The advent of advanced AI and machine learning (ML) technologies has revolutionized the way organizations leverage their data, offering new opportunities to unlock its potential. Today, we’re announcing the public preview of vector search in BigQuery, which enables vector similarity search on BigQuery data. This functionality, also commonly referred to as approximate nearest-neighbor search, is key to empowering numerous new data and AI use cases such as semantic search, similarity detection, and retrieval-augmented generation (RAG) with a large language model (LLM).
Vector search is often performed on high-dimensional numeric vectors, a.k.a. embeddings, which incorporate a semantic representation for an entity and can be generated from numerous sources, including text, image, or video. BigQuery vector search relies on an index to optimize the lookups and distance computations required to identify closely matching embeddings.
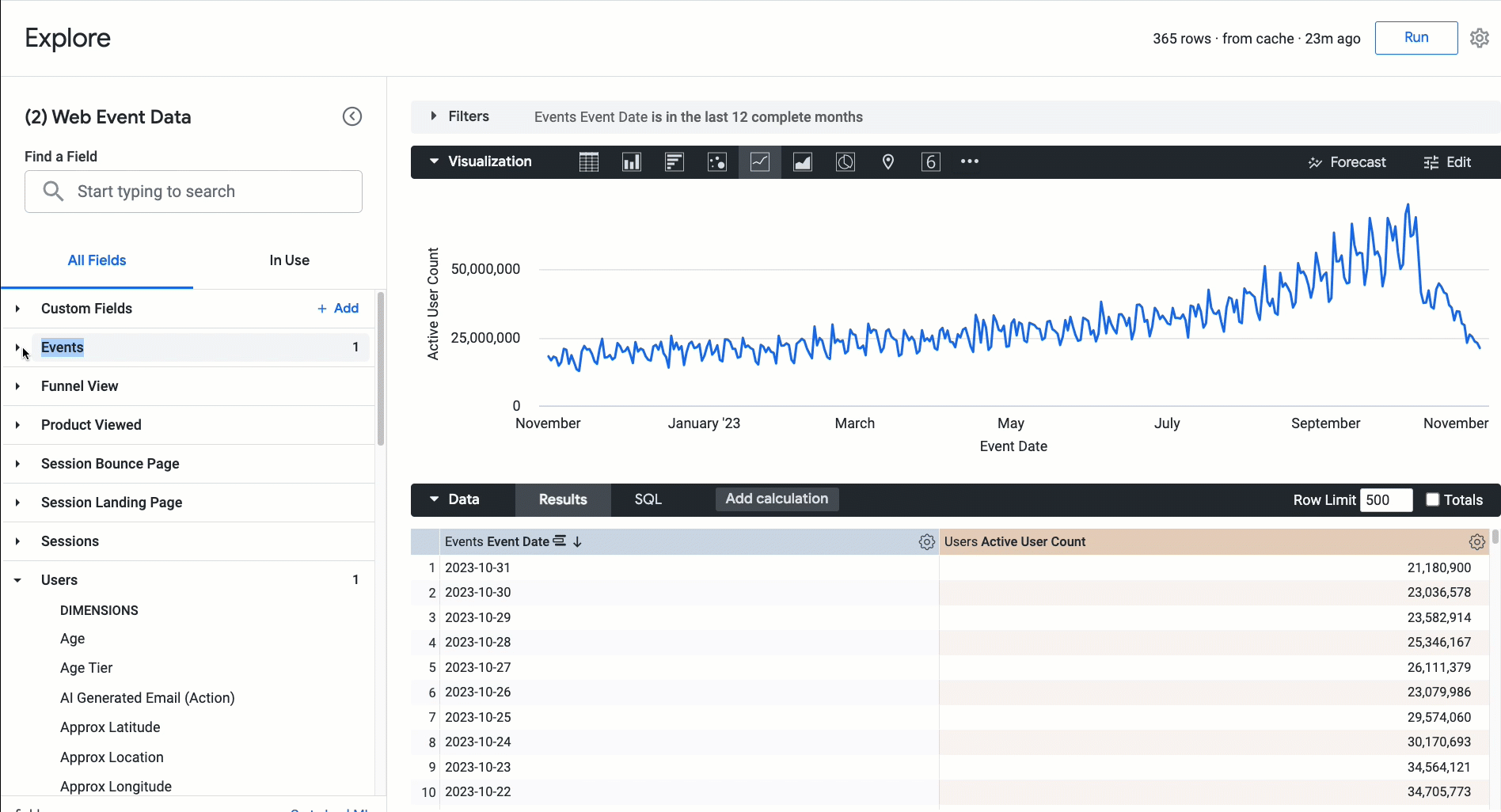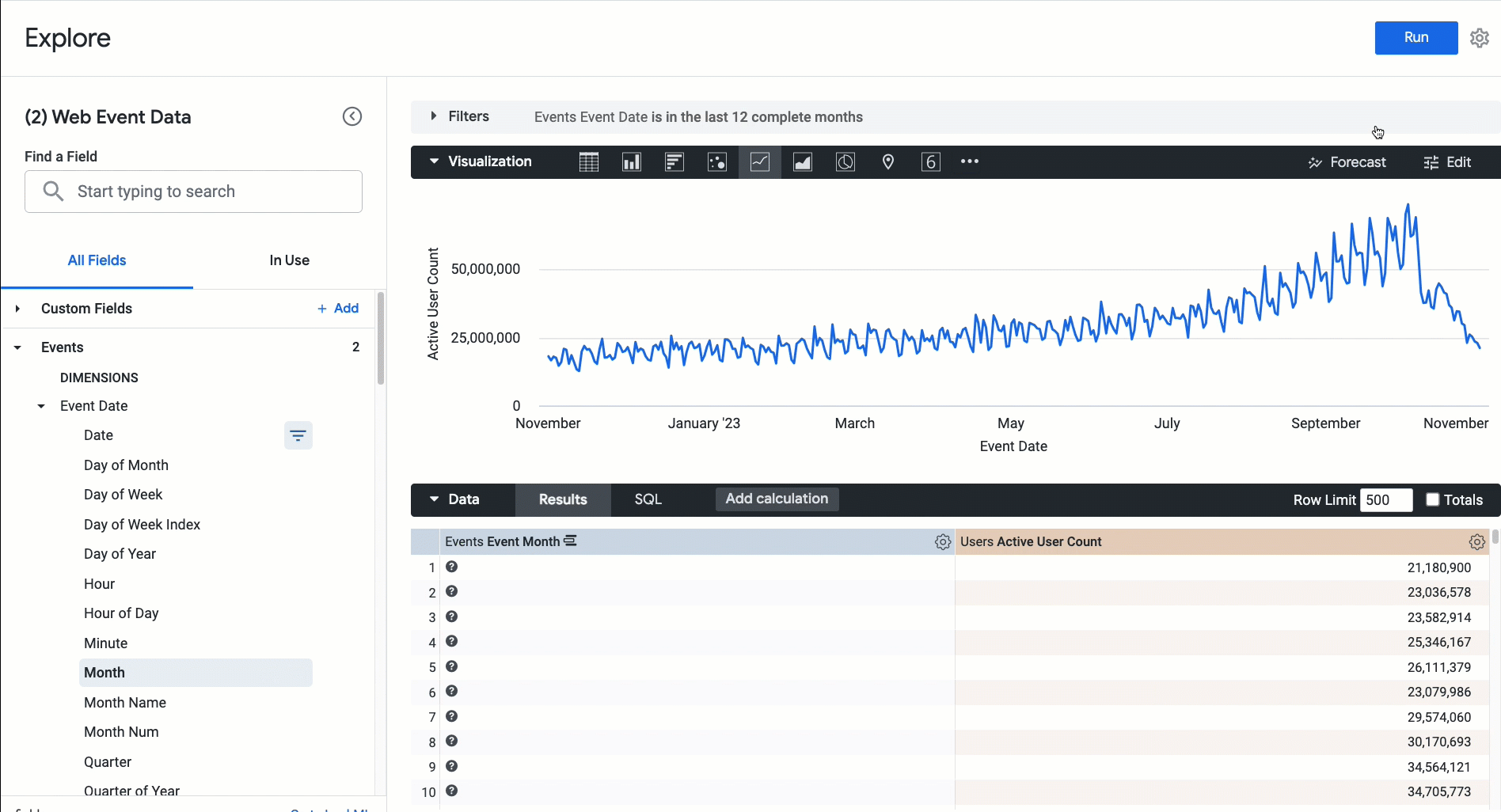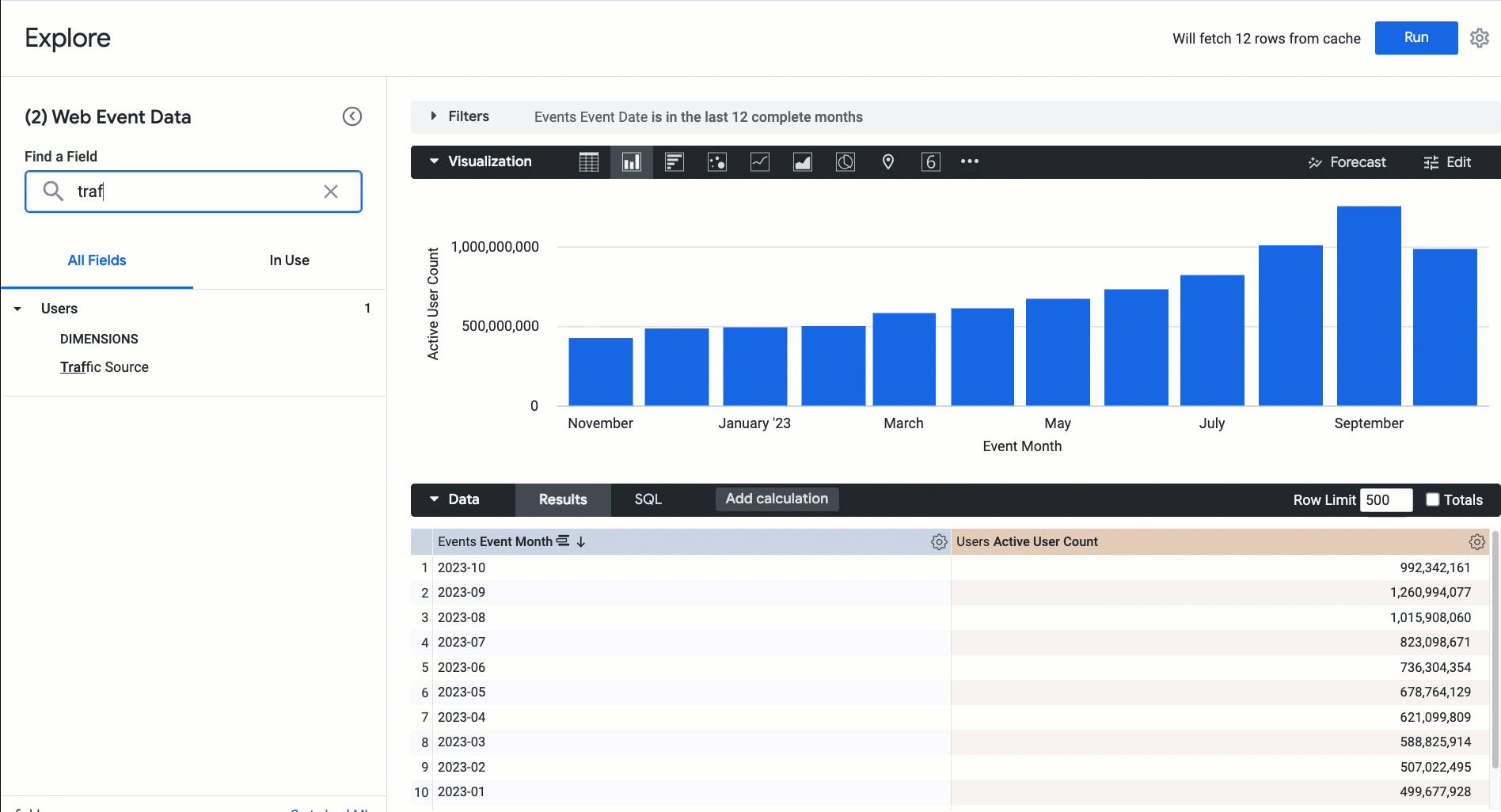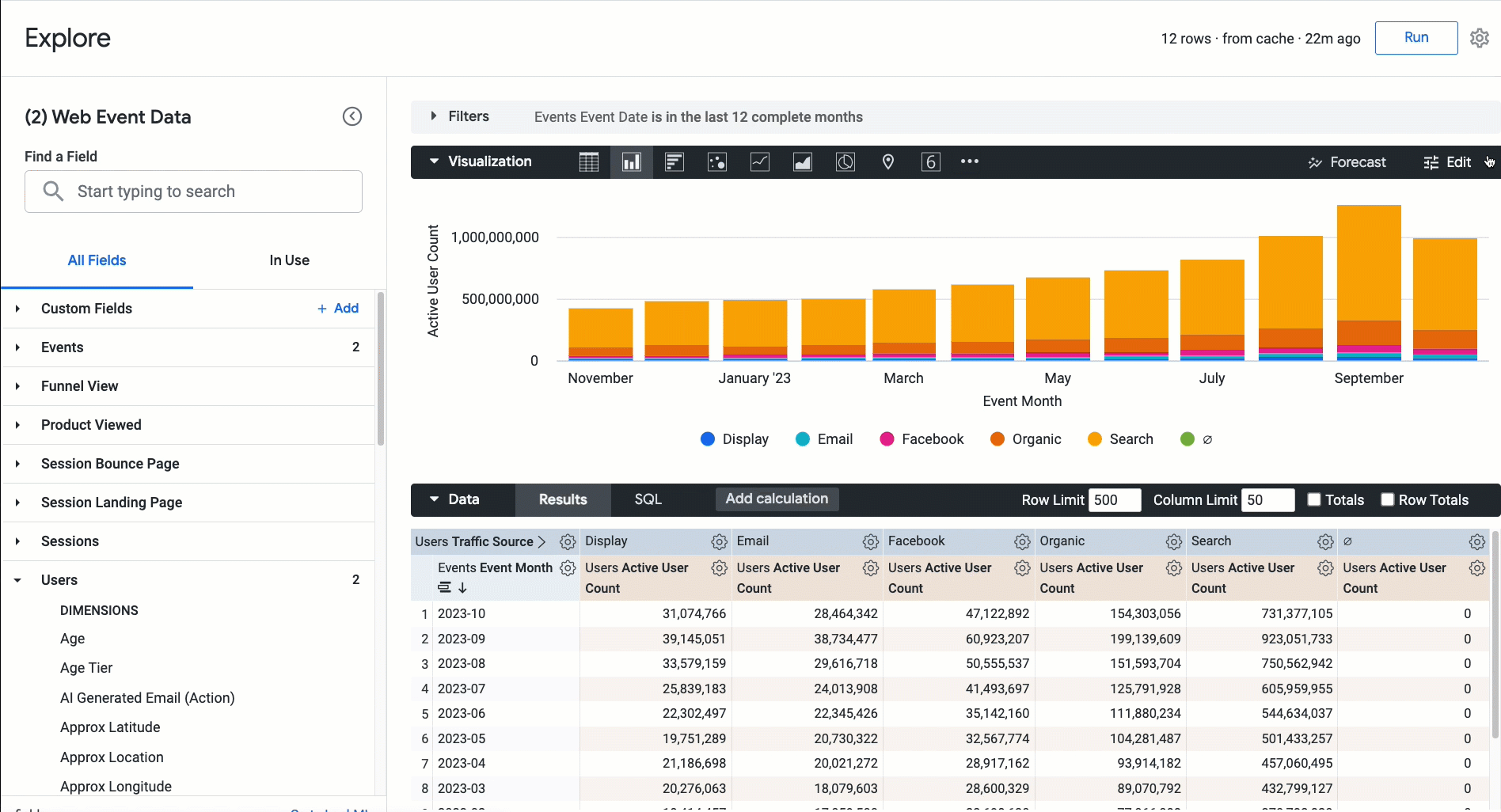
Here is an overview of BigQuery vector search:
It offers a simple and intuitive CREATE VECTOR INDEX and VECTOR_SEARCH syntax that is similar to BigQuery’s familiar text search functionality. This simplifies combining vector search operations with other SQL primitives, enabling you to process all your data at BigQuery scale.It works with BigQuery’s embedding generation capabilities, notably via LLM-based or pre-trained models. Yet the generic interface allows you to use embeddings generated via other means as well.BigQuery vector indexes are automatically updated as the underlying table data mutates, with the ability to easily monitor indexing progress. This extensible framework can support multiple vector index types, with the first implemented type (IVF) combining an optimized clustering model with an inverted row locator in a two-piece index.The LangChain implementation simplifies Python-based integrations with other open-source and third-party frameworks.The VECTOR_SEARCH function is optimized for analytical use cases and can efficiently process large batches of queries (rows). It also delivers low-latency inference results when handling small input data. Faster, ultra-low-latency online prediction can be performed on the same data through our integration with Vertex AI.It’s integrated with BigQuery’s built-in governance capabilities, notably row-level, data masking, and column-level security policies.
Use cases
The combination of embedding generation and vector search enables many interesting use cases, with RAG being a canonical one. The examples below provide high-level algorithmic descriptions for what can be encoded in your data application or queries using vector search:
Given a new (batch of) support case(s), find ten closely-related previous cases, and pass them to an LLM as context to summarize and propose resolution suggestions.Given an audit log entry, find the most closely matching entries in the past 30 days.Generate embeddings from patient profile data (diagnosis, medical and medication history, current prescriptions, and other EMR data) to do similarity matching for patients with similar profiles and explore successful treatment plans prescribed to that patient cohort.Given the embeddings representing pre-accident moments from all the sensors and cameras in a fleet of school buses, find similar moments from all other vehicles in the fleet for further analysis, tuning, and re-training of the models governing the safety feature engagements.Given a picture, find the most closely-related images in the customer’s BigQuery object table, and pass them to a model to generate captions.
