks or serve slightly stale data. BI Engine prefers serving slightly stale data and loading the new streaming blocks in the background instead.
BI Engine worker does this opportunistically during the queries, if the worker detects streaming data and the cache is newer than 1 minute, a background refresh is launched in parallel with the query. In practice, this means that with enough requests the data is no more stale than the previous request time. For example if a request arrives every second, then the streaming data will be around a second stale.
First requests loading data are slow
Due to the read time optimizations, loading data from previously unseen columns can take longer than BigQuery does. Subsequent reads will benefit from these optimizations.
For example, the query above here is backend time for a sample run of the same query with BI Engine off, first run and subsequent run.
Multiple block processing and dynamic single worker execution
BI Engine workers are optimized for BI workloads where the output size will be small compared to the input size and the output will be mostly aggregated. In regular BigQuery execution, a single worker tries to minimize data loading due to network bandwidth limitations. Instead, BigQuery relies on massive parallelism to complete queries quickly. On the other hand, BI Engine prefers to process more data in parallel on a single machine. If the data has been cached, there is no network bandwidth limitation and BI Engine further reduces network utilization by reducing the number of intermediate “shuffle” layers between query stages.
With small enough inputs and a simple query, the entire query will be executed on a single worker and the query plan will have a single stage for the whole processing. We constantly work on making more tables and query shapes eligible for a single stage processing, as this is a very promising way to improve the latency of typical BI queries.
For the example query, which is very simple and the table is very small, here is a sample run of the same query with BI Engine distributed execution vs single node (default).
How to get most out of BI Engine
While we all want a switch that we can toggle and everything becomes fast, there are still some best practices to think about when using BI Engine.
Output data size
BI optimizations assume human eyes on the other side and that the size of output data is small enough to be comprehensible by a human. This limited output size is achieved by selective filters and aggregations. As a corollary, instead of SELECT * (even with a LIMIT), a better approach will be to provide the fields one is interested in with an appropriate filter and aggregation.
To show this on an example – query “SELECT * FROM samples.shakespeare” processes about 6MB and takes over a second with both BigQuery and BI Engine. If we add MAX to every field – “SELECT MAX(word), MAX(word_count), MAX(corpus), MAX(corpus_date) FROM samples.shakespeare”, both engines will read all of the data, perform some simple comparisons and finish 5 times faster on BigQuery and 50 times faster on BI Engine.
Help BigQuery with organizing your data
BI Engine uses query filters to narrow down the set of blocks to read. Therefore, partitioning and clustering your data will reduce the amount of data to read, latency and slot usage. With a caveat, that “over partitioning” or having too many partitions might interfere with BI Engine multi-block processing. For optimal BigQuery and BI Engine performance, partitions larger than one gigabyte are preferred.
Query depth
BI Engine currently accelerates stages of the query that read data from the table, which are typically the leaves of the query execution tree. What this means in practice is that almost every query will use some BigQuery slots.That’s why one gets the most speedup from BI Engine when a lot of time is spent on leaf stages. To mitigate this, BI Engine tries to push as many computations as possible to the first stage. Ideally, execute them on a single worker, where the tree is just one node.
For example Query1 of TPCH 10G benchmark, is relatively simple. It is 3 stages deep with efficient filters and aggregations that processes 30 million rows, but outputs just 1.
Running this query in BI Engine we see that the full query took 215 ms with “S00: Input” stage being the one accelerated by BI Engine taking 26 ms.
Running the same query in BigQuery gets us 583ms, with “S00: Input” taking 229 ms.
What we see here is that the “S00: Input” stage run time went down 8x, but the overall query did not get 8x faster, as the other two stages were not accelerated and their run time remained roughly the same. With breakdown between stages illustrated by the following figure.
In a perfect world, where BI Engine processes its part in 0 milliseconds, the query will still take 189ms to complete. So the maximum speed gain for this query is about 2-3x.
If we, for example, make this query heavier on the first stage, by running TPCH 100G instead, we see that BI Engine finishes the query 6x faster than BigQuery, while the first stage is 30 times faster!
vs 1 second on BigQuery
Over time, our goal is to expand the eligible query and data shapes and collapse as many operations as feasible into a single BI Engine stage to realize maximum gains.
Joins
As previously noted, BI Engine accelerates “leaf” stages of the query. However, there is one very common pattern used in BI tools that BI Engine optimizes. It’s when one large “fact” table is joined with one or more smaller “dimension” tables. Then BI Engine can perform multiple joins, all in one leaf stage, using so-called “broadcast” join execution strategy.
During the broadcast join, the fact table is sharded to be executed in parallel on multiple nodes, while the dimension tables are read on each node in their entirety.
For example, let’s run Query 3 from the TPC-DS 1G benchmark. The fact table is store_sales and the dimension tables are date_dim and item. In BigQuery the dimension tables will be loaded into shuffle first, then the “S03: Join+” stage will, for every parallel part of store_sales, read all necessary columns of two dimension tables, in their entirety, to join.
Note that filters on date_dim and item are very efficient, and the 2.9M row fact table is joined only with about 6000 rows. BI Engine plan will look a bit different, as BI Engine will cache the dimension tables directly, but the same principle applies.
For BI Engine, let’s assume that two nodes will process the query due to the store_sales table being too big for a single node processing. We can see on the image below that both nodes will have similar operations – reading the data, filtering, building the lookup table and then performing the join. While only a subset of data for the store_sales table is being processed on each, all operations on dimension tables are repeated.
Note that
“build lookup table” operation is very CPU intensive compared to filtering
“join” operation performance also suffers if the lookup tables are large, as it interferes with CPU cache locality
dimension tables need to be replicated to each “block” of fact table
The takeaway is when join is performed by BI Engine, the fact table is sometimes split into different nodes. All other tables will be copied multiple times on every node to perform the join. Keeping dimension tables small or selective filters will help to make sure join performance is optimal.
Conclusions
Summarizing everything above, there are some things one can do to make full use of BI Engine and make their queries faster
Less is more when it comes to data returned – make sure to filter and aggregate as much data as possible early in the query. Push down filters and computations into BI Engine.
Queries with a small number of stages get the best acceleration. Preprocessing the data to minimize query complexity will help with optimal performance. For example, using materialized views can be a good option.
Joins are sometimes expensive, but BI Engine may be very efficient in optimizing typical star schema queries.
Arvind Ltd has been in the apparel industry for more than 90 years, with its retail powerhouse Arvind Fashions Ltd being the backbone of well-known names in the retail fashion industry in India.
Arvind Fashions Ltd (Arvind) has seen significant growth in its portfolio with new franchises being added every year. The six high conviction brands include Tommy Hilfiger, Calvin Klein, Sephora, Arrow, U.S. Polo Assn. & Flying Machine.
To secure a foundation for future growth, the company has embarked on a digital transformation (DX) journey, focusing on profitability and improving the customer experience. The key objectives for Arvind’s DX is to unlock the value of existing applications, gain new insights, and build a solid workflow with resilient systems.
Getting Google Cloud to address the challenges around insights & analytics was a natural step forward, since Arvind had already formed a relationship with Google Cloud, starting with its productivity and collaboration tools during the pandemic.
Key Challenges
Arvind’s enterprise applications estate is a mix of SAP, Oracle POS, logistics management systems and other applications. Having so many different applications made it a challenge for the company to bring all of this data together to drive retail insights and at the same time maintain the freshness of its products.
As a case in point, the existing sales reporting and inventory reconciliation process had been enabled by a mix of automated and semi-automated desktop applications. There were challenges to scale the infrastructure in order to process large amounts of data at a low latency.
The synchronization of master data across functions was critical to build the data platform that provides consistent insights to multiple stakeholders across the organization.
Solution Approach – Modern Data Platform
There are several ways to solve the challenges above and do more by building a modern data analytics platform. For example, using a data lake based approach that builds use case by use case, hybrid data estates and so on. Regardless of the approach, it is important to define the solution based on certain principles.
