Indonesia’s largest hyperlocal company, Gojek has evolved from a motorcycle ride-hailing service into an on-demand mobile platform, providing a range of services that include transportation, logistics, food delivery, and payments. A total of 2 million driver-partners collectively cover an average distance of 16.5 million kilometers each day, making Gojek Indonesia’s de-facto transportation partner.
To continue supporting this growth, Gojek runs hundreds of microservices that communicate across multiple data centers. Applications are based on an event-driven architecture and produce billions of events every day. To empower data-driven decision-making, Gojek uses these events across products and services for analytics, machine learning, and more.
Data warehouse ingestion challenges
To make sense of large amounts of data — and to better understand customers for the purpose of app development, customer support, growth, and marketing purposes — data must first be ingested into a data warehouse. Gojek uses BigQuery as its primary data warehouse. But ingesting events at Gojek’s scale, with rapid changes, poses the following challenges:
With multiple products and microservices offered, Gojek releases new Kafka topics almost every day and they need to be ingested for analytical purposes. This can quickly result in significant operational overhead for the data engineering team that is deploying new jobs to load data into BigQuery and Cloud Storage.
Frequent schema changes in Kafka topics require consumers of those topics to load the new schema to avoid data loss and capture more recent changes.
Data volumes can vary and grow exponentially as people start building new products and logging new activities on top of a new topic. Each topic can also have a different load during peak business hours. Customers need to handle the rising volume of data to quickly scale per their business needs.
Firehose and Google Cloud to the rescue
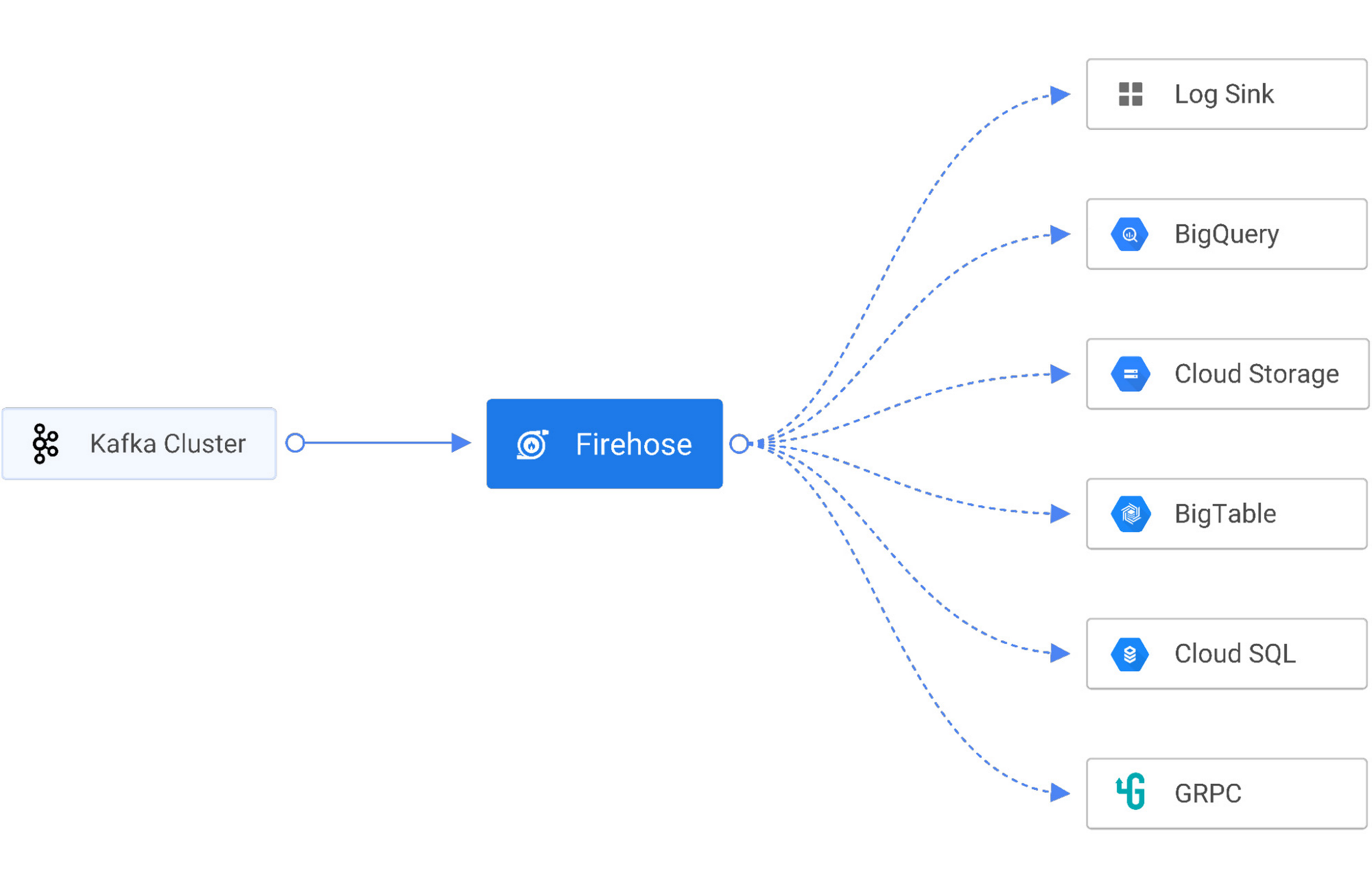
To solve these challenges, Gojek uses Firehose, a cloud-native service to deliver real-time streaming data to destinations like service endpoints, managed databases, data lakes, and data warehouses like Cloud Storage and BigQuery. Firehose is part of the Open Data Ops Foundation (ODPF), and is fully open source. Gojek is one of the major contributors to ODPF.
Here are Firehose’s key features:
Sinks – Firehose supports sinking stream data to the log console, HTTP, GRPC, PostgresDB (JDBC), InfluxDB, Elastic Search, Redis, Prometheus, MongoDB, GCS, and BigQuery.
Extensibility – Firehose allows users to add a custom sink with a clearly defined interface, or choose from existing sinks.
Scale – Firehose scales in an instant, both vertically and horizontally, for a high-performance streaming sink with zero data drops.
Runtime – Firehose can run inside containers or VMs in a fully-managed runtime environment like Kubernetes.
Metrics – Firehose always lets you know what’s going on with your deployment, with built-in monitoring of throughput, response times, errors, and more.
Key advantages
Using Firehose for ingesting data in BigQuery and Cloud Storage has multiple advantages.
