Editor’s note:Today we hear from Squarespace, an all-in-one website building and ecommerce platform, about its migration from a self-hosted Hadoop ecosystem to Google Cloud, running BigQuery, Dataproc and Google Kubernetes Engine (GKE). Read on to learn about how they planned and executed the migration, and what kinds of results they’re seeing.
Imagine you are a makeup artist who runs an in-home beauty business. As a small business owner, you don’t have a software development team who can build you a website. Yet you need to showcase your business, allow users to book appointments directly with you, handle the processing of payments, and continuously market your services to new and existing clients.
Enter Squarespace, an all-in-one platform for websites, domains, online stores, marketing tools, and scheduling that allows users to create an online presence for their business. In this scenario, Squarespace enables the makeup artist to focus entirely on growing and running the business while Squarespace would handle digital website presence and administrative scheduling tasks. Squarespace controls and processes data for customers and their end-users. Squarespace stores data to help innovate customer user features and drive customer-driven priority investments in the platform.
Until Q4 2022, Squarespace had a self-hosted Hadoop ecosystem composed of two independently managed Hadoop clusters. Both clusters were “duplicated” because we utilized an active/passive model for geo-redundancy, and staging instances also existed. Over time, the software and hardware infrastructure started to age. We quickly ran out of disk space and came up against hard limits on what we could store. “Data purges,” or bulk deletion of files to free up disk space, became a near-quarterly exercise.
By early 2021 we knew we couldn’t sustain the pace of growth that we saw in platform usage, particularly with our on-premises Presto and Hive deployments, which housed several hundred tables. The data platform team tasked with maintaining this infrastructure was also small and unable to keep up with scaling and maintaining the infrastructure while delivering platform functionality to users. We had hit a critical decision point: double-down on running our infrastructure or move to a cloud-managed solution. Supported by leadership, we opted for Google Cloud because we had confidence in the platform and knew we could migrate and deploy quickly.
Project planning
Dependency mapping
We took the necessary time upfront to map our planned cloud infrastructure. We decided what we wanted to keep, update or replace. This strategy was beneficial, as we could choose the best method for a given component. For example, we decided to replace our on-premises Hadoop Distributed File System (HDFS) with Cloud Storage using the Hadoop GCS Connector but to keep our existing reporting jobs unchanged and not rewrite them.
In-depth dependency tracking
We identified stakeholders and began communicating our intent early. After we engaged the teams, we began weekly syncs to discuss blockers. We also relied on visual project plans to manage the work, which helped us understand the dependencies across teams to complete the migration.
Radical deprioritization
We worked backward from our target date and ensured the next two months of work were refined during the migration. With the help of top-down executive sponsorship, the team consistently fought back interrupted work by saying ‘no, not now’ to non-critical requests. This allowed us to provide realistic timelines for when we would be able to complete those requests post-migration.
Responsibilities
We broke down responsibilities by team, allowing us to optimize how our time was spent.
The data platform teams built reusable tooling to rename and drop tables and to programmatically ‘diff; entire database tables to check for exact matching outputs. They also created a Trino instance on Google Cloud that mirrored the on-prem Presto.
The data engineering teams leveraged these tools while moving each of their data pipelines.
Technology strategy
Approach
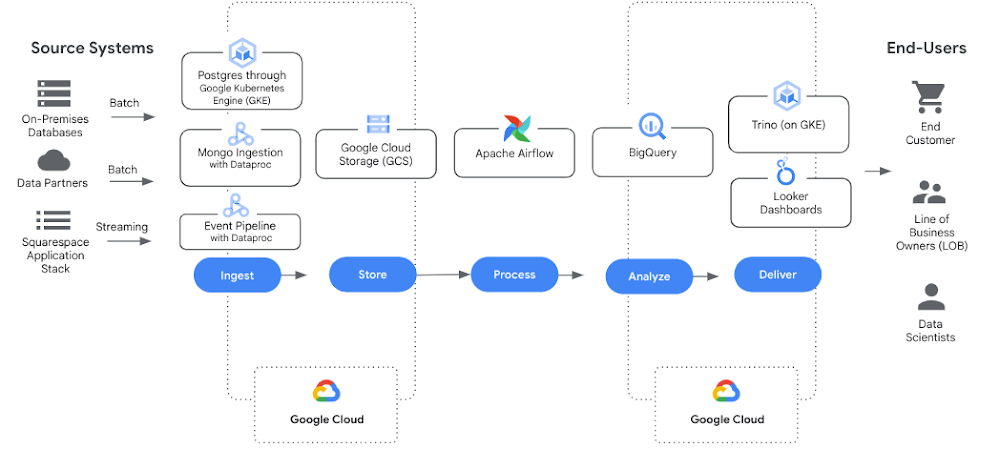
We took an iterative approach to migrating the compute and storage for all of our systems and pipelines. Changing only small, individual pieces at a time, let us validate the outputs at every migration phase, realize iterative wins, all while saving hours of manual validation time to achieve the overall architecture shown below.
Phase 1: Cutover platform and policies
Our first step was to cut over our query engine, Presto, to run on Google Kubernetes Engine (GKE). Deploying this service gave end users a place to start experimenting with queries with an updated version of the software, now called Trino. We also cut over our platform policies, meaning we established usage guidelines for using Cloud Storage buckets or assigning IAM privileges to access data.
Phase 2: Move compute to the Cloud
Once we had a Trino instance in Google Cloud, we granted it access to our on-prem data stores. We updated our Trino Airflow operator to run jobs in Google Cloud instead of on-premises. Spark processes were migrated to Dataproc. One by one, stakeholder teams switched from executing on-premises compute to cloud-based compute while still reading and writing data on-premises. They also had the option to migrate straight to Google Cloud-based storage. We let teams decide what sequencing fit in their current commitment schedule but also stipulated a hard deadline to end on-premises storage.
Phase 3: Storage cutover
After confirming the jobs were all successfully running in Google Cloud and validating the output, we started redirecting downstream processes to read from Google Cloud data sources (Cloud Storage/BigQuery). Over time we watched the HDFS read/writes to the old clusters get to zero. At that point we knew we could shut down the on-premises hardware.
Phase 4: Cutover orchestration
Our orchestration platform, Airflow, runs on-premises. We’re investigating moving to Cloud Composer in 2023. This component is a thin slice of functionality, but represents one of the largest lifts due to the number of teams and jobs involved.