In Arvind’s scenario, the key business principles considered are that data platforms should support Variety, Variability, Velocity and Volume. Each of these 4 V’s are critical business pivots to successful fashion retailing. Variety in SKU’s to deal with myriad fashion trends every season, Variability in shopping footfalls due to different festivities, weekends and special occasions, Velocity to be agile and responsive to customer needs, and Volumes of data that bring richer insights.
This is where Google BigQuery enabled data platform comes in, as it is able to meet the needs above.
Solution Architecture – Current Capabilities & Future Vision
BigQuery is the mothership of the data and analytics platform on Google Cloud. Its serverless construct ensures that data engineering teams focus only on insights & analytics. Storage and compute is decoupled and can be independently scaled. BigQuery has been leveraged to service both the raw as well as the curated data zones.
With BigQuery procedures, it is possible to process the data natively within the data warehouse itself. Procedures have been leveraged to process the data in a low latency manner with the familiar SQL.
But then what happens to advanced analytics and insights? With simplicity being our key guiding principle, BigQuery machine learning ensures that data analysts can create, train and deploy analytics models even with complex requirements. It can also consume data from Looker Studio, which is seamlessly integrated with BigQuery.
Here are the key principles and highlights of the data platform that have been achieved:
Simple, yet exhaustive – We needed a solution with vast technical capabilities such as data lake & data warehouse, data processing, data consumption, analytics amongst others. And at the same time it needed to be simple to implement and run ongoing operations.
Agility – High quality analytics use cases typically require a significant amount of time, effort and skill set. While building a simple solution we ensured that the selection of technology services ensured agility in the long term.
Security – An organization can be truly successful if the insights and analytics operations are democratized. But while data is made available to a wider community, we need to ensure data governance and security.
Ease of operations – Data engineering teams spend a lot of time doing infrastructure setting and management operations. With BigQuery, teams can put in more effort on building the data pipelines and models to feed into analytics instead of worrying about the infrastructure operations.
Costs – Decoupling storage and compute allows for flexible pricing. A pay-as-you-go model is the ideal solution to managing costs.
Business Impact
The ingestion frequency of the store level inventory (~800 stores) has now been changed to daily. With the additional data volumes and processing the scaling on BigQuery has been seamless. There are new processes and dashboards to address the reconciliation and root cause analysis. Operational efficiencies have improved leading to better productivity and turn around time of critical processes.
The discrepancies in various reconciliation activities have drastically reduced by an order of magnitude of 300X due to the capabilities offered by the data platform. Not only is it possible to identify discrepancies but the data platform has also enabled in identifying the root causes for the same as well.
Arvind Fashions Ltd have also been able to enhance some of the existing business processes and systems with insight from the data platform.
It’s going to be an exciting journey for Arvind Fashions Ltd and Google Cloud. There are several initiatives ready for kick off such as getting more apps on the edge devices, warehouse analytics, advanced customer data platforms, predicting the lifecycle of designs, style codes and other exciting initiatives.
Editor’s note: The post is part of a series highlighting our partners, and their solutions, that are Built with BigQuery.
Background and Context
A Customer Data Platform (CDP) provides a monolithic view of the customer by collecting data from various sources to provide accessibility across different systems. CDPs are becoming increasingly vital as companies look to improve customer experience, engagement and personalization. Among the different CDP types, a Composable CDP commonly referred to as Deconstructed CDP distinguishes itself as it provides the flexibility and agility to customize or even interchange the components of CDP based on specific requirements such as security, governance etc. A key construct of a CDP is the identity resolution which follows a set of rules to decide how collected data is used to create a new entity or merged to an existing one.
Lytics’ composable CDP approach
Lytics is a next generation composable CDP that enables companies to deploy a scalable CDP around their existing data warehouse/lakes, without losing control over their customer data and without compromising security and privacy to thrive in a cookieless future by tracking and identifying customer behavior [how]. Lytics offers reverse ETL capabilities and the ability to deploy both private instance (Single Tenant hosted SaaS ) & private cloud (deployed fully in Customers GCP project) deployments directly into your GCP Project (VPC), Lytics’ unique data-driven approach enables enterprises to improve their data pipeline by simplifying creation of unified view , increase customer engagement by personalizing experiences and advancing interactiveness and drive more effective marketing ROI as a result of delivering more value to customers.
Challenges in Data Sharing and Clean Rooms
More and more organizations have identified the benefits of securely sharing and organizing customer data as a means to improve business performance. Critical in the use case is the need to suppress PII during the process of enrichment while fully enabling data dependent teams, such as BI (Business Intelligence), Data Analysts, and Data Scientist, to stitch and enrich the data from multiple sources, while avoiding the risk of exposing any sensitive data.
As data sharing/clean rooms go become more prevalent, a set of new challenges need to be addressed namely:
Data residing in silos across different sources needs a method for relating two disparate sets of data to each other, identifiers, enabling the creation of a single view of the customer and all related attributes. A traditional solution such as an identity matching solution using a hashed identifier in the source data and customer’s dataset can help mitigate the technical challenge.
Latencies while working with a data warehouse and exchange can directly impact the agility for business teams to make real-time decisions. It is key to minimize the latencies in long running workflows
Ever changing security, compliance, and regulation requirements can create major roadblocks and drastically slow down or prevent a businesses ability to engage with their customers.
Flexibility is a must. Partners, vendors, and everyone in between provide a wide variety of requirements to navigate which prevents rigid, traditional, solutions from being viable.
Solution: Lytics on Google Cloud
Lytics chose to build on Google Cloud because of its desire to leverage the Google Data Cloud, with BigQuery at the core, to offer this necessary infrastructure and scalability which unlocks Google Cloud AI/ML capabilities for enhanced entity identification using a unique identifier to stitch a user profile, enrichment of first-party data with external sources, and ultimately highly targeted audience segments built from multiple behavioral factors and proprietary engagement based behavioral scores. In addition to BigQuery, the Lytics solution integrates with a variety of Google Cloud products including Google Cloud Pub/Sub, Google Kubernetes Engine (GKE). Also, Lytics’ First-Party Modeled Audiences is powered by Google, a one-of-a-kind solution that expands the reach of existing Google Ads audiences by accessing YouTube’s user data via a Lytics/Google proprietary API to create the Modeled Audiences using Google Tag Manager and Google Ads products.
Lytics and Google have been developing a scalable and repeatable offering for securely sharing data which utilizes Google Cloud (BigQuery) and the Lytics Platform. BigQuery’s capabilities have enabled use cases from data aggregation, data analysis, data visualization, and activation, all of which are able to be executed with extremely low-latency. Furthermore, with the introduction of Analytics Hub, Lytics is now able to offer their own Data Clean Room solution on Google Cloud for Advertisers and Media built from the collaboration including Lytics, BigQuery, and Google Cloud Analytics Hub. The Lytics Data Clean Room offers a range of features for managing and processing data, including ingestion, consolidation, enrichment, stitching, and entity resolution. This solution’s privacy centric data enablement utilizes Google’s exchange level permissions as well as leverages the ability to unify data without the necessity of exposing PII, thereby allowing customers to leverage data across their organization, while avoiding data duplication and limiting privacy risks.
Lytics Conductor’s strength is in its ability to collect and unify first-party datasets into customer profiles followed by its hosting in Google Cloud and integrating with BigQuery. The integration with BigQuery makes Lytics Conductor an ideal application to simplify and unlock data sharing by unifying and coalescing datasets that helps businesses to build or expand existing BigQuery data warehouses.
Lytics Conductor fuels Analytics Hub to create master data Exchanges for intra and inter sharing within organizations that house hundreds of listings to focus on secure, controlled consumption of critical datasets for Partners, Parent and child brands.
Lytics Cloud Connect, Lytics’ reverse-ETL product, closes the activation loop by easily and securely associating this new data set with individual customer profiles. This enables further segmentation and activation across hundreds of out-of-the-box, real-time integrations with mission-critical marketing tools.
