Big data technology has led to some other major technological breakthroughs. We have talked in detail about applications of big data in marketing, financial management and even the criminal justice system. However, there are other benefits of big data that get less attention, even though they are also remarkable.
One of the newer applications of big data is with NFTs. The entire concept of NFTs is actually predicated on big data.
How Big Data is Creating a Booming Market for NFTs
Non-fungible tokens – or simply NFTs – have gained global recognition in recent years. They have been responsible for the significant changes across various sectors, including art and finance. As a result, many have posited the possibility of every part of society being influenced eventually by NFTs.
This might sound overblown, yet it is not. The past few years have demonstrated the potential effects that NFTs can have – being one of the most significant innovations – in sports, fashion, and tech, among others. Since NFTs became a norm in 2021, it has attracted all sorts of media hype and drama.
NFTs have been made possible due to advances in big data. Praphul Chandra, Founder and CEOof Koinearth wrote an article for The World Economic Forum titled If data is the new oil, then enterprise NFTs are the tankers. Here’s why. Chandra pointed out that there are many wonderful benefits of treating data as an asset, but there are logistical issues that make that difficult. NFTs have helped mitigate many of these challenges.
However, it can prove difficult to fully fathom the dramatic rise these tokens have enjoyed in recent times. To lend you a hand, this comprehensive guide will provide an insight into what NFTs are and how they work. Let’s dive in!
What are NFTs?
Non-fungible tokens are a unit of data on a blockchain network, which can offer stable proof of ownership when linked to a physical or digital asset. These tokens often contain data that can be connected to songs, images, avatars, and videos, among others.
Despite this, they can also help owners gain exclusive access to digital or live events, as well as being connected to physical assets, such as cars and more. Big data creates opportunities to make the most of NFTs. With this in mind, it is safe to affirm that NFTs can enable users not just to create items but buy and sell assets safely on blockchain technology.
However, it must be stressed that you can’t purchase intellectual property rights or copyright of the underlying asset, except stated otherwise. However, trading NFTs is not so straightforward. The next section will explain better.
Creating, Buying, Selling and Valuing NFTs with Data Science
As stated earlier, dabbling into NFTs is not so simple. Fortunately, data science has made it a lot easier to take advantage of them, as Dr. Stylianos Kampakis discusses in this post in The Data Scientist. To purchase one, cryptocurrencies are used to fund an NFT account while using a crypto wallet to safeguard the data when an NFT is bought.
You are also going to have to know how to value them. This is where data science becomes especially valuable.
There are various tools that can enable traders to make the most of NFT derivatives, including NFT Profit. The steps below will provide more insight into how to create and trade NFTs:
Acquire a crypto wallet
Crypto wallets are used to store digital assets. You can choose between a software or hardware wallet. However, while the former is more suitable for short-term trades, the latter is a safer means of storing and transferring valuable assets.
The cryptocurrency sector is benefiting tremendously from data analytics. One of the benefits is that analytics helps investors time their purchases and select the best cryptocurrencies.
You will come across several NFT marketplaces that allow the use of traditional methods of payment. These include MakersPlace and Nitty Gateway. A lot of data analytics tools help you assess the quality of different marketplaces. You should also look at reviews of them to find the best. On the other hand, OpenSea and SuperRare only support cryptocurrencies. ETH is the best crypto for NFT transactions since most NFTs are part of the Ethereum blockchain at a high level.
Choose a Marketplace
Before choosing a marketplace, consider whether you need to mint a single NFT or a collection of these tokens in a batch. OpenSea represents one of the best places for the latter. You can also consider Rarible and LooksRare as well. Besides this, you should know that minting is associated with initial costs, which could be in the form of a transaction fee in some marketplaces. You should also acquaint yourself with royalty splits.
Mint a new NFT
Ensure that you must hold the intellectual property rights and copyright for the item you wish to mint before picking an item. This process is crucial since you can easily end up having legal issues if you create tokens by using assets that are not yours. You can create an account at your preferred marketplace. Then, you can start minting.
It is worth noting that some NFTs might only be purchased on the open market. However, you can buy your favorite NFTs immediately or, in some cases, make a bid on your preferred NFTs and wait until the closing of the auction.
Value Your NFTs
Data analytics can be used to value NFTs. Kampakis and one of his students developed a hedonic regression method with one of his students to value CryptoPunk. He points out that the same data analytics approach can be very useful or valuing other NFTs.
Big Data Has Made NFTs Valuable New Commodities
NFTs have grown in recognition across the far reaches of society. Big data has played a huge role in this sudden new market. NFTs serve so many purposes as a crucial modern innovation. However, creating, buying, and selling these tokens are not so simple. You must acquaint yourself to prevent getting into trouble during NFT transactions. The good news is that data analytics makes all of these steps easier.
The automotive industry is struggling to meet demand as a growing supply chain shortage cripples the global economy. Chip shortages, among other components, have fueled a steep increase in car prices, as much as USD$900 above the manufacturer-suggested retail price (MSRP) for non-luxury cars and USD$1,300 above MSRP for luxury ones.
Market analysts predict the supply chain to normalize in the third quarter of 2022, which is only a few months away as of this publication. In light of this, industry experts are using analytics to streamline production and minimize waste to address these challenges. Here’s an in-depth look into analytics and its role in the automotive sector.
The Fundamentals
It’s important to know that analytics is integral to every facet of car production, not only in supply chain optimization (more on that later). Everything from knowing consumer trends to ensuring a steady stream of resources requires data—lots of it. The cars themselves are valuable sources of data, an estimated 25 GB that can help manufacturers understand trends more.
Each aspect of the automotive workflow has its respective form of analytics. However, making the most out of these analytic processes entails integrating them into cross-value chain analytics, narrowing them down to four fundamentals:
Customer Behavior – Gauging the potential of various customer groups, catering to new customers while keeping old ones, and expanding the overall customer experienceMarketing Management – Measuring the impact of marketing campaigns on sales and other trends and developing auto repair advertising ideas and other campaignsPredictive Quality – Identifying possible defects and other issues in manufacturing lots, examining the need to issue recalls, and assessing warranty claimsSupply Chain Optimization – Anticipating trends to adjust the supply of specific parts and accessories and evaluating custom orders
Each of these is crucial in its own right, but turning tons of raw materials into a reliable and tech-laden vehicle begins with the supply chain. Car brands can study the market for trends and tailor their marketing campaigns based on them, but they won’t matter without the means to make the car that will deliver to customers.
Tackling The Issues
The lifeblood of any business or industry is its logistics, and car manufacturers are no different. Without the necessary components delivered to factories and service centers, manufacturing and repair activities can slow down, if not grind, to a stop.
Understanding how analytics will help curb the effects of supply chain issues in the automotive industry involves understanding the problems themselves. Industry experts have identified four critical issues that analytics need to address.
Supply Chain Visibility
A typical car needs an estimated 30,000 individual components (the exact number may vary depending on the make and model). It only takes one missing part for the whole vehicle to get stuck in production limbo.
Unfortunately, many experts agree that the automotive industry struggles with supply chain visibility. Difficulties in making orders and tracking their deliveries can hamper manufacturing. Resolving them becomes even more crucial for carmakers shifting to just-in-time manufacturing practices.