Leadership support
Our internal project sponsor was the Infrastructure team which needed to sunset the hardware. To make room for the data team to focus solely on Google Cloud migration, the Infrastructure leadership team found any opportunities possible to take responsibilities off of the data group.
Leadership within the data group shielded their engineers from all other asks from other parts of the organization, giving them plenty of support to say “no” to all non-migration related requests.
Looking forward, what’s next for Squarespace?
Following the successful migration to Google Cloud of our Hadoop ecosystem, we have seen the significant maintenance burden of the infrastructure disappear. From the months before our migration compared to the months immediately after, we’ve seen an 87% drop in the number of escalations. The data platform and data infrastructure teams have turned their attention away from monitoring the health of various services/filesystems, and are now focused on delivering new features and better software that our internal users need to move our business forward.
Next, in our analytics lakehouse plan is to continue the success we had with migrating our data lake and move more of the infrastructure responsibilities to Google Cloud. We’re actively planning the migration of our on-prem data warehouse to BigQuery and have begun to explore moving our Airflow Instances to Cloud Composer.
To learn how you can get started on your data modernization journey, contact Google Cloud.
Editor’s note: Today’s blog discusses efforts by Arkhia, the organization developed by BCW Group, to provide Infrastructure-as-a-Service (IaaS) and Web3 backend solutions for blockchain & DLT developers. It is the first of three posts.
BCW is a Web3 venture studio and enterprise consulting firm serving enterprise clients who want to integrate existing products or otherwise branch into the Web3 space. In this first of a three-part blog series, we will look at how BCW products use decentralized technology on Google Cloud.
BCW provides companies with an arsenal of support services that include consulting, technical, and go-to-market. This ensures our customers’ early and ongoing success in accommodating the sophisticated demands that new entrants into the space face.
Arkhia and the Hedera Network
The first product outlined in this series, Arkhia, focuses on Hedera network infrastructure. Hedera has seen some of the largest inflows of Web3 developer activity over the past several months, which Arkhia is poised to serve with infrastructure and API solutions.
For at least 15 years, the Web2 space has been dominated by traditional CRUD or central data storage applications. These applications worked well enough and were a decidedly significant improvement over the slow and rigid server structures they replaced. With the rise of Web3, however, a new paradigm in assets, computing, and security has arisen offering new forms of human interaction. As with any new paradigm, new hurdles have emerged that can inhibit adoption, such as growing hardware demands, increased need for reliability from relatively new protocols and codebases, and a lack of consistent definitions and access points.
To mitigate these challenges, Arkhia provides a gateway and workbench for aspiring Web3 developers and enterprises to access the underlying infrastructure of decentralized ledger technology (DLT). For example, Arkhia’s Workbench tool lets builders instantly view data schemas on the Hedera mirror node. The Watchtower tool enables subscribing to Hedera Consensus Service (HCS) through WebSockets by automatically translating HTTP2 to HTTP1, a critical functionality for higher-end development goals. Additionally, Arkhia provides enhanced APIs such as streams, subscriptions, and queries through the HCS gRPC, REST API, and JSON RPC Relay.
A fundamental aspect of our offerings is the use of Google Cloud products, which support the ability to build at-scale without compromising the principles of Web3. Pairing product process and service selection with Google Cloud technologies has empowered Arkhia to apply successful principles from the Web2 world to this new decentralized model of interaction.
Leveraging Google Cloud data services
The robust and wide ranging data services on Google Cloud, such as BigQuery, Dataflow, and Airflow, along with core infrastructural offerings such as Cloud Load Balancing and Cloud Storage, have enabled Arkhia to build out a highly scaled, wide reaching application that transforms a DLT into a data lake. This merges both the worlds of analytics and observation with participation, meeting the demands of internal and externally oriented strategies.
When viewing the customer journey, we find that a good DLT use case is nested in sound data strategy. In considering how to apply data strategy or blockchain strategy, we must consider the clients’ needs for specific use cases. Anyone familiar with design thinking frameworks will find this first step a no-brainer. Most importantly, we must determine how data will fit into that strategy.
When thinking about our customers, we tend to think of data in terms of external versus internal posturing. With external posturing, data is proactively applied when making decisions concerning customer success and marketing efforts in order to cultivate the initiatives and businesses of our clients. In an internal posture, data is applied to accommodate digital transformations, regulatory compliance, and optimization processes.
Building a DLT posture is similar. When we think externally, our customers begin to see blockchain as a core component of products and services such as payment rails, remittance services, exchanges (both DEX and CEX), and proof-of-reserve systems – with so many more to list.
Thinking internally, we often have customers looking to high-performance applications to service their organizations as mechanisms to reduce cost between departments and/or create CRM or employee incentive applications. It should be noted that the lines between external and internal thinking are often initially drawn between private and public chains. By making Google Cloud an inextricable part of its operations, Arkhia’s flexible set of tools allows clients to blur these lines and reduce stack.
Arkhia meets both postures simultaneously by creating access to the unique service layers of Hedera. By building a workbench of tooling around core out-of-the-box Hedera Hashgraph services such as HCS, Hedera Token Service (HTS), and the mirror node layers, access points for data and transactions are merged. This also enables technology teams to build effective technologies and strategies as they venture into the DLT wilds.
The Arkhia team leverages Google Cloud to mitigate challenges that arise from nascent code and libraries in DLT and creates a stable platform on which products can be built.
The collaboration between Google Cloud and Arkhia addresses concerns about the ubiquity of cloud technologies concerning the growing conversations on open ledgers (e.g. Bitcoin, Ethereum, etc.) and the privilege of anonymity which they ostensibly support. In Hedera’s case, there is a tolerance, if not an expectation, that known parties handle the infrastructure, which is important in data systems.
BigQuery, Billing, and Pub-Sub offerings lay the groundwork for the Arkhia team to investigate node-as-a-service offerings, highly scaled JSON-RPC deployments, and even independent ancillary services that can speed up builds, allow developers to compose Hedera services, and allow for further application-level flexibility.