The key features of the solution are:
Gather and aggregate data from multiple data sources
Construct unified customer profiles using industry-leading identity resolution capabilities
Develop or augment BigQuery warehouse with event and profiles synchronization by coalescing data across systems
Build Data exchanges and Listings using Analytics Hub in a scalable, reliable and secure manner for both internal and external Partner consumption
Activate segments across critical marketing channels
Solution Architecture
Below is a block diagram of how Lytics, BigQuery, and Google Cloud Analytics Hub work together to power the solution:
Data sources (batch and stream) map to a pre-built schema managed by Conductor.
Conductor provides a vast ecosystem of pre-built connectors and APIs unify disparate data sources into profiles, which are delivered to BigQuery. These profiles are the core foundation of first-party data to build the customer 360 view.
Analytics Hub helps in creating, publishing and searching listings, which is a subset of profiles and their attributes consumable as datasets. Analytics Hub establishes a natural data flow from producer to a consumer with a low-code, no-code solution.
Cloud Connect consumes the listings via its inherent ability to use standard SQL to model data for direct activation across channel tools or enrichment of unified profiles in Conductor.
Conductor directly interfaces with Decision Engine to build and explore segments of unified profiles.
Cloud Connect and Decision Engine allow for direct activation of either SQL based data models or audience segments.
The joint partnership between Google Cloud and Lytics has yielded a highly scalable and secure solution with tighter control of mission critical data for faster activation. The real-time streaming capability of BigQuery contributes widely to the rapid activations. The solution is more repeatable and reachable as it builds on Lytics functionality and Google Cloud infrastructure. In addition, it can be future proof In the wake of stringent privacy constraints, industry compliance standards and newer regulations.
How Lytics and Google Cloud are Better Together
The Lytics and Google Cloud story is one of collaboration and innovation on behalf of our current and future joint customer’s.
Built on Google Cloud, Lytics is able to leverage the power of Google processing speeds and capabilities with no technical lift from the customer. Lytics Conductor and Google Analytics hub are able to provide complementary capabilities improving data management needs on behalf of our joint customers focusing on getting maximum value out of data. In particular, the capabilities and power of Analytics Hub and BigQuery have helped decrease the time to value in complex data sharing scenarios where partnership collaboration is safe and secure and cross brand activation can be done in hours rather than days or even weeks
Lytics is a long-standing partner with Google Cloud; the Lytics platform has exclusive and total residency built on GCP. There are no retrofits to the solution described above and it is uniquely positioned to seamlessly integrate GCP features with minimal to no technical lift for our joint customers. The solution described above is available today. Google Cloud provides Lytics a means to enable forward thinking data strategies, future proofing solutions with a Privacy Forward approach to data management, unparalleled global scale and access to the greatest technical team in the industry.
Click here to learn more about Lytics’ CDP capabilities or to request a demo.
The Built with BigQuery advantage for ISVs
Google is helping tech companies like Lytics build innovative Solutions on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs through the Built with BigQuery initiative, launched in April as part of the Google Data Cloud Summit. Participating companies can:
Get started fast with a Google-funded, pre-configured sandbox.
Accelerate product design and architecture through access to designated experts from the ISV Center of Excellence who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable data warehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. And with a huge partner ecosystem and support for multi-cloud, open source tools and APIs, Google provides technology companies the portability and extensibility they need to avoid data lock-in.
We thank the Google Cloud and Lytics team members who co-authored the blog: Lytics: Kelsey Abegg, Senior Product Manager. Google: Sujit Khasnis, Solutions Architect & Bala Desikan, Principal Architect
Today we announce the Dataplex business glossary, now available in public preview. Dataplex is an intelligent data fabric that provides a way to manage, monitor, and govern your distributed data at scale. Dataplex business glossary offers users a cloud-native way to maintain and manage their business terms and definitions, establishing consistent business language, improving trust in data, and enabling self-serve use of data.
In enterprises, small, medium, or large, there are many different teams. Each team, over time, develops its own language. For example, for a corporate team, “customer” could mean “legal entity,” whereas for the central platform team, it could be individuals/legal entities/government entities, etc. This dissonance can lead to collaboration challenges and, worse, to misinterpretation of data and affect insights and decisions. This dissonance also prevents users unfamiliar with the area from having a self-service path, leaving them dependent on tribal knowledge in the organization. Navigating it introduces manual overhead and makes it hard to stay updated with changes.
With Dataplex business glossary, users can now :
capture their business terminology within glossaries and terms
enrich cataloged data entries with this business terminology by attaching defined terms to data entry columns
describe semantic relationships between terms by establishing cross-term associations.
Dataplex business glossary supports data practitioners in several ways. Firstly, it promotes semantic consistency in defining and interpreting data across teams, which helps to minimize redundancy and reduce the possibility of confusion and misinterpretation when consuming data. For example, with a centrally curated definition of the term ‘retail transaction,’ when two teams produce two different data assets capturing details of retail transactions, they would structure these data assets consistently according to the defined terminology.
Semantic consistency,in turn, reinforces understanding of and trust in data. When attached to data assets, glossary terms provide an additional layer of centrally curated and consistent business context that allows users to confidently establish the degree to which the data assets fit for their purpose. In the above example of customer data, an analyst searching for “show me all customer tables” does not have to worry about varying interpretations for identified data assets, i.e., whether they refer to personal customers or legal entities, etc. With business glossary, the correct interpretation is established via associated glossary terms which provide the required context for these data assets and allow the analyst to identify the relevance of discovered data more reliably.
All the above then unlocks self-serve use of data, allowing users to leverage glossary content to discover data assets (e.g. through search queries like “Show me all entries which attached glossary terms referencing ‘retail transaction’ anywhere in their definitions” – note how search can address varying term metadata, including descriptions and associated Data Stewards, when identifying data assets), understand the semantics of these data assets, and consequently – identify applicable usage scenarios for these data assets.
Additionally, Dataplex business glossary can support data governance, with data governance teams using glossary context for informing data governance policy configuration decisions. For example, these teams can consider data assets associated with glossary terms referencing “customer” for additional access control policies related to customer data handling.
In summary, you can leverage the Dataplex business glossary alongside the broad set of Dataplex data governance capabilities to enable users to establish a common and consistent business language, strengthen trust in data, promote self-serve use, and get value from your data.
How do I get started?
To get started with Dataplex business glossary, visit the Glossaries tab in Dataplex. You can capture business terminology by defining glossaries, terms, and cross-term relationships.
You can then associate cataloged entries with defined terms as you browse data entries in Dataplex Search.
Once glossary content is defined and associated with data entries, you can leverage glossary content in discovery and search.
Today’s leading organizations want to ensure their business users get fast access to data with real-time governed metrics, so they can make better business decisions. Last April, we announced our unified BI experience, bringing together both self-serve and governed BI. Now, we are making our Looker connector to Looker Studio generally available, enabling you to access your Looker modeled data in your preferred environment.
Connecting people to answers quickly and accurately to empower informed decisions is a primary goal for any successful business, and more than ten million users turn to Looker each month to easily explore and visualize their data from hundreds of different data sources. Now you can join the many Google Cloud customers who have benefited from early access to this connector by connecting your data in a few steps.*
How do I turn on the integration between Looker and Looker Studio?
You can connect to any Google Cloud-hosted Looker instance immediately after your Looker admin turns on its Looker Studio integration.
Once the integration is turned on, you create a new Data Source, select the Looker connector, choose an Explore in your connected Looker instance, and start analyzing your modeled data.
You can explore your company’s modeled data in the Looker Studio report editor and share results with other users in your organization.
When can I access the Looker connector?
The Looker connector is now available for Looker Studio, and Looker Studio Pro, which includes expanded enterprise support and compliance.
* A Google Cloud-hosted Looker instance with Looker 23.0 or higher is required to use the Looker connector. A Looker admin must enable the Looker Studio BI connector before users can access modeled data in Looker Studio.
