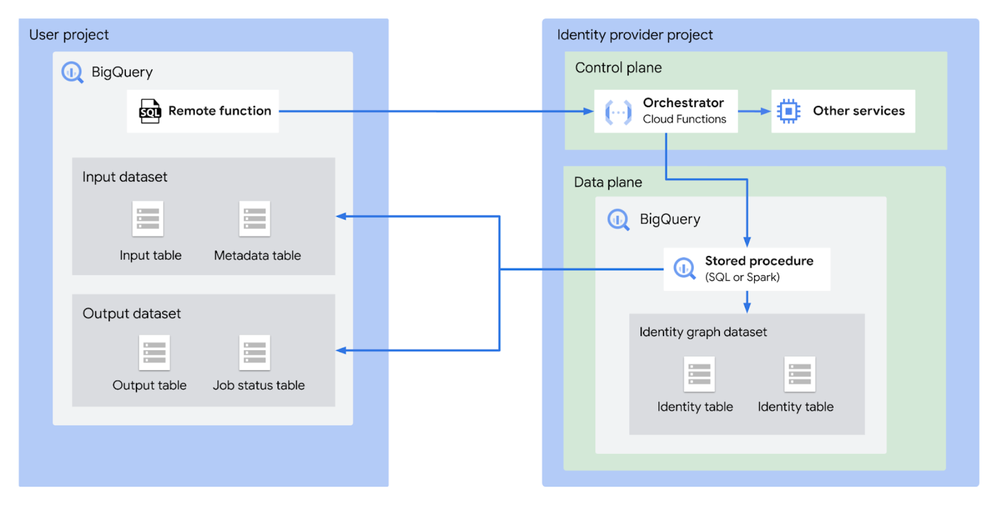
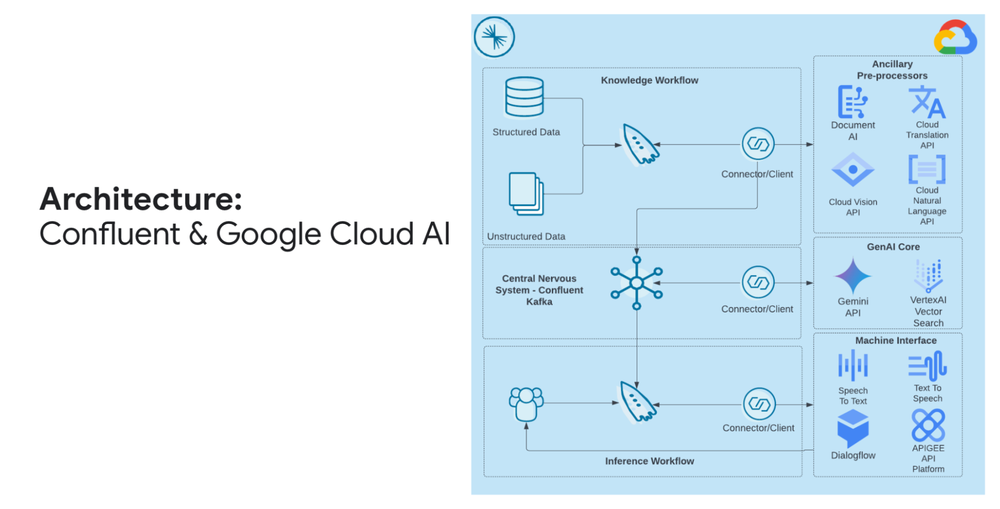
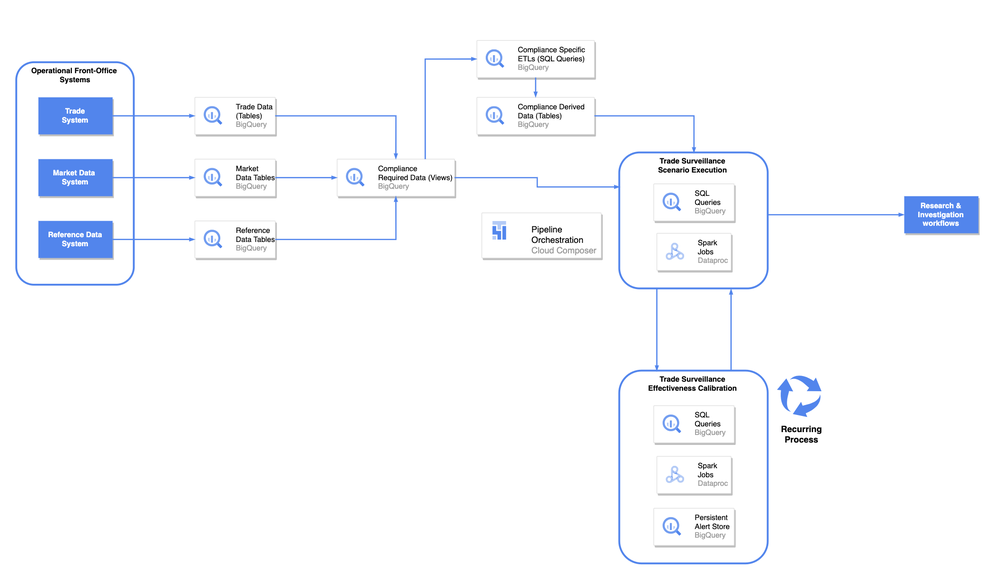
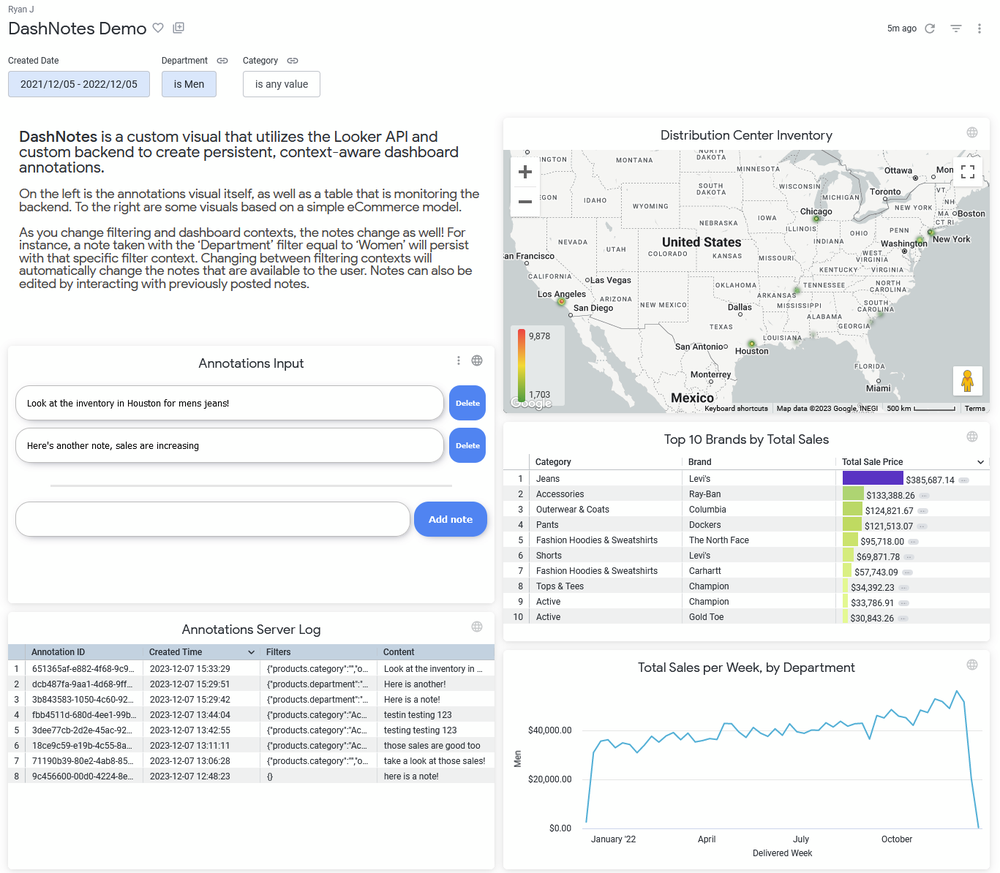
How Livesport activates data and saves engineering resources with BigQuery and Dataddo

Today, organizations can build a robust, end-to-end data infrastructure with a fraction of the in-house engineering resources. Livesport — a provider of real-time data, results, and statistics for virtually all sporting events around the globe — recognized this early on when building their data team.