As BigQuery expands the possibilities for the world of Web3 through ETL initiatives and data ingestion, Arkhia ensures that users can move forward confidently regardless of high-storage-intensive paradigms that are typical to the DLT ecosystem. From a business management perspective, BigQuery eliminates the need for the overhead of a high-cost infrastructure because it provides the opportunity to stream and consume blockchain data in near real-time for decentralized apps (dApps) and other services. It does all this with real-time analytics on all kinds of data to increase and improve both internal and external insights.
For business managers at Arkhia who work in the DLT IaaS space, Cloud Billing provides several improvements. Controlling billing with a detailed overview of services, costs, and computation/storage units can give managers the critical edge they need to not just survive, but thrive. Arkhia uses Google Cloud’s sophisticated features to adequately manage its scale and costs.
A comprehensive suite of APIs and Pub/Sub offerings
Google Cloud also has a comprehensive suite of APIs and Pub/Sub offerings for baked-in functionality, enabling quickstart POC’s to rapidly build and iterate at the speed of Web 3 innovation. Due to a high level of internal networking sophistication, Pub/Sub tools integrate easily with services such as BigQuery and Google Kubernetes Engine to reduce development time and tooling for real-time blockchain data. Using Google Cloud’s Pub/Sub to improve data streaming performance between data systems and clients is attractive to clients who want high-availability, security, and performance from data that is sensitive to time and accuracy.
Google Cloud’s computing and services empower platforms such as Arkhia to rapidly build scalable and stable infrastructure on the rapidly changing states of blockchain environments. As a greater number of firms transition their operations to environmentally sustainable tools that support Web3 functionality, Google Cloud will assist infrastructure developers in maintaining an ethos of decentralization.
Finally, Google cloud’s commitment to sustainability allows Arkhia to participate in a carbon-neutral decentralized service without violating the core values or benchmarks established by the curators of the Hedera protocol.
As we continue to combine principles of data strategy, practice, and capabilities, we see Google Cloud’s offerings as a critical piece of tooling for our system. From end-to-end, Arkhia and Google Cloud seek to build decentralized services for our clients and customers while supporting developers who grapple with the unique challenges of DLT and blockchain.
You probably have heard all about the role of ChatGPT. This tool got a lot of attention after many people realized how efficiently it can help people write content. We even wrote a post talking about ChatGPT as a content marketing tool. However, we have quickly realized that ChatGPT has benefits that go well beyond writing more efficiently.
The automotive industry has been rapidly transformed by the advent of artificial intelligence (AI). From autonomous vehicles to predictive maintenance and optimized production processes, AI is revolutionizing every aspect of the automotive industry.
General Overview of the Benefits of AI in the Automotive Sector
The market for AI in the automotive industry is booming. The fact is that there are many benefits of using AI to streamline the industry.
AI has a significant advantage in manufacturing. It starts with design and goes through the supply chain, production, and post-production. AI can help design vehicles and equipment, like wearable exoskeletons for safety and comfort. AI can also improve transportation by developing driver assist programs, autonomous driving, and driver monitoring. It can also improve customer service with predictive maintenance and notifications for engine and battery performance. AI can even be used for insurance programs that monitor driver behavior to calculate risks and costs.
One of the most visible impacts of AI on the automotive industry is the development of autonomous driving technology. With the help of machine learning algorithms, vehicles can now navigate roads and highways without human intervention. This technology has the potential to make driving safer, reduce traffic congestion, and increase mobility for people who cannot or do not want to drive.
Predictive Maintenance
Another way AI is changing the automotive industry is through predictive maintenance. With the help of sensors and data analysis, AI algorithms can predict when a vehicle is likely to experience a mechanical problem or breakdown. This allows for proactive maintenance, which can help prevent costly repairs and reduce downtime.
Optimized Production Processes
AI is also being used to optimize production processes in the automotive software development. By analyzing data on production lines, machine learning algorithms can identify inefficiencies and suggest improvements to maximize productivity and reduce waste. This can lead to significant cost savings for manufacturers and help them remain competitive in an increasingly crowded market.
Improved Customer Experience
Finally, AI is improving the overall customer experience in the automotive industry. With the help of chatbots and natural language processing (NLP), customers can interact with dealerships and manufacturers more easily and quickly. Additionally, AI-powered recommendation engines can suggest vehicles and features based on a customer’s preferences and behavior, creating a more personalized shopping experience.
In conclusion, AI is having a transformative impact on the automotive industry. From autonomous driving to optimized production processes and improved customer experiences, AI is helping manufacturers and dealerships stay competitive in a rapidly changing market. As AI technology continues to advance, we can expect even more innovation and disruption in the automotive industry in the years to come.
Data-driven organizations often struggle with inconsistent metrics due to a lack of shared definitions, conflicting business logic, and an ever-growing number of outdated data extracts. This can lead to KPIs that don’t match, which can erode trust and threaten a thriving data culture, when teams can’t agree on basic metrics like monthly active users or pipeline growth. By defining metrics once and using them everywhere, you can improve time to insight and help reduce risk, which can result in better governance, security, and cost control.
A decade ago, Looker’s innovative semantic model helped advance the modern business intelligence (BI) industry, and today, we’re using that intelligent engine to create a single source of truth for your business — a standalone metrics layer we call Looker Modeler, available in preview in Q2.
By defining metrics and storing them in Looker Modeler, metrics can be consumed everywhere, including across popular BI tools such as Connected Sheets, Looker Studio, Looker Studio Pro, Microsoft Power BI, Tableau, and ThoughtSpot. Looker Modeler also works across cloud databases, querying the freshest data available, avoiding the need to manage data extracts, and helping to minimize the risk of insights and reports (including those that impact financial decisions) being days or weeks out of date.
Looker Modeler expands upon the data collaboration and analysis capabilities users have come to expect from the Looker family over the last decade. Models can be shared with coworkers, and new LookML drafts can be submitted for review from the company’s central data team. The result is consistent accessible metrics that can define data relationships and progress against business priorities for a wide variety of use cases. Companies can define the business representation of their data in a semantic layer, without requiring users to have direct access to the underlying database, avoiding disruptions in the event of changes to related infrastructure.
In addition to the direct integrations with several popular visualization tools, Looker Modeler offers a new SQL interface that allows tools that speak SQL to connect to Looker via JDBC. This new capability is another step toward our vision of making Looker the most open BI platform, bringing trusted data to all types of users through the tools they already use. By reaching users where they use their data, organizations can create data-driven workflows and custom applications that help promote the development of a stronger data culture, drive operational efficiency, and foster innovation.