Recommendations include integrating suppliers into a common analytics platform to help identify delays and other problems. Analytics hardware and software that uses Internet of Things (IoT) technology can assist with real-time tracking.
Risk Management
The automotive industry faces numerous risks, from missed production goals to mishaps on the factory floor. Supply delays are no less significant for reasons explained earlier. Car makers should have contingencies, such as setting up secondary suppliers.
One standard method for mitigating risks is through a Failure Mode and Effect Analysis (FMEA). This method outlines how a business may suffer from failure and how it can affect the company in the short or long term. Businesses should conduct FMEA early in the design phase to have enough time to react to risks accordingly.
Quality Control
Regardless of the source of components, effective quality control is a must. Recalls are evidence that manufacturers may have overlooked something along the workflow and have to spend to replace the faulty parts.
Analytics can provide sufficient data to conduct internal and third-party audits of parts quality. Although internal quality control may be easy, getting suppliers to adhere to quality standards can be tricky. In this case, it all boils down to effective dialogue between the manufacturer and its suppliers.
External Factors
Risk factors like economic crashes, natural disasters, and—in this status quo—global health crises can hinder operations. While preventing them is beyond a manufacturer’s control, reducing their impact is well within.
Conclusion
As explained in this piece, analytics isn’t only integral for resolving the automotive industry’s many issues with its supply chain. It’s more or less being implemented significantly, helping manufacturers take careful steps as they build their products. It’s safe to say that analytics may hold the key to the more affordable and reliable cars of tomorrow.
Artificial intelligence technology has many implications for the fields of marketing and multimedia. Many marketers are using AI to create higher quality video content.
What Are the Benefits of AI Technology with Video Editing?
Video content is becoming more and more popular these days. According to Wyzowl, people now watch approximately 19 hours of online video per week. To create attractive and engaging videos, you need to have the right software at hand. However, editing videos is still a ton of work. The good news is that it can be done more efficiently with tools with sophisticated AI capabilities.
Video editing is much more efficient with AI. It used to take video editors between four or five hours to edit a single minute of footage. AI technology helps streamline the process and can save hundreds of hours of editing an hour long documentary. You can take advantage of powerful new features with AI. This includes using powerful filters and mockups that were previously unavailable to video editors before AI was available.You can automate many tasks with AI.
If you’re looking for the best video editing software, here are 5 different solutions you can try. They all use complex AI algorithms to edit videos more effectively.
While some of these video editors have a paid version with more features, there are plenty of great options that are completely free. So whether you’re a beginner or an experienced video creator, we have something for you! They all use machine learning technology to create quality video content.
In 2022, video editors are more popular than ever. Thanks to the advances in technology, you’re able to create truly stunning videos. From movies to TV shows, music videos to commercials, video editors are in high demand. And it’s no wonder why. A good video editor can take a boring concept and make it into something truly special. You can add effects, transitions, and voice-overs that bring the video to life and make it more engaging to your audience.
Best Free Video Editing Software for Desktop
If you’re looking to edit your promotional videos on a budget, check out our list of the 5 best free or partially free AI-based video editing software for 2022.
1. Adobe Premiere Rush
Adobe Premiere Rush is a great video editor app that has several advantages in today’s world of instant video sharing on social networks. It makes sense to include it as part of the Creative Cloud subscription ($52.99 per month), but a monthly fee of $9.99 seems excessive. If you believe that Rush may help solve your issues, try out the free Starter Plan, which provides three exports and 2 GB of server space.
Here are some of the selling points of this AI-based video editing tool.
Pros:
Simple and user-friendly interfaceExport in 1080pUnlimited desktop exportsChange video color, size, and positionAdd transitions, pan, zoom, and PiP effectsAutomatic reframingThe ability to change the aspect ratio of your video
Cons:
Lack of features in the free version of the softwareThe paid subscription is a bit pricey compared to other options
2. DaVinci Resolve
DaVinci Resolve is a powerful online video editor with a learning curve that can help you to create great clips by leveraging the power of artificial intelligence. The free version has no watermark and can export up to 1080p video. If you want to know how to edit videos, DaVinci can help you with that.
Pros:
A great set of features for experienced usersAdvanced color correction that is relatively easy to execute when compared to other alternatives.High-quality audio processing with FairlightExtensive resources to learn how to competently use the software as easy as possibleNo watermark on exported videos and audioFree or $299 one-time payment for the studio version
Cons:
The learning curve may be too steep for some usersThe free version lacks some advanced features that are only available in the paid versionWorking with multiple audio plugins with new windows for each can get a bit clutteringSome of the keyboard shortcuts for executing commonly used functions can be confusing, and it takes time to get used to them
3. Movavi Video Editor
Movavi Video Editor is a comprehensive AI-based video editing software solution that offers a wide range of features and tools for both novice and experienced users. The software is easy to use and navigate, which makes it simple to find the features you need. In addition, Movavi offers many tutorials and training resources to help you get the most out of the software.
Pros:
Intuitive interfaceThe ability to add transitions, titles, and stickersBuilt-in library of stock backgrounds, music, soundsHollywood-style effects and filtersFree or $59.95 one-time payment for the paid version
Cons:
The free version has a watermark which can be annoyingThe software lacks some professional features for trimming clips
4. Avidemux
Avidemux is a great AI-driven video editing app for both beginners and experienced users. It’s a free program that can be used on different operating systems. It has a simple interface that is easy to learn and use. Avidemux also has many features, including the ability to cut and join video files, change the video codec, add watermarks and subtitles, and more.
In addition, Avidemux is highly customizable, allowing users to change the interface layout, keyboard shortcuts, and many other settings. Here are the pros and cons of this AI video editing tool.
Pros:
Simple interface that is easy to learnA wide range of featuresFree or $19.95 one-time payment for the paid version
Cons:
The free version can only export up to 720p video, which may not be enough for some usersIntricate and confusing cut featuresBatch process unavailable
5. Blender
Blender is a powerful video editing software that has been gaining popularity in recent years. While it lacks some of the bells and whistles of more expensive editors, it more than makes up for it in terms of features and flexibility. One of the things that set Blender apart is its node-based interface, which allows for complex effects and compositing. This makes it ideal for artists and graphic designers who want to add an extra level of polish to their work. In addition, the software is also very capable when it comes to more traditional forms of video editing, such as trimming and cutting.
Cons:
A powerful set of features for experienced usersNo watermark on exported videos and audioFree or $129 one-time payment for the paid version
Cons:
The learning curve may be too steep for some usersThe free version lacks some advanced features that are only available in the paid version
6. VSDC Free Video Editor
VSDC Free Video Editor is a great choice for anyone looking for a powerful yet easy-to-use video editor that uses the best AI algorithms to create quality videos. The app is packed with features, yet it’s still easy to use. It supports many popular video formats, and it can be used to create videos of any length. In addition, VSDC offers a variety of ways to edit your videos, including trimmed sequences, picture-in-picture arrangements, and split-screen effects. Whether you want to create a short video for social media or a longer one for YouTube, VSDC Free Video Editor is worth checking out.
