It’s no secret that many organizations and job seekers find the hiring process exhausting. It can be time consuming, costly, and somewhat risky for both parties. Those are just some of the experiences we wanted to change when we started Gyfted, a pre-vetted talent marketplace for people who complete tech training or degree programs and are looking for the right career move. At the same time, we’re helping businesses save time and improve recruiting outcomes with our automated candidate screening and sourcing tools.
Our vision is clear: To take a candidate through one structured hiring process, and then put them in front of thousands of companies. It’s similar to the common app system in higher education. Sounds simple, but it is a herculean technical and UX task. To succeed we had to combine advanced psychometric testing, machine learning, the latest in behavioral design, and develop the highest quality structured, relational dataset to represent candidate and manager profiles and preferences on our network. Fortunately, we were cofounded by world-leading experts in these areas including Dr. Michal Kosinski, one of the world’s top computational psychologists, and Adam Szefer, a gifted young technologist. We’ve been joined by a group of equally talented employees, most of whom work remotely in Poland, US, Switzerland, UK, Israel, and Ukraine.
The influence of dating platforms and matching
When seeking inspiration, we were influenced by the success of dating platforms, especially Bumble with its focus on commitment. These platforms have done a great job using design to match people together.
We like to think we’re doing the same for recruiters and candidates in terms of not only role and culture fit matching, but also through a fundamental feature of Gyfted, which is that our job-seekers are anonymous. This helps recruiters meet one of their goals today, which is to minimize bias in the hiring process and enable objective, diversity-oriented recruiting.
Another of our unique selling points is that we conduct candidate screening that is gamified and automated, with a structured interview, where the interview remains with the candidate’s profile. We roughly estimate that just for the 15 million open jobs on LinkedIn, if companies fill in 50% of those via external recruiting, and conduct a screening interview with 10 candidates per job filled at $50/hour paid to an employee to do the screening, that’s $3.75 billion and 75 million hours in direct costs. This is on top of applying for jobs, selecting CVs, and coordinating the process, which takes an even bigger financial and time toll on both applicants and recruiters. Instead, it would be better to take one interview for 1000 companies. The impact of what we want to achieve with our vision is enormous.
We also offer career discovery and career search tools for job candidates. This includes free, personalized feedback for every job-seeker. Right now, we’re aiming the service at students, bootcamp graduates and juniors, helping them to land jobs in tech and the creative industry at large. Next, we’ll expand into mid and senior roles. In the long run we want to reshape how recruiting happens through a common app that saves everyone in the market significant time and resources, helping people find jobs not only faster, but jobs that truly fit them.
Developing advanced AI applications with Google Cloud
We obtained our original funding from angel and institutional investors, and we were selected into the Fall 2021 batch of StartX, the non-profit start-up accelerator and founder community associated with Stanford University. But like most startups our budgets are tight, and we need to find ways to operate as efficiently as possible, especially when building out our technology stack and developer environment.
That’s where Google Cloud comes in. It’s a lot more affordable and flexible than competing solutions, and our developers love it. We use Google App Engine for the hosting and development of our applications giving us enormous flexibility. Vertex AI enables us to build, deploy, and scale machine learning models faster, within a unified artificial intelligence platform. On top of that we use Google Vertex AI Workbench as the development environment for the data science workflow, which allows us to have everything that we need to host and develop innovative AI-based applications.
BigQuery, Google Cloud’s serverless data warehouse, is another stand-out solution for us. We use it to crunch big data from all our systems and the UX is very intuitive and easy to use, allowing us to use it across the business and get insights from a wide range of employees, not just technical experts.
Above all, Google Cloud helps us solve the main platform challenges facing Gyfted including scalability and identity management, so we are perfectly positioned for growth. Right now, we handle about 2 million candidate interactions, a volume we expect to grow exponentially. As that number grows, we rely on Google Cloud to help us scale securely and with reliability.
Eliminating bias from the hiring process
Our technology partners have also been integral to helping us get to an advanced stage of our beta program. MongoDB on Google Cloud takes the data burden off our teams and reduces time to value of our applications. We can stay nimble and can scale database capacity at the push of a button.
Our collaboration with the Google team has been fantastic. Our Startup Success Manager is an expert when it comes to Google Cloud solutions, and he also understands our business from his own experience as an entrepreneur and an investor. It’s great to have an internal point of contact who can help us navigate all of Google’s resources.
I’d also stress the extent to which Google Cloud values align with ours. For example, a key benefit for our customers is the ability to strip unconscious bias out of the hiring process. Google Cloud tools support this commitment to diversity, especially when we are building out our AI models.