To learn more about Looker Modeler, watch our session from the Data Cloud & AI Summit: Trusted Metrics Everywhere. To test Looker Modeler in your environment, sign up here.
Businesses across industries share data, combining first-party data with external sources to obtain new insights and collaborate with partners. In fact, 6000+ organizations share over 275 PBs of data across organizational boundaries every week using BigQuery. Last year, we launched in market Analytics Hub, built on BigQuery, which lets customers share and exchange data cost-effectively, while helping to minimize data movement challenges. However, customers share many types of data, some of which may be subject to more stringent regulatory and privacy requirements. In those cases customers may require extra layers of protection to analyze multi-channel marketing data and securely collaborate with business partners across different industries.
To help, we’re introducing BigQuery data clean rooms, coming in Q3, to help organizations create and manage secure environments for privacy-centric data sharing, analysis, and collaboration across organizations — all without generally needing to move or copy data.
Data clean rooms can help large enterprises to understand audiences while respecting user privacy and data security. For example, with BigQuery data clean rooms:
Retailers can optimize marketing and promotional activities by combining POS data from retail locations and marketing data from CPG companies
Financial Services enterprises can improve fraud detection by combining sensitive data from other financial and government agencies or build credit risk scoring by aggregating customer data across multiple banks
In the healthcare industry, doctors and pharmaceutical researchers can share data within a clean room to learn how patients are reacting to treatments.
These are just a few of the use cases that BigQuery data clean rooms can enable. Let’s take a look at how it works.
Deploy data clean rooms in minutes
Data clean rooms will be available in all BigQuery regions through Analytics Hub, and can be created and deployed in minutes. Customers can use Google Cloud console or APIs to create secure clean room environments, and invite partners or other participants to contribute data.
Data contributors can publish tables or views within a clean room and aggregate, anonymize, and help protect sensitive information. They can also configure analysis rules to restrict the types of queries that can be run against the data. More importantly, adding data to a clean room does not generally require creating a copy or moving the data; it can be shared in-place and remain under the control of the data contributor. Finally, data subscriber customers will be able to discover and subscribe to clean rooms where they can perform privacy-centric queries within their own project.
Shared data within a clean room can be live and up-to-date — any changes to shared tables or views are immediately available to subscribers. Data contributors also receive aggregated logs and metrics to understand how their data is being used within a clean room.
There are no additional costs for BigQuery customers associated with using BigQuery data clean rooms. When collaborating with multiple partners, data contributors only pay for the storage of the data and subscribers of data clean rooms only pay for the queries.
Note: For organizations that need to run general-purpose applications on sensitive data with hardware-backed confidentiality and privacy guarantees, Google Cloud offers Confidential Space, which recently became generally available.
Partners enabling data clean rooms in BigQuery
Data clean rooms capabilities in BigQuery are enabled today by our partnerships with Habu and LiveRamp. With Habu, a data collaboration platform for privacy-centric data orchestration, customers like L’Oréal are working with Google Cloud and Habu to help securely share data. “We are thrilled to be among the first to work within the BigQuery and Habu environment. The ability to safely and securely access and analyze more data, without tapping into data science resources, has empowered us to better understand our customers and measure the true impact of our marketing activities,” said Shenan Reed, SVP Head of Media at L’Oréal.
“Our partnership with Google Cloud exemplifies our commitment to deliver frictionless collaboration across an open technology ecosystem. Democratizing clean room access and delivering the privacy-centric tools that brands demand is opening up new avenues for growth for our shared customers,” said Matt Kilmartin, Co-founder and CEO of Habu.
LiveRamp on Google Cloud can enable privacy-centric data collaboration and identity resolution within BigQuery to drive more effective data partnerships. LiveRamp’s solution in BigQuery unlocks the value of a customer’s first-party data and establishes a privacy-centric identity data model that can accurately:
Improve consolidation of both offline and online records for a more accurate and holistic view of customer audience profiles
Activate audiences securely with improved match rates for greater reach and measurement quality
Connect customer and prospect data with online media reports and partner data elements to help improve customer journeys and attribution insights using ML models
“LiveRamp has developed deep support for accurate and privacy-safe data connectivity throughout the Google ecosystem. As one of the first clean room providers on Google Cloud with our Data Collaboration Platform, we have been very excited to watch the evolution of Analytics Hub into a powerful native clean room solution for the entire BigQuery ecosystem. Our continued work with Google Cloud is focused on allowing global clients to more easily connect and collaborate with data, driving more impactful audience modeling and planning, and ensuring that they can extend the utility of data natively on BigQuery both safely and securely,” said Max Parris, Head of Identity Resolution Products, LiveRamp.
Finally, Lytics is a customer data platform built onBigQuery that helps activate insights across marketing channels. Lytics offers a data clean room solution on Google Cloud for Advertisers and Media built from the collaboration with BigQuery. The Lytics data clean room offers features for managing and processing data, ingestion, consolidation, enrichment, stitching, and entity resolution. The solution utilizes Google Cloud’s exchange-level permissions and can unify data without exposing PII, thereby allowing customers to leverage data across their organization, while avoiding data duplication and limiting privacy risks.
Take the next step
Want to learn more about BigQuery data clean rooms? Join the upcoming BigQuery customer roadmap session, speak to a member of the Data Analytics team to inquire about early access, or reach out to Habu to get started today with your data clean room. For marketers who are looking to use a clean room to better understand Google and YouTube campaign performance and leverage first party data in a privacy-centric way, Ads Data Hub for Marketers, built on BigQuery, is Google’s advertising measurement solution.
Even in today’s changing business climate, our customers’ needs have never been more clear: They want to reduce operating costs, boost revenue, and transform customer experiences. Today, at our third annual Google Data Cloud & AI Summit, we are announcing new product innovations and partner offerings that can optimize price-performance, help you take advantage of open ecosystems, securely set data standards, and bring the magic of AI and ML to existing data, while embracing a vibrant partner ecosystem. Our key innovations will enable customers to:
Improve data cost predictability using BigQuery editions
Break free from legacy databases with AlloyDB Omni
Unify trusted metrics across the organization with Looker Modeler
Extend AI & ML insights to BigQuery and other third-party platforms
Help reduce operating costs for BigQuery
In the face of fast-changing market conditions, organizations need smarter systems that provide the required efficiency and flexibility to adapt. That is why today, we’re excited to introduce new BigQuery pricing editions along with innovations for autoscaling and a new compressed storage billing model.