Pros:
A powerful set of features for experienced users4K and HD SupportBuilt-in DVD burning toolColor blending and filtersSpecific multimedia devices creationDesktop video captureNon-linear video editingNo watermark on exported videos and audioFree or $19.99 one-time payment for the paid version
Cons:
The learning curve may be too steep for some usersFor professional tools like motion tracking, stabilization, and beat syncing you need to switch to VSDC ProAudio waveform and hardware acceleration features aren’t available in the free version
AI-Based Tools Make Video Editing Easier than Ever
AI technology has made video editing easier than ever. However, you have to use the right AI-based video editing tools.
We all work in different areas and need video editors for specific tasks. To pick the software that is right for you, you need to take the time to explore the available alternatives. When choosing, always listen to your feelings, because the right video editor can only be found through trial and error. Good luck in mastering the digital world and finding a tool that will help you comfortably solve your problems!
Google Cloud Data Heroes is a series where we share stories of the everyday heroes who use our data analytics tools to do incredible things. Like any good superhero tale, we explore our Google Cloud Data Heroes’ origin stories, how they moved from data chaos to a data-driven environment, what projects and challenges they are overcoming now, and how they give back to the community.
In this month’s edition, we’re pleased to introduce Francisco! He is based out of Austin, Texas, but you’ll often find him in Miami, Mexico City, or Bogotá, Colombia. Francisco is the founder of Direcly, a Google Marketing Platform and Google Cloud Consulting/Sales Partner with presence in the US and Latin America.
Francisco was born in Quito, Ecuador, and at age 13, came to the US to live with his father in Miami, Florida. He studied Marketing at Saint Thomas University, and his skills in math landed him a job as Teaching Assistant for Statistics & Calculus. After graduation, his professional career began at some nation’s leading ad agencies before he eventually transitioned into the ad tech space. In 2016, he ventured into the entrepreneurial world and founded Direcly, a Google Marketing Platform, Google Cloud, and Looker Sales/Consulting partner obsessed with using innovative technological solutions to solve business challenges. Against many odds and with no external funding since its inception, Direcly became a part of a selected group of Google Cloud and Google Marketing Platform partners. Francisco’s story was even featured in a Forbes Ecuador article!
Outside of the office, Francisco is an avid comic book reader/collector, a golfer, and fantasy adventure book reader. His favorite comic book is The Amazing Spider-Man #252, and his favorite book is The Hobbit. He says he isn’t the best golfer, but can ride the cart like a pro.
When were you introduced to the cloud, tech, or data field? What made you pursue this in your career?
I began my career in marketing/advertising, and I was quickly drawn to the tech/data space, seeing the critical role it played. I’ve always been fascinated by technology and how fast it evolves. My skills in math and tech ended up being a good combination.
I began learning some open source solutions like Hadoop, Spark, and MySQL for fun and started to apply them in roles I had throughout my career. After my time in the ad agency world, I transitioned into the ad tech industry, where I was introduced to how cloud solutions were powering ad tech solutions like demand side, data management, and supply side platforms.
I’m the type of person that can get easily bored doing the same thing day in and day out, so I pursued a career in data/tech because it’s always evolving. As a result, it forces you to evolve with it. I love the feeling of starting something from scratch and slowly mastering a skill.
What courses, studies, degrees, or certifications were instrumental to your progression and success in the field? In your opinion, what data skills or competencies should data practitioners be focusing on acquiring to be successful in 2022 and why?
My foundation in math, calculus, and statistics was instrumental for me. Learning at my own pace and getting to know the open source solutions was a plus. What I love about Google is that it provides you with an abundance of resources and information to get started, become proficient, and master skills. Coursera is a great place to get familiar with Google Cloud and prepare for certifications. Quests in Qwiklabs are probably one of my favorite ways of learning because you actually have to put in the work and experience first hand what it’s like to use Google Cloud solutions. Lastly, I would also say that just going to the Google Cloud internal documentation and spending some time reading and getting familiar with all the use cases can make a huge difference.
For those who want to acquire the right skills I would suggest starting with the fundamentals. Before jumping into Google Cloud, make sure you have a good understanding of Python, SQL, data, and some popular open sources. From there, start mastering Google Cloud by firstly learning the fundamentals and then putting things into practice with Labs. Obtain a professional certification — it can be quite challenging but it is rewarding once you’ve earned it. If possible, add more dimension to your data expertise by studying real life applications with an industry that you are passionate about.
I am fortunate to be a Google Cloud Certified Professional Data Engineer and hold certifications in Looker, Google Analytics, Tag Manager, Display and Video 360, Campaign Manager 360, Search Ads 360, and Google Ads. I am also currently working to obtain my Google Cloud Machine Learning Engineer Certification. Combining data applications with analytics and marketing has proven instrumental throughout my career. The ultimate skill is not knowledge or competency in a specific topic, but the ability to have a varied range of abilities and views in order to solve complicated challenges.
You’re no doubt a thought leader in the field. What drew you to Google Cloud? How have you given back to your community with your Google Cloud learnings?
Google Cloud solutions are highly distributed, allowing companies to use the same resources an organization like Google uses internally, but for their own business needs. With Google being a clear leader in the analytics/marketing space, the possibilities and applications are endless. As a Google Marketing Platform Partner and having worked with the various ad tech stacks Google has to offer, merging Google Cloud and GMP for disruptive outcomes and solutions is really exciting.
I consider myself to be a very fortunate person, who came from a developing country, and was given amazing opportunities from both an educational and career standpoint. I have always wanted to give back in the form of teaching and creating opportunities, especially for Latinos / US Hispanics. Since 2018, I’ve partnered with Florida International University Honors College and Google to create industry relevant courses. I’ve had the privilege to co-create the curriculum and teach on quite a variety of topics. We introduced a class called Marketing for the 21st Century, which had a heavy emphasis on the Google Marketing Platform. Given its success, in 2020, we introduced Analytics for the 21st Century, where we incorporated key components of Google Cloud into the curriculum. Students were even fortunate enough to learn from Googlers like Rob Milks (Data Analytics Specialist) and Carlos Augusto (Customer Engineer).
What are 1-2 of your favorite projects you’ve done with Google Cloud’s data products?
My favorite project to date is the work we have done with Royal Caribbean International (RCI) and Roar Media. Back in 2018, we were able to transition RCI efforts from a fragmented ad tech stack into a consolidated one within the Google Marketing Platform. Moreover, we were able to centralize attribution across all the paid marketing channels. With the vast amount of data we were capturing (17+ markets), it was only logical to leverage Google Cloud solutions in the next step of our journey. We centralized all data sources in the warehouse and deployed business intelligence across business units.
The biggest challenge from the start was designing an architecture that would meet both business and technical requirements. We had to consider the best way to ingest data from several different sources, unify them, have the ability to transform data as needed, visualize it for decision makers, and set the foundations to apply machine learning. Having a deep expertise in marketing/analytics platforms combined with an understanding of data engineering helped me tremendously in leading the process, designing/implementing the ideal architecture, and being able to present end users with information that makes a difference in their daily jobs.
We utilized BigQuery as a centralized data warehouse to integrate all marketing sources (paid, organic, and research) though custom built pipelines. From there we created data driven dashboards within Looker, de-centralizing data and giving end users the ability to explore and answer key questions and make real time data driven business decisions. An evolution of this initiative has been able to go beyond marketing data and apply machine learning. We have created dashboards that look into covid trends, competitive pricing, SEO optimizations, and data feeds for dynamic ads. From the ML aspect, we have created predictive models on the revenue side, mixed marketing modeling, and applied machine learning to translate English language ads to over 17 languages leveraging historical data.