BigQuery-based RAG deep dive
BigQuery enables you to generate vector embeddings and perform vector similarity search to improve the quality of your generative AI deployments with RAG. You can find some some steps and tips below:
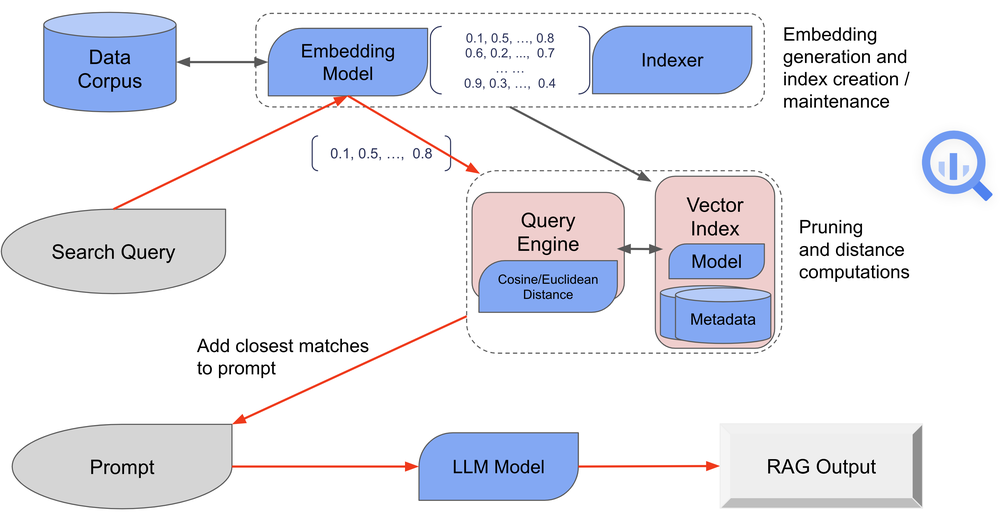
You can generate vector embeddings from text data using a range of supported models, including LLM-based ones. These models effectively understand the context and semantics of words and phrases, allowing them to encode the text into vectors that represent its meaning in a high-dimensional space.With BigQuery’s scale and ease of use, you can store these embeddings in a new column, right alongside the data it was generated from. You can then perform queries against these embeddings or build an index to improve retrieval performance.Efficient and scalable similarity search is crucial for RAG, as it allows the system to quickly find the most relevant pieces of information based on the query’s semantic meaning. Vector similarity search involves efficiently searching through millions or billions of vectors from the vector data store to find the most similar vectors. BigQuery vector search uses its indexes to efficiently find the closest matching vectors according to a distance measurement technique such as cosine or euclidean.When doing prompt engineering with RAG, the first step involves converting the input into a vector using the same (or a similar) model to that used for encoding the knowledge base. This ensures that the query and the stored information are in the same vector space, making it possible to measure similarity.The vectors identified as most similar to the query are then mapped back to their corresponding text data. This text data represents the pieces of information from the knowledge base that are most likely to be relevant to the query.The retrieved text data is then fed into a generative model. This model uses the additional context provided by the retrieved information to generate a response that is not only based on its pre-trained knowledge, but also enhanced by the specific information retrieved for the query. This is particularly useful for questions that require up-to-date information or detailed knowledge on specific topics.
The diagram below provides a simplified view of the RAG workflow in BigQuery:
Publication search and RAG examples
In the next three sections, we use the `patents-public-data.google_patents_research.publications` table in the Google Patents public dataset table as a running example to highlight three (of the many) use cases BigQuery vector search enables.
Case 1: Patent search using pre-generated embedding
One of the most basic use cases for BigQuery vector search is performing similarity search using data with pre-generated embeddings. This is common when you intend to use embeddings that are previously generated from proprietary or pre-trained models. As an example, if you store your data and queries in <my_patents_table> and <query_table> respectively, the search journey would consist index creation, followed by vector search:
code_block
<ListValue: [StructValue([(‘code’, “CREATE OR REPLACE VECTOR INDEX `<index_name>`rnON `<my_patents_table>`(embedding_v1)rnOPTIONS(distance_type=’COSINE’, index_type=’IVF’)”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e857331cfa0>)])]>
Note that indexing is mainly a performance optimization mechanism for approximate nearest-neighbor search, and vector search queries can succeed and return correct results without an index as well. For more details, including specifics on recall calculation, please see this tutorial.