BigQuery editions provide more choice and flexibility for you to select the right feature set for various workload requirements. You can mix and match among Standard, Enterprise, and Enterprise Plus editions to achieve the preferred price-performance by workload.
BigQuery editions include the ability for single or multi-year commitments at lower prices for predictable workloads and new autoscaling that supports unpredictable workloads by providing the option to pay only for the compute capacity you use. And unlike alternative VM-based solutions that charge for a full warehouse with a pre-provisioned, fixed capacity, BigQuery harnesses the power of a serverless architecture to provision additional capacity in granular increments to help you not overpay for underutilized capacity. Additionally, we are offering a new compressed storage billing model for BigQuery editions customers, which can reduce costs depending on the type of data stored.
Break free from legacy databases with AlloyDB
For many organizations, reducing costs means migrating from expensive legacy databases. But sometimes, they can’t move as fast as they want, because their workloads are restricted to on-premises data centers due to regulatory or data sovereignty requirements, or they’re running their application at the edge. Many customers need a path to support in-place modernization with AlloyDB, our high performance, PostgreSQL-compatible database, as a stepping stone to the cloud.
Today, we’re excited to announce the technology preview of AlloyDB Omni, a downloadable edition of AlloyDB designed to run on-premises, at the edge, across clouds, or even on developer laptops. AlloyDB Omni offers the AlloyDB benefits you’ve come to love, including high performance, PostgreSQL compatibility, and Google Cloud support, all at a fraction of the cost of legacy databases. In our performance tests, AlloyDB Omni is more than 2x faster than standard PostgreSQL for transactional workloads, and delivers up to 100x faster analytical queries than standard PostgreSQL. Download the free developer offering today at https://cloud.google.com/alloydb/omni.
And to make it easy for you to take advantage of our open data cloud, we’re announcing Google Cloud’s new Database Migration Assessment (DMA) tool, as part of the Database Migration Program. This new tool provides easy-to-understand reports that demonstrate the effort required to move to one of our PostgreSQL databases — whether it’s AlloyDB or Cloud SQL. Contact us today at g.co/cloud/migrate-today to get started with your migration journey.
Securely set data standards
Data-driven organizations need to know they can trust the data in their business intelligence (BI) tools. Today we are announcing Looker Modeler, which allows you to define metrics about your business using Looker’s innovative semantic modeling layer. Looker Modeler is the single source of truth for your metrics, which you can share with the BI tools of your choice, such as PowerBI, Tableau, and ThoughtSpot, or Google solutions like Connected Sheets and Looker Studio, providing users with quality data to make informed decisions.
In addition to Looker Modeler, we are also announcing BigQuery data clean rooms, to help organizations to share and match datasets across companies while respecting user privacy. In Q3, you should be able to use BigQuery data clean rooms to share data and collaborate on analysis with trusted partners, all while preserving privacy protections. One common use case for marketers could be combining ads campaign data with your first-party data to unlock insights and improve campaigns.
We are also extending our vision for data clean rooms with several new partnerships. Habu will integrate with BigQuery to support privacy safe data orchestration and their data clean room service. LiveRamp on Google Cloud will enable privacy-centric data collaboration and identity resolution right within BigQuery to help drive more effective data partnerships. Lytics is a customer data platform built on BigQuery, to help activate insights across marketing channels.
Bring ML to your data
BigQuery ML, which empowers data analysts to use machine learning through existing SQL tools and skills, saw over 200% year overview growth in usage in 2022. Since BigQuery ML became generally available in 2019, customers have run hundreds of millions of prediction and training queries. Google Cloud provides infrastructure for developers to work with data, AI, and ML, including Vertex AI, Cloud Tensor Processing Units (TPUs), and the latest GPUs from Nvidia. To bring ML closer to your data, we are announcing new capabilities in BigQuery that will allow users to import models such as PyTorch, host remote models on Vertex AI, and run pre-trained models from Vertex AI.
Building on our open ecosystem for AI development, we’re also announcing partnerships to bring more choice and capabilities for customers to turn their data into insights from AI and ML, including new integrations between:
DataRobot and BigQuery provide users with repeatable code patterns to help developers modernize deployment and experiment with ML models more quickly.
Neo4j and BigQuery, allowing users to extend SQL analysis with graph data science and ML using BigQuery, Vertex AI and Colab notebooks.
ThoughtSpot and multiple Google Cloud services — BigQuery, Looker, and Connected Sheets — which will provide more AI-driven, natural language search capabilities to help users more quickly get insights from their business data.
Accelerate your Data Cloud with an open ecosystem
Over 900 software partners power their applications using Google’s Data Cloud. Partners have extended Google Cloud’s open ecosystem by introducing new ways for customers to accelerate their data journeys. Here are a few updates from our data cloud partners:
Crux Informatics is making more than 1,000 new datasets available on Analytics Hub, with plans to increase to over 2,000 datasets later this year.
Starburst is deepening its integration with BigQuery and Dataplex so that customers can bring analytics to their data no matter where it resides, including data lakes, multi and hybrid cloud sources.
Collibra introduced new features across BigQuery, Dataplex, Cloud Storage, and AlloyDB to help customers gain a deeper understanding of their business with trusted data.
Informatica launched a cloud-native, AI-powered master data management service on Google Cloud to make it easier for customers to connect data across the enterprise for a contextual 360-degree view and insights in BigQuery.
Google Cloud Ready for AlloyDB is a new program that recognizes partner solutions that have met stringent integration requirements with AlloyDB. Thirty partners have already achieved the Cloud Ready – AlloyDB designation, including Collibra, Confluent, Datadog, Microstrategy, and Striim.
At Google Cloud, we believe that data and AI have the power to transform your business. Join all our sessions at the Google Data Cloud & AI Summit for more on the announcements we’ve highlighted today. Dive into customer and partner sessions, and access hands-on content on the summit website. Finally, join our Data Cloud Live events series happening in a city near you.