On a team level, we also appreciate the support that Google Cloud has shown through its Google Support Fund for Start-ups in Ukraine. This has helped many Ukrainian businesses to continue to operate at a very challenging time, including startups with remote, distributed teams in Poland where most of us stem from.
If I had to sum up Google Cloud and our collaboration with Google for Startups in a phrase, I’d say that it adds enormous value to our business while removing much of the risk when scaling up a start-up. We’ve seen the addition of many new tools and features in the past two years and our Google mentors are always looking at the best way these can be integrated with Gyfted’s own roadmap. That means that we can continue to transform recruiting and hiring processes with the support of one of the world’s most advanced tech companies as a strategic growth partner.
Gyfted Team Members
If you want to learn more about how Google Cloud can help your startup, visit our pagehere to get more information about our program, andsign up for our communications to get a look at our community activities, digital events, special offers, and more.
The magnitude and direction of wind significantly impacts airport operations, and Lufthansa Group Airlines are no exception. A particularly troublesome kind is called BISE: it is a cold, dry wind that blows from the northeast to southwest in Switzerland, through the Swiss Plateau. Its effects on flight schedules can be severe, such as forcing planes to change runways, which can create a chain reaction of flight delays and possible cancellations. In Zurich Airport, in particular, BISE can potentially reduce capacity by up to 30%, leading to further flight delays and cancellations, and to millions in lost revenue for Lufthansa (as well as dissatisfaction among their passengers).
Being able to predict this kind of wind well in advance lets the Network Operations Control team schedule flight operations optimally across runways and timeslots, to minimize disruptions to the schedule. However, predicting speed and magnitude can be incredibly difficult to model and thus to predict— which is why Lufthansa reached out to Google Cloud.
Machine learning (ML) can help airports and airlines to better anticipate and manage these types of disruptive weather events. In this blog post, we’ll explore an experiment Lufthansa did together with Google Cloud and its Vertex AI Forecast service, accurately predicting BISE hours in advance, with more than 40% relative improvement in accuracy over internal heuristics, all within days instead of the months it often takes to do ML projects of this magnitude and performance.
“Being impressed with Google’s technology and prowess in the field of AI and machine learning, we were certain that my working together with their expert, to combine our technology with their domain expertise, we would achieve the best results possible,“ said Christian Most, Senior Director, Digital Operations Optimization at Lufthansa Group.
Collecting and preparing the dataset
The goal of Lufthansa and Google Cloud’s project was to forecast the BISE wind for Zurich’s Kloten Airport using deep learning-based ML approaches, then to see if the prediction surpasses internal heuristics-driven solutions and gauge the ease of use and practicality of the deep learning approach in production.
Since deep learning-based techniques require large datasets, the project relies on Meteoswiss simulation data, a dataset consisting of multiple meteorological sensor measurements collected from several weather stations across Switzerland over the past five years. By using this dataset, we obtained data on factors like wind direction, speed, pressure, temperature, humidity and more, at a 10 min resolution, along with some information about the location of the weather stations, such as altitude. These factors, which we hypothesized to be predictive of the BISE, ended up carrying valuable signals, as we would see later.
This collected data was next subjected to an extensive cleaning and feature engineering process using Vertex AI Workbench, in order to prepare the final dataset for training. The cleaning phase included steps to drop the features, or rows, that contained too many missing values, or failed statistical tests for entropy, etc. Since the direction of wind is a circular feature (between 0 and 360 degrees), this column/feature was replaced with two features: the corresponding sine and cosine embedding. The dataset was then flattened such that the columns contained all the relevant features and sensor measurements from all the weather stations at a particular 10-minute interval.
Since the target variable — i.e,. BISE — was not directly available, we engineered a proxy target variable for BISE called “tailwind speed around runway,” which above a certain threshold indicates the presence of BISE along the runway.
Forecasting wind in the Cloud
Once the dataset was ready, Lufthansa and Google Cloud evaluated several options before deciding to experiment and tune Vertex AI Forecast, Google’s AutoML-powered forecasting service, in order to achieve optimum results. Vertex Forecast is capable of the required feature engineering, neural architecture search, and hyper parameter tuning, and it is managed by Google Cloud to score in the top 2.5% in the M5 Forecasting Competition on Kaggle, in a completely automated fashion. These qualities made it an excellent choice for Lufthansa, to reduce the manual overhead of creating, deploying, and maintaining top performing deep learning models.