Case 2: Patent search with BigQuery embedding generation
You can achieve a more complete end-to-end semantic search journey by using BigQuery’s capabilities to generate embeddings. More specifically, you can generate embeddings in BigQuery via LLM-based foundational or pre-trained models. The SQL snippet below assumes you have already created a BigQuery <LLM_embedding_model> that references a Vertex AI text embedding foundation model via BigQuery (see this tutorial for more details):
code_block
<ListValue: [StructValue([(‘code’, “CREATE TABLE `<patents_my_embeddings_table>` ASrn SELECT * FROM ML.GENERATE_TEXT_EMBEDDING(rn MODEL `<LLM_embedding_model>`,rn (SELECT *, abstract AS contentrn FROM `patents-public-data.google_patents_research.publications`rn WHERE LENGTH(abstract) > 0 AND LENGTH(title) > 0 AND country = ‘Singapore’))rn WHERE ARRAY_LENGTH(text_embedding) > 0;”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e857074ec70>)])]>
We skip demonstrating the index-creation step, as it is similar to “Case 1” above. After the index is created, we can use VECTOR_SEARCH combined with ML.GENERATE_TEXT_EMBEDDING to search related patents. Below is an example query to search patents related to “improving password security”:
code_block
<ListValue: [StructValue([(‘code’, “SELECT query.query, base.publication_number, base.title, base.abstractrnFROM VECTOR_SEARCH(rn TABLE `<patents_my_embeddings_table>`, ‘text_embedding’,rn (SELECT text_embedding, content AS queryrn FROM ML.GENERATE_TEXT_EMBEDDING(rn MODEL `<LLM_embedding_model>`,rn (SELECT ‘improving password security’ AS content))rn ), top_k => 5)”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8572fdee80>)])]>
Case 3: RAG via integration with generative models
BigQuery’s advanced capabilities allow you to easily extend the search cases covered above into full RAG journeys. More specifically, you can use the output from the VECTOR_SEARCH queries as context for invoking Google’s natural language foundation (LLM) models via BigQuery’s ML.GENERATE_TEXT function (see this tutorial for more details).
The sample query below demonstrates how you can ask the LLM to propose project ideas to improve user password security. It uses the top_k patents retrieved via semantic similarity vector search as context passed to the LLM model to ground its response:
code_block
<ListValue: [StructValue([(‘code’, ‘SELECT ml_generate_text_llm_result AS generated, promptrnFROM ML.GENERATE_TEXT(rn MODEL `<LLM_text_generation_model>`,rn (SELECT CONCAT(‘Propose some project ideas to improve user password security using the context below: ‘, STRING_AGG(FORMAT(“patent title: %s, patent abstract: %s”, base.title, base.abstract), ‘,\n’)) AS prompt,rn FROM VECTOR_SEARCH(rn TABLE `<patents_my_embeddings_table>`, ‘text_embedding’,rn (SELECT text_embedding, content AS queryrn FROM ML.GENERATE_TEXT_EMBEDDING(rn MODEL `<LLM_embedding_model>`,rn (SELECT ‘improving password security’ AS content))rn ), top_k => 5)rn ),rn STRUCT(0.4 AS temperature, 300 AS max_output_tokens, 0.5 AS top_p, 5 AS top_k,rn TRUE AS flatten_json_output));’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e8572fdef10>)])]>
Getting started
BigQuery vector search is now available in preview. Get started by following the documentation and tutorial.
In December, the Looker team invited our developer and data community to collaborate, learn, and inspire each other at our annual Looker Hackathon. More than 400 participants from 93 countries joined together, hacked away for 48 hours and created 52 applications, tools, and data experiences. The hacks use Looker and Looker Studio’s developer features, data modeling, visualizations and other Google Cloud services like BigQuery and Cloud Functions.
For the first time in Looker Hackathon history, we had two hacks tie for the award of the Best Hack. See the winners below and learn about the other finalists from the event. In every possible case, we have included links to code repositories or examples to enable you to reproduce these hacks.
Best Hack winners
DashNotes: Persistent dashboard annotations
By Ryan J, Bartosz G, Tristan F
Have you ever wanted to take note of a juicy data point you found after cycling through multiple filterings of your data? You could write your notes in an external notes application, but then you might lose the dashboard and filter context important to your discovery. This Best Hack allows you to take notes right from within your Looker dashboard. Using the Looker Custom Visualization API, it creates a dashboard tile for you to create and edit text notes. Each note records the context around its creation, including the original dashboard and filter context. The hack stores the notes in BigQuery to persist the notes across sessions. Check out the GitHub repository for more details.
Document repository sync automation
By Mehul S, Moksh Akash M, Rutuja G, Akash
Does your organization struggle to maintain documentation on an increasing number of ever-changing dashboards? This Best Hack helps your organization automatically generate current detailed documentation on all your dashboards, for simplified administration. The automation uses the Looker SDK, the Looker API, and serverless Cloud Functions to parse your LookML for useful metadata, and stores it in BigQuery. Then the hack uses LookML to model and display the metadata inside a Looker dashboard. Checkout the GitHub repository for the backend service and the GitHub repository for the LookML for more details.
Nearly Best Hack winner
Querying Python services from a Looker dashboard
By Jacob B, Illya M
If your Looker dashboard had the power to query any external service, what would you build? This Nearly Best Hack explores how your Looker Dashboard can communicate with external Python services. It sets up a Python service to mimic a SQL server and serves it as a Looker database connection for your Looker dashboard to query. Then, clever LookML hacks enable your dashboard buttons to send data to the external Python service, creating a more interactive dashboard. This sets up a wide array of possibilities to enhance your Looker data experience. For example, with this hack, you can deploy a trained ML model from Google Cloud’s Vertex AI in your external service to deliver keen insights about your data. Check out the GitHub repository for more details.
Finalists
What do I watch?
By Hamsa N, Shilpa D
We’ve all had an evening when we didn’t know what movie to watch. You can now tap into a Looker dashboard that recommends ten movies you might like based on your most liked movie from IMDB’s top 1000 movies. The hack analyzes a combination of genre, director, stars, and movie descriptions, using natural language processing techniques. The resulting processed data resides in BigQuery, with LookML modeling the data. Check out the GitHub repository for more details.
Template analytics
By Ehsan S
If you need to determine which customer segment will be most effective to market to, check out this hack, which performs Recency, Frequency, Monetary (RFM) analysis on data from a Google Sheet to help you segment customers based on their last transaction recency, how often they’ve purchased, and how much they’ve spent over time. You provide the custom Looker Studio Community Connector, along with a Google Sheet, and the connector performs RFM analysis on your Google Sheet’s data. The hack’s Looker Studio report visualizes the results to give an overview of your customer segments and behavior. Check out the Google Apps Script code for more details.
LOV filter app
By Markus B
This hack implements a List of Values (LOV) filter that enables you to have the values of one dimension filter a second dimension. For example, take two related dimensions: “id” and “name”. The “name” dimension may change, while the “id” dimension always stays constant.
This hack uses Looker’s Extension Framework and Looker Components to show “name” values in the LOV filter that translate to “id” values in an embedded dashboard’s filter. This helps your stakeholders filter on values they’re familiar with and keeps your data model flexible and robust. Check out the GitLab repository for more details.
Looker accelerator
By Dmitri S, Joy S, Oleksandr K
This collection of open-source LookML dashboard templates provides insight into Looker project performance and usage. The dashboards use Looker’s System Activity data and are a great example of using LookML to create reusable dashboards. In addition, you can conveniently install the Looker Block of seven dashboards through the Looker Marketplace (pending approval) to help your Looker developer or admin to optimize your Looker usage. Check out the GitHub repository for more details.
The SuperViz Earth Explorer
By Ralph S
With this hack, you can visually explore the population and locations of cities across the world on an interactive 3D globe, and can filter the size of the cities in real time as the globe spins. This custom visualization uses the Looker Studio Community Visualization framework with the clever combination of three.js, a 3D Javascript library, and clever graphics hacks to create a visual experience. Check out the GitHub repository for more details.
dbt exposure generator
By Dana H.
Are you using dbt models with Looker? This hack automatically generates dbt exposures to help you debug and identify how your dbt models are used by Looker dashboards. This hack serves as a great example of how our Looker SDK and Looker API can help solve a common pain point for developers. Check out the GitHub repository for more details.
Hacking Looker for fun and community
At Looker Hackathon 2023, our developer community once again gave us a look into how talented, creative, and collaborative they are. We saw how our developer features like Looker Studio Community Visualizations, LookML, and Looker API, in combination with Google Cloud services like Cloud Functions and BigQuery, enable our developer community to build powerful, useful — and sometimes entertaining — tools and data experiences.
We hope these hackathon projects inspire you to build something fun, innovative, or useful for you. Tap into our linked documentation and code in this post to get started, and we will see you at the next hackathon!
Self-service analytics powered by ML and generative AI is the new holy grail for data-driven enterprises, enabling enhanced decision-making through predictive insights, and providing a significant boost in operational efficiency and innovation. C-level executives increasingly see self-service analytics as the key driver of employee productivity and business efficiency.
Today, technical practitioners employ a variety of open-source libraries, including Apache Spark, Ray, pandas, sk-learn, h20 and many more to create analytics and ML applications. This entails writing a lot of code, which has a steep learning curve. Additionally, developing front-end interfaces for business users to interact with the systems in a secure and scalable manner takes a long time.
Enterprises also face challenges in hiring and retaining data-science experts and incur overhead costs for managing a large number of heterogeneous tools and technologies. Handling a growing variety and volume of data from siloed sources is a huge barrier to analytics initiatives. Lack of seamless workload scaling slows business solutions development.
Democratizing analytics and building ML applications are best done when business users and IT teams are empowered with services offered by cloud technology through intuitive, easy-to-use workflows, analytical apps, and conversational interfaces.
This brings out the strong need for a unified self-service platform made for all users to create and launch business solutions powered by cloud.
Sparkflows
Sparkflows is a Google Cloud partner that provides a powerful platform packed with self-service analytics, ML and gen AI capabilities for building data products. Sparkflows help integrate diverse open-source technologies through intuitive user-driven interfaces.
With Sparkflows, data analytics teams can turbocharge the development of ETL, exploratory analytics, feature engineering, ML models and gen AI apps using 460+ no-code/ low-code processors, and various workbenches as shown below.
Sparkflows has developed a large number of solutions for the sales and marketing, manufacturing and supply chain departments of retail and CPG customers.
Business scenarios using Sparkflows and Google Cloud
Let’s assume the engineering team of a retail company needs to empower the marketing team with a self-service analytics tool that can identify the customers who are likely to churn, and measure the effectiveness of the campaigns by analyzing the coupon responsiveness, sales, and demographic data.
The team needs to ingest and prepare data quickly, build ML models, analytics reports and gen AI apps in an automated fashion where Spark code will be generated and jobs will be submitted to a Dataproc cluster effortlessly.
Installation
As the first step, Sparkflows is installed inside the customer’s secure VPC network either on a virtual machine or in a container running in Google Cloud. Sparkflows runs securely with built-in SSO integration.
Sparkflows enables a unified experience for continuous machine learning.
Let’s now discuss the steps required to identify customers who are likely to churn and the ability to analyze the reviews by customers to measure satisfaction. This process involves:
Sparkflows connects with various Google Cloud services for performing the above operations (Ref: Interaction diagram: Sparkflows and Google Cloud).
Datasets
In this example, the datasets (customer transactions, campaigns, coupons and demographic info) are stored in BigQuery and product review data is in Cloud Storage. Business users can select a domain like retail and then view all the datasets stored in Google Cloud within Sparkflows. Users can browse files in Cloud Storage, explore and query BigQuery tables. Sparkflows dataset explorer seamlessly connects with Data Catalog.
Data preparation
Users can rapidly design various workflows for ingesting the datasets and performing data profiling, automated quality checks, cleaning and exploratory analysis using 350+ no-code/low-code data preparation processors. All these workflows help automate the Spark code generation and functionality development for the current business solution, cutting down the engineering time from weeks to hours.
Each of the visual workflows results in the automatic creation of a Spark job which is launched on Dataproc Serverless. Dataproc Serverless is an ideal platform for running these jobs. It is a highly performant and cost-effective distributed computing platform that is able to quickly spin up additional compute resources as needed. The platform is also very cost-effective as customers are only billed for resources for the duration of the job execution.
ML model training
Data scientists and analysts can perform feature engineering to calculate various aggregated metrics from the data processed by workflows designed in previous steps. Developers can leverage 80+ No Code/Low Code ML processors to create an ML modeling workflow. The features are used for training a model which can predict customers most likely to churn.