Reliability Firehose is battle-tested for large-scale data ingestion. At Gojek, Firehose streams 600 Kafka topics in BigQuery and 700 Kafka topics in Cloud Storage. On average, 6 billion events are ingested daily in BigQuery, resulting in more than 10 terabytes of daily data ingestion.
Streaming ingestion A single Kafka topic can produce up to billions of records in a day. Depending on the nature of the business, scalability and data freshness are key to ensuring the usability of that data, regardless of the load. Firehose uses BigQuery streaming ingestion to load data in near-real-time. This allows analysts to query data within five minutes of it being produced.
Schema evolution With multiple products and microservices offered, new Kafka topics are released almost every day, and the schema of Kafka topics constantly evolves as new data is produced. A common challenge is ensuring that as these topics evolve, their schema changes are adjusted in BigQuery tables and Cloud Storage. Firehose tracks schema changes by integrating with Stencil, a cloud-native schema registry, and automatically updates the schema of BigQuery tables without human intervention. This reduces data errors and saves developers hundreds of hours.
Elastic infrastructure Firehose can be deployed on Kubernetes and runs as a stateless service. This allows Firehose to scale horizontally as data volumes vary.
Organizing data in cloud storage Firehose GCS Sink provides capabilities to store data based on specific timestamp information, allowing users to customize how their data is partitioned in Cloud Storage.
Supporting a wide range of open source software
Built for flexibility and reliability, Google Cloud products like BigQuery and Cloud Storage are made to support a multi-cloud architecture. Open source software like Firehose is just one of many examples that can help developers and engineers optimize productivity. Taken together, these tools can deliver a seamless data ingestion process, with less maintenance and better automation.
How you can contribute
Development of Firehose happens in the open on GitHub, and we are grateful to the community for contributing bug fixes and improvements. We would love to hear your feedback via GitHub discussions or Slack.
Enterprise cloud adoption increased dramatically during the COVID-19 pandemic — now, it’s the rule rather than the exception. In fact, 9 in 10 companies currently use the cloud in some capacity, according to a recent report from O’Reilly.
Although digital transformation initiatives were already well underway in many industries, the global health crisis introduced two new factors that forced almost all organisations to move operations online. First, that’s where their customers went. Amid stay-at-home mandates and store closings, customers had to rely almost solely on digital services to shop, receive support, partake in personalised experiences, and otherwise interact with companies.
Second, the near-universal shift to remote work made the continued use of on-premises hardware and computing resources highly impractical. To ensure newly distributed teams could work together effectively, migrating to the cloud was the only option for many companies. And although current adoption statistics are a testament to the private sector’s success in this endeavour, most companies encountered some obstacles on their journey to the cloud.
Barriers to success in cloud adoption
There are several different types of cloud platforms and a variety of cloud service models. To keep things simple, I tend to think of cloud resources in terms of two components: back end and front end. The former is the infrastructure layer. Outside of the physical servers and data centres that every cloud provider is comprised of, the infrastructure layer encompasses everything related to information architecture, including data access and security, data storage systems, computational resources, availability, and service-level agreements. The front end is the presentation layer or application interface, including the end-user profile, authentication, authorisation, use cases, user experiences, developer experiences, workflows, and so on.
Not long ago, companies would typically migrate to the cloud in long, drawn-out stages, taking plenty of time to design and implement the back end and then doing the same with the front end. In my experience working with enterprise customers, the pandemic changed that. What used to be a gradual process is now a rapid undertaking with aggressive timelines, and front-end and back-end systems are frequently implemented in tandem where end users are brought in earlier to participate in more frequent iterations.
Moreover, the pandemic introduced new cost considerations associated with building, maintaining, and operating these front-end and back-end systems. Organisations are searching for more cost savings wherever possible, and though a cloud migration can result in a lower total cost of ownership over the long run, it does require an upfront investment. For those facing potential labour and capital constraints, cost can be an important factor to consider.
Aggressive timelines and cost considerations aren’t roadblocks themselves, but they can certainly create challenges during cloud deployments. What are some other obstacles to a successful cloud integration?
Attempting to ‘lift and shift’ architecture
When trying to meet cloud migration deadlines, organisations often are prone to provision their cloud resources as exact replicas of their on-premises setups without considering native cloud services that can offset a lot of the maintenance or performance overhead. Without considering how to use available cloud-native services and reworking different components of their workflows, companies end up bringing along all of their inefficiencies to the cloud. Instead, organisations should view cloud migration as an opportunity to consider a better architecture that might save on costs, improve performance, and result in a better experience for end users.
Focusing on infrastructure rather than user needs
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of data scientists and data engineers. Rather than optimising for developer productivity and quick iterations, leaders commonly focus on developing a robust and scalable back-end system. Additionally, data professionals want to get the cloud architecture perfect before bringing users into the cloud environment. But the longer the cloud environment goes untested by end users, the less useful it will be for them. The recommendation is to bring a minimal amount of data, development environments, and automation tools to the initial cloud environment, then introduce users and iterate based on their needs.
Failing to make production data accessible in the cloud
Data professionals often enable many different cloud-native services to help users perform distributed computations, build and store container images, create data pipelines, and more. However, until some or all of an organisation’s production data is available in the cloud environment, it’s not immediately useful. Company leaders should work with their data engineering and data science teams to figure out which data subsets would be useful for them to have access to in the cloud, migrate that data, and let them get hands-on with the cloud services. Otherwise, leaders might find that almost all production workloads are staying on-premises due to data gravity.
A smoother cloud transition
Although obstacles abound, there are plenty of steps that data leaders can take to ensure their cloud deployment is as smooth as possible. Furthermore, taking these steps will help maximise the long-term return on investment of cloud adoption:
1. Centralise new data and computational resources.
Many organisations make too many or too few computational and data analytics resources available — and solutions end up being decentralised and poorly documented. As a result, adoption across the enterprise is slow, users do most of their work in silos or on laptops, and onboarding new data engineers and data scientists is a messy process. Leaders can avoid this scenario by focusing on the core data sets and computational needs for the most common use cases and workflows and centralise the solutions for these. Centralising resources won’t solve every problem, but it will allow companies to focus on the biggest challenges and bottlenecks and help most people move forward.
2. Involve users early.
Oftentimes, months or even years of infrastructure management and deployment work happens before users are told that the cloud environment is ready for use. Unfortunately, that generally leads to cloud environments that simply aren’t that useful. To overcome this waste of resources, data leaders should design for the end-user experience, workflow, and use cases; onboard end users as soon as possible in the process; and then iterate with them to solve the biggest challenges in priority order. They should avoid delaying production usage in the name of designing the perfect architecture or the ideal workflow. Instead, leaders can involve key stakeholders and representative users as early as possible to get real-world feedback on where improvements should be made.