What are your favoriteGoogle Cloud data productswithin the data analytics, databases, and/or AI/ML categories? What use case(s) do you most focus on in your work? What stands out aboutGoogle Cloud’s offerings?
I am a big fan of BigQuery (BQ) and Looker. Traditional data warehouses are no match for the cloud – they’re not built to accommodate the exponential growth of today’s data and the sophisticated analytics required. BQ offers a fast, highly scalable, cost-effective and fully controlled cloud data warehouse for integrated machine learning analytics and the implementation of AI.
Looker on the other hand, is truly next generation BI. We all love Structured Query Language (SQL), but I think many of us have been in position of writing dense queries and forgetting how some aspects of the code work, experiencing the limited collaboration options, knowing that people write queries in different ways, and how difficult it can be to track changes in a query if you changed your mind on a measure. I love how Look ML solves all those challenges, and how it helps one reuse, control and separate SQL into building blocks. Not to mention, how easy it is to give end users with limited technical knowledge the ability to look at data on their terms.
What’s next for you?
I am really excited about everything we are doing at Direcly. We have come a long way, and I’m optimistic that we can go even further. Next for me is just to keep on working with a group of incredibly bright people who are obsessed with using innovative technological solutions to solve business challenges faced by other incredibly bright people.
From this story I would like to tell those that are pursuing a dream, that are looking to provide a better life for themselves and their loved ones, to do it, take risks, never stop learning, and put in the work. Things may or may not go your way, but keep persevering — you’ll be surprised with how it becomes more about the journey than the destination. And whether things don’t go as planned, or you have a lot of success, you will remember everything you’ve been through and how far you’ve come from where you started.
Want to join the Data Engineer Community?
Register for the Data Engineer Spotlight, where attendees have the chance to learn from four technical how-to sessions and hear from Google Cloud Experts on the latest product innovations that can help you manage your growing data.
Is it September yet? Hardly! School is barely out for the summer. But according to Google and Quantum Metric research, the back-to-school and off-to-college shopping season – which in the U.S. is second only to the holidays in terms of purchasing volume1 – has already begun. For retailers, that means planning for this peak season has kicked off as well.
1. Out-of-stock and inflation concerns are changing the way consumers shop. Back-to-school shoppers are starting earlier every year, with 41% beginning even before school is out – even more so when buying for college1. Why? The behavior is driven in large part by consumers’ concerns that they won’t be able to get what they need if they wait too long. 29% of shoppers start looking a full month before they need something1.
Back-to-school purchasing volume is quite high, with the majority spending up to $500 and 21% spending more than $1,0001. In fact, looking at year-over-year data, we see that average cart values have not only doubled since November 2021, but increased since the holidays1. And keep in mind that back-to-school spending is a key indicator leading into the holiday season.
That said, as people are reacting to inflation, they are comparing prices, hunting for bargains, and generally taking more time to plan. This is borne out by the fact that 76% of online shoppers are adding items to their carts and waiting to see if they go on sale before making the purchase1. And, to help stay on budget and reduce shipping costs, 74% plan to make multiple purchases in one checkout1. That carries over to in-store shopping, when consumers are buying more in one visit to reduce trips and save on gas.
2. The omnichannel theme continues. Consumers continue to use multiple channels in their shopping experience. As the pandemic has abated, some 82% expect that their back-to-school buying will be in-store, and 60% plan to purchase online. But in any case, 45% of consumers report that they will use both channels; more than 50% research online first before ever setting foot in a store2. Some use as many as five channels, including video and social media, and these 54% of consumers spend 1.5 times more compared to those who use only two channels4.
And mobile is a big part of the journey. Shoppers are using their phones to make purchases, especially for deadline-driven, last-minute needs, and often check prices on other retailers’ websites while shopping in-store. Anecdotally, mobile is a big part of how we ourselves shop with our children, who like to swipe on the phone through different options for colors and styles. We use our desktops when shopping on our own, especially for items that require research and represent a larger investment – and our study shows that’s quite common.
3. Consumers are making frequent use of wish lists. One trend we have observed is a higher abandonment rate, especially for apparel and general home and school supplies, compared to bigger-ticket items that require more research. But that can be attributed in part to the increasing use of wish lists. Online shoppers are picking a few things that look appealing or items on sale, saving them in wish lists, and then choosing just a few to purchase. Our research shows that 39% of consumers build one or two wish lists per month, while 28% said they build one or two each week, often using their lists to help with budgeting1.
4. Frustration rates have dropped significantly. Abandonment rates aside, shopper annoyance rates are down by 41%, year over year1. This is despite out-of-stock concerns and higher prices. But one key finding showed that both cart abandonment and “rage clicks” are more frequent on desktops, possibly because people investing time on search also have more time to complain to customer service.
And frustration does still exist. Some $300 billion is lost each year in the U.S. from bad search experiences5. Data collected internationally shows that 80% of consumers view a brand differently after experiencing search difficulties, and 97% favor websites where they can quickly find what they are looking for5.
Lessons to Learn
What are the key takeaways for retailers? In general, consider the sources of customer pain points and find ways to erase friction. Improve search and personalization. And focus on improving the customer experience and building loyalty. Specifically:
80% of shoppers want personalization6. Think about how you can drive personalized promotions or experiences that will drive higher engagement with your brand.
46% of consumers want more time to research1. Drive toward providing more robust research and product information points, like comparison charts, images, and specific product details.
43% of consumers want a discount1, but given current economic trends, retailers may not be offering discounts. In order to appease budget-conscious shoppers, retailers can consider other retention strategies such as driving loyalty using points, rewards, or faster-shipping perks.
Be sure to keep returns as simple as possible so consumers feel confident when making a purchase, and reduce possible friction points if a consumer decides to make a return. 43% of shoppers return at least a quarter of the products they buy and do not want to pay for shipping or jump through hoops1.
How We Can Help
Google-sponsored research shows that price, deals, and promotions are important to 68% of back-to-school shoppers.7 In addition, shoppers want certainty that they will get what they want. Google Cloud can make it easier for retailers to enable customers to find the right products with discovery solutions. These solutions provide Google-quality search and recommendations on a retailer’s own digital properties, helping to increase conversions and reduce search abandonment. In addition, Quantum Metric solutions, available on the Google Cloud Marketplace, are built with BigQuery, which helps retailers consolidate and unlock the power of their raw data to identify areas of friction and deliver improved digital shopping experiences.
Data scientists need to have a number of different skills. In addition to understanding the logistics of networking and a detailed knowledge of statistics, they must possess solid programming skills.
When you are developing big data applications, you need to know how to create code effectively. You will need to start by learning the right programming languages. There are a lot of important practices that you need to follow if you want to make sure that your program can properly carry out data analytics or data mining tasks.
Common Programming Mistakes Data Developers Must Avoid
By now, you probably know that coding involves extensive work. It will be even more intensive when you are creating big data applications, because they tend to require a lot more code and greater complexity.
Sadly, complex applications are more likely to have bugs that have to be resolved. You will have to find ways to effectively debug issues when creating software. To make coding more straightforward and effective, you must start by learning the best practices. This entails being aware of some of the biggest mistakes that can cause your code to fail.