When it comes to their data platforms, organizations want flexibility, predictable pricing, and the best price performance. Today at the Data Cloud & AI Summit, we are announcing BigQuery editions with three pricing tiers — Standard, Enterprise and Enterprise Plus — for you to choose from, with the ability to mix and match for the right price-performance based on your individual workload needs.
BigQuery editions come with two innovations. First, we are announcing compute capacity autoscaling that adds fine-grained compute resources in real-time to match the needs of your workload demands, and ensure you only pay for the compute capacity you use. Second, compressed storage pricing allows you to only pay for data storage after it’s been highly compressed. With compressed storage pricing, you can reduce your storage costs while increasing your data footprint at the same time. These updates reflect our commitment to offer new, flexible pricing models for our cloud portfolio.
With over a decade of continuous innovation and working together with customers, we’ve made BigQuery one of the most unified, open, secure and intelligent data analytics platforms on the market, and a central component of your data cloud. Unique capabilities include BigQuery ML for using machine learning through SQL, BigQuery Omni for cross-cloud analytics, BigLake for unifying data warehouses and lakes, support for analyzing all types of data, an integrated experience for Apache Spark, geospatial analysis, and much more. All these capabilities build on the recent innovations we announced at Google Cloud Next in 2022.
“Google Cloud has taken a significant step to mature the way customers can consume data analytics. Fine-grained autoscaling ensures customers pay only for what they use, and the new BigQuery editions is designed to provide more pricing choice for their workloads.” — Sanjeev Mohan, Principal at SanjMo & former Gartner Research VP.
With our new flexible pricing options, the ability to mix and match editions, and multi-year usage discounts, BigQuery customers can gain improved predictability and lower total cost of ownership. In addition, with BigQuery’s new granular autoscaling, we estimate customers can reduce their current committed capacity by 30-40%.
“BigQuery’s flexible support for pricing allows PayPal to consolidate data as a lakehouse. Compressed storage along with autoscale options in BigQuery helps us provide scalable data processing pipelines and data usage in a cost-effective manner to our user community.” – Bala Natarajan, VP Enterprise Data Platforms at PayPal.
More flexibility to optimize data workloads for price-performance
BigQuery editions allow you to pick the right feature set for individual workload requirements. For example, the Standard Edition is best for ad-hoc, development, and test workloads, while Enterprise has increased security, governance, machine learning and data management features. Enterprise Plus is targeted at mission-critical workloads that demand high uptime, availability and recovery requirements, or have complex regulatory needs. The table below describes each packaging option.
Prices above are for the US. For regional pricing, refer to the detailed pricing page
Pay only for what you use
BigQuery autoscaler manages compute capacity for you. You can set up maximum and optional baseline compute capacity, and let BigQuery take care of provisioning and optimizing compute capacity based on usage without any manual intervention on your part. This ensures you get sufficient capacity while reducing management overhead and underutilized capacity.
Unlike alternative VM-based solutions that charge for a full warehouse with pre-provisioned, fixed capacity, BigQuery harnesses the power of a serverless architecture to provision additional capacity in increments of slots with per-minute billing, so you only pay for what you use.
“BigQuery’s new pricing flexibility allows us to use editions to support the needs of our business at the most granular level.” — Antoine Castex, Group Data Architect at L’Oréal.
Here are a few examples of customers benefiting from autoscaling:
Retailers experiencing spikes in demand, scaling for a few hours a couple of times per year
Analysts compiling quarterly financial reports for the CFO
Startups managing unpredictable needs in the early stages of their business
Digital natives preparing for variable demand during new product launches
Healthcare organizations scaling usage during seasonal outbreaks like the flu
Lower your data storage costs
As data volumes grow exponentially, customers find it increasingly complex and expensive to store and manage data at scale. With the compressed storage billing model you can manage complexity across all data types while keeping costs low.
Compressed storage in BigQuery is grounded in our years of innovation in storage optimization, columnar compression, and compaction. With this feature, leader in security operations Exabeam has achieved a compression rate of more than 12:1 and can store more data at a lower cost which helps their customers solve the most complex security challenges. As customers migrate to BigQuery editions or continue to leverage the on-demand model, they can take advantage of the compressed storage billing model to store more data cost-efficiently.
Next steps for BigQuery customers
Starting on July 5, 2023, BigQuery customers will no longer be able to purchase flat-rate annual, flat-rate monthly, and flex slot commitments. Customers already leveraging existing flat-rate pricing can begin migrating their flat and flex capacity to the right edition based on their business requirements, with options to move to edition tiers as their needs change.
Taking into account BigQuery’s serverless functionality, query performance, and capability improvements, we are increasing the price of the on-demand analysis model by 25% across all regions, starting on July 5, 2023.
Irrespective of which pricing model you choose, the combination of these innovations with multi-year commitment usage discounts, can help you lower your total cost of ownership. Refer to the latest BigQuery cost optimization guide to learn more.
Customers will receive more information about the changes coming to BigQuery’s commercial model through a Mandatory Service Announcement email in the next few days. In the meantime, check out the FAQs, pricing information and product documentation, and register for the upcoming BigQuery roadmap session on April 5, 2023 to learn more about BigQuery’s latest innovations.
1. All Google Cloud Platform wide certifications including ISO 9001, ISO 27001, SOC 1-3, PCI (link for full list) 2. Roadmap functionality
Organizations worldwide are excited about the potential of Artificial Intelligence and Machine Learning capabilities. However, according to HBR, only 20% see their ML models go into production because ML often is deployed separately from their core data analytics environment. To bridge this increasing gap between data and AI, organizations need to build massive data pipelines, hire resources skilled in Python and other advanced coding languages, manage governance, and scale deployment infrastructure. This approach to harnessing ML is expensive and exposes several security risks.
BigQuery ML addresses this gap by bringing ML directly to your data. Since BigQuery ML became generally available in 2019, customers have run hundreds of millions of prediction and training queries on it, and its usage grew by over 200% YoY in 2022.