3. Focus on workflows first.
Rather than aiming for a completely robust, scalable, and redundant system on the first iteration, companies should determine the core data sets (or subsets) and the smallest viable set of tools that will allow data engineers and data scientists to perform, say, 80% of their work. They can then gradually gather feedback and identify the next set of solutions, shortening feedback loops as efficiently as possible with each iteration. If a company deals with production data sets and workloads, then it shouldn’t take any shortcuts when it comes to acceptable and standard levels of security, performance, scalability, or other capabilities. Data leaders can purchase an off-the-shelf solution or partner with someone to provide one in order to avoid gaps in capability.
No going back
Cloud technology used to be a differentiator — but now, it’s a staple. The only way for companies to gain a competitive edge is by equipping their data teams with the tools they need to do their best work. Even the most expensive, secure, and scalable solution out there won’t get used unless it actually empowers end users.
Kristopher Overholt works with scalable data science workflows and enterprise architecture as a senior sales engineer at Coiled, whose mission is to provide accessibility to scalable computing for everyone.
Artificial intelligence is driving a lot of changes in modern business. Companies are using AI to better understand their customers, recognize ways to manage finances more efficiently and tackle other issues. Since AI has proven to be so valuable, an estimated 37% of companies report using it. The actual number could be higher, since some companies don’t realize the different forms of AI they might be using.
AI technology has been helpful for businesses in different industries for years. It is becoming even more valuable for companies as ongoing economic issues create new challenges.
The benefits of AI stem from the need to manage close relationships with business stakeholders, which is a difficult task. Businesses do not exist on islands. All companies require complex relationships with various suppliers and service providers to develop the products and services they offer to clients and customers — but those relationships always carry some risk. Since the War in Ukraine, Covid-19 crisis and other problems have worsened these risks, AI is becoming more important for companies that want to mitigate them.
Here are some of the risks that organizations face in dealing with suppliers, and what they can do to mitigate those risks with artificial intelligence.
Failure or Delay Risk
Failure to deliver goods is one of the most common risks businesses have suffered over the past two years. This risk is best defined as a complete supply or service failure, which can be permanent or temporary.
There can be many localized or widespread reasons for a supplier to fail to provide goods or services. For example, poor management might cause their business to collapse, eliminating their products from the supply chain. The availability of materials can cause failures, as suppliers cannot manufacture products when they lack the resources to do so. Finally, unexpected or unavoidable events, like the blockage of a major trade route or unprecedented and severe storms, can cause catastrophic delays that shut down manufacturing or prevent trade from coming or going to a region.
This is one area that can be partially resolved with AI. You can use predictive analytics tools to anticipate different events that could occur. Cloud-based applications can also help.
Google Cloud author Matt A.V. Chaban addressed this in a recent article. Hans Thalbauer, Google Cloud’s managing director for supply chain and logistics stated that companies are using end-to-end data to better manage risks at different junctions in the supply chain to avoid breakdowns.
Brand Reputation Risk
Suppliers have to be true to their mission and think about their reputation. Fortunately, AI technology can make this easier.
There are a few ways that a company’s brand can be negatively impacted by a member of its supply chain. If a supplier maintains poor practices that result in frequent product recalls, the business selling those products might be viewed by consumers as equally negligent and untrustworthy. Likewise, if a supplier publishes messaging that contradicts a brand’s marketing messages, consumers might become confused or disheartened by the inconsistency of the partnership. Because the internet reveals more about supplier relationships and social media provides consumers with louder voices, businesses need to be especially careful about the brand reputation risks they face in their supply chains.
How can AI help with brand reputation management? You can leverage machine learning to drive automation and data mining tools to continue researching members of your supply chain and statements your own customers are making. This will help you identify issues that have to be rectified.
Competitive Advantage Risk
Businesses that rely on the uniqueness of their intellectual property face risks in working with suppliers, who might sell that IP, counterfeit goods or otherwise dilute the market with similar products.
Saturated markets require companies to develop some kind of unique selling proposition to provide them with a competitive advantage. Unfortunately, the power of that competitive advantage can wane if a business opts to work with an untrustworthy supplier. In other countries, rules about intellectual property are less rigid, and suppliers might be interested in generating additional revenue by working with a business’s competitors, offering information about secret or special IP. Though the supply chain itself might be unharmed by this risk, this supplier behavior could undermine a business’s strategy and cause it to fail.
AI technology can help suppliers improve their competitive risk in numerous ways. They can save money through automation, identify more cost-effective ways to transport goods and improve value in other ways with artificial intelligence.
Price and Cost Risk
This risk involves unexpectedly high prices for suppliers or services. In some cases, business leaders do not adequately budget for the goods and services they expect from their suppliers; in other cases, suppliers take advantage of a lack of contract or “non-firm” prices to raise their costs and earn more income from business clients. This is one of the easiest risks to avoid, as business leaders can and should perform due diligence to understand reasonable rates amongst suppliers in their market.
AI technology can also help in this regard. Machine learning tools have made it a lot easier to conduct cost-benefit analyses to recognize opportunities and risks.
Quality Risk
Cutting corners can cut costs but doing so can also result in poor product or service quality that is unattractive to consumers. Businesses need to find a balance between affordability and quality when considering which suppliers to partner with.
Some suppliers maintain a consistent level of high or low quality, but with other suppliers, quality can rise and fall over time. Some factors that can influence quality include material and labor cost in the supplier’s region, shipping times and costs and the complexity of the product or service required. Business leaders who recognize a dip in quality might try to address the issue with their current supplier before looking for a new supplier relationship.
Fortunately, AI can help identify any of these issues.
The Best Risk Mitigation Strategy Requires AI Technology
AI technology has made it a lot easier for suppliers to manage their risks. Undoubtedly, the best way to mitigate the risks associated with suppliers is with a robust supplier risk management system. The right AI tools and procedures help business leaders perform more diligent research and assess supplier options more accurately to develop a supply chain that is less likely to suffer from delays, failures, low quality, undue costs and other threats. Risk management software developed for the supply chain help business leaders build and maintain strong relationships with top-tier suppliers, which should result in a stable and lucrative supply chain into the future.
Global companies spent over $2.83 billion on marketing analytics in 2020. This figure certainly increased in light of the pandemic, as digitization accelerated.
Marketing has always been about numbers. Now, those numbers are highly refined, narrowed by algorithms and databases, and processed by people with advanced degrees. Indeed, data and marketing are a match made in heaven, taking much of the guesswork out of a profession that once was as much about luck as it was about creativity.
In this article, we look at how data impacts marketing. We also review what it takes for a business’ marketing division to find real success with their data implementation efforts.