This article outlines some common coding errors that programmers creating big data programs need to avoid.
Failing to Back Up Code
One of the most common programming errors is failing to create a backup for your work. Building code is hard work, and you don’t want to risk losing all your information because of a system failure or power outage. Therefore, you will need to spend some time backing up your code as you continue with work.
The purpose of creating backups for your work is that if you lose or damage a file or if problems happen, your backups will survive, and you continue to work uninterrupted. This is more important than ever, since many developers are increasingly dealing with ransomware attacks, so backing up your essential work is critical. Applications that handle data mining and data analytics tasks are even more likely to be targeted by hackers, because they often have access to very valuable data.
One of the most serious errors in programming is using bad names for your variables. The variable name should represent the kind of information contained in the variable. Of course, they are referred to as variables because the data contained within them can change. However, the core operations of the variables remain the same.
Some budding programmers make the mistake of using names that are either too short or cannot communicate their use in the code. When naming them, you may assume that you understand their use. However, if you return to your code after a few months, you may not recall what the variables were for. Using a lousy name also makes sharing your work or collaborating with larger team members cumbersome.
Another mistake that many programmers developing data science applications make is that they don’t provide important information about the function served by the variable. Unfortunately, they may also include this information in a difficult way to read and understand. The best variable names are neither too long nor too short. Anyone going through your code should understand what your variables represent.
The name should designate the data that your variable represents. Also, your code will probably be read more times than written. So instead of taking the most straightforward approach to writing code, you should focus on how easy it will be for other people to read it.
Most experts recommend using simple and concise code names. The name should be written in English but shouldn’t comprise special characters.
Improper Use of Comments
Data science applications are very complex. Therefore, they are more likely to have cumbersome code that can be difficult to follow. Therefore, it is imperative that developers creating big data applications use plenty of comments to understand the code and make sure other programmers can pick up on it as well.
Comments are excellent reminders of the function performed by a piece of code. In programming, a comment implies an annotation or explanation in the source code intended to make the code easier to comprehend. Unfortunately, compilers and interpreters generally ignore comments, but they serve an essential function.
All programs should contain comments that make it easy to describe the purpose of the code. Users need to be able to use a previously created program as easily as possible. However, there are limitations on the number of comments you can have in your code.
Having too many comments means you will have difficulty changing the comments every time you alter the variables. Only use comments in situations where the code is not self-explanatory. If you use the correct naming convention, your work should have very few comments.
Repetitive Code
Another frequent programming error is repetition. One of the core philosophies of effective programming is to not repeat yourself. You may need to revise your work multiple times to ensure that you have not repeated code. As a rule, copy and pasted code are likely repeated. You want to practice using functions and loops as you generate code.
This can be a very costly problem when you are creating a program that has to process lots of data. Your program can crash if there are lots of repetitive issues.
To avoid repetition, do not reuse code by copying and pasting some existing fragments. It is much safer to put the code in a method. This way, you can always call it if it is required the second time.
Being Inconsistent with Code Formatting
When creating new code for a data science application, consistency implies settling for a style and sticking with it throughout. The first level of consistency is the individual degree. This essential consistency means doing what you prefer and staying true to it.
On the other hand, collective consistency means doing your work in a way that can be easily understood by others when working in teams. If other developers are to go through your code, they should be able to understand the work wherever you touch code, respect and remain consistent with the style.
This article summarizes a few mistakes to avoid when programming or coding. For example, stay away from functions that are too big and name your code appropriately. Research more on how to avoid coding errors online.
In order to better serve their customers and users, digital applications and platforms continue to store and use sensitive data such as Personally Identifiable Information (PII), genetic and biometric information, and credit card information. Many organizations that provide data for analytics use cases face evolving regulatory and privacy mandates, ongoing risks from data breaches and data leakage, and a growing need to control data access.
Data access control and masking of sensitive information is even more complex for large enterprises that are building massive data ecosystems. Copies of datasets often are created to manage access to different groups. Sometimes, copies of data are obfuscated while other copies aren’t. This creates an inconsistent approach to protecting data, which can be expensive to manage. To fully address these concerns, sensitive data needs to be protected with the right defense mechanism at the base table itself so that data can be kept secure throughout its entire lifecycle.
Today, we’re excited to introduce two new capabilities in BigQuery that add a second layer of defense on top of access controls to help secure and manage sensitive data.
1. General availability of BigQuery column-level encryption functions
BigQuery column-level encryption SQL functions enable you to encrypt and decrypt data at the column level in BigQuery. These functions unlock use cases where data is natively encrypted in BigQuery and must be decrypted when accessed. It also supports use cases where data is externally encrypted, stored in BigQuery, and must then be decrypted when accessed. SQL functions support industry standard encryption algorithms AES-GCM (non-deterministic) and AES-SIV (deterministic). Functions supporting AES-SIV allow for grouping, aggregation, and joins on encrypted data.
In addition to these SQL functions, we also integrated BigQuery with Cloud Key Management Service (Cloud KMS). This gives you additional control, and allows you to manage your encryption keys in KMS and enables on-access secure key retrieval as well as detailed logging. An additional layer of envelope encryption enables generations of wrapped key sets to decrypt data. Only users with permission to access the Cloud KMS key and the wrapped keyset can unwrap the keyset and decrypt the ciphertext.
“Enabling dynamic field level encryption is paramount for our data fabric platform to manage highly secure, regulated assets with rigorous security policies complying with several regulations including FedRAMP, PCI, GDPR, CCPA and more. BigQuery column-level encryption capability provides us with a secure path for decrypting externally encrypted data in BigQuery unblocking analytical use cases across more than 800+ analysts,” said Kumar Menon, CTO of Equifax.
Users can also leverage available SQL functions to support both non-deterministic encryption and deterministic encryption to enable joins and grouping of encrypted data columns.
The following query sample uses non-deterministic SQL functions to decrypt ciphertext.
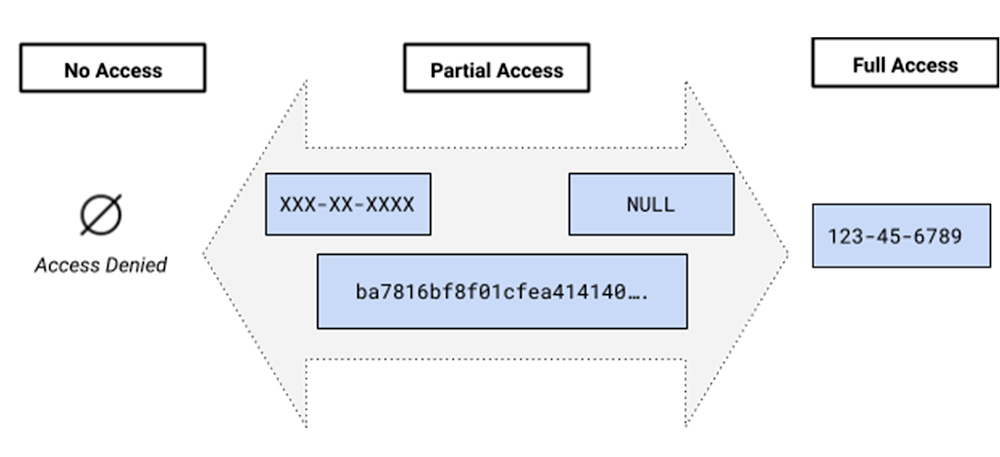
Extending BigQuery’s column-level security, dynamic data masking allows you to obfuscate sensitive data and control user access while mitigating the risk of data leakage. This capability selectively masks column level data at query time based on the defined masking rules, user roles and privileges. Masking eliminates the need to duplicate data and allows you to define different masking rules on a single copy of data to desensitize data, simplify user access to sensitive data, and protect against compliance, privacy regulations, or confidentiality issues.