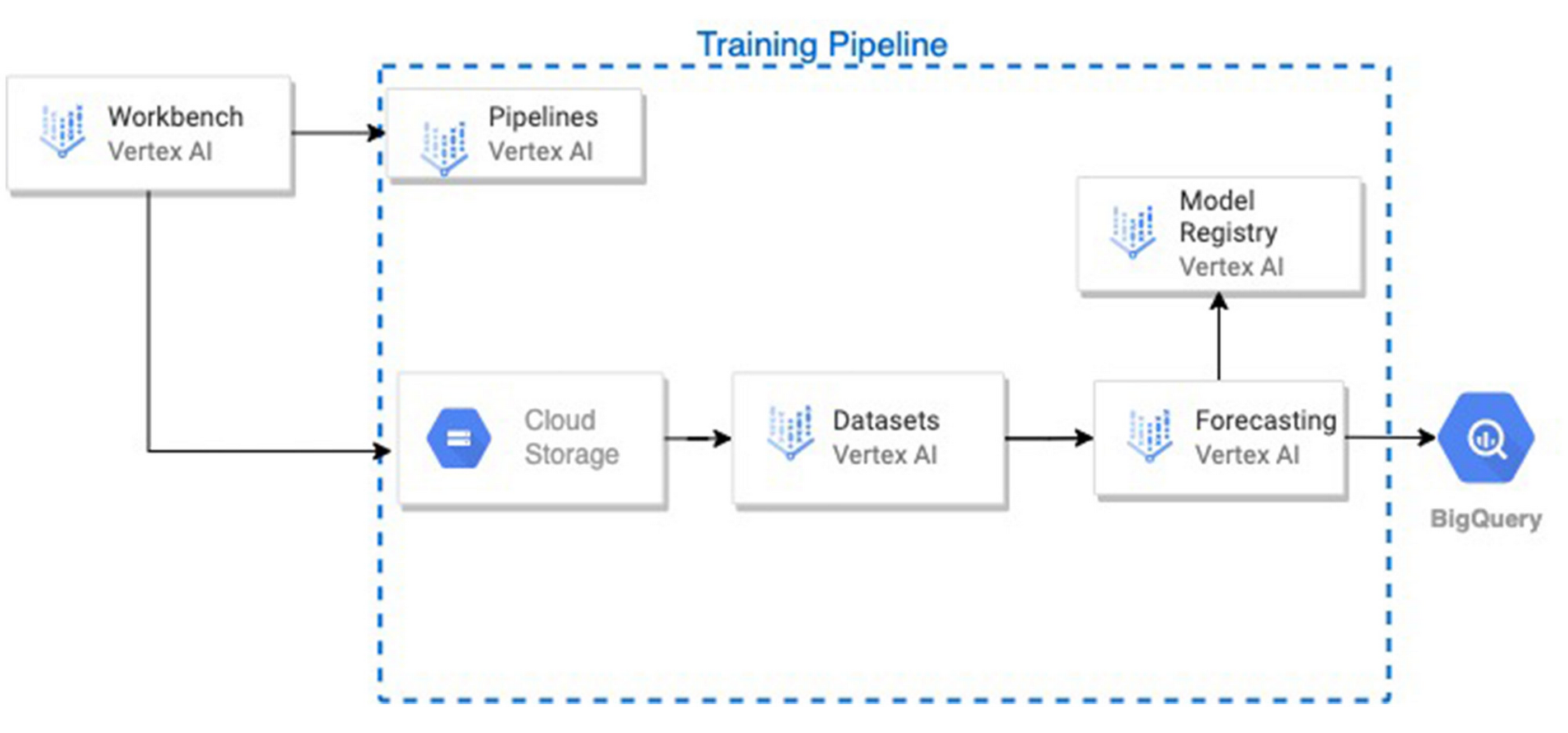
The raw data files were loaded from cloud storage, preprocessed on Vertex AI Workbench. Then, a training pipeline was initiated on Vertex AI Pipelines, which performed the following steps in sequence:
A Vertex AI forecasting training job was initiated with the dataset, and it was also registered as a model in the Vertex AI Model Registry.
Upon completion, the model was evaluated on the test set, and the model’s predictions and the input features and ground truth of the test set, were stored in a user-defined table in BigQuery. Several test metrics were also available on the service and model dashboards.