Technique Matters:
Proper data analysis is very method dependent. Businesses that wish to use data in their marketing efforts first need to consider what data analysis techniques are right for them, and how they can use them to improve outcomes.
Some degrees specialize in data-driven marketing. To truly master this art form, consider pursuing an advanced degree in data analysis, or investing in staff with the appropriate background.
Knowing Your Audience
The best thing about data in marketing is that it helps you understand who your audience is. This is critical not only in how you describe your product but also in how it is framed. If your audience consists primarily of middle-aged business people, you’ll probably want to reach for a more formal tone. If your audience is millennials, humor might be more appropriate.
Data reveals the story that marketers need to tell.
Knowing What Features to Emphasize
Your product can probably do a lot more things than you are going to want to fit into a Tweet or a short ad. A successful marketing campaign knows how to emphasize the features that will appeal to the largest number of people.
Of course, not every marketing campaign is about casting the widest possible net. Numbers can also help you narrow the focus of your messaging by zeroing in on what features your best customers respond the most to. Not only does this maximize the impact of your ad efforts, but it also helps attract ideal customers: people who stick around, spend lots of money, and offer referrals.
How to Market Your Product
Data can also make your outreach efforts significantly more impactful. Most social media sites feature their own ad analytic software that helps you see who your demographic is and when they are most likely to be online.
Using this information, you can create targeted ads that only show up during the peak web traffic periods. Not only does this boost ad engagement but it also makes sure you aren’t wasting money.
The Necessity Of Making it A Data-Driven Culture
It’s important to understand that half measures will never produce any of the results listed above. Companies all too often invest heavily in data infrastructure, buying tools and software subscriptions that never get used, or worse yet, get used poorly. Superficial data implementation can lead to:
High rates of turnover: Employees who have little or no tech experience are often very discouraged when they are told they need to master a new software tool. It’s important to allocate a significant amount of time (months) to training. No one should be expected to master the tech overnight. True data implementation is a long-term investment and should be treated as such.Wasted Tech: On the flip side, some people will just ignore new software entirely. The average American worker has a company-provided tech stack filled with tools they don’t understand and never use. Why? Usually, it comes down to company leadership. If management isn’t taking data implementation seriously, the staff won’t either.Half-baked conclusions: Finally, poor data implementation also just produces bad results. Unless the training is significant and the tools are on point, the conclusions generated by a data implementation strategy are not going to produce the results you are looking for.
A true data-driven culture stems from the top down. Management must take the adaptions seriously, work towards understanding and implementing themselves, and check in regularly with the rest of the staff, not to breathe down their necks, but to address concerns and see how they can help smooth the transition along.
Analytics is becoming more important than ever in the world of business. Over 70% of global businesses use some form of analytics. This figure will rise as globalization, supply chain challenges and other factors increase competitiveness.
This is an important year for enterprises keeping in view that most global industries are recovering from the pandemic horror, and the era of web 3.0 is at the doorstep. For both reasons, the role of CIOs has to embrace automation and analytical thinking in strategizing the organization’s initiatives. Until now, they were proactively involved to maximize IT efficiencies and accelerate cost savings in general.
However, the rapid technology change, the increasing demand for user-centric processes and the adoption of blockchain & IoT have all positioned business analytics (BA) as an integral component in an enterprise CoE. They are using analytics to help drive business growth. And since no one except CIOs has the technical nerve of a business; they are seizing the opportunity to increase value to the organization while positioning themselves as thought leaders.
While we are at it, Gartner’s 2022 report on business composability further pushes the need for analytics. It suggests the immediate need for decision-makers including CIOs to embrace automation to absorb the pressures of the rapidly changing business landscape.
Continuous Building of BA practice in your organization
Even though business analytics operates across organizational verticals and all levels of the hierarchy, a CIO owns the responsibility to ensure the building of the practice. It requires a deep-rooted understanding of the organizational workflows and the scope of analytics in making significant improvements. Therefore, building BA is a continuous practice and often involves partners to kick-start.
One such education institution called Adaptive US collaborates with multiple organizations with a focus on building/improving their BA practice. Such platforms provide full-stack training solutions for IIBA certifications & several training programs for professionals of different work experience groups. Various educational groups deliver sessions in different formats such as self-learning, guided learning, live & recorded sessions, exam prep sessions, office hours and others to suit the learning needs of the various kinds of learners.
CIOs, in collaboration with such groups, can categorize their practice building into 3 focus areas:
Team Upskilling: Train business analysts on planning, gap analysis, scoping & blueprinting, cost-benefit calculation of new initiatives, solution architecture, modelling, elicitation, requirement management, performance management, and other improvement initiatives. Process Upgrade: Ensure following industry standards and benchmarking the process against the Business Analysis Body of Knowledge (BABOK) and modernize them.Tools Updating: A business analyst is as good as his/her tools. Having effective tools is vital to the organization’s success. Having cost-effective and high-quality business analytics tools such as Atlassian, MS Visio, Business Process Modeller, Balsamiq, and similar BA tools is essential for org initiative improvement.
Not to miss, Cloud analytics are increasingly dominating their on-premise predecessors. It is growing at a CAGR of 23.0% and shall touch USD 65.4 bn by 2025.
Executive Portfolio Management
Unlike previously when only corporates would consider portfolio management as an important arm of C-level decision making, scenes are different today. Given the on-demand accessibility of data, start-ups and SMEs want their CIOs to manage resource investments through application portfolios, infrastructure portfolios, and project portfolios.
Since there’s vast information at disposal, business analysis has a crucial role for CIOs. Here, the dashboard could include project health elements such as cost, schedule, scope, ROIs, feedback, value to the partner, evaluation of meaningful outcomes, and management hierarchy to name a few. Not to miss, a low-level (detailed) view of such a dashboard would include a problem statement, business case, status, budget, delegation, etc.
The answers captured above further enable a CIO to create a top-level view and evaluate how optimal is the spending, how progressive is the pipeline and ultimately how on track are the committed deliverables.
Extract Value From Customer
Predictive analytics have an unquestionable influence on drawing patterns around consumer behavior and their likelihood to either re-subscribe or discontinue the service. Based on the engagement with the product, the customer experience team, a key part of the CIO’s team has to score customers on these metrics and position them in the growth funnel, also known as the pirate funnel.
This sales/marketing funnel can consume insights from BA to predict the probability of upselling. Subsequently, the outcome of the tool/funnel would prompt the ‘sales’ to offer incentives or other rewards against an upsell or referral to the potential customers. This analytical ability to predict customer churn can assist insetting appropriate goals but also strengthening their financial planning area as discussed previously.