Data is one of the single most valuable assets for organizations today. It can empower businesses to do incredible things like create better views of health for hospitals, enable people to share timely insights with their colleagues, and — increasingly — be a foundational building block for startups who build their products and businesses in a data cloud.
Last year, we shared that more than 800 software companies are building their products and businesses with Google’s data cloud. Many of these are fast-growing startups. These companies are creating entirely new products with technologies like AI, ML and data analytics that help their customers turn data into real-time value. In turn, Google’s data cloud and services like Google BigQuery, Cloud Storage, and Vertex AI are helping startups build their own thriving businesses.
We’re committed to supporting these innovative, fast-growing startups and helping them grow within our open data cloud ecosystem. That’s why today, I’m excited to share how three innovative data companies – Ocient, SingleStore, and Glean – are now building on Google’s data cloud as they grow in the market and deliver scalable data solutions to more customers around the world.
Founded in 2016, Ocient is a hyperscale data warehousing and analytics startup that is helping enterprises analyze and gain real-time value from trillions of data records by enabling massively parallelized processing in a matter of seconds. By designing its data warehouse architecture with compute adjacent to storage on NVMe solid state drives, continuous ingest on high-volume data sets, and intra-database ELT and machine learning, Ocient’s technology enables users to transform, load, and analyze otherwise infeasible data queries at 10x-100x the price performance of other cloud data warehouse providers. To help more enterprises scale their data intelligence to drive business growth, Ocient chose to bring its platform to Google Cloud’s flexible and scalable infrastructure earlier this year via Google Cloud Marketplace. In addition to bringing its solution to Google Cloud Marketplace, Ocient is using Google Cloud technologies including Google Cloud Storage for file loading, Google Compute Engine (GCE) for running its managed hyperscale data analytics solutions, and Google Cloud networking tools for scalability, increased security, and for analyzing hyperscale sets data with greater speed. In just three months, Ocient more than doubled its Google Cloud usage in order to support the transformation workloads of enterprises on Google Cloud.
Another fast-growing company that recently brought its solution to Google Cloud Marketplace to reach more customers on Google Cloud’s scalable, secure, and global infrastructure is SingleStore. Built with developers and database architects in mind, SingleStore helps companies provide low-latency access to large datasets and simplify the development of enterprise applications by bringing transactions and analytics in a single, unified data engine (SingleStoreDB). Singlestore integrates with Google Cloud services to enable a scalable and highly available implementation. In addition to growing its business by reaching more customers on Google Cloud Marketplace, SingleStore is today announcing the establishment of its go-to-market strategy with Google Cloud, which will further enable them to deliver their database solution to customers around the world.
I’m also excited to share how Glean is leveraging our solutions to scale its business and support more customers. Founded in 2019, Glean is a powerful, unified search tool built to search across all deployed applications at an organization. Glean’s platform understands context, language, behavior, and relationships, which in turn enables users to find personalized answers to questions, instantly. To achieve this, the Glean team built its enterprise search and knowledge discovery product with Google managed services, including Cloud SQL and Kubernetes, along with solutions from Google Cloud like our Vertex AI, Dataflow, Google BigQuery. By creating its product with technologies from Google Cloud, Glean has the capabilities needed to be agile and iterate quickly. This also gives Glean’s developer team more time to focus on developing the core application aspects of its product, like relevance, performance, ease of use, and delivering a magical search experience to users. To support the growing needs of enterprises and bring its product to more customers at scale, Glean is today announcing its formal partnership with Google Cloud and the availability of its product on Google Cloud Marketplace.
We’re proud to support innovative startups with the data cloud capabilities they need to help their customers thrive and to build and grow their own businesses, and we’re committed to providing them with an open and extensible data ecosystem so they can continue helping their customers realize the full value of their data.
A collaboration between Google Cloud and NVIDIA has enabled Apache Beam users to maximize the performance of ML models within their data processing pipelines, using NVIDIA TensorRTand NVIDIA GPUs alongside the new Apache Beam TensorRTEngineHandler.
The NVIDIA TensorRT SDK provides high-performance, neural network inference that lets developers optimize and deploy trained ML models on NVIDIA GPUs with the highest throughput and lowest latency, while preserving model prediction accuracy. TensorRT was specifically designed to support multiple classes of deep learning models, including convolutional neural networks (CNNs), recurrent neural networks (RNNs), and Transformer-based models.
Deploying and managing end-to-end ML inference pipelines while maximizing infrastructure utilization and minimizing total costs is a hard problem. Integrating ML models in a production data processing pipeline to extract insights requires addressing challenges associated with the three main workflow segments:
Preprocess large volumes of raw data from multiple data sources to use as inputs to train ML models to “infer / predict” results, and then leverage the ML model outputs downstream for incorporation into business processes.
Call ML models within data processing pipelines while supporting different inference use-cases: batch, streaming, ensemble models, remote inference, or local inference. Pipelines are not limited to a single model and often require an ensemble of models to produce the desired business outcomes.
Optimize the performance of the ML models to deliver results within the application’s accuracy, throughput, and latency constraints. For pipelines that use complex, computate-intensive models for use-cases like NLP or that require multiple ML models together, the response time of these models often becomes a performance bottleneck. This can cause poor hardware utilization and requires more compute resources to deploy your pipelines in production, leading to potentially higher costs of operations.
Google Cloud Dataflow is a fully managed runner for stream or batch processing pipelines written with Apache Beam. To enable developers to easily incorporate ML models in data processing pipelines, Dataflow recently announced support for Apache Beam’s generic machine learning prediction and inference transform, RunInference. The RunInference transform simplifies the ML pipeline creation process by allowing developers to use models in production pipelines without needing lots of boilerplate code.
You can see an example of its usage with Apache Beam in the following code sample. Note that the engine_handler is passed as a configuration to the RunInference transform, which abstracts the user from the implementation details of running the model.
Along with the Dataflow runner and the TensorRT engine, Apache Beam enables users to address the three main challenges. The Dataflow runner takes care of pre-processing data at scale, preparing the data for use as model input. Apache Beam’s single API for batch and streaming pipelines means that RunInference is automatically available for both use cases. Apache Beam’s ability to define complex multi-path pipelines also makes it easier to create pipelines that have multiple models. With TensorRT support, Dataflow now also has the ability to optimize the inference performance of models on NVIDIA GPUs.
Editor’s note: Six customers, across a range of industries, share their success stories with Google Cloud databases.
From professional sports leagues to kidney care and digital commerce, Google Cloud databases enable organizations to develop radically transformative experiences for their users. The stories of how Google Cloud Databases have helped Box, Credit Karma, Davita, Forbes, MLB, and PLAID build data-driven applications is truly remarkable – from unifying data lifecycles for intelligent applications, to reducing, and even eliminating operational burden. Here are some of the key stories that customers shared at Google Cloud Next.
Box modernizes its NoSQL databases with zero downtime with Bigtable
A content cloud, Box enables users to securely create, share, co-edit, and retain their content online. While moving its core infrastructure from on-premises data centers to the cloud, Box chose to migrate its NoSQL infrastructure to Cloud Bigtable. To fulfill the company’s user request needs, the NoSQL infrastructure has latency requirements measured in tens of milliseconds. “File metadata like location, size, and more, are stored in a NoSQL table and accessed at every download. This table is about 150 terabytes in size and spans over 600 billion rows. Hosting this on Bigtable removes the operational burden of infrastructure management. Using Bigtable, Box gains automatic replication with eventual consistency, an HBase-compliant library, and managed backup and restore features to support critical data.” Axatha Jayadev Jalimarada, Staff Software Engineer at Box, was enthusiastic about these Bigtable benefits, “We no longer need manual interventions by SREs to scale our clusters, and that’s been a huge operational relief. We see around 80 millisecond latencies to Bigtable from our on-prem services. We see sub-20 millisecond latencies from our Google Cloud resident services, especially when the Bigtable cluster is in the same region. Finally, most of our big NoSQL use cases have been migrated to Bigtable and I’m happy to report that some have been successfully running for over a year now.”