Livesport was already using BigQuery as a data warehouse for all layers of their infrastructure, but the company didn’t want to build a data team based on syncing data to BigQuery from other databases and non-Google sources. Instead, Livesport sought a solution from Dataddo, a recognized Google Cloud Ready data integration partner for BigQuery.
Offloading data integration tasks to a dedicated tool
Livesport’s data team has strong SQL skills, so it was important to give the team space to focus on data activation and analytics while outsource engineering workloads associated with data automation and ingestion.
The data team was already syncing data from Google services like GA4 and Google Ads to BigQuery, which cost them nothing to maintain thanks to native integrations. However, they needed a tool that could sync a mountain of data from sources outside the Google ecosystem, such as Livesport’s internal databases (e.g., sports data and data from their app), ERP system, third-party services, social media accounts, and affiliate partner APIs.
At the same time, Livesport was also looking for a solution that could provide some other nice-to-haves that could help reduce the burden on the data team. These benefits included fixed pricing due to high fluctuation in the amount of data synced monthly, close support to connect data from unique internal solutions, and a willingness to build out new connectors quickly if needed.
Flexible, customizable, end-to-end connectivity with Dataddo
Livesport first evaluated another popular data integration tool, but eventually chose Dataddo because it met all their essential criteria and more.
With Dataddo, Livesport can:
Connect data from all of its sources to BigQuery, including internal databases (via CDC data replication), third-party services, custom sources, and affiliate partner APIs.Gain real-time support from dedicated specialists, with a Slack channel where specialists from both sides can interact and collaborate to implement custom integrations.Build new connectors within 10 days, free of charge.Ensure no surprises at the end of billing periods with fixed pricing.
Livesport is also taking advantage of Dataddo capabilities that go beyond their initial requirements. For example, Dataddo makes it easy to connect online services with business intelligence (BI) tools. The no-code user interface enables Livesport’s business teams, such as marketing, to flexibly sync data from apps like Facebook with BI systems to gain ad-hoc insights — without intervention from the data team. Dataddo also allows Livesport to import offline conversion data from BigQuery directly into Google Ads and even provides an added layer of security with reverse SSH tunneling.
Less engineering, bigger BI team
By outsourcing data engineering tasks to Dataddo, Livesport’s data team is now free to fully capitalize on the analytics capabilities of BigQuery. They can also spend more time using other Google Cloud Platform services like Vertex AI, BigQueryML, and Cloud Functions to enrich data and then send it downstream to end users.
“We save about 70% of the time it would otherwise take to ingest all our data, or 3-4 full-time equivalents, and spend this much more time on data analytics and activation. We only have one full-time data engineer, who does more than just collect data, while our BI team consists of 11 members,” said Zdeněk Hejnak, Data development Team Leader at Livesport.
Livesport is also testing Dataddo’s reverse ETL capabilities to automate the import of offline conversion data from BigQuery to Google Ads — a cutting-edge way to optimize ad spend and punctually target qualified prospects.
“We’re constantly looking for new opportunities to get more from our data, so reverse ETL to Google Ads is a promising direction,” Hejnak said.
To learn more about Dataddo, visit the Google Cloud partner directory or Dataddo’s Marketplace offerings. If you’re interested in using Dataddo for BigQuery, check out Dataddo’s BigQuery Connector and learn more about Google Cloud Ready – BigQuery.
Source : Data Analytics Read More