One of the biggest challenges was the severe imbalance in the dataset, as measurements with BISE were very far and few in between. In order to account for this, instances where BISE occurred, as well the occurrences temporally close to them, were upweighted using weights calculated with methods including Inverse of Square Root of Number of Samples (ISNS), Effective Number of Samples (ENS), and Gaussian reweighting. The formulas for the methods are given below. These weights were supplied as separate columns in the dataset, and were iteratively used thereafter by the service as the “weight” column.
ISNS
ENS
Weighted gaussian
Results and next steps
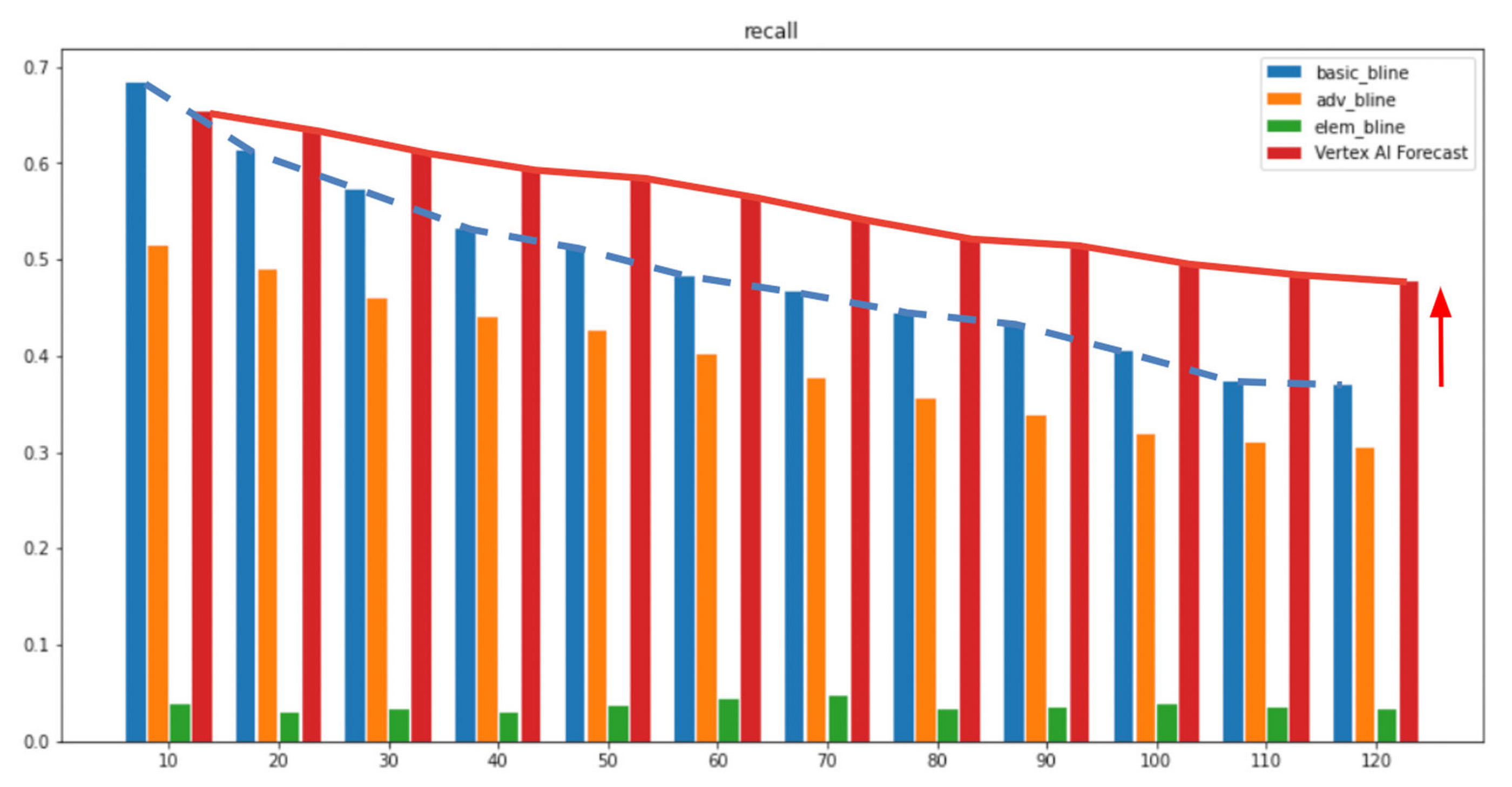
Fig 1. Recall for 2-hour horizon
Fig 2. F1 Score for a 2-hour Horizon
In the above figures, the x-axis represents the forecast horizon and the Y-axis shows the respective metrics (Recall/F1-score). As shown after multiple experiments, we can see Vertex AI Forecast achieved higher recall and precision t (red bar), outperforming Lufthansa’s internal baseline heuristics, with the performance gap widening steadily as the forecast horizon extends further into the future. At the two-hour mark, our custom-configured Vertex AI Forecast model improved by 40% relative to the internal heuristics and 1700% compared to the random guess baseline. As we saw with other experiments, at a six-hour forecast horizon, the performance gap widens even more, with Vertex AI Forecast in the lead. Since forecasting BISE a few hours in advance is very beneficial to prevent flight delays for Lufthansa, this was a great solution for them.