Credit Karma deploys models faster with Cloud Bigtable and BigQuery
Credit Karma, a consumer technology platform helping consumers in the US, UK and Canada make financial progress, is reliant on its data models and systems to deliver a personalized experience for its nearly 130 million members. Given its scale, Credit Karma recognized the need to cater to the growing volume, complexity, and speed of data, and began moving its technology stack to Google Cloud in 2016.
UsingCloud Bigtable andBigQuery, Credit Karma registered a 7x increase in the number of pre-migration experiments, and began deploying 700 models/week compared to 10 per quarter. Additionally, Credit Karma was able to push recommendations through its modeling scoring service built on a reverse extract, transform, load, (ETL) process on BigQuery, Cloud Bigtable andGoogle Kubernetes Engine. Powering Credit karma’s recommendations are machine learning models at scale — the team runs about 58 billion model predictions each day.
Looking to learn “what’s next for engineers”? Check outthe conversation between Scott Wong, and Andi Gutmans, General Manager and Vice President of Engineering for Databases at Google.
DaVita leverages Spanner and BigQuery to centralize health data and analytics for clinician enablement
As a leading global kidney care company, DaVita spans the gamut of kidney care from chronic kidney disease to transplants. As part of its digital transformation strategy, DaVita was looking to centralize all electronic health records (EHRs) and related care activities into a single system that would not only embed work flows, but also save clinicians time and enable them to focus on their core competencies. Jay Richardson, VP, Application Development at DaVita, spoke to the magnitude of the task, “Creating a seamless, real-time data flow across 600,000 treatments on 200,000 patients and 45,000 clinicians was a tall engineering order.” The architecture was set up in Cloud Spanner housing all the EHRs and related-care activities, and BigQuery handling the analytics. Spanner change streams replicated data changes to BigQuery with a 75 percent reduction in time for replication–from 60 to 15 seconds-enabling both, simplification of the integration process, as well as, a highly scalable solution. DaVita also gained deep, relevant, insights–about 200,000 a day–and full aggregation for key patient meds and labs data. This helps equip physicians with additional tools to care for their patients, without inundating them with numbers.
Forbes fires up digital transformation with Firestore
A leading media and information company, Forbes is plugged into an ecosystem of about 140 million—employees, contributors, and readers—across the globe. It recently underwent a successful digital transformation effort to support its rapidly scaling business. This included a swift, six-month migration to Google Cloud, and integrating with the full suite of Google Cloud products from BigQuery to Firestore—a NoSQL document database. Speaking of Firestore, Vadim Supitskiy, Chief Digital & Information Officer at Forbes, explained, “We love that it’s a managed service, we do not want to be in the business of managing databases. It has a flexible document model, which makes it very easy for developers to use and it integrates really, really, well with the products that GCP has to offer.” Firestore powers the Forbes insights and analytics platform to give its journalists and contributors comprehensive, real-time suggestions that help content creators author relevant content, and analytics to assess the performance of published articles. At the backend, Firestore seamlessly integrates with Firebase Auth, Google Kubernetes Engine, Cloud Functions, BigQuery, and Google Analytics, while reducing maintenance overheads. As a cloud-native database that requires no configuration or management, it’s cheap to store data in, and executes low-latency queries
Minh Nguyen, Senior Product Manager at Google cloud, discusses “serverless application development with a document database” with Vadim Supitskiyhere.
MLB hits a home run by moving to Cloud SQL
When you think ofMajor League Baseball (MLB), you think of star players and home runs. But as Joseph Zirilli, senior software engineer at MLB explained, behind-the-scenes technology is critical to the game, whether it is the TV streaming service, or on-field technology to capture statistics data. And that’s a heavy lift, especially when MLB was running its player scouting and management system for player transactions on a legacy, on-premises database. This, in combination with the limitations of conventional licensing, was adversely impacting the business. The lack of in-house expertise in the legacy database, coupled with its small team size, made routine tasks challenging.
Having initiated the move to Google Cloud a few years ago, MLB was already using Cloud SQL for some of its newer products. It was also looking to standardize its relational database management system around PostgreSQL so it could build in-house expertise around a single database. They selected Cloud SQL which supported their needs, and also offered high availability and automation.
Today, with drastically improved database performance and automatic rightsizing of database instances, MLB is looking forward to keeping its operational costs low and hitting it out of the park for fan experience.
Major League Baseball trademarks and copyrights are used with permission of Major League Baseball. Visit MLB.com.
PLAID allies with AlloyDB to enhance the KARTE website and native app experience for customer engagement
PLAID, a Tokyo-based startup hosts KARTE, an engagement platform focused on customer experience that tracks the customer in real time, supports flexible interactions, and provides wide analytics functionality. To support hybrid transactional and analytical processing (HTAP) at scale, KARTE was using a combination of BigQuery, Bigtable, and Spanner in the backend. This enabled KARTE to process over 100,000 transactions per second, and store over 10 petabytes of data. Adding AlloyDB for PostgreSQL to the mix has provided KARTE with the ability to answer flexible analytical queries. In addition to the range of queries that KARTE can now handle, AlloyDB has brought in expanded capacity with low-latency analysis in a simplified system. As Yuki Makino, CTO at PLAID pointed out, “With the current (columnar) engine and AlloyDB performance is about 100 times faster than earlier.”
Yuki Makino, in conversation with Sandy Ghai, Product Manager at Google Cloud, says “goodbye, expensive legacy database, hello next-gen PostgreSQL database” here.
Implement a modern database strategy
Transformation hinges on new cloud database capabilities. Whether you want to increase your agility and pace of innovation, better manage your costs, or entirely shut down data centers, we can help you accelerate your move to cloud. From integration into a connected environment, to disruption-free migration, and automation to free up developers for creative work, Google Cloud databases offer unified, open, and intelligent building blocks to enable a modern database strategy.
Download the complimentary 2022 Gartner Magic Quadrant for Cloud Database Management Systems report.
Master data is a holistic view of your key business entities, providing a consistent set of identifiers and attributes that give context to the business data that matters most to your organization. It’s about ensuring that clean, accurate, curated data – the best available – is accessible throughout the company to manage operations and make critical business decisions. Having well-defined master data is essential to running your business operations.
Master data undergoes a far more enriched and refined process than other types of data captured across the organization. For instance, it’s not the same as the transactional data generated by applications. Instead, master data gives context to the transaction itself by providing the fundamental business objects – like the Customer, Product, Patient, or Supplier – on which the transactions are performed.
Without master data, enterprise applications are left with potentially inconsistent data living in disparate systems; with an unclear picture of whether multiple records are related. And without it, gaining essential business insight may be difficult, if not impossible, to attain: for example, “which customers generate the most revenue?” or “which suppliers do we do the most business with?”
Master data is a critical element of treating data as an enterprise asset and as a product.. A data product strategy requires that the data remain clean, integrated, and freshly updated with appropriate frequency. Without this additional preparation and enrichment, data becomes stale and incomplete, leading to inability to provide the necessary insights for timely business decisions. Data preparation, consolidation and enrichment should be a part of a data product strategy, since consolidating a complete set of external data sources will provide more complete and accurate insights for business decisions. This data preparation, consolidation and enrichment requires the right infrastructure, tools, and processes, otherwise it will be an additional burden on already thinly stretched data management teams. .
This is why it is necessary to adopt and implement a next-generation master data management platform that enables a data product strategy to be operationalized. This in turn enables the acquisition of trusted records to drive business outcomes.