Financial Management
Financial planning is a critical area and involves all stakeholders including CIOs. For most organizations, it sets the narrative for project forecasting, recruiting, scaling, and others. CIOs, along with everyone on the leadership board use finance models to anticipate any hurdles.
For CIOs, financial planning coupled with business forecasting through analysts is a primary role. So if the overall spending trails the expected forecast, it’s a good indicator and an opportunity to discover newer avenues that could work for the organization. At the same time, if the spending exceeds the expected limit, CIOs have to identify weak links and rewrite the quarterly plan.
Financial visualization in key areas can fuel analytical decision-making. These include budgeting, forecasting, actuals & accruals, variance & absolute variance, spending economics, vendors, contracts, and more.
Conclusion
Organizations waking up to the importance of analytics at C-level decision-making need no detailing. However, the market trends in the post-pandemic era ask for rapid adoption and CIOs are at the helm of that transformation. So far, we discussed the confluence of business analytics across verticals and how that changes the role of CIOs. From the discussion, it is inevitably clear that this association will further strengthen in the web 3.0 era. Organizations that have captured the hint will have a lasting stint in the competition.
If you are building a career in business analytics, you are a step closer to building a profession as a future CIO.
Businesses have been using websites to reach customers for nearly 30 years. The first websites predated modern analytics technology. Google Analytics wasn’t launched until 2005. However, advances in analytics over the past decade have made it easier for companies to create quality websites. This has in turn increased the demands of customers using modern websites.
If you are trying to create a great website, then you have to leverage analytics tools to improve the quality of your site by assessing the right metrics. Keep reading to learn more about using analytics to optimize your website.
Analytics is Crucial for Optimizing Websites
Your website is only as brilliant as the amount of effort you put into it. A well-built site will automatically respond to your visitors by tailoring content for their needs. More thoughtful websites make users happier, generate more leads and conversions, and increase the odds that they will return.
A more imaginative visitor experience takes time to accomplish. However, making investments will give you the best return based on your goals and resources is best.
Web optimization positively impacts your revenue, whether you profit from advertising or sales via content distribution. You can use sophisticated digital and behavior analytics technology.
Analytics technology can measure the effectiveness of your website’s elements, reveal weak areas, and show you what needs improvement. You can track every performance component, including network bandwidth usage, user interaction patterns, and system response times.
One of the best ways to use analytics in website optimization is to test different value propositions. This will help you choose the best for your website.
A value proposition is a message that your site sends to visitors. It’s the promise of what you’ll provide, including customer service and products or services.
Your site should include offers highlighting your product or service and highlight what makes it distinguishable from other options available. It’s also vital that the value proposition is tailored to your audience and does not come across as generic or insincere.
You want to use Google Analytics or another website analytics tool to split-test different value propositions. You can create a Conversion Goal in Google Analytics and test the effectiveness of each value proposition to see which ones work the best.
Optimize your visual creatives
You will also want to use analytics technology to test different visual creatives. You can evaluate many different images, banners and buttons by setting up conversion goals in Google Analytics or creating heat maps with analytics tools like Crazy Egg.
Visuals are a super important part of any website. It’s a great way to bring your website to life and help you stand out in the crowd. Consider investing in photography and video production.
Visual content can build awareness, increase engagement and generate sales. It’s also great to share personal stories and experiences with your target audience. Remember that maintaining clear and consistent visual elements, including color, graphics, and contrast, is essential.
Therefore, you should use analytics tools to carefully optimize all of your visual creatives.
Focus on mobile responsiveness
Mobile devices account for a significant portion of all web traffic. To meet the growing needs of your customers, make sure your website is mobile-friendly.
Your site should also be compatible with multiple mobile devices, including smartphones, tablets, and small handhelds. Remember to include instructions and information about any mobile device-specific features.
Analytics technology helps you see how customers respond to different elements, so you can tweak them accordingly. You can also use AI applications that make websites more responsive.
Prioritize accessibility
Analytics technology can also help make your website more accessible to people with disabilities. Tom Widerøe has an entire article on Medium on this topic titled Can we use web analytics to improve accessibility?
Web standards allow people with disabilities to access websites, including those with impaired vision and hearing loss. For example, you can include alternate content such as text descriptions or transcripts for visual media, braille transcripts for audio content, and text-to-speech technologies for video and audio content.
Analytics technology helps identify the areas where people with disabilities will struggle to access your content. However, you will need to know what changes to make.
Alternatively, you can also use screen readers to provide access for blind users to multimedia content. If you aren’t already implementing these principles, it may be an excellent time to review your site’s accessibility and make any necessary updates.
Identify key integrations
You can also use analytics technology to identify outdated plugins or other issues. Then you can take measures to update your site.
One of the quickest ways to improve your site’s functionality is by integrating it with other web and mobile applications. Integrate your website with email marketing solutions, digital dashboards, and lead management services.
Site owners can use plugins that add to their existing customer platforms, such as shopping carts, and eCommerce platforms, such as Shopify. You can also integrate your website with social media platforms like YouTube, Facebook, and Twitter.
Test different calls to action
A clear CTA is vital for creating a memorable experience for your website visitors. Chances are, if your site lacks one, you may be missing the opportunity to keep your website visitors engaged with the content.
Compel users to take action and increase the chances of making a purchase, subscribing to your email list, or downloading your content.
Again, you will want to use analytics tools to test different calls to action. Setting up conversion goals in Google Analytics will help a lot.
Update regularly
Your website must reflect the same quality, functionality, and aesthetic style you display in your marketing materials. If not, then you’re quickly losing traffic to competitors.
You may find it easier to implement updates after the initial launch, so there is less risk of messing up or forgetting about them later. You can also use the timed release of new features as a way to ensure a consistent level of improvement throughout the life cycle of your website and content.
Analytics Technology is Essential for Website Optimization
With a more imaginative visitor experience, you’re more likely to generate better results. With transparent analytics and progress tracking, you can measure the success of your efforts and closely monitor website performance. Using effective web design, you can quickly build a more substantial online presence while retaining the interest of your online customers.
Data science is both a rewarding and challenging profession. One study found that 44% of companies that hire data scientists say the departments are seriously understaffed. Fortunately, data scientists can make due with fewer staff if they use their resources more efficiently, which involves leveraging the right tools.
There are a lot of important queries that you need to run as a data scientist. You need to utilize the best tools to handle these tasks.
One of the most valuable tools available is OLAP. This tool can be great for handing SQL queries and other data queries. Every data scientist needs to understand the benefits that this technology offers.
Using OLAP Tools Properly
Online analytical processing is a computer method that enables users to retrieve and query data rapidly and carefully in order to study it from a variety of angles. Trend analysis, financial reporting, and sales forecasting are frequently aided by OLAP business intelligence queries. (see more).