“We are very excited to be able to not only do accurate long term forecasts for the BISE, but also that Vertex AI Forecasting makes training and deploying such models much easier and faster, allowing us to innovate rapidly to serve our customers and stakeholders in the best possible manner,” said Swiss Oliver Rueegg, Product Owner, Swiss International Airlines.
Lufthansa plans to explore productionizing this solution by integrating it into their Operations Decision Support Suite, which is used by the network controllers in the Operations Control Center in Kloten, as well as to work closely with Google’s specialists to integrate both Vertex AI Forecast and other of Google’s AI/ML offerings for their use cases.
There are a growing number of risks with big data. Some of them stem from security issues if data is compromised. There are also physical safety issues associated with using the hardware that big data depends on.
You must understand how to protect yourself even as you collect as much data as possible. Businesses need to collect information on just about everything to remain competitive in the current environment; however, how you use that data truly makes a difference. Hackers try to circumvent your security measures just as you work hard to protect the data you collect. What do you need to know about protecting yourself in the era of big data, and what should you do if you feel like something has been compromised?
Focus on Strong Password Hygiene
Without a doubt, you need to focus on solid password hygiene. Your password must be secure since it is your first layer of defense, and you must ensure it is as strong as possible. A strong password has a nice mixture of numbers, letters, and symbols. You also need to change your password regularly. That way, if someone has stolen your password without you knowing it, they do not get access to your information forever. You should also encourage your employees to change their passwords from time to time. Do not hesitate to use two-factor authentication to protect your information.
Use the Right Equipment
You also need to make sure you use the right equipment. Even though you are probably thinking about collecting this information annually, there are automation tools that can make the process easier. That way, you don’t have to spend as much time typing. If you spend a lot of time typing on the computer, you may want to invest in a wrist brace that can protect against the development of carpal tunnel syndrome. If you feel forced to type to the point of developing this condition, you must reach out to a doctor. Carpal tunnel syndrome is one of the leading causes of injuries in the tech environment.
Software Updates Should Not Be Neglected
Even though it can be annoying to have to deal with software updates from time to time, there is a reason why they have been released. There is a chance that there could be an essential security patch that covers up a vulnerability. You need to make sure you install software updates as quickly as possible. Otherwise, you could be vulnerable to an attack. You may want to set your computers to update in the middle of the night automatically. That way, you don’t have to worry about disrupting your daily operations to install a software update.
Think About the Dangers of Shadow IT
Shadow IT is one of the most significant risks in the current business environment. There are a lot of people who spend time working from home. Even though this flexibility might be nice, it can also leave your company vulnerable. Home internet connections do not necessarily have the same level of security as your company’s network. If you allow people to use their personal devices, you must make sure you have the right security protocols installed. For example, you should encourage them to use a VPN. A VPN can make it much more difficult for someone to hack the device and steal information. You might also want to install your security protocols on their devices. This will make it easier for you to protect your confidential information while still allowing your employees to work from home.
Ensure You Protect Yourself Accordingly With These Tips
In the era of big data, cybersecurity has never been more important than it is. You must protect yourself by following these tips, and do not hesitate to reach out to an expert who can help you. As the cybersecurity landscape changes, you must stay one step ahead of hackers and cybercriminals. By investing in the correct security protocols, using the right equipment, and training your employees appropriately, you can reduce your chances of dealing with a security breach down the road. Don’t forget to protect yourself against physical injuries as well.
There are countless benefits of investing in AI as a manufacturer. However, this is also going to lead to some major changes that might be a bane for many workers.
The good news is that there are still ways for workers to thrive in this field. However, they need to know what skills they need to possess as AI technology dominates the industry.
What Skills Will Manufacturers Need as AI Becomes More Prominent
Manufacturing is far from dead. All of the speculation that AI would kill the industry has proven to be untrue. In fact, there are the same number of Americans working in manufacturing in 2019 as there were in the industrial heyday of the late ’40s.