Today, we are announcing BigQuery ML inference engine, which allows you to run predictions not only with popular models formats directly in BigQuery but also using remotely hosted models and Google’s state of the art pretrained models. This is a major step towards seamless integration of predictive analytics in a data warehouse. With this new feature, you can run ML inferences across:
Imported custom models trained outside of BigQuery with a variety of formats (e.g. ONNX, XGBoost and TensorFlow)
Remotely hosted models on Vertex AI Prediction
State-of-the-art pretrained Cloud AI models (e.g. Vision, NLP, Translate and more)
All these capabilities are available right within BigQuery where your data resides. This eliminates the need for data movement, reducing your costs and security risks. You can harness a broad range of ML capabilities using familiar SQL without knowledge of advanced programming languages. And with BigQuery’s petabyte scale and performance, you don’t have to worry about setting up serving infrastructure. It just works, regardless of the workload!
Let’s look at each of these capabilities in detail.
Imported custom models trained outside of BigQuery
BigQuery ML can import models that were trained outside of BigQuery. Previously limited to TensorFlow models, we are now expanding this to TensorFlow Lite, XGBoost and ONNX. For example, you can convert many common ML frameworks, such as PyTorch and scikit-learn, into ONNX and then import them into BigQuery ML. This allows you to run predictions on state-of-the-art models that were developed elsewhere directly within BigQuery — without moving your data. By running inference inside BigQuery, you get better performance by leveraging BigQuery’s distributed query engine for batch inference tasks.
Here’s a basic workflow:
Store a pre-trained model artifact in a Cloud Storage bucket
Run the CREATE MODEL statement to import the model artifact into BigQuery
Run a ML.PREDICT query to make predictions with the imported model
Inference on remote models
Some models need unique serving infrastructure to handle low-latency requests and a large number of parameters. Vertex AI endpoints makes this easy by auto-scaling to handle requests and providing access to accelerate compute options with GPU and multi-GPU serving nodes. These endpoints can be configured for virtually limitless model types, with many options for pre-built containers, custom containers, custom prediction routines, and even NVIDIA Triton Inference Server. Now, you can do inference with these remote models from right inside BigQuery ML.
Here’s a basic workflow:
Host your model on a Vertex AI endpoint
Run CREATE MODEL statement in BigQuery pointing to the Vertex AI endpoint
Use ML.PREDICT to send BigQuery data to run inference against the remote Vertex AI endpoint and get the results back to BigQuery
Inference on Vertex AI APIs with unstructured data
Earlier this year, we announced BigQuery ML’s support of unstructured data such as images. Today, we are taking it one step further by enabling you to run inferences on Vertex AI’s state-of-the-art pretrained models for images (Vision AI), text understanding (Natural Language AI), and translation (Translate AI) right inside BigQuery. These models are available using their own unique prediction functions directly within BigQuery ML inference engine. These APIs take text or images as input and return JSON responses that are stored in BigQuery with the JSON data type.
Here’s a basic workflow:
If working with images, first create an Object Table with your images. This step is not required if you are working with text in BigQuery.
Run the CREATE MODEL statement and use a remote connection along with the Vertex AI model type as a parameter.
Use one of the functions below to send BigQuery data to Vertex AI to get inference results.
ML.ANNOTATE_IMAGE
ML.TRANSLATE
ML.UNDERSTAND_TEXT
Get started
By extending support to run inferences on a broad range of open source and other platform hosted models, BigQuery ML makes it simple, easy and cost effective to harness the power of machine learning for your business data. To learn more about these new features, check out the documentation, and be sure to sign up for early access.
Googlers Firat Tekiner, Jiashang Liu, Mike Henderson, Yunmeng Xie, Xiaoqiu Huang, Bo Yang, Mingge Deng, Manoj Gunti and Tony Lu contributed to this blog post. Many Googlers contributed to make these features a reality.
AI is driving major changes in the financial world. It is estimated that Fintech companies spent over $9.5 billion on AI in 2021, but small businesses may spend even more on AI-driven financial management software.
The banking industry is among those most heavily affected by AI. Smart solutions can give banks an advantage over competitors. Some of the benefits of AI in banking include:
Banks and other financial institutions are combining AI with other technologies to transform their business models. For example, Infosys helped an Australian bank predict demand, consumption, and price for trading companies. The dashboard streamlined their business trading and procurement process.
While AI can have huge implications for large financial institutions, it is also changing the financial strategy for small businesses as well. Many small businesses are investing in AI-driven financial management software. Upgrading your tech stack is a big undertaking. Many businesses fail to take full advantage of the resources that are available to them simply because they aren’t sure how to get started. The problem is you don’t want to stay analog while your competitors are up in the “Cloud.”
AI-based financial tools aren’t just for your accountants. They can be an invaluable asset for your entire business. In this article, we look at the importance of financial software and discuss how you can use it to secure better business outcomes. Keep reading to learn more about the relevance of AI in finance.
The Evolution of Fintech
For decades the most important technological innovation in finance was the calculator. As AI technology began to work its way into offices all across the country, experts made bold predictions. Financial technology (FinTec) wouldn’t just make accountants’ lives easier. It would replace them altogether.
In the early 2000s, articles were being written that suggested accounting would no longer exist as a profession in the next several decades (in other words, right about now). Obviously, that did not happen. However, AI has changed the state of the profession for better or worse.
Part of the reason for that is that FinTec isn’t quite there yet. Automation is good for taking on repetitive tasks, so AI is a lifesaver for companies with many monotonous tasks. When variables enter the equation, manual effort and human oversite are both necessary.
The other thing? These accountants who now have digitalized their jobs aren’t sitting around useless. They use their free time to focus on more fruitful efforts, so AI has helped them do more important things.
That is often the end game for digital tech implementation. A good financial tech stack that incorporates AI into its models allows you to:
Scale: Growing pains are very real. When a company begins to expand its business things start to change. Suddenly, you have all of your previous responsibilities, plus a new challenge: How do we operate at the same peak efficiency while serving twice as many people? Digital technology allows you to transition into growth without endlessly expanding your departments.
Focus on the bigger picture: While the software handles small stuff, your accountants and other financial professionals can help leverage their time toward bigger goals. Planning out an expansion. Thinking about the financial components of product development, etc. Of course, you would need their help for these things eventually, but now it can happen quicker and with fewer distractions.
A great Fintech lineup may trim your staff somewhat. This is particularly true for companies that were previously making lots of hires to keep up with their growing businesses’ new demands. However, digital technology hasn’t been nearly as much of a job killer as many people once assumed.