The Challenge: A Single Source of Truth – The Unified “Golden” Record
Many companies have built or are working on rolling out data lakes, lake houses, data marts, or data warehouses to address data integration challenges. However, when multiple data sets from disparate sources are combined, there is a high likelihood of introducing problems , which Tamr and Google Cloud are partnering to address and alleviate:
Data duplication: same semantic/physical entity like customer with different keys
Inconsistency: same entity having partial and/or mismatching properties (like different phone numbers or addresses for the same customers)
Reduced insight accuracy: duplicates skew the analytic key figures (like total distinct customers are higher with duplicates than without them)
Timeliness impact: manual efforts to reach a consistent and rationalized core set of data entities used for application input and analytics cause significant delays in processing and ultimately, decision making
Solution
Tamr is the leader in data mastering and next-generation master data management, delivering data products that provide clean, consolidated, and curated data to help businesses stay ahead in a rapidly changing world. Organizations benefit from Tamr’s integrated, turn-key solution that combines machine learning with humans-in-the-loop, a low-code/no-code environment, and integrated data enrichment to streamline operations. The outcome is higher quality data; faster and with less manual work
Tamr takes multiple source records, identifies duplicates, enriches data, assigns a unique ID, and provides a unified, mastered “golden record” while maintaining all source information for analysis and review. Once cleansed, data can be utilized in the downstream analytics and applications, enabling more informed decisions.
A successful data product strategy requires consistently cleaning and integrating data, a task that’s ideal for data mastering. machine-learning based capabilities in a data mastering platform can handle increases in data volume and variety, as well as data enrichment to ensure that the data stays fresh and accurate so it can be trusted by the business consumers.
With accurate key entity data, companies can unlock the bigger picture of data insights. The term “key” signifies entities that are most important to an organization. For example, for healthcare organizations, this could mean patients and providers; for manufacturers, it could mean suppliers; for financial services firms, it could mean customers.
Below are examples of key business entities after they’ve been cleaned, enriched, and curated with Tamr:
Better Together: How Tamr leverages Google Cloud to differentiate their next-gen MDM
Tamr Mastering, a template-based SaaS MDM solution, is built on Google Cloud Platform technologies such as Cloud Dataproc, Cloud Bigtable and BigQuery, allowing customers to scale modern data pipelines with excellent performance while controlling costs.
The control plane (application layer) is built on Google Compute Engine (GCE) to leverage its scalability. The data plane utilizes a full suite of interconnected Google Cloud Platform services such as Google Dataproc for distributed processing, allowing for a flexible and sustainable way to bridge the gap between the analytics powers of distributed TensorFlow and the scaling capabilities of Hadoop in a managed offering. Google Cloud Storage is used for data movement/staging.
Google Cloud Run, which enables Tamr to deploy containers directly on top of Google’s scalable infrastructure, is used in the data enrichment process. This approach allows serverless deployments without the need to create a stateful cluster or manage infrastructure to be productive with container deployments. Google Bigtable is utilized for data-scale storage, allowing for high throughput and scalability for key/value data. Data that doesn’t fall into the key/value lookup schema is retrieved in batches or used for analytical purposes. Google BigQuery is the ideal storage for this type of data and storage of the golden copy of the data discussed earlier in this blog post. Additionally, Tamr chose BigQuery as their central data storage solution due to the ability of BigQuery to promote schema denormalization with the native support of nested and repeated fields to denormalize data storage and increase query performance.
On top of that, Tamr Mastering utilizes Cloud IAM for access control, authn/authz, configuration and observability. Deploying across the Google framework provides key advantages such as better performance due to higher bandwidth, lower management overhead, and autoscaling and resource adjustment, among other value drivers, all resulting in lower TCO.
The architecture above illustrates the different layers of functionality. Starting from the top down with the front-end deployment to the core layers at the borrow of the diagram. To scale the overall MDM architecture depicted in the above diagram, efficiently, Tamr has partnered with Google Cloud to focus on three core capabilities:
Capability One: Machine learning optimized for scale and accuracy
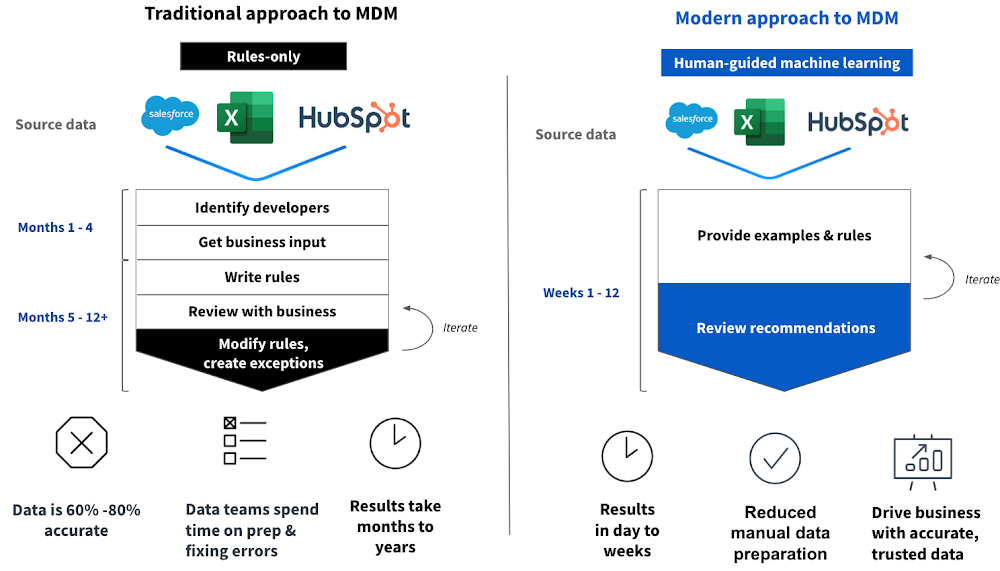
Traditionally, organizing and mastering data in most organizations’ legacy infrastructure has been done using a rules-based approach (if <condition> then <action>). Conventional rules-based systems can be effective on a small scale, relying on human-built logic implemented in the rules to generate master records. However, such rules fail to scale when tasked with connecting and reconciling large amounts of highly variable data.
Machine learning, on the other hand, becomes more efficient at matching records across datasets as more data is added. In fact, huge amounts of data (more than 1 million records across dozens of systems) provide more signal, so the machine learning models are able to identify patterns, matches, and relationships, accelerating years of human effort down to days. Google’s high performance per core on Compute Engine, high network throughput and lower provisioning times across both storage and compute are all differentiating factors in Tamr’s optimized machine learning architecture on Google Cloud.
Capability Two: Ensure there is sufficient human input
While machine learning is critical, so is keeping humans in the loop and letting them provide feedback. Engaging business users and subject matter experts is key to building trust in the data. A middle ground where machines take the lead and humans provide guidance and feedback to make the machine – and the results – better is the data mastering approach that delivers the best outcomes. Not only will human input improve machine learning models, but it will also foster tighter alignment between the data and business outcomes that require curated data.
Capability Three: Enrichment built in the workflow
As a final step in the process, data enrichment integrates internal data assets with external data to increase the value of these assets. It adds additional relevant or missing information so that the data is more complete – and thus more usable. Enriching data improves its quality, making it a more valuable asset to an organization. Combining data enrichment with data mastering means that not only are data sources automatically cleaned, they are also enhanced with valuable commercial information while avoiding the incredibly time-consuming and manual work that goes into consolidating or stitching internal data with external data.
Below is an example of how these three core-capabilities are incorporated into the Tamr MDM architecture:
Building the data foundation for connected customer experiences at P360
When a major pharmaceutical company approached P360 for help with a digital transformation project aimed at better reaching the medical providers they count as customers, P360 realized that building a solid data foundation with a modern master data management (MDM) solution was the first step.
“One of the customer’s challenges was master data management, which was the core component of rebuilding their data infrastructure. Everything revolves around data so not having a solid data infrastructure is a non-starter. Without it, you can’t compete, you can’t understand your customers and how they use your products,” said Anupam Nandwana, CEO of P360, a technology solutions provider for the pharmaceutical industry.
To develop that foundation of trusted data, P360 turned to Tamr Mastering. By using Tamr Mastering, the pharmaceutical company is quickly unifying internal and external data on millions of health care providers to create golden records that power downstream applications, including a new CRM system. Like other business-to-business companies, P360’s customer has diverse and expansive data from a variety of sources. From internal data like physician names and addresses to external data like prescription histories and claims information, this top pharmaceutical company has 150 data sources to master in order to get complete views of their customers. This includes records on 1 million healthcare providers (as well as 2 million provider addresses) and records on the more than 100,000 healthcare organizations.