The features based on purchase pattern and coupon redemption information are used for creating the segments of customers
ML model prediction
Below is an example of the Prediction workflow for churn prediction.
The Prediction workflow can be triggered manually, via the built-in scheduler, through the API, or using the Analytical App UI.
ML Model Prediction Workflow
Visualization – descriptive and predictive analytics
Business users can drag the nodes used in workflows in the report designer UI and create powerful reports, which allow data scientists to inspect profiling stats, data quality results, exploratory insights, training metrics and prediction outputs.
When the underlying workflows are executed in a Dataproc cluster, the reports are automatically refreshed.
Reports of descriptive and predictive analytics
Business analytical apps
Business analytical apps in Sparkflows let business users build front-end applications for data products. Business users interact with these apps using their browsers. The analytical apps are built with an interactive UI.
Gen AI apps
Now, let’s build a few gen AI apps to allow the business team perform the following operations:
Ask questions from the product review dataSummarize, extract topics and translate texts
The first step is to configure the Vertex PaLM API connection in the admin console and select the connection in the Analytical App.
Allow users to query product reviews and gain insights
Allow users to translate and query documents
This is how Sparkflows helps sales and marketing teams of a retail company identify potential customer churn, measure campaign effectiveness, find target customer segments, and analyze product reviews and business documents.
ML solutions
It enables a wide range of gen AI apps, from content synthesis, content generation, and NLQ-based reports, to prompt-based business solutions.
Generative AI solutions
Better together
Having the ability to move fast with AI and generative AI is of great value to all types of enterprises. The partnership between Sparkflows and Google Cloud puts powerful and affordable self-serve AI and gen AI capabilities in the hands of the users in a secure and scalable way. Building gen AI solutions using Sparkflows and Google Cloud is highly affordable, thanks to Vertex’s highly cost-effective gen-ai pricing model and Sparkflows’ discounted pricing package. Overall, Sparkflows with Google Cloud drives operational efficiencies, accelerates business solutions, and speeds up time to market thereby propelling business growth.
Try out Sparkflows
Here are a few links to get started with Sparkflows and Google Cloud:
We thank the many Google Cloud and Sparkflows team members who contributed to this collaboration, especially Kaniska Mandal and Deb Dasgupta for their guidance during the process.
In recent years, there’s been a surge in the adoption of streaming analytics for a variety of use cases, for instance predictive maintenance to identify operational anomalies, and online gaming — creating player-centric games by optimizing experiences in real-time. At the same time, the rise of generative AI and large language models (LLMs) that are capable of generating and understanding text, has led us to explore new ways to combine the two to create innovative solutions.
In this blog post, we showcase how to get real-time LLM insights in an easy and scalable way using Dataflow. Our solution applies to a gameroom chat, but it could be used to gain insights into a variety of other types of data, such as customer support chat logs, social media posts, and product reviews — any other domain where real-time communication is prevalent.
Game chats: a goldmine of information
Consider a company seeking real-time insights from chat messages. A key challenge for many companies is understanding users’ evolving jargon and acronyms. This is especially true in the gaming industry, where “gg” means “good game” or “g2g” means “got to go.” The ideal solution would adapt to this linguistic fluidity without requiring pre-defined keywords.
For our solution, we looked at anonymized data from Kaggle of gamers chatting while playing Dota 2, conversing freely with one another via short text messages. Their conversations were nothing short of gold in our eyes. From gamers’ chats with one another, we identified an opportunity to quickly detect ongoing connection or delay issues, and by that ensure good quality of service (QoS). Similarly, gamers often talk about missing items such as tokens or game weapons, information we can also leverage to improve the gaming experience and its ROI.
At the same time, whatever solution we built had to be easy and quick to implement!
Solution components
The solution we built includes industry-leading Google Cloud data analytics and streaming tools, plus open-source gaming data and an LLM.
BigQuery stores the raw data and holds detection alerts.Pub/Sub, a Google Cloud serverless message bus, is used to decouple the streamed chat messages and the Dataflow pipeline.Dataflow, a Google Cloud managed service for building and running the distributed data processing pipeline, relies on the Beam RunInference transform for a simple and easy-to-use interface for performing local and remote inference.The DOTA 2 game chat dataset is taken from Kaggle -G game chats raw data.Google/Flan-T5 is the LLM model used for detection based on the prompt. It is hosted in Hugging Face.
Once we settled on the components, we had to choose the right prompt for the specific business use case. In this case, we settled on game chats latency detection.
We analyzed our gaming data, looking for keywords such as connection, delay, latency, lag, etc.
Example:
code_block
<ListValue: [StructValue([(‘code’, “SELECT text from GOSU_AI_Dota2_game_chats ‘rn’WHERE text LIKE ‘%latency%’ or text like ‘%connection%’ ‘”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed148cec3d0>)])]>
The following game id came up:
code_block
<ListValue: [StructValue([(‘code’, “SELECT text from summit2023.GOSU_AI_Dota2_game_chats ‘rn’WHERE match = 507332 ‘”), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3ed148cec0a0>)])]>
Here, we spotted a lot of lag and server issues:
match
time
slot
text
507332
68.31666
1
0 losees
507332
94.94348
3
i think server
507332
77.21448
4
quit plsss
507332
51.15418
3
lag
507332
319.15543
8
made in chine
507332
126.50245
9
i hope he doesnt reconnect
507332
315.65628
8
shir server
507332
62.85132
5
15 packet loses
507332
65.75062
3
wtfd lag
507332
289.02948
9
someone abandon
507332
445.02468
9
YESYESYES
507332
380.94034
3
lag wtf
507332
79.34728
4
quit lagger stupid shit
507332
75.21498
9
great game volvo
507332
295.66118
7
HAHAHA
After a few SQL query iterations, we managed to tune the prompt in such a way that the true positive was high enough to raise a detection alert, but agnostic enough to spot delay issues without providing specific keywords.
“Answer by [Yes|No] : does the following text, extracted from gaming chat room, can indicate a connection or delay issue : “
Our next challenge was to create a Dataflow pipeline that seamlessly integrated two key features:
Dynamic detection prompts: Users must be able to tailor detection prompts for diverse use cases, all while the pipeline is up and running — without writing any code.
Seamless model updates: We needed a way to swap in a better-trained model without interrupting the pipeline’s operation, ensuring continuous uptime — again, without writing any code.
To that end, we chose to use the Beam RunInference transform.
RunInference offers numerous advantages:
Data preprocessing and post-processing are encapsulated within the RunInference function and treated as distinct stages in the process. Why is this important? RunInference effectively manages errors associated with these stages and automatically extracts them into separate PCollections, enabling seamless handling as demonstrated in the code sample below.
RunInference’s automated model refresh mechanism is the watch file pattern. This enables us to update the model and load the newer version without halting and restarting the pipeline.
All with a few lines of code:
RunInference uses a “ModelHandler” object, which wraps the underlying model and provides a configurable way to handle the used model.There are different types of ModelHandlers; which one you choose depends on the framework and type of data structure that contains the inputs. This makes it a powerful tool and simplifies the building of machine learning pipelines.
Solution architecture
We created a Dataflow pipeline to consume game chat messages from a Pub/Sub topic. In the solution, we simulated the pipeline by reading the data from a BigQuery table and pushed it to the topic.
The Flan-T5 model is loaded into the workers’ memory and provided with the following prompt:
“Answer by [Yes|No] : does the following text, extracted from gaming chat room, indicate a connection or delay issue : “
A Beam side input PCollection, read from a BigQuery table, empowers various business detections to be performed within the Beam pipeline.
The model generates a [Yes|No] response for each message within a 60-second fixed window. The number of Yes responses is counted, and if it exceeds 10% of the total number of responses, the window data is stored in BigQuery for further analysis.
Conclusion:
In this blog post, we showcased how to use LLMs with Beam Dataflow’s RunInference function to gain insights about gamers chatting amongst themselves.
We used the RunInference transform with a loaded Google/Flan-t5 model to identify anything that indicates a system lag, without giving the model any specific words. In addition, the prompts can be changed in real time and be provided as a side input to the created pipeline. This approach can be used to gain insights into a variety of other types of data, such as customer support chat logs, social media posts, and product reviews.
Check out the Beam ML Documentation to learn more about integrating ML using the RunInference transform as part of your real-time Dataflow workstreams. For a Google Colab notebook on using RunInference for Generative AI, check out this link.
LookML is a powerful tool that applies business logic and governance to enterprise data analytics. However, LookML’s capabilities are often conflated with those of in-warehouse “ELT” transformation tools like Dataform and DBT.
As these tools appear to be similar in nature, it is often thought that users need to choose one over the other. This post outlines why customers should be using both LookML and ELT tools in their data analytics stack, with a specific focus on the importance of LookML. In a follow-up article, we will cover how you should architect your business logic and transformations between the LookML and ELT layers.
Quick background on LookML
If you are new to LookML, you will want to check out this video and help center article to get more familiar. But to quickly summarize:
LookML is a code-based modeling layer based on the principles of SQL that:
Allows developers to obfuscate the complexity behind their data and create an explorable environment for less-technical data personas
Brings governance and consistency to analytics because all queries are based off of the LookML model, acting as a “single source of truth”
Enables modern development through its git-integrated version control
LookML can power third-party tools
LookML was originally designed to enable analytics inside of Looker’s UI (or in custom data applications using Looker’s APIs). Looker has continued to evolve and announced several LookML integrations into other analytics tools, enabling customers to add governance and trust to more of their analytics, regardless of which user interface they are using.
Increased adoption of “ELT” Transformation tools
Over the last few years, many organizations have adopted in-warehouse ELT transformation tools, like Dataform (from Google) and DBT, as an alternative to traditional ETL processes. ETL typically transforms data before it’s loaded into a data warehouse. ELT tools take a more simplified and agile approach by transforming data after it’s loaded in the warehouse. They also adhere to modern development practices.
Similarities with LookML
On the surface, characteristics of these ELT tools sound very similar to those of LookML. Both:
Are built on the foundations of SQL
Enable reusable and extendable code
Help define standardized data definitions
Are Git version-controlled and collaborative
Have dedicated IDEs with code validation and testing
The deeper value of LookML
LookML adds three critical capabilities to your organization that cannot be done solely with an ELT tool:
Flexible metrics and exploratory analysis
Consistency and governance in the “last mile” of your analytics
Agile development and maintenance of your BI layer
Flexible metrics and exploratory analysis
Many teams attempt to define and govern their data solely using their most familiar ELT tool. One reason you should avoid this is related to aggregated metrics (also known as “facts” or “measures”), specifically non-additive and semi-additive metrics. ELT tools are not designed to efficiently support these types of metrics, without building a lot of unnecessary tables.
Types of BI metrics
Metric Type
Examples
Additive
Sum of Sales
Count of Orders
Semi-additive
Products in Stock
Account Balance
Non-additive
Daily Active Users (count distinct)
Average Gross Margin (avg)
Flexible Metrics A flexible metric is a metric that is dynamically calculated based on the scope of the request from the user. For example, let’s say your business wants to report on the Daily Active Users on your website, a non-additive metric. If you’re working inside your ELT tool, you may say: “Hey, that’s easy! I can build a new table or view.”
code_block
<ListValue: [StructValue([(‘code’, ‘SELECTrn DATE(created_at) AS date,rn COUNT(DISTINCT user_id) AS daily_active_usersrnFROM `events` rnGROUP BY 1’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eea0da566d0>)])]>
However, the business also wants to see Monthly Active Users. You can’t just sum up the daily active users because if the same user was active on multiple days, they would be counted multiple times for that month. This is an example of a non-additive metric, where the calculation is dependent on the dimensions it is being grouped by (in this case day or month).