Examples of AI in Fintech
Like so many other aspects of workplace digitization, your Fintech stack will usually be made up of many tools that utilize AI. Your accounts will have software specific to accounting. Your analysts might have software designed to help with business forecasting. Billing will have software to manage invoices and payment processing.
It sounds expensive.
It is! Software is now typically a monthly recurring cost. Each tool you acquire may have a relatively low subscription fee, but these costs add up. The benefits of the Software as a Service model (wherein you never own your software but simply rent it) do tend to outweigh the cons. Benefits include:
Free updates: It used to be that you would buy software, and hang on to it for as long as you could. This might mean using the same program for ten-plus years. Frugal, sure, but also a bit of a hindrance. Tech companies are constantly updating their products. Keeping your software up-to-date can help you secure a competitive advantage.
Easier startup cost: Instead of spending tens of thousands of dollars on the front end to acquire all of your tools, you can instead lease them at a much more achievable price. Better yet, because you’re just a renter, it’s easy to pivot into new tools if your first choice doesn’t work out the way you hoped it would.
You’ll still pay a pretty penny for tech. However, part of the promise is that when you use digital technology the right way, it usually pays for itself.
The Right Way
Unfortunately, acquiring software isn’t only about finding the best of every product. You do want excellent tech solutions, but you also want programs that work well together. Unfortunately, that is often easier said than done.
The key word here is “integrations.” That’s the phrase tech folk use to describe how well various tools interact and communicate with one another. Some tools are designed specifically to link up and integrate. These tools will be well adapted for sharing data between departments and generally optimizing your operations.
Tools that don’t integrate can result in “data siloes.” In these situations, your business has all of the data it could ever want, but not in places that are accessible. Accounting has data here, sales has data there, and never shall the two meet.
Why does sales need to be able to look at billing’s data?
Let’s say you want to start focusing more on upsells. You need your sales team to go out, and find the people most willing to not only buy your products but buy the premium version. First, you need to figure out what sort of person is currently doing that the most.
Guess who has the information? Billing.
Separation between departments is largely an imaginary concept. Your business has a broad set of goals, and every department is contributing toward said goals in the best way that they can. Integrations make this job much easier.
If you don’t feel up to the task of choosing the right tech solutions, some consultants can help advise you. They will charge a fee, of course, but it will be much less expensive than the cost of constantly revamping your tech stack.
AI is Changing Finance
AI is certainly the future. There is no doubt that it is changing the state of finance. More companies will need to use AI-driven software to improve their financial services models.
Unleash your analytical prowess in today’s most coveted professions – Data Science and Data Analytics! As companies plunge into the world of data, skilled individuals who can extract valuable insights from an ocean of information are in high demand. Join the data revolution and secure a competitive edge for businesses vying for supremacy.
Data Scientists and Analysts use various tools such as machine learning algorithms, statistical modeling, natural language processing (NLP), and predictive analytics to identify trends, uncover opportunities for improvement, and make better decisions. With the right combination of technical know-how, communication skills, problem solving abilities, and creative thinking – these professionals can help organizations gain a competitive advantage by leveraging data effectively.
The skills required for a successful career in data science and data analysis
Data science and data analysis have rapidly emerged as flourishing and versatile career paths, encompassing a wide range of industries and applications. Essential skills for aspiring professionals in these fields include a solid foundation in mathematics, which is crucial for understanding statistical models and algorithms, and analytical abilities to uncover valuable insights from complex datasets. Proficiency in various programming languages, such as Python, R, and SQL, empowers individuals to efficiently manipulate and visualize data, thus enhancing the decision-making process for businesses. Equally important is the ability to communicate effectively, presenting data-driven solutions to stakeholders in a clear and concise manner. Pursuing a successful career in data science and data analysis demands an innate curiosity to identify trends, unravel hidden patterns, and possess a keen problem-solving mindset, transforming complex data into actionable strategies.
Understanding the job market for these roles
The demand for data science and data analysis professionals is increasingly growing, as businesses are increasingly leveraging data-driven methods to stay competitive. According to Forbes Insights, the number of jobs in these fields will continue to rise in 2021 – with Data Scientist positions expected to grow by 32% over the next five years. These roles are highly prized among employers, and specialized talent is in high demand. Companies are also investing heavily in data science initiatives, with an increasing number of corporations building out their own analytics teams to stay ahead of the curve.
With the right skills, qualifications and experience, data scientists and analysts can secure high-paying jobs in top tech companies such as Google, Amazon, Microsoft and Facebook. Alternatively, these professionals can also choose to become independent consultants – leveraging their expertise to help businesses make better decisions.
Exploring different educational pathways to become a data scientist or analyst
If you’ve ever wondered about becoming a data scientist or analyst, you’ll be glad to know that there’s no one-size-fits-all approach. Traditional paths, like earning a degree in computer science, statistics, or mathematics, can provide you with a solid foundation in the subject. Yet, there are other exciting avenues to explore: self-paced online courses, IT trade schools, boot camps, and even pursuing an interdisciplinary degree combining data science principles with another field of study. Moreover, experimenting with real-world projects or participating in competitions and internships can give you that essential hands-on experience to stand out.
Tips on how to stand out as a candidate when applying for these roles
When it comes to competing for data science and analysis jobs, employers usually look for candidates who can bring something extra to the table. Here are some tips on how to stand out as a candidate:
Build an impressive portfolio of work that showcases your skills, expertise and experience in the field.
Participate in online competitions or hackathons to demonstrate your ability to address challenging problems with creative solutions.
Develop relationships with experienced professionals in the industry and gain practical knowledge through mentoring opportunities.
Make sure you have a good understanding of relevant software and technologies in the field such as big data platforms, machine learning algorithms, natural language processing tools etc., as this will set you apart from other applicants.
Wrapping Up
In conclusion, the demand for data Science and Data Analysts is higher than ever and will continue to rise in the foreseeable future. These crucial roles are essential to businesses of all sizes, providing insights that no other profession can deliver. To be successful in this field requires a diverse set of skills, ranging from technical to analytical proficiency. Understanding the job market is key to setting oneself apart from the competition, as there are differences between companies in regards to educational requirements. Additionally gaining a deep understanding of how companies use data science and analytics will provide invaluable experience. Therefore, by developing these skills, staying informed about emerging trends and being flexible with educational pathways will make any data scientist or analyst shine in the current highly competitive job market.