“For the modern data platform, cloud is the only answer. To provide the scale, flexibility and speed that’s needed, it’s just not pragmatic to leverage other infrastructure. The cloud gives us the opportunity to do things faster. Completing this project in a short amount of time was a key criteria for success and that would have only been possible with the cloud. Using it was an easy decision,” Nandwana said.
With Tamr Mastering, P360 helped their customer master millions of provider records in weeks and create golden records containing unique customer IDs as a consistent identifier and single source of truth.
Conclusion
Google’s data cloud provides a complete platform for building data-driven applications like Tamr’s MDM solution on Google Cloud. Simplified data ingestion, processing, and storage to powerful analytics, AI, ML, and data sharing capabilities are integrated with the open, secure, and sustainable Google Cloud platform. With a diverse partner ecosystem, open-source tools, and APIs, Google Cloud can provide technology companies with a platform that provides the portability and differentiators they need to build their products and serve the next generation of customers.
Hosting, orchestrating, and managing data pipelines is a complex process for any business. Google Cloud offers Cloud Composer – a fully managed workflow orchestration service – enabling businesses to create, schedule, monitor, and manage workflows that span across clouds and on-premises data centers. Cloud Composer is built on the popular Apache Airflow open source project and operates using the Python programming language. Apache Airflow allows users to create directed acyclic graphs (DAGs) of tasks, which can be scheduled to run at specific intervals or triggered by external events.
This guide contains a generalized checklist of activities when authoring Apache Airflow DAGs. These items follow best practices determined by Google Cloud and the open source community. A collection of performant DAGs will enable Cloud Composer to work optimally and standardized authoring will help developers manage hundreds or even thousands of DAGs. Each item will benefit your Cloud Composer environment and your development process.
Get Started
1. Standardize file names. Help other developers browse your collection of DAG files. a. ex) team_project_workflow_version.py
2. DAGs should be deterministic. a. A given input will always produce the same output.
3. DAGs should be idempotent. a. Triggering the DAG multiple times has the same effect/outcome.
4. Tasks should be atomic and idempotent. a. Each task should be responsible for one operation that can be re-run independently of the others. In an atomized task, a success in part of the task means a success of the entire task.
5. Simplify DAGs as much as possible. a. Simpler DAGs with fewer dependencies between tasks tend to have better scheduling performance because they have less overhead. A linear structure (e.g. A -> B -> C) is generally more efficient than a deeply nested tree structure with many dependencies.
Standardize DAG Creation
6. Add an owner to your default_args. a. Determine whether you’d prefer the email address / id of a developer, or a distribution list / team name.
7. Use with DAG() as dag: instead of dag = DAG() a. Prevent the need to pass the dag object to every operator or task group.
8. Set a version in the DAG ID. a. Update the version after any code change in the DAG. b. This prevents deleted Task logs from vanishing from the UI, no-status tasks generated for old dag runs, and general confusion of when DAGs have changed. c. Airflow open-source has plans to implement versioning in the future.
9. Add tags to your DAGs. a. Help developers navigate the Airflow UI via tag filtering. b. Group DAGs by organization, team, project, application, etc.
10. Add a DAG description. a. Help other developers understand your DAG.
11. Pause your DAGs on creation. a. This will help avoid accidental DAG runs that add load to the Cloud Composer environment.
12. Set catchup=False to avoid automatic catch ups overloading your Cloud Composer Environment.
13. Set a dagrun_timeout to avoid dags not finishing, and holding Cloud Composer Environment resources or introducing collisions on retries.
14. Set SLAs at the DAG level to receive alerts for long-running DAGs. a. Airflow SLAs are always defined relative to the start time of the DAG, not to individual tasks. b. Ensure that sla_miss_timeout is less than the dagrun_timeout. c. Example: If your DAG usually takes 5 minutes to successfully finish, set the sla_miss_timeout to 7 minutes and the dagrun_timeout to 10 minutes. Determine these thresholds based on the priority of your DAGs.
15. Ensure all tasks have the same start_date by default by passing arg to DAG during instantiation
16. Use a static start_date with your DAGs. a. A dynamic start_date is misleading, and can cause failures when clearing out failed task instances and missing DAG runs.
17. Set retries as a default_arg applied at the DAG level and get more granular for specific tasks only where necessary. a. A good range is 1–4 retries. Too many retries will add unnecessary load to the Cloud Composer environment.
Example putting all the above together:
code_block[StructValue([(u’code’, u’import airflowrnfrom airflow import DAGrnfrom airflow.operators.bash_operator import BashOperatorrnrn# Define default_args dictionary to specify default parameters of the DAG, such as the start date, frequency, and other settingsrndefault_args = {rn ‘owner’: ‘me’,rn ‘retries’: 2, # 2-4 retries maxrn ‘retry_delay’: timedelta(minutes=5),rn ‘is_paused_upon_creation’: True,rn ‘catchup’: False,rn}rnrn# Use the `with` statement to define the DAG object and specify the unique DAG ID and default_args dictionaryrnwith DAG(rn ‘dag_id_v1_0_0′, #versioned IDrn default_args=default_args,rn description=’This is a detailed description of the DAG’, #detailed descriptionrn start_date=datetime(2022, 1, 1), # Static start datern dagrun_timeout=timedelta(minutes=10), #timeout specific to this dagrn sla_miss_timeout=timedelta(minutes=7), # sla miss less than timeoutrn tags=[‘example’, ‘versioned_dag_id’], # tags specific to this dagrn schedule_interval=None,rn) as dag:rn # Define a task using the BashOperatorrn task = BashOperator(rn task_id=’bash_task’,rn bash_command=’echo “Hello World”‘rn )’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e853b802f10>)])]
18. Define what should occur for each callback function. (send an email, log a context, message slack channel, etc.). Depending on the DAG you may be comfortable doing nothing. a. success b. failure c. sla_miss d. retry
Example:
code_block[StructValue([(u’code’, u’from airflow import DAGrnfrom airflow.operators.python_operator import PythonOperatorrnrndefault_args = {rn ‘owner’: ‘me’,rn ‘retries’: 2, # 2-4 retries maxrn ‘retry_delay’: timedelta(minutes=5),rn ‘is_paused_upon_creation’: True,rn ‘catchup’: False,rn}rnrndef on_success_callback(context):rn # when a task in the DAG succeedsrn print(f”Task {context[‘task_instance_key_str’]} succeeded!”)rnrndef on_sla_miss_callback(context):rn # when a task in the DAG misses its SLArn print(f”Task {context[‘task_instance_key_str’]} missed its SLA!”)rnrndef on_retry_callback(context):rn # when a task in the DAG retriesrn print(f”Task {context[‘task_instance_key_str’]} retrying…”)rnrndef on_failure_callback(context):rn # when a task in the DAG failsrn print(f”Task {context[‘task_instance_key_str’]} failed!”)rnrn# Create a DAG and set the callbacksrnwith DAG(rn ‘dag_id_v1_0_0′,rn default_args=default_args,rn description=’This is a detailed description of the DAG’,rn start_date=datetime(2022, 1, 1), rn dagrun_timeout=timedelta(minutes=10),rn sla_miss_timeout=timedelta(minutes=7),rn tags=[‘example’, ‘versioned_dag_id’],rn schedule_interval=None,rn on_success_callback=on_success_callback, # what to do on successrn on_sla_miss_callback=on_sla_miss_callback, # what to do on sla missrn on_retry_callback=on_retry_callback, # what to do on retryrn on_failure_callback=on_failure_callback # what to do on failurern) as dag:rnrn def example_task(**kwargs):rn # This is an example task that will be part of the DAGrn print(f”Running example task with context: {kwargs}”)rnrn # Create a task and add it to the DAGrn task = PythonOperator(rn task_id=”example_task”,rn python_callable=example_task,rn provide_context=True,rn )’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e853b355650>)])]
code_block[StructValue([(u’code’, u’# Use the `with` statement to define the DAG object and specify the unique DAG ID and default_args dictionaryrnwith DAG(rn ‘example_dag’,rn default_args=default_args,rn schedule_interval=timedelta(hours=1),rn) as dag:rn # Define the first task grouprn with TaskGroup(name=’task_group_1′) as tg1:rn # Define the first task in the first task grouprn task_1_1 = BashOperator(rn task_id=’task_1_1′,rn bash_command=’echo “Task 1.1″‘,rn dag=dag,rn )’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e853b3553d0>)])]
Reduce the Load on Your Composer Environment
20. Use Jinja Templating / Macros instead of python functions. a. Airflow’s template fields allow you to incorporate values from environment variables and jinja templates into your DAGs. This helps make your DAGs idempotent (meaning multiple invocations do not change the result) and prevents unnecessary function execution during Scheduler heartbeats. b. The Airflow engine passes a few variables by default that are accessible in all templates.