You need to build another table or view that is grouped by month. But the business may also want to slice it by other dimensions, such as the specific pages that the users hit, or products they viewed. If the only tool you have available is the ELT tool, you’re going to end up creating separate tables for every possible combination of dimensions, which is a waste of time and storage space.
Exploratory analysis (powered by flexible metrics) Even if you wanted to spend your time modeling every permutation, you’d be siloing your users into only analyzing one table or combination at a time. When they change how they want to look at the data, switching daily to monthly for example, they’d have to change the underlying table that they are querying, adding friction to the user experience and leading to less curious and less data-driven users.
LookML avoids this by enabling you to define one measure called “Active User Count” and allowing users to freely query it by day, month, or any other dimension without having to worry about which table and granularity they are querying (as shown below).
code_block
<ListValue: [StructValue([(‘code’, ‘# LookML for non-additive measure, flexibly works with any dimensionrnmeasure: active_user_count {rn description: “For DAU: query w/ Date. For MAU: query w/ Month”rn type: count_distinctrn sql: ${user_id} ;;rn }’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eea0da56460>)])]>
Having flexible metrics can enable smoother exploratory analysis
Consistency and governance in the “last mile” of your analytics
Even if you believe you’ve perfectly manicured the data inside your data warehouse with your ELT tool, the “last mile” of analytics, between the data warehouse and your user, introduces another level of risk.
Inconsistent logic No matter how much work you’ve put into your ELT procedures, analysts, who may be working in separate ungoverned BI or visualization tools, still have the ability to define new logic inside their individual report workbooks. What often happens here is users across different teams start to define logic differently or even incorrectly, as their metrics and tools are inconsistent.
Maintenance challenges Even if you manage to do it correctly and consistently, you are likely duplicating logic in each workbook/dashboard, and inevitably over time, something changes. Whether the logic itself, or a table or column name, you now have to find and edit every report that is using the out-dated logic.
Agile development and maintenance in your BI layer
LookML itself is a “transformation” tool. LookML applies its transformations at query time, making it an agile option that doesn’t require persisting logic into a data-warehouse table before analysis. For example, a hypothetical ecommerce company may have some business logic around how it defines the “days to process” an order.
As an analyst, I have the autonomy to quickly apply this logic in LookML without having to wait for the data engineering team to bake it into the necessary warehouse tables.
code_block
<ListValue: [StructValue([(‘code’, ‘# LookML example of agile transformation at query timerndimension: days_to_process {rn description: “Days to process each order”rn type: numberrn sql: rn CASErn WHEN ${status} = ‘Processing’ rn THEN TIMESTAMP_DIFF(CURRENT_TIMESTAMP(), ${created_raw}, DAY)rn WHEN ${status} IN (‘Shipped’, ‘Complete’, ‘Returned’) rn THEN TIMESTAMP_DIFF(${shipped_raw}, ${created_raw}, DAY)rn WHEN ${status} = ‘Canceled’ THEN NULLrn END ;;rn }’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eea0da56700>)])]>
This is especially useful for use cases where the business requirements are fluid or not well defined yet (we’ve all been there). You can use LookML to accelerate “user acceptance testing” in these situations by getting reports and dashboards into user’s hands quickly — maybe even before the requirements are fully locked down.
If you’re solely using ELT tools and the requirements change, you will have to truncate and rebuild your tables each time. This is not only time-consuming, but expensive. Using LookML instead of ELT for quick, light-weight transformations puts data in the hands of your users faster and at less cost.
On the other hand, adding too much transformation logic at query time could have a negative impact on the cost and performance of your queries. LookML helps here as well. Using the same example, let’s say the business requirements solidified after a couple weeks and you’d like to add the “days to process” logic to our ELT jobs, rather than LookML. You can swap out the logic with the new database column name, and all of the existing dashboards and reports that were built will continue to work.
code_block
<ListValue: [StructValue([(‘code’, ‘# Added the transformation logic to ELT layer, new column “days_to_process”rndimension: days_to_process {rn description: “Days to process each order”rn type: numberrn sql: ${TABLE}.days_to_process ;;rn }’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3eea0da568e0>)])]>
LookML is a valuable tool for modern data teams that should be used in conjunction with your ELT tool of choice. In a follow-up post, we’ll take you through specific examples on how you should architect your transformations between the LookML and ELT layers. As a sneak peak, here’s a high-level summary of what we would recommend.
Where should I do what?
ELT
LookML
The “heavy lifting” transformations that need to be pre-calculated
Data cleansing
Data standardization
Multi-step transformations
Defining data types
Any logic needed outside of Looker or LookML
The “last mile” of your data
Metric definitions
Table relationship definitions
Light-weight transformation (at query time)
Filters
Frequently changing or loosely defined business logic
Editor’s note: The post is part of a series showcasing partner solutions that are Built with BigQuery.
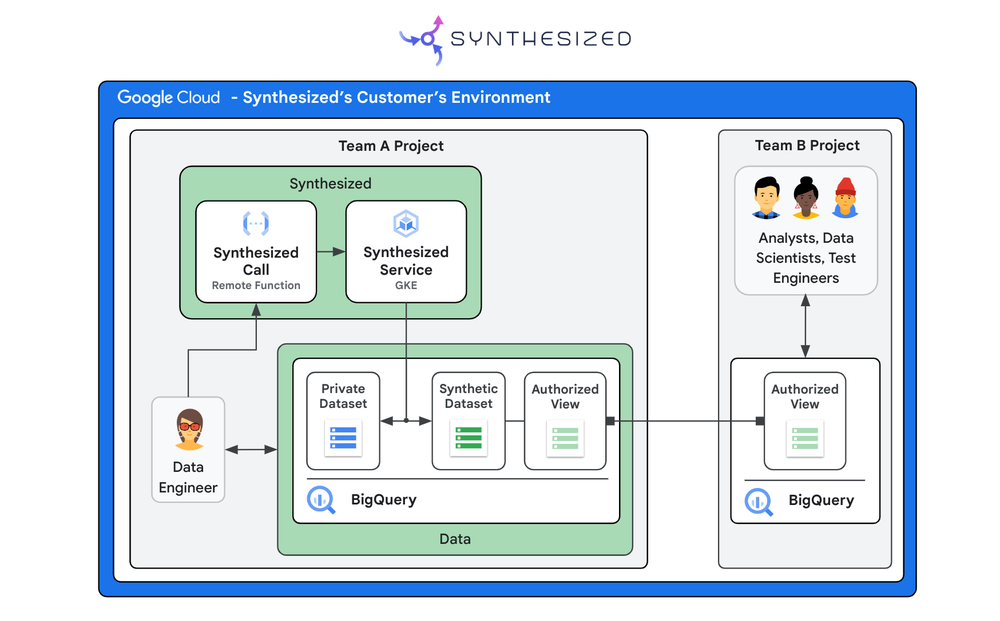
Today, it’s data that powers the enterprise, helping to provide competitive advantage, inform business decisions, and drive innovation. However, accessing high-quality data can be costly and time-consuming, and using it often involves complying with strict data compliance regulations.
Synthesized helps organizations gain faster access to data and navigate compliance restrictions by using generative AI to create shareable, compliant snapshots of large datasets. These snapshots can then be used to make faster and more informed business decisions, and power application development and testing. It does this by helping organizations overcome many of the obstacles to fast and compliant insights:
Accessing compliant data – BigQuery provides a wide range of capabilities that help data to be stored and governed in a secure and compliant way. However, when that data is used in a different context, for example to train an ML model, for testing, or to share information with a different department with different clearance levels, ensuring that data is accessed in a compliant way can become complex. Confidential datasets, such as those with personally identifiable information (PII), medical records, financial data, or other sensitive information that should not be disclosed, are often subject to different restrictions due to industry and local governmental regulations. This can make it difficult for international offices managing access for various teams across regions and countries.Ensuring data quality – One way to manage and protect confidential datasets is data masking, that is, obscuring data so that it cannot be read by certain users. While this is a powerful approach for many use cases, it’s less suited to scenarios where visibility of the underlying data is required for example training a machine learning model. On top of this, organizations are also tasked with uncovering insights from low-quality or unbalanced data, which makes it difficult to land on accurate and representative data insights.
Unlocking data’s potential with accurate snapshots
Synthesized uses generative AI to help customers across healthcare, financial services, insurance, government, and more generate a new and accurate view of their data with confidentiality restrictions automatically applied.
The solution effectively applies data transformations such as masking, subsetting, redaction or generation to create high-fidelity snapshots of large datasets that can be used for modeling and testing. Synthesized uses generative AI to capture deep statistical properties, which are often hidden in the data, to create valuable data patterns and recreate them in synthetic data. At the same time, Synthesized helps ensure adherence to enterprise data privacy regulations, as the output data is programmatically designed to be fully anonymized, for easy and fast access to high-quality data, enabling better decision-making.
With the click of a button, organizations can access insights from a synthetic snapshot that is representative of the entire original dataset — in a way that’s fast and compliant. In other words, the solution addresses the “chicken-and-egg” problem of data access: Data consumers have to formulate their request for data access in terms of SQL query, but they can’t write the query without access to data in the first place.
The newly generated synthetic data can be used for a variety of purposes, including:
Fast access to a compliant snapshot of the data for testing and development purposes.Simplifying model training by programmatically creating diverse data snapshots that cover a wide range of scenarios, including edge cases and rare events. This diversity helps improve the robustness and generalization of machine learning models.Accelerating and evaluating cloud migration with accurate test data that mimics the structure of cloud databases, so you can confidently add sanitized or synthetic data by extending existing CI/CD pipelines.Creating full datasets from unbalanced data, when an original dataset has unequal distribution of examples, and analysis requires the extrapolation of additional reliable data points.
German bank gets compliant, high-quality synthetic data
One of the largest banks in Germany turned to Synthesized to give its engineers and data science teams fast access to the synthetic test data. They wanted to accelerate the preparation time needed to query the data so that they could speed up testing and time to market, and increase accuracy. Synthesized provided non-traceable snapshots of the original datasets, enabling the bank to start data analysis, app migration and testing in the cloud, and experiment with large datasets for new AI/ML use cases and technologies.
Insurance company accelerates product development
Likewise, a leading insurance company wanted to move away from highly manual and resource-intensive data processes to help it remain competitive. Synthesized helped the company generate millions of highly representative test datasets that could be shared safely with third-party vendors for product development. The company was able to accelerate product development, save 200 man-hours per project and drastically reduce its volume of work.
Built with BigQuery
Synthesized extends the functions already available in BigQuery. For example, BigQuery covers masking and data loss prevention for redaction, while Synthesized applies transformations like subsetting and generation. Integrating Synthesized and BigQuery can help organizations to gain fast and secure access to ready-to-query datasets, extracting only the snapshots they need to inform testing or business intelligence. Once the snapshots are ready to be shared safely from a compliance perspective, they can be stored in an organization’s own systems, or shared with third parties for analysis.
Because these snapshots remain in BigQuery, they can be easily used with the full range of Google Data and AI products, including training AI models with BigQuery ML and Vertex AI.
Synthesized has API access to BigQuery, so extracting snapshots and provisioning data is easy and automated. Synthesized also uses a generative model to synthesize data and create balanced datasets from unbalanced datasets, providing the necessary distribution of examples that are ready for sharing. This generative model is stored within the customer’s tenant and can also be shared along with the data.
Here is a simple illustrative example query to generate a fast and compliant snapshot with 1,000 rows from a input table:
The built with BigQuery advantage for ISVs and data providers
Built with BigQuery helps ISVs and data providers build innovative applications with Google’s Data Cloud. Participating companies can:
Accelerate product design and architecture through access to designated experts who can provide insight into key use cases, architectural patterns, and best practicesAmplify success with joint marketing programs to drive awareness, generate demand, and increase adoption
BigQuery gives ISVs the advantage of a powerful, highly scalable unified AI lakehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. Click here to learn more about Built with BigQuery.