However, the industry is changing faster now than in perhaps any time period since the Industrial Revolution. As manufacturing becomes increasingly affected by advances in AI and other forms of high technology, it’s clear that tomorrow’s manufacturing worker will need to come ready to work with a new toolbox.
When we picture the ideal manufacturing worker of 2030 and beyond, what skills will they need as the industry is shaped by AI? How should our educational institutions prepare tomorrow’s manufacturing labor force to become empowered and productive employees? There’s no telling what the future holds—but these six skill sets will be invaluable no matter what comes down the pipeline.
1. Critical Thinking
With so many jobs headed for automation as manufacturers invest more in AI, it’s important to focus on acquiring skills that are difficult to automate. Near the top of that list is the ability to use critical thinking to grasp and solve complex problems. AI technology can accomplish many things, but it still can’t think like a real human. That includes skills like seeing the big picture in data, evaluating the pros and cons of an option and identifying and mitigating one’s own weaknesses through collaboration.
The skilled jobs of the new economy require critical thinking on an almost constant basis. It’s such a foundational skill that once a person grasps the basic concepts of critical thinking (such as evaluating an argument, making a judgment based on known facts and coordinating multiple systems to solve a problem), they understand the basis of almost any 21st century business practice. Moreover, it’s an important skill that helps guide an individual’s choices in their career.
2. Essential Computer Skills
The ability to organize an email inbox or make a basic Excel sheet will be expected of nearly every worker in the new economy, and not just in white-collar office jobs. Computers are now among the most essential tools of doing any kind of business, so basic computer skills will be expected just to get in the door, even if the factory floor is where you’re interested in going.
With manufacturing workplaces increasingly relying on apps, ERP systems and other AI applications to streamline their operations, manufacturing positions will no longer be immune from the requirement of computer skills. The 21st century manufacturing job will be less like the ultra-repetitive assembly line work of the 20th century and more focused on continually learning to use new tools to take command of one’s own productivity. In that environment, tools like Dropbox, Outlook and Excel could be the new hammer, wrenches and screwdrivers.
3. Programming and Automation
The new manufacturing jobs created in the 21st century are often the ones that involve programming or manipulating automated systems, and that means that the new manufacturing worker is something closer to a manager who supervises processes rather than individuals. To compete, the 21st century worker needs to be able to create and manage shop floor-level implementations of automation and AI.
Different kinds of programming and technology skills are needed for different fields. Machinists, for example, must be highly skilled at using technologies such as custom CNC machining that rely on automation. Supervisors on automated vehicle manufacturing lines, meanwhile, must sometimes learn hardware skills up to and including opening an electronics enclosure to fix a programmable logic controller. It’s clear that learning a wide range of skills related to automation and AI will serve workers well in the increasingly automated manufacturing environment.
4. Technological Adaptability
Technology and automation have already drastically changed just about every corner of the manufacturing sector, and none will be able to escape forever. That means that a well-rounded 21st century manufacturing employee will be able to roll with the punches and embrace new technologies–even as those technologies create big disruptions. This includes using AI to use augmented reality in manufacturing.
For example, additive manufacturing and 3D printing have recently taken the manufacturing world by storm. Other technologies, such as blockchain, could well revolutionize the supply chains and the record-keeping systems that keep manufacturing operations running. Workers who are able to quickly master and implement these technologies have a distinct advantage over those who are slower to embrace them.
5. Empathy and Communication Skills
Skills in interpersonal communication and understanding are commonly called “soft skills,” but that phrase doesn’t accurately communicate just how important these skills are. People skills enable employees to work together, overcome differences and create strong working relationships. And despite the increased power and productivity that new technologies offer, smooth collaboration is still the secret that creates great businesses where people want to work.
Empathy is the key to developing workplace communication skills, and it’s particularly important for management. The ability to put yourself in another person’s shoes means understanding their responsibilities, how they interlock with your own and how you can work together more effectively—whether you get along personally or not. Thus, by combining empathy with critical thinking, employees at all levels can better understand the roles that they and their co-workers play and work harder to ensure that all the pieces fit together smoothly.
6. Leadership and Decision Making
In today’s manufacturing environment, the average worker has more powerful tools to work with than ever. That means that leadership must come from all levels, not just management. Every worker must be more responsible, exercise better judgment and be more able to stand as a leader to their coworkers. The seamless collaboration required to be a competitive 21st century manufacturer means that there’s very little room for “not my job,” and responsible use of powerful new tools makes accountability and transparency at every level mission critical.