Contrary to best practices, the following example defines variables based on datetime Python functions:
code_block[StructValue([(u’code’, u”# Variables used by tasksrn# Bad example – Define today’s and yesterday’s date using datetime modulerntoday = datetime.today()rnyesterday = datetime.today() – timedelta(1)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e853b355090>)])]
If this code is in a DAG file, these functions execute on every Scheduler heartbeat, which may not be performant. Even more importantly, this doesn’t produce an idempotent DAG. You can’t rerun a previously failed DAG run for a past date because datetime.today() is relative to the current date, not the DAG execution date.
A better way of implementing this is by using an Airflow Variable as such:
code_block[StructValue([(u’code’, u”# Variables used by tasksrn# Good example – Define yesterday’s date with an Airflow variablernyesterday = {{ yesterday_ds_nodash }}”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e8554a515d0>)])]
21. Avoid creating your own additional Airflow Variables. a. The metadata database stores these variables and requires database connections to retrieve them. This can affect the performance of the Cloud Composer Environment. Use Environment Variables or Google Cloud Secrets instead.
22. Avoid running all DAGs on the exact same schedules (disperse workload as much as possible). a. Prefer to use cron expressions for schedule intervals compared to airflow macros or time_deltas. This allows a more rigid schedule and it’s easier to spread out workloads throughout the day, making it easier on your Cloud Composer environment. b. Crontab.guru can help with generating specific cron expression schedules. Check out the examples here.
Examples:
code_block[StructValue([(u’code’, u’schedule_interval=”*/5 * * * *”, # every 5 minutes.rnrn schedule_interval=”0 */6 * * *”, # at minute 0 of every 6th hour.’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e8554a516d0>)])]
23. Avoid XComs except for small amounts of data. a. These add storage and introduce more connections to the database. b. Use JSON dicts as values if absolutely necessary. (one connection for many values inside dict)
24. Avoid adding unnecessary objects in the dags/ Google Cloud Storage path. a. If you must, add an .airflowignore file to GCS paths that the Airflow Scheduler does not need to parse. (sql, plug-ins, etc.)
25. Set execution timeouts for tasks.
Example:
code_block[StructValue([(u’code’, u”# Use the `PythonOperator` to define the taskrntask = PythonOperator(rn task_id=’my_task’,rn python_callable=my_task_function,rn execution_timeout=timedelta(minutes=30), # Set the execution timeout to 30 minutesrn dag=dag,rn)”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e8554a517d0>)])]
26. Use Deferrable Operators over Sensors when possible. a. A deferrable operator can suspend itself and free up the worker when it knows it has to wait, and hand off the job of resuming it to a Trigger. As a result, while it suspends (defers), it is not taking up a worker slot and your cluster will have fewer/lesser resources wasted on idle Operators or Sensors.
27. When using Sensors, always define mode, poke_interval, and timeout. a. Sensors require Airflow workers to run. b. Sensor checking every n seconds (i.e. poke_interval < 60)? Use mode=poke. A sensor in mode=poke will continuously poll every n seconds and hold Airflow worker resources. c. Sensor checking every n minutes (i.e. poke_interval >= 60)? Use mode=reschedule. A sensor in mode=reschedule will free up Airflow worker resources between poke intervals.
28. Offload processing to external services (BigQuery, Dataproc, Cloud Functions, etc.) to minimize load on the Cloud Composer environment. a. These services usually have their own Airflow Operators for you to utilize.
29. Do not use sub-DAGs. a. Sub-DAGs were a feature in older versions of Airflow that allowed users to create reusable groups of tasks within DAGs. However, Airflow 2.0 deprecated sub-DAGs because they caused performance and functional issues.
31. Make DAGs load faster. a. Avoid unnecessary “Top-level” Python code. DAGs with many imports, variables, functions outside of the DAG will introduce greater parse times for the Airflow Scheduler and in turn reduce the performance and scalability of Cloud Composer / Airflow. b. Moving imports and functions within the DAG can reduce parse time (in the order of seconds). c. Ensure that developed DAGs do not increase DAG parse times too much.
Example:
code_block[StructValue([(u’code’, u”import airflowrnfrom airflow import DAGrnfrom airflow.operators.python_operator import PythonOperatorrnrn# Define default_args dictionaryrndefault_args = {rn ‘owner’: ‘me’,rn ‘start_date’: datetime(2022, 11, 17),rn}rnrn# Use with statement and DAG context manager to instantiate the DAGrnwith DAG(rn ‘my_dag_id’,rn default_args=default_args,rn schedule_interval=timedelta(days=1),rn) as dag:rn # Import module within DAG blockrn import my_module # DO THISrnrn # Define function within DAG blockrn def greet(): # DO THISrn greeting = my_module.generate_greeting()rn print(greeting)rnrn # Use the PythonOperator to execute the functionrn greet_task = PythonOperator(rn task_id=’greet_task’,rn python_callable=greetrn )”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e8554a51ad0>)])]
Improve Development and Testing
32. Implement “self-checks” (via Sensors or Deferrable Operators). a. To ensure that tasks are functioning as expected, you can add checks to your DAG. For example, if a task pushes data to a BigQuery partition, you can add a check in the next task to verify that the partition generates and that the data is correct.
33. Look for opportunities to dynamically generate similar tasks/task groups/DAGs via Python code. a. This can simplify and standardize the development process for DAGs.
code_block[StructValue([(u’code’, u’from airflow import modelsrnfrom airflow.utils.dag_cycle_tester import test_cyclernrnrndef assert_has_valid_dag(module):rn “””Assert that a module contains a valid DAG.”””rnrn no_dag_found = Truernrn for dag in vars(module).values():rn if isinstance(dag, models.DAG):rn no_dag_found = Falsern test_cycle(dag) # Throws if a task cycle is found.rnrn if no_dag_found:rn raise AssertionError(‘module does not contain a valid DAG’)’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e8554a51dd0>)])]
35. Perform local development via the Composer Local Development CLI Tool. a. Composer Local Development CLI tool streamlines Apache Airflow DAG development for Cloud Composer 2 by running an Airflow environment locally. This local Airflow environment uses an image of a specific Cloud Composer version.
36. If possible, keep a staging Cloud Composer Environment to fully test the complete DAG run before deploying in the production. a. Parameterize your DAG to change the variables, e.g., the output path of Google Cloud Storage operation or the database used to read the configuration. Do not hard code values inside the DAG and then change them manually according to the environment.
37. Use a Python linting tool such as Pylint or Flake8 for standardized code.
38. Use a Python formatting tool such as Black or YAPF for standardized code.
Next Steps
In summary, this blog provides a comprehensive checklist of best practices for developing Airflow DAGs for use in Google Cloud Composer. By following these best practices, developers can help ensure that Cloud Composer is working optimally and that their DAGs are well-organized and easy to manage.
For more information about Cloud Composer, check out the following related blog posts and documentation pages: