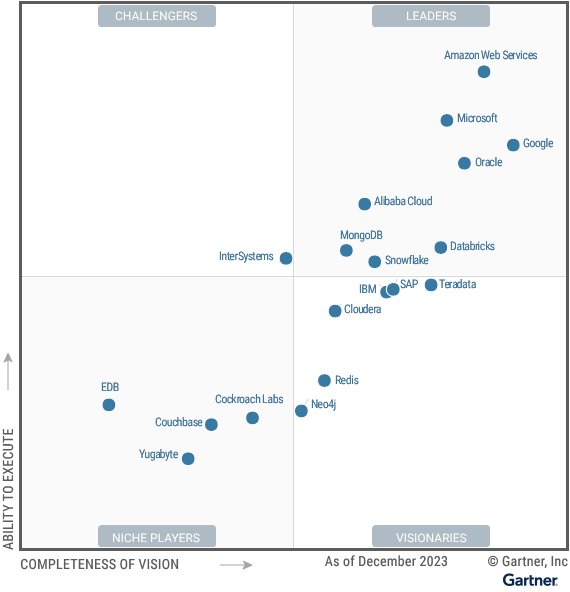
Download the complimentary 2023 Gartner Magic Quadrant for Cloud Database Management Systems report.
“The market has been undergoing a significant shift as companies look to move to more modern, cloud-first approaches. This shift is being driven by a number of factors, including the need for greater agility, scalability, cost savings, and the desire to leverage generative AI capabilities in conjunction with data to innovate.” said Sanjeev Mohan, Principal Analyst at SanjMo and Former Gartner VP. “The way in which Google Cloud is approaching the entire data and AI stack through principles of simplification, unification and open standards is well-aligned to what customers are looking for in a long-term strategic partner.”
Data is critically important to every organization’s AI journey. A strong data foundation can accelerate enterprise-wide AI and revenue growth, according to interviews with hundreds of global executives. The higher an organization’s data maturity, the stronger its AI capabilities and offerings tend to be, the survey found.
However, many organizations are still struggling to extract the full business value of data due to disparate tools and data sources, as well as poor data quality. Moreover, organizations are managing an increasing variety of databases and analytics workloads, resulting in additional complexity, overhead, and risk.
With Google’s Data and AI Cloud, our vision is to bring the simplicity, scalability, security, and intelligence of Google’s data approach to your business, allowing you to unify your data, leverage the best of open source compatibility, all while providing the latest AI capabilities, so you can unlock the full potential of that data.
Manage all data with a unified data cloud
Google’s Data and AI Cloud is based on the principle of simplicity, enabling you to interconnect your data at multiple levels. It provides an open and unified data platform that allows organizations to manage every stage of the data lifecycle — from running operational databases for applications, to managing analytical workloads across data warehouses and data lakes, to data-driven decision making, to AI and machine learning.
Google’s Data and AI Cloud architecture is distinctive, so you can unify your data, people, and workloads. Our databases are built on a highly scalable, distributed storage system with fully disaggregated resources and high-performance Google-owned global networking. This combination allows us to provide tightly integrated data services across AlloyDB, BigQuery, BigLake, Bigtable, Cloud SQL, Dataflow, Dataplex, Dataproc, and Spanner.
We recently launched several capabilities that further strengthen these integrations, making it even easier to accelerate innovation:
Unification of workspace for data and AI people – BigQuery Studio, in preview, brings data engineering, analytics, and ML workloads together, enabling you to edit SQL, Python, Spark and other languages and easily run analytics at petabyte scale without any additional infrastructure management overhead. BigQuery Studio gives you direct access to Colab Enterprise, a new offering that brings Google Cloud’s enterprise-level security and compliance support to Colab.Unification of transactional and analytical systems – We announced the general availability of Spanner Data Boost, a breakthrough technology that allows you to analyze your Spanner data via services such as BigQuery, Spark on Dataproc, or Dataflow — all with virtually no impact to your transactional workloads. We also made it easier to ingest data from BigQuery back to operational databases like Bigtable, our HBase-compatible, NoSQL database, with just a few clicks. With the new BigQuery Export to Bigtable feature, you can serve analytical insights from your applications without having to touch any ETL tools.Unified data management and governance – We introduced intelligent data profiling and data quality capabilities to help you understand completeness, accuracy and validity of your data. We also launched extended data management and governance capabilities in Dataplex. Now, you have a single experience for all your data and AI assets, including Vertex AI models and datasets, operational databases, and analytical systems.Unification of all types of data – BigLake lets you work with data of any type, in any location. You no longer have to worry about underlying storage formats and can reduce cost and inefficiencies because BigLake is deeply integrated with BigQuery. We launched the general availability of BigLake Object Tables to help data users easily access, transverse, process and query unstructured data like images, audio and documents using SQL. BigLake is in hyper-growth; just since the beginning of this year, there has been a 27x increase in BigLake usage.
Run all your data where it is, with an open data ecosystem
Google Cloud provides industry leading integration with open source and open APIs, helping to ensure portability, flexibility, and reducing the risk of vendor lock-in. These integrations include BigQuery Migration Service to accelerate migration from traditional data warehouses and the Database Migration Service to help you migrate and modernize your operational databases. You can also take advantage of our managed database services that are fully compatible with popular open-source engines such as PostgreSQL, MySQL, and Redis.
We continue to focus on making Google Cloud the most open data cloud. Some recent launches in this area include:
Analyze BigQuery data in other clouds – Many of our customers manage and analyze their data on Google Cloud, AWS or Azure with BigQuery Omni which provides a single pane of glass across clouds. Taking BigQuery Omni one step further, we added support for cross-cloud materialized views, and cross-cloud joins. In the past six months, BigQuery Omni saw over 120% growth in data processed by customers while querying across AWS, and Azure environments.Run AlloyDB virtually anywhere – We announced the general availability of AlloyDB Omni, the downloadable edition of AlloyDB that runs virtually anywhere — on Google Cloud, AWS, Azure, Google Distributed Cloud Hosted, on-premises, and even on developer laptops. AlloyDB Omni provides the flexibility to run the same enterprise-class database, AlloyDB for PostgreSQL, across all your environments, backed by Google’s enterprise support organization, and at a fraction of the cost of legacy databases. We also launched the preview of the AlloyDB Omni Kubernetes operator, which simplifies common database tasks including database provisioning, backups, secure connectivity, and observability, allowing you to run AlloyDB Omni in most Kubernetes environments.Support for open table formats – We launched the availability in BigLake for Hudi, Delta, and Iceberg tables. This allows customers to use streaming ingestion for data in Google Cloud storage and gain a fully managed experience with automatic storage optimizations, as well as perform DML transactions to enable consistent modifications and improved data security, all while retaining full Iceberg reader compatibility.Enhance performance for enterprise workloads – We announced Enterprise Plus edition for MySQL and PostgreSQL, providing new availability, performance, and data protection enhancements in Cloud SQL. Cloud SQL Enterprise Plus edition for MySQL delivers up to three times higher performance than Amazon’s comparable MySQL service. We’ve also been working on supercharging our Memorystore for Redis offering with a brand new fully managed offering, Memorystore for Redis Cluster which is now generally available. With Memorystore for Redis Cluster, you get an easy-to-use, open-source-compatible Redis Cluster service that provides up to 60 times more throughput than Memorystore for Redis, with microseconds latencies.
We’ve also significantly expanded our data cloud partner ecosystem, and are increasing our partner investments across many new areas. Today, more than 1,000 software partners are building their products using Google’s data cloud, and more than 70 data platform partners offer validated integrations through our Google Cloud Ready – BigQuery initiative. We also announced Google Cloud Ready for Cloud SQL, a program that recognizes partner solutions that have met integration requirements with Cloud SQL. This program joins our existing Google Cloud Ready for AlloyDB partner program.
Unlock new value from data with integrated AI
AI provides numerous opportunities to activate your data. So, we made AI easily accessible to all your data teams and also made it effortless to use your data to train AI models. Here are some recent launches:
Easily build enterprise gen AI apps – We introduced AlloyDB AI, an integral part of AlloyDB, which offers an integrated set of capabilities for easily building enterprise gen AI apps, everywhere. AlloyDB AI runs vector queries up to 10x faster compared to standard PostgreSQL when using the IVFFlat index, allows you to easily generate embeddings from within your database, and fully integrates with Vertex AI and open-source gen AI tools. We also launched the preview of BigQuery feature tables and vector embeddings to store all your ML features and vector embeddings. This allows you to build powerful semantic searches and do recommendation queries on the scale of your BigQuery data in real-time.Access to foundational models – We enabled users to access our Vertex AI’s foundation models directly from BigQuery. With just a single statement, you can connect a BigQuery table to a large language model (LLM) and tune prompts with your BigQuery data. This allows you to use gen AI capabilities such as text analysis on your data or generate new attributes to enrich your data model. Additionally, we launched BigQuery ML inference engine that allows you to embrace the ecosystem of pretrained models and open ML frameworks. It helps you run predictions on Google vision, natural language and translation models in BigQuery, import models in additional formats like TensorFlow Lite, ONNX and XGBoost, and directly use models hosted in Vertex AI.Enhance productivity with Duet AI – We launched Duet AI in BigQuery to simplify data analysis, generate code and assist with writing SQL queries and Python code, allowing you to focus more on logic and outcomes. We also announced Duet AI in Spanner, which allows you to generate code to structure, modify, or query your data using natural language. And to make it even easier to modernize your Oracle databases, we brought the power of Duet AI to the last mile of Oracle to PostgreSQL migrations with Duet AI in Database Migration Service. Finally, Duet AI in Dataplex can be used for metadata insights to solve the cold-start problem — how do I know which questions I can ask my data?
We are honored to be recognized as a Leader in the 2023 Gartner Magic Quadrant for Cloud Database Management Systems.
What’s next
We look forward to continuing to innovate and partner with you on your digital transformation journey. Download the complimentary 2023 Gartner Magic Quadrant for Cloud Database Management Systems report.
2023 Gartner Magic Quadrant for Cloud Database Management Systems, Adam Ronthal, Henry Cook, Rick Greenwald, Aaron Rosenbaum, Ramke Ramakrishnan, Xingyu Gu, December 18, 2023.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s Research and Advisory organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademarks and service mark, and MAGIC QUADRANT is a registered trademark of Gartner, Inc. and/or its affiliates in the US and internationally and are used herein with permission. All rights reserved. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from Google.