Dynamic data masking allows for different transformations of underlying sensitive data to obfuscate data at query time. Masking rules can be defined on the policy tag in the taxonomy to grant varying levels of access based on the role and function of the user and the type of sensitive data. Masking adds to the existing access controls to allow customers a wide gamut of options around controlling access. An administrator can grant a user full access, no access or partial access with a particular masked value based on data sharing use case.
For the preview of data masking, three different masking policies are being supported:
ALWAYS_NULL. Nullifies the content regardless of column data types.
Default_VALUE. Returns the default value based on the data type.
A user must first have all of the permissions necessary to run a query job against a BigQuery table to query it. In addition, for users to view the masked data of a column tagged with a policy tag they need to have a MaskedReader role.
When to use dynamic data masking vs encryption functions?
Common scenarios for using data masking or column level encryption are:
protect against unauthorized data leakage
access control management
compliance against data privacy laws for PII, PHI, PCI data
create safe test datasets
Specifically, masking can be used for real-time transactions whereas encryption provides additional security for data at rest or in motion where real-time usability is not required.
Any masking policies or encryption applied on the base tables are carried over to authorized views and materialized views, and masking or encryption is compatible with other security features such as row-level security.
These newly added BQ security features along with automatic DLP can help to scan your data across your entire organization, give you visibility into where sensitive data is stored, and enable you to manage access and usability of data for different use cases across your user base. We’re always working to enhance BigQuery’s (and Google Cloud’s) data governance capabilities, to enable end to end management of your sensitive data. With the new releases, we are adding deeper protections for your data in BigQuery.
Indonesia’s largest hyperlocal company, Gojek has evolved from a motorcycle ride-hailing service into an on-demand mobile platform, providing a range of services that include transportation, logistics, food delivery, and payments. A total of 2 million driver-partners collectively cover an average distance of 16.5 million kilometers each day, making Gojek Indonesia’s de-facto transportation partner.
To continue supporting this growth, Gojek runs hundreds of microservices that communicate across multiple data centers. Applications are based on an event-driven architecture and produce billions of events every day. To empower data-driven decision-making, Gojek uses these events across products and services for analytics, machine learning, and more.
Data warehouse ingestion challenges
To make sense of large amounts of data — and to better understand customers for the purpose of app development, customer support, growth, and marketing purposes — data must first be ingested into a data warehouse. Gojek uses BigQuery as its primary data warehouse. But ingesting events at Gojek’s scale, with rapid changes, poses the following challenges:
With multiple products and microservices offered, Gojek releases new Kafka topics almost every day and they need to be ingested for analytical purposes. This can quickly result in significant operational overhead for the data engineering team that is deploying new jobs to load data into BigQuery and Cloud Storage.
Frequent schema changes in Kafka topics require consumers of those topics to load the new schema to avoid data loss and capture more recent changes.
Data volumes can vary and grow exponentially as people start building new products and logging new activities on top of a new topic. Each topic can also have a different load during peak business hours. Customers need to handle the rising volume of data to quickly scale per their business needs.
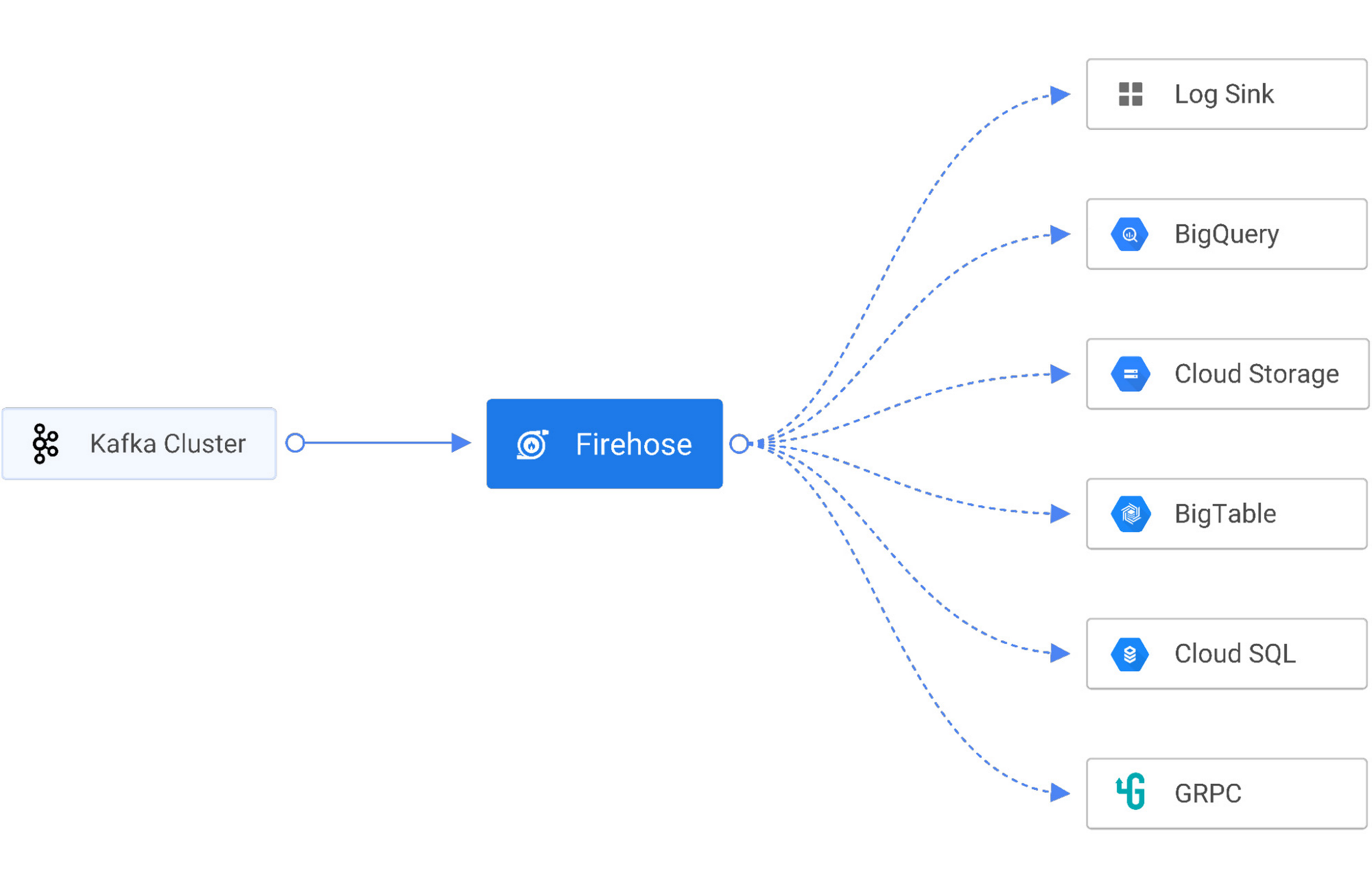
Firehose and Google Cloud to the rescue
To solve these challenges, Gojek uses Firehose, a cloud-native service to deliver real-time streaming data to destinations like service endpoints, managed databases, data lakes, and data warehouses like Cloud Storage and BigQuery. Firehose is part of the Open Data Ops Foundation (ODPF), and is fully open source. Gojek is one of the major contributors to ODPF.