A user can ask for data to be examined so that they can see a spreadsheet with all of an industry’s beach ball products that are sold in Florida in July, compare revenue statistics with all those for almost the same items in September, and compare other demand for a product in Florida during the same time period.
Several or more cubes are used to separate OLAP databases. The cubes are structured in such a manner that it is simple to create and read reports. Online Analytical Processing (OLAP) is a term that refers to the process of analyzing data online.
Data processing and analysis are usually done with a simple spreadsheet, which has data values organized in a row and column structure. For two-dimensional data, this is ideal. OLAP, on the other hand, comprises multidimensional data, which is typically collected from a separate and unrelated source. Using a spreadsheet isn’t the best solution.
What is the mechanism behind it?
The data is processed and modified after it has been extracted. Data is fed into an Analytical server (or OLAP cube), which calculates information ahead of time for later analysis. A data warehouse extracts data from a variety of sources and formats, including text files, excel sheets, multimedia files, and so on.
Types:
HOLAP stands for Hybrid Online Analytical Processing. The consolidated totals are saved in a data model in the HOLAP technique, while the particular data is maintained in a relational database. This provides both the ROLAP model’s data efficiency and the MOLAP model’s performance.
OLAP on the desktop (DOLAP): In Desktop OLAP, a person receives a dataset from the system and analyzes it locally or on their desktop.
Portable OLAP: Mobile OLAP allows users to use their device to access and evaluate OLAP data.
Web OLAP (WOLAP) is an OLAP system that can be accessed through a web browser. The WOLAP architecture is three-tiered. There are three parts to it: a client, software, and server software.
SOLAP (Spatial OLAP) was developed to make it easier to manage both temporal and non-spatial data in a Gis Mapping (GIS).
ROLAP (Relational OLAP): ROLAP is an extended RDBMS that performs typical relational operations using multidimensional data mapping.
A single OLAP cube cannot have a significant number of dimensions.OLAP necessitates data organization into something like a snowflake schema. These schemas are difficult to set up and maintain.Any change to an OLAP cube necessitates a complete upgrade of the cube.An OLAP system cannot access transactional data.
The Benefits of OLAP
There are also benefits of using OLAP, which include:
OLAP is a business platform that encompasses strategy, planning, monitoring, and analysis for many types of businesses.In an OLAP cube, data and calculations are consistent. This is a significant advantage.Search the OLAP data for broad or particular terms with ease.Create and analyze “What if” scenarios quickly.Corporate simulation models, and performance reporting tools all use OLAP as a foundation.It’s useful for looking at time series.Users can slice up cube data using a variety of metrics, filters, and dimensions.With OLAP, finding clusters and anomalies is simple.
The online analytical processing tool, also known as the OLAP, is a technology which helps the researchers and surveyors to look into their business from the various overviews.
The current world is undergoing a rapid transformation as a direct result of the many scientific breakthroughs and technological advancements enabling the production of an abundance of intelligent gadgets, appliances, and systems.
Such intelligent devices, gadgets, and systems encompass automation, smart sensor networks, communication systems, and various other gadgets. Examples are robotics, smart cars, intelligent transport systems, and home robotization.
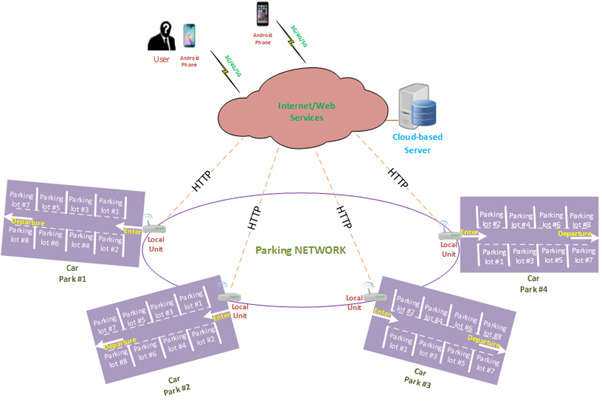
The management of parking lots is not a simple job for businesses and other organizations since there are many moving factors, such as the flow of traffic and the number of available places.
It is an activity that needs human effort, takes a lot of time, and is wasteful overall. Utilizing a parking management system may assist a company in lowering the administrative expenses associated with parking and lessening their parking space’s influence on the neighbourhood in which they are located.
Smart Parking is a low-barrier solution because it can be installed quickly and easily, is scalable, and is economical. It is the ideal solution for contemporary cities that wish to leverage the power of the internet of things while providing possible advantages to their residents.
Deep Learning Technology has started being used increasingly in managing parking areas. Learn more here.
What is Deep Learning Technology
Deep learning is a kind of machine learning that involves teaching machines to understand in the same way people do naturally, via observation and imitation of others.
Deep learning is one of the most important technologies underpinning autonomous vehicles since it allows them to detect things like stop signs and tell a human from a signpost.
It is essential to implement voice control in consumer electronics like mobile phones and tablets, televisions, and hands-free speakers. Recently, many emphases have been focused on deep learning, and for a good reason.
It means accomplishing goals that could not have been done in the past. A computer model may learn to execute categorization tasks directly from pictures, text, or voice using a technique known as “deep learning.”
Models trained using deep learning have the potential to attain an accuracy that is comparable to or even superior to that of humans.
And What is Parking Management System
Innovative technologies that answer problems in the parking business are collectively referred to as park management systems.
The fundamental concept that underpins any parking management system is easy to understand. People, businesses, and other organizations may benefit from this approach to better manage parking areas.
Car Parking Problems That the Modern Drivers Are Facing
Nearly two-thirds of U.S. drivers described experiencing worried when searching for parking, as per the research. The research also found that almost 42% of Americans had missed a meeting, 34% had aborted a visit due to parking challenges, and 23% had been the victim of bad driving.
Secured parking has become more sought after owing to two primary trends: development and a rise in automobile ownership. Drivers are having difficulty finding a parking space due to an increase in automobiles on the road.
Drivers in highly crowded locations lose a lot of money, production, and time due to the inefficiency of the existing parking structure. This irritates motorists and adds to the volume of traffic, increasing commuting times by 35 percent.
As a result, typical parking systems aren’t up to the task of making parking easier for drivers while lowering the amount of time they spend searching for a spot.
This demonstrates the logic for using cutting-edge technology in urban transportation to modernize the system and alleviate the difficulties experienced by drivers.