Twenty years from now, it’s a safe bet that manufacturing will look very little like it does today. That means recognizing that human capital is still the most valuable kind and that investing in the skills and development of employees will help create the long-term stability that every business wants in a changing economy.
AI Technology is Changing the State of the Manufacturing Sector and Workers Must Adapt
AI technology offers many promising benefits for the manufacturing sector. Manufacturers invest in solutions like robotic polishing to make the most of AI. Workers will need to adapt as AI becomes more of a gamechanger in the years to come.
Bloomberg published a press release in June showing that this is the best time ever to create an AI startup. The market for AI is growing over 39% a year through 2028. AI companies stand to benefit from this booming industry.
However, it is imperative to do your due diligence. The stakes are higher as the market grows and it is important to have a solid product.
Are you developing new AI technology to better meet the needs of your customers? You are going to want to create the highest quality AI software application possible.
Customers have higher standards than ever when it comes to AI software. They expect applications to use the most sophisticated machine learning algorithms to better serve their users. They want to work with companies that can use AI to solve real challenges, rather than merely offer interesting features.
Hiring a software development company to create AI software is not an easy task. There are many companies that claim to be the best in the business, but very few can actually deliver on their promises.
This article will cover some important factors you need to consider when hiring a software development company for your AI startup.
Determine a Budget
AI applications usually cost more to develop than you expect. You need to make sure your startup has sufficient funds to cover the costs.
The first step of the process is to determine your budget. This can be difficult because so many factors go into setting a price, but it’s important to know what you have available and make sure you have enough money in the bank for this project before moving forward.
Some things that will affect your budget:
Scope of work – The more features and functionality you want for your AI application, the higher your costs will be. Additionally, those costs might increase even more dramatically if it’s an urgent project with little time for research or planning upfront.Timeline – If you need something done quickly, expect to pay more than if it were done within two months. Save yourself some money by keeping communication open between parties throughout the development process.
Identify Your Goals
Defining the goals of your AI software is essential to hiring a reliable development company. You need to know how much you can afford, how long you’re willing to wait for a solution, and what kind of software you want.
Armed with this information, you’ll be able to identify potential software development companies that fit your needs and budget.
What type of development are you looking for?
Now that you know what to look for in a developer, it’s time to decide what type of software development you need. Here are some examples:
Web Development – web developers create websites and applications that are accessed onlineMobile Development – mobile developers create apps and games that run on smartphones and tabletsGame Development – game designers design computer games, video games, or any other interactive game played on a screenApplication Development – application developers develop custom software applications for businesses or individuals.
Assess The Company’s Experience and Portfolio
If you’re hiring a software development company, it’s important to know what they have done in the past. The best way to do this is by looking at their portfolio. Look through the client list of potential companies and see if there are any that you recognize.
If so, ask yourself if those companies are similar to yours in size or industry. If so, it may be an indication that this particular software development firm has experience working with businesses like yours.
A second consideration is how long a company has been in business and what kind of reputation it has within its community. Reputation is important because it shows that other people trust them with their money and time—and now your company wants them handling theirs too.
Hiring the Best Software Company is Essential for AI Startups
Are you planning on creating an AI software application? You don’t want to go through the process blind. You want to work with the best software developers to guide you through the process. The best thing to remember when looking for a software development company is that you should be as specific as possible. This will help you narrow down your search, so you can find the perfect company for your needs.
You don’t have to work in the women’s clothing business to know that one size doesn’t fit all. Adore Me pioneered the try-at-home shopping service, helping to ensure that every woman can feel good in what she wears. I’ve been lucky enough to have played a part in our growth and success over the years. Now, data is transforming every aspect of how we work, shop, and do business, making these last few years especially exciting. But I’m often asked about how we utilize data here at Adore Me, so I thought I’d share some of the obstacles we’ve encountered, how we resolved them, and offer up a few pointers that I hope others will find helpful.
Freeing up teams from getting to the data, to use the data more effectively
It’s no secret: The less time we spend getting to the data, the more time we have to actually use it to support our business. Getting an online shopping service off the ground brings complexity into every part of our business. We quickly discovered that providing everyone in-house with the ability to make smart, data-driven decisions resulted in fewer errors and fewer choices that slowed down the business, driving better results for the company and our customers.
Once I got my nose out of code and started looking around for ways I could help the business make the most of its data, Looker and BigQuery quickly fell into place as the solutions we needed. In BigQuery, we found a centralized, self-managed database that reduced management overhead. And once all our data was in place, Looker had the most significant impact on our overall productivity, particularly around efficiency and reducing human hours previously spent waiting for data and sharing results between teams. With Looker, we saved time on both ends: in the gathering of data as well as in sharing the insights it revealed with those who needed them most.