Here are Firehose’s key features:
Sinks – Firehose supports sinking stream data to the log console, HTTP, GRPC, PostgresDB (JDBC), InfluxDB, Elastic Search, Redis, Prometheus, MongoDB, GCS, and BigQuery.
Extensibility – Firehose allows users to add a custom sink with a clearly defined interface, or choose from existing sinks.
Scale – Firehose scales in an instant, both vertically and horizontally, for a high-performance streaming sink with zero data drops.
Runtime – Firehose can run inside containers or VMs in a fully-managed runtime environment like Kubernetes.
Metrics – Firehose always lets you know what’s going on with your deployment, with built-in monitoring of throughput, response times, errors, and more.
Key advantages
Using Firehose for ingesting data in BigQuery and Cloud Storage has multiple advantages.
Reliability Firehose is battle-tested for large-scale data ingestion. At Gojek, Firehose streams 600 Kafka topics in BigQuery and 700 Kafka topics in Cloud Storage. On average, 6 billion events are ingested daily in BigQuery, resulting in more than 10 terabytes of daily data ingestion.
Streaming ingestion A single Kafka topic can produce up to billions of records in a day. Depending on the nature of the business, scalability and data freshness are key to ensuring the usability of that data, regardless of the load. Firehose uses BigQuery streaming ingestion to load data in near-real-time. This allows analysts to query data within five minutes of it being produced.
Schema evolution With multiple products and microservices offered, new Kafka topics are released almost every day, and the schema of Kafka topics constantly evolves as new data is produced. A common challenge is ensuring that as these topics evolve, their schema changes are adjusted in BigQuery tables and Cloud Storage. Firehose tracks schema changes by integrating with Stencil, a cloud-native schema registry, and automatically updates the schema of BigQuery tables without human intervention. This reduces data errors and saves developers hundreds of hours.
Elastic infrastructure Firehose can be deployed on Kubernetes and runs as a stateless service. This allows Firehose to scale horizontally as data volumes vary.
Organizing data in cloud storage Firehose GCS Sink provides capabilities to store data based on specific timestamp information, allowing users to customize how their data is partitioned in Cloud Storage.
Supporting a wide range of open source software
Built for flexibility and reliability, Google Cloud products like BigQuery and Cloud Storage are made to support a multi-cloud architecture. Open source software like Firehose is just one of many examples that can help developers and engineers optimize productivity. Taken together, these tools can deliver a seamless data ingestion process, with less maintenance and better automation.
How you can contribute
Development of Firehose happens in the open on GitHub, and we are grateful to the community for contributing bug fixes and improvements. We would love to hear your feedback via GitHub discussions or Slack.
Enterprise cloud adoption increased dramatically during the COVID-19 pandemic — now, it’s the rule rather than the exception. In fact, 9 in 10 companies currently use the cloud in some capacity, according to a recent report from O’Reilly.
Although digital transformation initiatives were already well underway in many industries, the global health crisis introduced two new factors that forced almost all organisations to move operations online. First, that’s where their customers went. Amid stay-at-home mandates and store closings, customers had to rely almost solely on digital services to shop, receive support, partake in personalised experiences, and otherwise interact with companies.
Second, the near-universal shift to remote work made the continued use of on-premises hardware and computing resources highly impractical. To ensure newly distributed teams could work together effectively, migrating to the cloud was the only option for many companies. And although current adoption statistics are a testament to the private sector’s success in this endeavour, most companies encountered some obstacles on their journey to the cloud.
Barriers to success in cloud adoption
There are several different types of cloud platforms and a variety of cloud service models. To keep things simple, I tend to think of cloud resources in terms of two components: back end and front end. The former is the infrastructure layer. Outside of the physical servers and data centres that every cloud provider is comprised of, the infrastructure layer encompasses everything related to information architecture, including data access and security, data storage systems, computational resources, availability, and service-level agreements. The front end is the presentation layer or application interface, including the end-user profile, authentication, authorisation, use cases, user experiences, developer experiences, workflows, and so on.
Not long ago, companies would typically migrate to the cloud in long, drawn-out stages, taking plenty of time to design and implement the back end and then doing the same with the front end. In my experience working with enterprise customers, the pandemic changed that. What used to be a gradual process is now a rapid undertaking with aggressive timelines, and front-end and back-end systems are frequently implemented in tandem where end users are brought in earlier to participate in more frequent iterations.
Moreover, the pandemic introduced new cost considerations associated with building, maintaining, and operating these front-end and back-end systems. Organisations are searching for more cost savings wherever possible, and though a cloud migration can result in a lower total cost of ownership over the long run, it does require an upfront investment. For those facing potential labour and capital constraints, cost can be an important factor to consider.
Aggressive timelines and cost considerations aren’t roadblocks themselves, but they can certainly create challenges during cloud deployments. What are some other obstacles to a successful cloud integration?
Attempting to ‘lift and shift’ architecture
When trying to meet cloud migration deadlines, organisations often are prone to provision their cloud resources as exact replicas of their on-premises setups without considering native cloud services that can offset a lot of the maintenance or performance overhead. Without considering how to use available cloud-native services and reworking different components of their workflows, companies end up bringing along all of their inefficiencies to the cloud. Instead, organisations should view cloud migration as an opportunity to consider a better architecture that might save on costs, improve performance, and result in a better experience for end users.
Focusing on infrastructure rather than user needs
When data leaders move to the cloud, it’s easy to get caught up in the features and capabilities of various cloud services without thinking about the day-to-day workflow of data scientists and data engineers. Rather than optimising for developer productivity and quick iterations, leaders commonly focus on developing a robust and scalable back-end system. Additionally, data professionals want to get the cloud architecture perfect before bringing users into the cloud environment. But the longer the cloud environment goes untested by end users, the less useful it will be for them. The recommendation is to bring a minimal amount of data, development environments, and automation tools to the initial cloud environment, then introduce users and iterate based on their needs.
Failing to make production data accessible in the cloud
Data professionals often enable many different cloud-native services to help users perform distributed computations, build and store container images, create data pipelines, and more. However, until some or all of an organisation’s production data is available in the cloud environment, it’s not immediately useful. Company leaders should work with their data engineering and data science teams to figure out which data subsets would be useful for them to have access to in the cloud, migrate that data, and let them get hands-on with the cloud services. Otherwise, leaders might find that almost all production workloads are staying on-premises due to data gravity.