Ways Through Which the Deep Learning Technology Helps Parking Management Systems
Here are some of the most prominent ways through which the Deep Learning Technology helps parking management systems improve:
Reduces Search Traffic on Streets
The hunt for parking spots is responsible for over a third of all of the congestion that can be seen in metropolitan areas. Cities can better manage and reduce the amount of parking search traffic on the roads thanks to parking management solutions.
This software also assures parking safety, but its most significant contribution to reducing traffic congestion is that it makes the parking experience quicker, more pleasant, and less burdensome overall.
There will be fewer automobiles driving in circles around the neighbourhood looking for a parking place due to the use of intelligent parking technology.
This finally makes traffic flow smoother and reduces the amount of search traffic on the streets to the greatest extent feasible.
Eliminate Parking Stress
Most people want to avoid travelling to the more crowded parts of the city because they do not want to find themselves caught up in the parking problem that causes tension and anxiety among drivers.
It is frustrating to know that you will have to spend a lot of time looking for parking spots but that you will ultimately have to park your vehicle in a location that is quite a distance from where you need to be.
In addition, it is a source of frustration to have to drive up and down the same street many times to locate a parking spot, but to no avail.
The goal of developing Deep Learning Technology is to remove the stress associated with parking for motorists.
The users of the smart parking apps are informed about the available parking spots in the region they want to visit.
The uncertainty and stress involved with locating a suitable parking place close to the intended location are reduced as a result.
Minimize the Personal Carbon Footprint
One additional advantage of smart parking is that it helps cut down on the pollution caused by automobiles by reducing traffic and the need for drivers to move about as much as they do now.
When drivers have to go from one location to another for parking, this increases the individual environmental footprint.
In the United States, the average time spent searching for parking by car is about twenty minutes, which wastes fuel and time and contributes to increased congestion in metropolitan areas.
The longer it takes to find a parking spot, the greater the carbon footprint left behind; however, this time may be cut down significantly with the assistance of an intelligent parking solution.
There is a negative effect on the environment caused by the carbon dioxide emissions produced by all types of fuel, including diesel, gasoline, and fossil fuel.
The fact that the emissions from personal carbon footprints caused by automobiles do not immediately affect human existence is another unfavorable aspect of these emissions. Still, they might be a component in the progression of climate change.
When intelligent parking solutions are incorporated into metropolitan areas, there is a subsequent reduction in a person’s environmental footprint, particularly the amount of carbon dioxide released.
A Time and Cost-Efficient Solution
Intelligent parking technology may result in time and financial savings for motorists. When the drivers reach the crowded parking lot, they spend several minutes looking for a location to park their vehicles.
Since of this, eventually, they are wasting their time, which causes them to get upset because the drivers cannot arrive at the required place on time.
Similarly, travelling more kilometres in search of parking causes an increase in wasted gasoline, which in turn causes an increase in the amount of money spent by the drivers of the automobile’s fuel.
A system based on the Internet of Things (IoT), Smart Parking is outfitted with sensors that convey data to apps regarding empty parking places.
Instead of spending time and fuel driving around in circles looking for a parking spot, the drivers may use this application to guide them to the now available places.
Helps Consume Less Fuel
Deep Learning Technology is a consequence of human inventions and technology that allows easy access to parking places and helps save precious resources, including fuel, time, and space.
Deep Learning Technology is an outcome of human innovations and advanced technology. Deep Learning Technology provides easy access to the parking spots. When Deep Learning Technology is implemented in metropolitan areas, cars are directed directly to vacant parking places.
This makes the most efficient use of limited space. Because of this, there is no longer a need to drive additional kilometres to locate available parking places.
Because of this, using the Deep Learning Technology results in less wasted gasoline, which eventually saves the drivers money and makes the parking experience more pleasant for them.
Now Businesses Have More Commercial Parking for Rent!
Now you know how Deep Learning Technology has impacted the parking management system. In the world that we are living today, such innovations have made major advancements to accommodate people and businesses.
One major advantage for businesses is freeing up many spaces for a commercial parking lot for rent. Businesses have used data algorithms to ensure they stay ahead of the curve and generate sustainable profits.
Machine Learning (ML) is part of everything we do at Wayfair to support each of the 30 million active customers on our website. It enables us to make context-aware, real-time and intelligent decisions across every aspect of our business. We use ML models to forecast product demand across the globe, to ensure our customers can quickly access what they’re looking for. Natural language processing (NLP) models are used to analyze chat messages on our website so customers can be redirected to the appropriate customer support team as quickly as possible, without having to wait for a human assistant to become available..
ML is an integral part of our strategy for remaining competitive as a business and supports a wide range of eCommerce engineering processes at Wayfair. As an online furniture and home goods retailer, the steps we take to make the experience of our customers as smooth, convenient, and pleasant as possible determine how successful we are. This vision inspires our approach to technology and we’re proud of our heritage as a tech company, with more than 3,000 in-house engineers and data scientists working on the development and maintenance of our platform.
We’ve been building ML models for years, as well as other homegrown tools and technologies, to help solve the challenges we’ve faced along the way. We began on-prem but decided to migrateto Google Cloud in 2019, utilizing a lift-and-shift strategy to minimize the number of changes we had to make to move multiple workloads into the cloud. Among other things, that meant deploying Apache Airflow clusters on the Google Cloud infrastructure and retrofitting our homegrown technologies to ensure compatibility.
While some of the challenges we faced with our legacy infrastructure were resolved immediately, such as lack of scalability, others remained for our data scientists. For example, we lacked a central feature store and relied on a shared cluster with a shared environment for workflow orchestration, which caused noisy neighbor problems.
As a Google Cloud customer, however, we can easily access new solutions as they become available. So in 2021, when Google Cloud launched Vertex AI, we didn’t hesitate to try it out as an end-to-end ML platform to support the work of our data scientists.
One AI platform with all the ML tools needed
As big fans of open source, platform-agnostic software, we were impressed by Vertex AI Pipelines and how they work on top of open-source frameworks like Kubeflow. This enables us to build software that runs on any infrastructure. We enjoyed how the tool looks, feels, and operates. Within six months, we moved from configuring our infrastructure manually to conducting a POC, to a first production release.
Next on our priority list was to use Vertex AI Feature Store to serve and use AI technologies as ML features in real-time, or in batch with a single line of code. Vertex AI Feature Store fully manages and scales its underlying infrastructure, such as storage and compute resources. That means our data scientists can now focus on feature computation logic, instead of worrying about the challenges of storing features for offline and online usage.
While our data scientists are proficient in building and training models, they are less comfortable setting up the infrastructure and bringing the models to production. So, when we embarked on an MLOps transformation, it was important for us to enable data scientists to leverage a platform as seamlessly as possible without having to know all about its underlying infrastructure. To that end, our goal was to build an abstraction on Vertex AI. Our simple python-based library interacts with the Vertex AI Pipeline and Vertex AI Features Store. And a typical data scientist can leverage this setup without having to know how Vertex AI works in the backend. That’s the vision we’re marching towards–and we’ve already started to notice its benefits.