In today’s dynamic landscape, businesses need faster data analysis and predictive insights to identify and address fraudulent transactions. Typically, tackling fraud through the lens of data engineering and machine learning boils down to these key steps:
Data acquisition and ingestion: Establishing pipelines across various disparate sources (file systems, databases, third-party APIs) to ingest and store the training data. This data is rich with meaningful information, fueling the development of fraud-prediction machine learning algorithms.Data storage and analysis: Utilizing a scalable, reliable and high-performance enterprise cloud data platform to store and analyze the ingested data.Machine-learning model development: Building training sets out of and running machine learning models on the stored data to build predictive models capable of differentiating fraudulent transactions from legitimate ones.
Common challenges in building data engineering pipelines for fraud detection include:
Scale and complexity: Data ingestion can be a complex endeavor, especially when organizations utilize data from diverse sources. Developing in-house ingestion pipelines can consume substantial data engineering resources (weeks or months), diverting valuable time from core data analysis activities.Administrative effort and maintenance: Manual data storage and administration, including backup and disaster recovery, data governance and cluster sizing, can significantly impede business agility and delay the generation of valuable data insights.Steep learning curve/skill requirements: Building a data science team to both create data pipelines and machine learning models can significantly extend the time required to implement and leverage fraud detection solutions.
Addressing these challenges requires a strategic approach focusing on three central themes: time to value, simplicity of design and the ability to scale. These can be addressed by leveraging Fivetran for data acquisition, ingestion and movement, and BigQuery for advanced data analytics and machine learning capabilities.
Streamlining data integration with Fivetran
It’s easy to underestimate the challenge of reliably persisting incremental source system changes to a cloud data platform unless you happen to be living it and dealing with it on a daily basis. In my previous role, I worked with an enterprise financial services firm that was stuck on legacy technology described as “slow and kludgy” by the lead architect. The addition of a new column to their DB2 source triggered a cumbersome process, and it took six months for the change to be reflected in their analytics platform.
This delay significantly hampered the firm’s ability to provide downstream data products with the freshest and most accurate data. Consequently, every alteration in the source’s data structure resulted in time-consuming and disruptive downtime for the analytics process. The data scientists at the firm were stuck wrangling incomplete and outdated information.
In order to build effective fraud detection models, they needed all of their data to be:
Curated, contextual: The data should be personalized and specific to their use case, while being high quality, believable, transparent, and trustworthy.Accessible and timely: Data needs to always be available, high performance, and offering frictionless access with familiar downstream data consumption tools.
The firm chose Fivetran notably for its automatic and reliable handling of schema evolution and schema drift from multiple sources to their new cloud data platform. With over 450 source connectors, Fivetran allows the creation of datasets from various sources, including databases, applications, files and events.
The choice was game-changing. With Fivetran ensuring a constant flow of high-quality data, the firm’s data scientists could devote their time to rapidly testing and refining their models, closing the gap between insights and action and moving them closer to prevention.
Most importantly for this business, Fivetran automatically and reliably normalized the data and managed changes that were required from any of their on-premises or cloud-based sources as they moved to the new cloud destination. These included:
Schema changes (including schema additions)Table changes within a schema (table adds, table deletes, etc.)Column changes within a table (column adds, column deletes, soft deletes, etc.)Data type transformation and mapping (here’s an example for SQL Server as a source)
The firm’s selection of a dataset for a new connector was a straightforward process of informing Fivetran how they wanted source system changes to be handled — without requiring any coding, configuration, or customization. Fivetran set up and automated this process, enabling the client to determine the frequency of changes moving to their cloud data platform based on specific use case requirements.
Fivetran demonstrated its ability to handle a wide variety of data sources beyond DB2, including other databases and a range of SaaS applications. For large data sources, especially relational databases, Fivetran accommodated significant incremental change volumes. The automation provided by Fivetran allowed the existing data engineering team to scale without the need for additional headcount. The simplicity and ease of use of Fivetran allowed business lines to initiate connector setup with proper governance and security measures in place.
In the context of financial services firms, governance and complete data provenance are critical. The recently released Fivetran Platform Connector addresses these concerns, providing simple, easy and near-instant access to rich metadata associated with each Fivetran connector, destination or even the entire account. The Platform Connector, which incurs zero Fivetran consumption costs, offers end-to-end visibility into metadata (26 tables are automatically created in your cloud data platform – see the ERD here) for the data pipelines, including:
Lineage for both source and destination: schema, table, columnUsage and volumesConnector typesLogsAccounts, teams, roles
This enhanced visibility allows financial service firms to better understand their data, fostering trust in their data programs. It serves as a valuable tool for providing governance and data provenance — crucial elements in the context of financial services and their data applications.
BigQuery’s scalable and efficient data warehouse for fraud detection
BigQuery is a serverless and cost-effective data warehouse designed for scalability and efficiency, making it good fit for enterprise fraud detection. Its serverless architecture minimizes the need for infrastructure setup and ongoing maintenance, allowing data teams to focus on data analysis and fraud mitigation strategies.
Key benefits of BigQuery include:
Faster insights generation: BigQuery’s ability to run ad-hoc queries and experiments without capacity constraints allows for rapid data exploration and quicker identification of fraudulent patterns.Scalability on demand: BigQuery’s serverless architecture automatically scales up or down based on demand, ensuring that resources are available when needed and avoiding over-provisioning. This removes the need for data teams to manually scale their infrastructure, which can be time-consuming and error-prone. A key part here to understand is that BigQuery can scale while the queries are running/in-flight — a clear differentiator with other modern cloud data warehouses.Data analysis: BigQuery datasets can scale to petabytes, helping to store and analyze financial transactions data at near-limitless scale. This empowers you to uncover hidden patterns and trends within your data, for effective fraud detection.Machine learning: BigQuery ML offers a range of off-the-shelf fraud detection models, from anomaly detection to classification, all implemented through simple SQL queries. This democratizes machine learning and enables rapid model development for your specific needs. Different types of models that BigQuery ML supports are listed here.Model deployment for inference at scale: While BigQuery supports batch inference, Google Cloud’s Vertex AI can be leveraged for real-time predictions on streaming financial data. Deploy your BigQuery ML models on Vertex AI to gain immediate insights and actionable alerts, safeguarding your business in real-time.
The combination of Fivetran and BigQuery provides a simple design to a complex problem — an effective fraud detection solution capable of real-time, actionable alerts. In the next series of this blog, we’ll focus on the hands-on implementation of the Fivetran-BigQuery integration using an actual dataset and create ML models in BigQuery that can accurately predict fraudulent transactions.
The games industry is one of the most data-driven industries in the world. Games generate massive amounts of data every second, from player behavior and in-game transactions to social media engagement and customer support tickets. This data can be used to improve games, make better business decisions, and create new and innovative experiences for players.
However, the games industry also faces a unique challenge: how to analyze this data in real-time or near-real-time. This is because games are now constantly changing and evolving, and players expect a personalized and highly responsive experience. Imagine, you and your friends are all set to join your favorite game’s new version launch! You take the day off, get your snacks ready and POOF! Server unresponsive… Reload… Still nothing.
Massively Multiplayer Online Role-Playing Games (MMORPGs), for instance, need to be able to handle a large number of concurrent players while simulating a virtual world in real time. This can put a strain on game server infrastructure, and it can be difficult to scale the infrastructure to meet the needs of a growing player base. Here is where real-time analytics plays a role in auto-scaling infrastructure in response to these events.
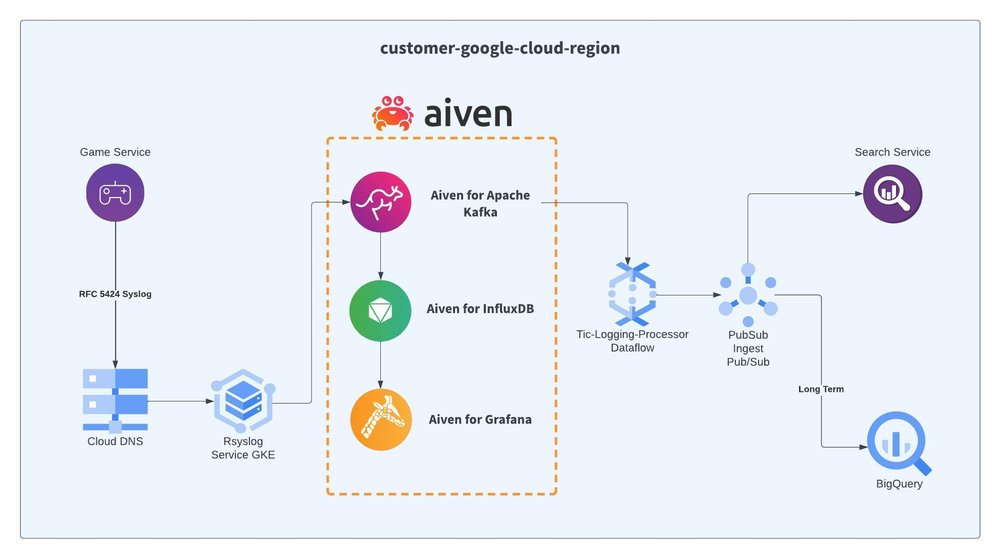
Automating infrastructure scaling in real-time
Aiven for Apache Kafka provides time-value to player-volume-based data, allowing automation of infrastructure scaling, based on traffic patterns and load. In addition, with Aiven for InfluxDB and Aiven for Grafana, data infrastructure teams have insights into the health of gaming services — as the gameplay is happening. Once certain thresholds are detected, automation scripts employing the Kubernetes Operator or Terraform Provider can spin up new game services to answer demand.
As one of the most demanding industries for computing power, online or mobile games need to be able to handle a large number of concurrent players. This can put a strain on game server infrastructure, and it can be difficult to scale the infrastructure to meet the needs of a growing player base.
The Aiven Platform offers multiple features, across all managed services, that make it well-suited for automated game service scaling, including:
Scalability: Aiven services can be scaled to handle any amount of data, making it ideal for high player volume gaming scenarios, such as a highly anticipated version launch.High reliability and availability: Via the management plane — or Aiven Console — highly reliable services are designed to be always available. (Typically, even smaller plans provided by Aiven for Apache Kafka include three High-Available Nodes, out of the box.)Security: The Aiven Console offers a number of security features and compliance by default to protect your data, including encryption and authentication.
Some of the benefits gained when using the Aiven Stack, shown in our reference architecture, to scale game servers are:
Improved performance: By automatically scaling the number of game servers up or down as needed, you can ensure that your game servers are always operating at optimal capacity.Cost optimization: You can save money on your cloud computing costs by only running the number of game servers that you need.Improved scalability: Aiven for Apache Kafka, coupled with Aiven observability services (Aiven for InfluxDB and Aiven for Grafana), can be used to scale your game server infrastructure to meet the needs of your growing player base.
Future-proofing automated scaling
Google Pub/Sub capabilities within the BigQuery suite can be used together to perform longer-term analytics for the games industry. Pub/Sub is a near-real-time/longer-term messaging service that can be used to collect data from game servers, in our case, messages from Aiven for Apache Kafka.
There are a variety of use cases beyond the scope of auto-scaling infrastructure that can be leveraged when using Pub/Sub and BigQuery for longer-term analytics of player telemetry data:
Player behavior analysis: By tracking player behavior over time, game companies can identify trends and patterns in how players are playing their games. This information can be used to improve the player experience, develop new content, and balance in-game economies.Game performance analysis: By tracking game performance over time, game companies can identify areas where technical performance is struggling. This information can be used to fix bugs, optimize performance, and improve the overall quality of the game experience.Business intelligence: By analyzing data on player engagement, revenue, and other metrics, companies can make better business decisions. For example, a gaming company could use this data to identify their most popular and profitable titles.