A smoother cloud transition
Although obstacles abound, there are plenty of steps that data leaders can take to ensure their cloud deployment is as smooth as possible. Furthermore, taking these steps will help maximise the long-term return on investment of cloud adoption:
1. Centralise new data and computational resources.
Many organisations make too many or too few computational and data analytics resources available — and solutions end up being decentralised and poorly documented. As a result, adoption across the enterprise is slow, users do most of their work in silos or on laptops, and onboarding new data engineers and data scientists is a messy process. Leaders can avoid this scenario by focusing on the core data sets and computational needs for the most common use cases and workflows and centralise the solutions for these. Centralising resources won’t solve every problem, but it will allow companies to focus on the biggest challenges and bottlenecks and help most people move forward.
2. Involve users early.
Oftentimes, months or even years of infrastructure management and deployment work happens before users are told that the cloud environment is ready for use. Unfortunately, that generally leads to cloud environments that simply aren’t that useful. To overcome this waste of resources, data leaders should design for the end-user experience, workflow, and use cases; onboard end users as soon as possible in the process; and then iterate with them to solve the biggest challenges in priority order. They should avoid delaying production usage in the name of designing the perfect architecture or the ideal workflow. Instead, leaders can involve key stakeholders and representative users as early as possible to get real-world feedback on where improvements should be made.
3. Focus on workflows first.
Rather than aiming for a completely robust, scalable, and redundant system on the first iteration, companies should determine the core data sets (or subsets) and the smallest viable set of tools that will allow data engineers and data scientists to perform, say, 80% of their work. They can then gradually gather feedback and identify the next set of solutions, shortening feedback loops as efficiently as possible with each iteration. If a company deals with production data sets and workloads, then it shouldn’t take any shortcuts when it comes to acceptable and standard levels of security, performance, scalability, or other capabilities. Data leaders can purchase an off-the-shelf solution or partner with someone to provide one in order to avoid gaps in capability.
No going back
Cloud technology used to be a differentiator — but now, it’s a staple. The only way for companies to gain a competitive edge is by equipping their data teams with the tools they need to do their best work. Even the most expensive, secure, and scalable solution out there won’t get used unless it actually empowers end users.
Kristopher Overholt works with scalable data science workflows and enterprise architecture as a senior sales engineer at Coiled, whose mission is to provide accessibility to scalable computing for everyone.
Artificial intelligence is driving a lot of changes in modern business. Companies are using AI to better understand their customers, recognize ways to manage finances more efficiently and tackle other issues. Since AI has proven to be so valuable, an estimated 37% of companies report using it. The actual number could be higher, since some companies don’t realize the different forms of AI they might be using.
AI technology has been helpful for businesses in different industries for years. It is becoming even more valuable for companies as ongoing economic issues create new challenges.
The benefits of AI stem from the need to manage close relationships with business stakeholders, which is a difficult task. Businesses do not exist on islands. All companies require complex relationships with various suppliers and service providers to develop the products and services they offer to clients and customers — but those relationships always carry some risk. Since the War in Ukraine, Covid-19 crisis and other problems have worsened these risks, AI is becoming more important for companies that want to mitigate them.
Here are some of the risks that organizations face in dealing with suppliers, and what they can do to mitigate those risks with artificial intelligence.
Failure or Delay Risk
Failure to deliver goods is one of the most common risks businesses have suffered over the past two years. This risk is best defined as a complete supply or service failure, which can be permanent or temporary.
There can be many localized or widespread reasons for a supplier to fail to provide goods or services. For example, poor management might cause their business to collapse, eliminating their products from the supply chain. The availability of materials can cause failures, as suppliers cannot manufacture products when they lack the resources to do so. Finally, unexpected or unavoidable events, like the blockage of a major trade route or unprecedented and severe storms, can cause catastrophic delays that shut down manufacturing or prevent trade from coming or going to a region.
This is one area that can be partially resolved with AI. You can use predictive analytics tools to anticipate different events that could occur. Cloud-based applications can also help.
Google Cloud author Matt A.V. Chaban addressed this in a recent article. Hans Thalbauer, Google Cloud’s managing director for supply chain and logistics stated that companies are using end-to-end data to better manage risks at different junctions in the supply chain to avoid breakdowns.
Brand Reputation Risk
Suppliers have to be true to their mission and think about their reputation. Fortunately, AI technology can make this easier.
There are a few ways that a company’s brand can be negatively impacted by a member of its supply chain. If a supplier maintains poor practices that result in frequent product recalls, the business selling those products might be viewed by consumers as equally negligent and untrustworthy. Likewise, if a supplier publishes messaging that contradicts a brand’s marketing messages, consumers might become confused or disheartened by the inconsistency of the partnership. Because the internet reveals more about supplier relationships and social media provides consumers with louder voices, businesses need to be especially careful about the brand reputation risks they face in their supply chains.
How can AI help with brand reputation management? You can leverage machine learning to drive automation and data mining tools to continue researching members of your supply chain and statements your own customers are making. This will help you identify issues that have to be rectified.
Competitive Advantage Risk
Businesses that rely on the uniqueness of their intellectual property face risks in working with suppliers, who might sell that IP, counterfeit goods or otherwise dilute the market with similar products.
Saturated markets require companies to develop some kind of unique selling proposition to provide them with a competitive advantage. Unfortunately, the power of that competitive advantage can wane if a business opts to work with an untrustworthy supplier. In other countries, rules about intellectual property are less rigid, and suppliers might be interested in generating additional revenue by working with a business’s competitors, offering information about secret or special IP. Though the supply chain itself might be unharmed by this risk, this supplier behavior could undermine a business’s strategy and cause it to fail.
AI technology can help suppliers improve their competitive risk in numerous ways. They can save money through automation, identify more cost-effective ways to transport goods and improve value in other ways with artificial intelligence.
Price and Cost Risk
This risk involves unexpectedly high prices for suppliers or services. In some cases, business leaders do not adequately budget for the goods and services they expect from their suppliers; in other cases, suppliers take advantage of a lack of contract or “non-firm” prices to raise their costs and earn more income from business clients. This is one of the easiest risks to avoid, as business leaders can and should perform due diligence to understand reasonable rates amongst suppliers in their market.
AI technology can also help in this regard. Machine learning tools have made it a lot easier to conduct cost-benefit analyses to recognize opportunities and risks.
Quality Risk
Cutting corners can cut costs but doing so can also result in poor product or service quality that is unattractive to consumers. Businesses need to find a balance between affordability and quality when considering which suppliers to partner with.
Some suppliers maintain a consistent level of high or low quality, but with other suppliers, quality can rise and fall over time. Some factors that can influence quality include material and labor cost in the supplier’s region, shipping times and costs and the complexity of the product or service required. Business leaders who recognize a dip in quality might try to address the issue with their current supplier before looking for a new supplier relationship.
Fortunately, AI can help identify any of these issues.
The Best Risk Mitigation Strategy Requires AI Technology
AI technology has made it a lot easier for suppliers to manage their risks. Undoubtedly, the best way to mitigate the risks associated with suppliers is with a robust supplier risk management system. The right AI tools and procedures help business leaders perform more diligent research and assess supplier options more accurately to develop a supply chain that is less likely to suffer from delays, failures, low quality, undue costs and other threats. Risk management software developed for the supply chain help business leaders build and maintain strong relationships with top-tier suppliers, which should result in a stable and lucrative supply chain into the future.






{kind=link}
{kind=link}