Reducing hyperparameter tuning from two weeks to under one hour
While we enjoy using open source tools such as Apache Airflow, the way we were using it was creating issues for our data scientists. And we frequently ran into infrastructure challenges, carried over from our legacy technologies, such as support issues and failed jobs. So we built a CI/CD pipeline using Vertex AI Pipelines, based on Kubeflow, to remove the complexity of model maintenance.
Now everything is well arranged, documented, scalable, easy to test, and well organized in terms of best practices. This incentivizes people to adopt a new standardized way of working, which in turn brings its own benefits. One example that illustrates this is hyperparameter tuning, an essential part of controlling the behavior of a machine learning model.
In machine learning, hyperparameter tuning or optimization is the problem of choosing a set of optimal hyperparameters for a learning algorithm. A hyperparameter is a parameter whose value is used to control the learning process. Every machine learning model will have a different hyperparameter, whose value is set before the learning process begins. And a good choice of hyperparameters can make an algorithm perform optimally.
But while hyperparameter tuning is a very common process in data science, there are no standards in terms of how this should be done. Doing it in Python using a legacy infrastructure would take a data scientist on average two weeks. We have over 100 data scientists at Wayfair, so standardizing this practice and making it more efficient was a priority for us.
With a standardized way of working on Vertex AI, all our data scientists can now leverage our code to access CI/CD, monitoring, and analytics out-of-the-box to conduct hyperparameter tuning in just one day.
Powering great customer experiences with more ML-based functionalities
Next, we’re working on a docker container template that will enable data scientists to deploy a running ‘hello world’ Vertex AI pipeline. It can take a data science team more than two months to get a ML model fully operational on average. With Vertex AI, we expect to cut down that time to two weeks. Like most of the things we do, this will have a direct impact on our customer experience.
It’s important to remember that some ML models are more complex than others. Those that have an output that the customer immediately sees while navigating the website, such as when an item will be delivered to their door, are more complicated. This prediction is made by ML models and automated by Vertex AI. It must be accurate, and it must appear on-screen extremely quickly while customers browse the website. That means these models have the highest requirements and are the most difficult to publish to production.
We’re actively working on building and implementing tools to streamline and enable continuous monitoring of our data and models in production, which we want to integrate with Vertex AI. We believe in the power of AutoML to build models faster, so our goal is to evaluate all these services in GCP and then find a way to leverage them internally.
And it’s already clear that the new ways of working enabled by Vertex AI not only make the lives of our data scientists easier, but also have a ripple effect that directly impacts the experience of millions of shoppers who visit our website daily. They’re all experiencing better technology and more functionalities, faster.
For a more detailed dive on how our data scientists are using Vertex AI, look for part two of this blog coming soon.
Artificial intelligence has become a very important technological development in the life sciences. Michel L. Leite and his colleagues at Universidade Católica de Brasília addressed this phenomenon in their study Artificial intelligence and the future of life sciences.
AI is helping advance the life sciences in many ways, which include improving the outcomes of clinical trials and making certain features more accessible to both researchers and patients. One of the benefits of AI in the life sciences is in the field of cryopreservation.
Cryopreservation is the practice of preserving cells and tissues. It is a complex process where things can easily go wrong, but AI technology can help mitigate some of the challenges.
How Can AI Improve the State of Cryopreservation?
There is a growing need for stem cell storage which makes the idea of starting a business around this practice can be very profitable. Companies like IBM have also been involved in biological research. However, the preservation of the cells can be a very complex challenge to overcome. Getting the cells preserved while also maintaining their structural integrity is complex and is the reason why so many labs will outsource storage.
There are many benefits of using artificial intelligence in these settings. They include improving safety and making sure biological materials are stored optimally. It also helps with bioinformatics.
In order to appreciate the benefits of using AI, it is important to first understand the issues clinicians and researchers will face. Biological material needs to be preserved for long periods of time and it is essential that it be kept in the same exact condition by the end of the process as it was in during the beginning. If you are trying to do this as a medical field business then it is important to understand the process well. In this article, we will go over the essentials to keep in mind when you are trying to use a cryopreservation liquid nitrogen freezer for stem cell preservation.
Here are some ways that AI can help with this process.
1 – Identify the best medium with machine learning
Every system is going to need its own medium to successfully preserve the samples. It is crucial to understand which one is going to give you the right results.
Cryoprotectants are used for a few primary reasons. The first is to slowly freeze the sample while also reducing the salt concentrations. Secondly, they decrease cell shrinkage, and lastly, they minimize intracellular ice formation. With all that in mind, it is usually the case that you’ll need Glycerol, salts, and dimethyl sulfoxide (DMSO).
Some of these protectants are more effective at protecting biological systems that are cooled quickly since they promote extracellular glass formation. It’s important that the water remains liquid during this process which requires a temperature just below the glass formation stage.
For some applications, ready-to-use solutions are the best idea as they are the most effective and also easy to use. They also work with various media for great results. Unfortunately, they may not be best for all storage options.
AI technology is useful for identifying the best mediums to store biological material. Many labs carefully track data on the different storage systems they use and figure out which ones seem to work best under different conditions. An application with AI monitoring tools can recommend the best medium for a given material based on readily available data.
2 – Use the right method
The freezing method is as important as any other part of the process. There are several different methods to choose from but the one that’s best for you is the one that will give you specific results with your specific medium and sample.
The most common method and one that works very well with many different media is liquid nitrogen. It’s a popular choice due to it being chemically inert, non-flammable, and often the most economical.
Another common method is using Direct Temperature Feedback which does also use liquid nitrogen as it’s injected directly into the chamber and automatically adjusts for freezing rates.
When using a small number of straws or vials, the Plunge Freezing method is useful as it controls the cooling temperature by submerging the block of vials which controls the freezing rate.
AI technology can make it easier to automate the use of these materials. You can use a robot that relies on machine learning technology to handle these processes, so you don’t have to expose yourself to harmful liquid nitrogen and can accurately control the use of these materials.
3 – Safety
The lab environment that uses a lot of nitrogen can be quite dangerous if protocols are not adhered to. Since it is odorless and colorless, it can be inhaled without knowing. It is important to make sure that all containers are properly sealed and stored in a way that will prevent them from exploding or becoming contaminated with other chemicals.
This is another area where AI technology can be very helpful. More clinicians and researchers are using AI to improve the safety of their labs.





{kind=link}
{kind=link}