Several benefits games industry customers will see by using Pub/Sub and BigQuery for longer-term analytics in the games industry are:
Scalability and reliability: Pub/Sub and BigQuery are both highly scalable and highly available services that can handle any amount of data.Security: Pub/Sub and BigQuery offer a number of security features to help protect your data, including encryption and authentication.Cost-optimization: By analyzing longer term data points, Pub/Sub and BigQuery can help forecast future player workloads and enable adjustments to auto-scaling behavior.
Aiven + Google Cloud = better together
By partnering with Google Cloud and Aiven on Google Cloud, the games industry can prepare for a worry-free launch while having the data to understand players and keep them coming back for more. Service reliability is key — a hassle-free experience dictates the success of the game! — but cost should always be considered. By lowering the total cost of operations, and right-sizing in real-time, you can achieve greater game-play usability while minimizing unnecessary overscaling.
Predictive analytics in BigQuery allows you to tweak the scaling parameters based on past data, enabling greater control of future volumes that would otherwise be lost. The combination of managed services from Aiven and Google Cloud add time value to data — and increased revenue from a successful launch. Game on!
Conclusion and next steps
As the games industry continues to evolve and embrace data-driven decision-making, the combination of Aiven for Kafka and Pub/Sub capabilities within the BigQuery suite will become increasingly essential for success. By harnessing the power of real-time data, games companies can unlock new opportunities, enhance player experiences, and drive sustainable growth. If you’re ready to learn more, check out the following links below:
In today’s data-driven world, the ability to leverage real-time data for machine learning applications is a game-changer. Two key players in this field, Striim and Google Cloud with BigQuery, offer a powerful combination to make this possible. Striim serves as a real-time data integration platform that seamlessly and continuously moves data from diverse sources to destinations such as cloud databases, messaging systems, and data warehouses, making it a vital component in modern data architectures. BigQuery is an enterprise data platform with best-in-class capabilities to unify all data and workloads in multi-format, multi-storage and multi-engine. BigQuery ML is built into the BigQuery environment, allowing you to create and deploy machine learning models using SQL-like syntax in a single, unified experience.
Real-time data processing in the world of machine learning (ML) allows data scientists and engineers to focus on model development and monitoring, instead of relying on traditional methods where data scientists and ML engineers used to manually execute workflows and code to gather, clean, and label their raw data through batch processing, which often involved delays and less responsiveness. Striim’s strength lies in its capacity to connect to over 150 data sources, enabling real-time data acquisition from virtually any location and simplifying data transformations. This empowers businesses to expedite the creation of machine learning models and make data-driven decisions and predictions swiftly, ultimately enhancing customer experiences and optimizing operations. By incorporating the most current data, organizations can further boost the accuracy of their decision-making processes, ensuring that insights are derived from the latest information available, leading to more informed and strategic business outcomes.
Prerequisites
Before we embark on the journey of integrating Striim with BigQuery ML for real-time data processing in machine learning, there are a few prerequisites that you should ensure are in place.
Striim instance: To get started, you need to have a Striim instance created and have access to it. Striim is the backbone of this integration, and having a working Striim instance is essential for setting up the data pipelines and connecting to your source databases. For a free trial, please sign up for a Striim Cloud on Google Cloud trial at https://go2.striim.com/trial-google-cloudBasic understanding of Striim: Familiarity with the basic concepts of Striim and the ability to create data pipelines is crucial. You should understand how to navigate the Striim environment, configure data sources, and set up data flows. If you’re new to Striim or need a refresher on its core functionalities, you can review the documentation and resources available at https://github.com/schowStriim/striim-PoC-migration.
In the forthcoming sections of this blog post, we will guide you through the seamless integration of Striim with BigQuery ML, showcasing a step-by-step process from connecting to a Postgres database to deploying machine learning models. The integration of Striim’s real-time data integration capabilities with BigQuery ML’s powerful machine learning services empowers users to not only move data seamlessly but also harness the latest data for building and deploying machine learning models. Our demonstration will highlight how these tools facilitate real-time data acquisition, transformation, and model deployment, ultimately enabling organizations to make quick, data-driven decisions and predictions while optimizing their operational efficiency.
Section 1: Connecting to the source database
The first step in this integration journey is connecting Striim to a database that contains raw machine learning data. In this blog, we will focus on a PostgreSQL database. Inside this database, we have an iris_dataset table with the following column structure.
This table contains raw data related to the characteristics of different species of iris flowers. It’s worth noting that this data has been gathered from a public source, and as a result, there are NULL values in some fields, and the labels for the species are represented numerically. Specifically, in this dataset, 1 represents “setosa,” 2 represents “versicolor,” and 3 represents “virginica.”
To read raw data from our PostgreSQL database, we will use Striim’s PostgreSQL Reader adapter, which captures all operations and changes from the PostgreSQL log files.
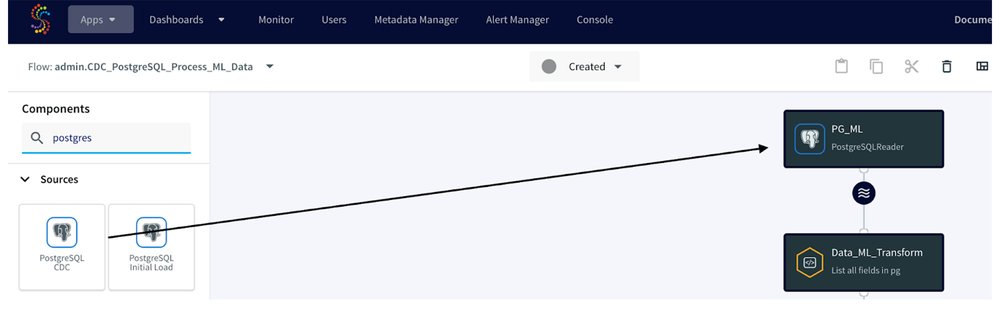
To get the PostgreSQL Reader adapter created, we will drag and drop it from the Component section, provide the Connection URL, username, and password, and specify the iris_dataset table in the Tables property. The PostgreSQL Reader adapter utilizes the wal2json plugin of the PostgreSQL database to read the log files and capture the changes. Therefore, as a part of the setup, we need to create a replication slot in the source database and then provide its name in the replication slot property.
In the context of Striim, CQ refers to continuously running queries that transform data in-flight by using Striim queries, which are similar to SQL queries. These adapters can be used to filter, aggregate, join, enrich, and transform events.
This adapter plays a crucial role in this integration, as it helps transform and prepare the data for machine learning in BigQuery ML. In order for us to create and attach a CQ adapter under the previous adapter, we have to click on the ‘Wave’ icon and ‘+’ sign, then select ‘Connect next CQ component’:
We will now walk you through the steps of writing SQL-like queries in the CQ adapters and how Striim transforms the data in-flight once we read it from the Postgres database.
1. Handling NULL Values:
We build a CQ adapter that transforms NULL values into a float 0.0, ensuring the consistency and integrity of your data. Here’s the SQL query for this transformation:
code_block<ListValue: [StructValue([(‘code’, ‘SELECT * FROM pg_output_ml rnMODIFY(rn data[1] = CASE WHEN data[1] IS NULL THEN TO_FLOAT(0.0) ELSE data[1] END,rn data[2] = CASE WHEN data[2] IS NULL THEN TO_FLOAT(0.0) ELSE data[2] END,rn data[3] = CASE WHEN data[3] IS NULL THEN TO_FLOAT(0.0) ELSE data[3] END,rn data[4] = CASE WHEN data[4] IS NULL THEN TO_FLOAT(0.0) ELSE data[4] ENDrn);’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e0e51caedf0>)])]>
We will attach the PostgreSQL Reader adapter to this CQ for seamless data processing:
2. Converting numeric species classes to text:
We build another CQ adapter to convert numeric species classes to text classes, making the data more human-readable and interpretable for the ML model.
We attach the Data_ML_Transform CQ adapter to this CQ for label processing:
3. Data transformation:
Finally, we create the last CQ adapter to extract the final data and assign it to variable/column names, making it ready for integration with BigQuery ML.
code_block<ListValue: [StructValue([(‘code’, ‘SELECT rn data[0] as id, rn data[1] as sepal_length, rn data[2] as sepal_width, rn data[3] as petal_length, rn data[4] as petal_width, rn data[5] as speciesrnFROM transformed_data t;’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e0e53139670>)])]>
We attach the Label_ML_Transform CQ adapter to this CQ to assign data field to variables:
Section 3: Attaching CQ to BigQuery Writer adapter
Now that we’ve prepared the data using CQ adapters, we need to connect them to the BigQuery Writer adapter, the gateway for streaming data into BigQuery. By clicking on the ‘Wave’ icon, and attaching the BigQuery adapter, you establish a connection between the previous adapters and BigQuery.
In the Tables property, we use the ColumnMap to connect the transformed data with the appropriate BigQuery columns:
code_block<ListValue: [StructValue([(‘code’, ‘DMS_SAMPLE.iris_dataset ColumnMap(rn id = id, rn sepal_length = sepal_length, rn petal_length = petal_length, rn petal_width = petal_width, rn species = speciesrn)’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e0e58bc3eb0>)])]>
After we create the service account key, we specify the Project ID and supply the Service Account Key JSON file to give Striim permission to connect to BigQuery:
Section 4: Execute the CDC data pipeline to replicate the data to BigQuery
To execute the CDC data pipeline, simply click on the top dropdown labeled as ‘Created,’ select ‘Deploy App’:
and then choose ‘Start App’ to initiate the data pipeline:
After successfully executing the CDC data pipeline, the Application Progress page indicates that we’ve read 30 ongoing changes from our source database and written these 30 records and changes to my BigQuery database. At the bottom of the Application Progress page, you can also preview the data flowing from the source to the target by clicking on the ‘Wave’ icon and then the ‘Eye’ icon located between the source and target components. This is one sample of the raw data:
This is the processed data after undergoing the CQ transformations. Please observe how we transformed the NULL value in the petal_width to 0.0 and changed the numeric class ‘1’ to ‘setosa’ for the species.
With your data flowing seamlessly into BigQuery, it’s time to harness the power of Google Cloud’s machine learning service. BigQuery ML provides a user-friendly environment for creating machine learning models, without the need for extensive coding or external tools. We provide you with step-by-step instructions on building a logistic machine learning model within BigQuery. This includes examples of model creation, training, and making predictions, giving you a comprehensive overview of the process.
Verify that the data has been populated correctly in the BigQuery iris_dataset table. Note that ‘ancient-yeti-175123’ represents the name of our project, and ‘DMS_SAMPLE’ is the designated dataset. It is important to acknowledge that individual project and dataset names may vary.
2. Create a logistic regression model from the iris_dataset table by executing this query:
Logistic regression is a statistical method used for classification tasks, making it suitable for predicting outcomes with possible values. In the context of our iris dataset, logistic regression can be used to predict the probability of a given iris flower belonging to a particular species based on its features. This model is particularly useful when dealing with problems where the dependent variable is categorical, providing valuable insights into classification scenarios.
Here’s a breakdown of what this query is doing:
CREATE MODEL IF NOT EXISTS: This part of the query creates a machine learning model if it doesn’t already exist with the specified name, which is `striim_bq_model` in this case.
OPTIONS: This section defines various options and hyperparameters for the model. Here’s what each of these options means:
model_type=’logistic_reg’:Specifies that you are creating a logistic regression model.ls_init_learn_rate=.15:Sets the initial learning rate for the model to 0.15.l1_reg=1:Applies L1 regularization with a regularization strength of 1.max_iterations=20:Limits the number of training iterations to 20.input_label_cols=[‘species’]:Specifies the target variable for the logistic regression, which is ‘species’ in this case.data_split_method=’seq’:Uses a sequential data split method for model training and evaluation.data_split_eval_fraction=0.3:Allocates 30% of the data for model evaluation.data_split_col=’id’:Uses the ‘id’ column to split the data into training and evaluation sets.
AS:This keyword indicates the start of the SELECT statement, where you define the data source for your model.
SELECT:This part of the query selects the features and target variable from theiris_datasettable, which is the data used for training and evaluating the logistic regression model.
id, sepal_length, sepal_width, petal_length, petal_widthare the feature columns used for model training.speciesis the target variable or label column that the model will predict.
In summary, this query creates a logistic regression model namedstriim_bq_modelusing theiris_datasetdata in BigQuery ML. It specifies various model settings and hyperparameters to train and evaluate the model. The model’s goal is to predict the ‘species’ based on the other specified columns as features.
3. Evaluate the model by executing this query:
code_block<ListValue: [StructValue([(‘code’, ‘SELECT * FROM ML.EVALUATE(MODEL `ancient-yeti-175123.DMS_SAMPLE.striim_bq_model`, (SELECT * FROM `ancient-yeti-175123.DMS_SAMPLE.iris_dataset`))’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e0e5086f6d0>)])]>
Evaluating the performance of an ML model is a critical step in gauging its effectiveness in generalizing to new, unseen data. This process includes quantifying the model’s predictive accuracy and gaining insights into its strengths and weaknesses.This query performs an evaluation of the machine learning model calledstriim_bq_modelthat we previously created. Here’s a breakdown of what this query does:
SELECT * FROM ML.EVALUATE:This part of the query is using theML.EVALUATEfunction, which is a BigQuery ML function used to assess the performance of a machine learning model. It evaluates the model’s predictions against the actual values in the test dataset.
(MODEL ancient-yeti-175123.DMS_SAMPLE.striim_bq_model, … ):Here, you specify the model to be evaluated. The model being evaluated is namedstriim_bq_model, and it resides in the datasetancient-yeti-175123.DMS_SAMPLE.
(SELECT * FROM `ancient-yeti-175123.DMS_SAMPLE.iris_dataset):This part of the query selects the data from theiris_dataset, which is used as the test dataset. The model’s predictions will be compared to the actual values in this dataset to assess its performance.
In summary, this query evaluates thestriim_bq_modelusing the data from theiris_datasetto assess how well the model makes predictions. The results of this evaluation will provide insights into the model’s accuracy and performance.
4. Now, we will predict the type of Iris based on the features of sepal_length, petal_length, sepal_width, and petal_width using the model we trained in the previous step:
code_block<ListValue: [StructValue([(‘code’, ‘SELECT * FROM ML.PREDICT(MODEL `ancient-yeti-175123.DMS_SAMPLE.striim_bq_model`,(SELECT 5.1 as sepal_length, 2.5 as petal_length, 3.0 as petal_width, 1.1 as sepal_width))’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3e0e5086f9a0>)])]>
In the screenshot above, you can see that the `striim_bq_model` provided us with information such as the predicted species, probabilities for the predicted species, and the feature column values used in our ML.PREDICT function.
Conclusion
Integrating Striim with BigQuery ML enhances the capabilities of data scientists and ML engineers by eliminating the need to repeatedly gather data from the source and execute the same data cleaning processes. Instead, they can focus solely on building and monitoring machine learning models. This powerful combination accelerates decision-making, enhances customer experiences, and streamlines operations. We invite you to explore this integration for your real-time machine learning projects, as it has the potential to revolutionize how you leverage data for business insights and predictions. Embrace the future of real-time data processing and machine learning with Striim and BigQuery ML!
Refer to this link to learn more about what you can do with Striim and Google Cloud.
We thank the many Google Cloud and Striim team members who contributed to this collaboration, especially Bruce Sandell and Purav Shah for their guidance during the process.
This article covers how to enhance query performance on an astronomy dataset employing clustering of the records by HEALPix index. Although this article specifically refers to astronomy data, the techniques could be useful for any user of the BigQuery GIS platform.
Introduction to HEALPix
Briefly, HEALPix is a hierarchical equal-area pixelization scheme for the sphere. It is a widely used tool for representing and analyzing data on the celestial sphere. Clustering the records by Geopositioning fields and by adding a HEALPix index field for each record in the collection of tables involved in the dataset can improve the performance of queries that involve multiple tables because HEALPIX Index keep close together on the server nodes records within the region depicted by the HEALPix Index. This way BigQuery can optimize the query response and even filter out records from other clusters that are not required for processing the query.
First there are some key definitions for the rest of this article:
Clustered tablesare tables that have a user-defined column sort order. The columns defined create storage blocks for the records based on their values of these fields in the records.
Materialized viewsare precomputed views that periodically cache the results of a query for increased performance.
HEALPix(Hierarchical Equal Area isoLatitude Pixelation) of a sphere. It is a subdivision of the spherical surface in which each pixel covers the same surface area as every other pixel. We use this as a column to cluster tables for the astronomy datasets as the majority of the query searches are for objects and their neighbors.
Reading this article you will, learn how to:
Create and measure the performance of clustered tables and materialized views
Transfer astronomy datasets to clustered tables efficiently
Bringing astronomy datasets to BigQuery
Many astronomy datasets are publicly available in different platforms and media and in some cases you may want to consolidate these datasets into BigQuery to have a central consolidated place with all the information needed to serve astronomers in their research. Frequently, transformations may be needed to harmonize and enhance records from the source datasets, such as adding the HEALPix Index to all records with Geoposition.
There are multiple options to migrate large datasets including astronomy datasets to BigQuery. In order to choose the best option, there are some areas to consider:
Size of the datasets: astronomy datasets can be very large, in some cases multiple PBs.
Data structure: astronomy datasets often have complex data structures with wide-size records that contain multiple positioning and characterists attributes.
Data validations: astronomy datasets often have complex data validations, for example the truth match validations.
Combining data from different tables or multiple observatories sources: combining data from different tables or multiple observatories sources can be complex and frequently involves a large number of records to be processed.
Storage Performance: the target storage for these datasets must be highly scalable to handle the high volumes and optimized for analytics to handle the queries and joins against the final tables where the different pieces of data will be stored.
It is important to have a clear understanding of the data, the target storage, and the migration process before beginning the migration.
The datasets used for this article contain a large amount of data and to speed up the migration with the necessary transformations to add HEALPix into Clustered Target tables and avoid duplication of data at the target, we usedGoogle DataFlow(ApacheBeam SDK).
As Cloud Dataflow is a fully managed service for data processing, it provides a simple and familiar way to define data pipelines, then applies optimization and executes the pipelines using parallel processing on the Google Compute Engine resources. Also, during the execution users get visibility into the processing jobs and resources using cloud console monitoring.
Cloud Dataflow accepts Python and Java for programming the pipelines and for our transformation we used Python to leverage important libraries for this project such as HEALPY: the out-of-the-box library to perform HEALPix Index determination.
How does BigQuery help?
There are several benefits of using BigQuery as a platform for astronomy datasets:
BigQuery is a highly scalable and performant data warehouse that can handle large volumes of data, such as those generated by astronomical observatories.
It’s optimized for analytics, which means that it can quickly and easily answer complex queries on astronomy catalogs.
It offers a variety of features that are useful for astronomy, such as the ability to store and analyze geo-spatial data with out-of-the-box geopositioning data types and operations.
BigQuery also offersmaterialized viewsto speed up complex and large table joins because materialized views are precomputed in the background when the base tables change. Any incremental data changes from the base tables are automatically added to the materialized views, with no user action required. Also it has smart tuning. If any part of a query against the base table can be resolved by querying the materialized view, then BigQuery reroutes the query to use the materialized view for better performance and efficiency.
Overall, BigQuery is a powerful and versatile tool that can be used to store, analyze, and share astronomy datasets. It is a good choice for astronomers who need to store and analyze large amounts of data, or who need to share their data with others.
The dataset we used
Our dataset is fromVera C. Rubin Observatory. Data Preview 0 (DP0) is the first data preview to test Legacy Survey of Space and Time (LSST) Science Pipelines and the Rubin Science Platform (RSP). DP0 will provide a limited number of astronomers and students with synthetic preview data, allowing them to prepare for science with the LSST. This dataset contains 5 tables with photometry, object details, position, and truth match records. These tables vary in size from 150 million to 800 million records (100 Gb to 300 Gb) in BigQuery.
When we uploaded the dataset into BigQuery Clustered tables by HEALPix Id, GeoPoint (latitude, longitude), and Object Identification, we use the following optimizations:
We applied the HEALPIx NESTED index to all records. This method labels cells in a specific sequence to preserve multiple levels and we used 512 cells per pixel.
We created a GEOPOINT type object column to leverage the Geoposition features from BigQuery and reduce the calculations of Geographical operations during query processing.
Now that we have our data harmonized, loaded into the clustered tables, and the necessary materialized views created. We identified scenarios that required further optimizations on the query processing. We compared query executions in BigQuery on tables without clustering and the same query executions on tables with clusters. The data records used are the same in both tables.
Scenario 1: Clustered tables
Query Name
BIG Query non-Clustered(seconds)
BIG Query Clustered(seconds)
Single Record
Table Volume: 147 million rows (148 GB)
1.9
0.8
Magnitude Between Values
Table Volume: 147 million rows (148 GB)
2.0
1.0
Truth match join
Table1 Volume: 147 million rows (148 GB)Table2 Volume: 765 million rows(183 GB)
29.6
20
Table 1: Queries runtime database comparison by query type.
We see a significant improvement on the performance of the BigQuery with clustered tables compared with the BigQuery without clustered tables for scenarios where the queries are executed with simple filters, range or values, or direct joins and filters.
Scenario 2: Materialized views
There are more complex scenarios involving geopositioning queries that require additional optimization. The use of materialized views preprocess and cache large table joins which records can be clustered together, providing further optimization.
Take for example the following query that selects an object within a circle in the sky and with limited magnitude intensity:
SELECT * FROM object AS obj JOIN truth_match AS truth ON truth.match_objectId = obj.objectId WHERE CONTAINS(POINT(‘ICRS’, obj.ra, obj.dec), CIRCLE(‘ICRS’, 61.863, -35.79, 0.05555555555555555))=1 AND (obj.mag_g <25 AND obj.mag_i <24)
These 2 tables are very large (147 million rows and 765 million rows) and the query optimizer would not be able to push down filters completely to process this query.
Therefore, we created a materialized view with all required non-duplicated columns from the 2 tables and clustered the materialized view by HEALPix, object id, object geoposition from object table.
The following figure shows the query execution on the materialized view and the filters being pushed down to the database which brought for processing a subset of the data and not the totality of the records.
Image 2: Processing steps for the query using clustered materialized view.
Detailed runtime durations and consumption of BigQuery resources are described in the following image:
Image 3: Processing runtime details per step of querying materialized views.
The comparison results below shows a significant improvement results of the query with addition of clustered materialized view for processing:
Query Name
BigQuery Clustered(seconds)
BigQuery Materialized View(seconds)
Magnitude cut in a cone on JOIN of object and truth-match (same query but with Materialized View)
13
1
Table 2: Queries runtime database comparison with materialized view.
Closing
This article has discussed the benefits of migrating astronomy datasets into clustered tables in BigQuery and use cases for materialized views. It has also provided an approach on how to migrate astronomy datasets and improve query performance. This article results show that out-of-the-box BigQuery geopositioning functions, table clustering, and materialized views can significantly improve the performance of queries on large datasets. Customers around the globe may extend the application of these optimization approaches in large datasets in different scenarios.