What’s remarkable about the BigQuery and Looker combination is how much we can accomplish with relatively small teams. We have our Business Intelligence team, the Data Engineering team, and the Data Science team. These are our ‘data people’, who bring in the data rather than consume it. Then we have our power users who need quick insights from that data and therefore rely on Looker to access up-to-the minute data when they need it. Empowering everyone with data consistently pays off, and it’s a much better use of our time than hammering away at SQL.
Surfacing data insights that lead to action
Data permeates everything we do at Adore Me because we believe that a smarter business results in happier customers. Data helps us run interference, identify problems, and find a fix in real-time, whether that’s optimizing our delivery times or tracking lost packages. On the business planning side, our data reveals what our customers are looking at on our site. This gives us insight into their interests, what’s trending, and what they want to see more of, which in turn also helps to inform our marketing strategies.
As an online shop, driving traffic to the site is critical to Adore Me’s business. With real-time data at our disposal, we’re able to determine which campaigns are the most effective and which markets are best suited for a specific message, so we can intelligently refine our campaigns during peak seasons. With the data in BigQuery and insights surfaced by Looker, we can deliver the products and services our customers want most on our site.
Enabling continuous improvement with a flexible infrastructure
Ultimately, we want to have all of our production-critical data in BigQuery and Looker, acting as an easy-to-manage single source of truth. Data lives where we can easily access it, see it, and analyze it. We can set the rules for all of our KPIs, and everyone is able to look at the same data in order to work towards achieving them together.
What makes Google Cloud Platform so powerful is the suite of products and services that allow our teams to experiment with data in ways that are relevant to our particular business needs. For example, when working with new data sources, we need the ability to quickly visualize a .csv file, and Google Data Studio is the perfect tool for enabling that. If we find something that we want to bring into production, BigQuery makes it easy while modeling it in Looker speeds up the process. This is one way we are constantly improving and enriching our organization’s data capabilities.
Making it easy to find the right tools for the job
Our teams have discovered that the variety of solutions offered by Google Cloud are ideal to address the evolving data challenges we face. Flexibility is critical in business today, and Google Cloud provides a major advantage to those who embrace a proof of concept mentality, which is why we take advantage of the free Google Cloud trials offered. They allow us to roll a product into a project, test drive it for a few days, and fail fast if necessary. No contracts. No hassle. Better still, the variety of products, their ease of use, and overall versatility make it a good bet that we’ll find a solution that works for us.
Anyone with experience working with data will tell you that there’s no shortage of fly-by-night tools out there. But personal experience has shown us that, at the end of the day, success comes down to the strength of your team and choosing the right tools to get the job done. At Adore Me, we’ve built a fantastic team and, with the power of Looker and BigQuery, the sky’s the limit.
Great technology gives us new ways of seeing and working with the world. The microscope enabled new scientific understanding. Trains and telegraphs, in different ways, changed the way we think about distance. Today, cloud computing is changing how we can assist in improving human health.
When you think of the healthcare system, it historically includes a visit to the doctor, sometimes coupled with a hospital stay. These are deeply important events, where tests are done, information on the patient is gathered, and a consultation is set up. But as you think about this structure, there are also limits. Multiple visits are inconvenient and potentially distressing for patients, expensive for the healthcare system and, at best, provide a view of patient health at a specific point in time.
But what if that snapshot of health could be supplemented with a stream of patient information that the doctor could observe and use to help predict and prevent diseases? By harnessing advancements in wearables—devices that sense temperature, heart rate, and oxygen levels—combined with the power of cloud and artificial intelligence (AI) technologies, it is possible to develop a more accurate understanding of patient health.
This broader perspective is the goal of a collaboration between cardiologists at The Hague’s Haga Teaching Hospital, Fitbit—one of the world’s leading wearables that tracks activity, sleep, stress, heart rate, and more—and Google Cloud.
Initially focusing on 100 individuals who have been identified as at-risk of developing heart disease, during a pilot study (ME-TIME), cardiologists at the hospital will give patients a Fitbit Charge 5—Fitbit’s latest activity and health tracker with ECG monitoring1—to wear at home after an initial consultation.
With user consent, the devices will send information about certain patient behavioural metrics to the hospital via the cloud, in an encrypted state.
This data is only accessed by (Haga Teaching Hospital approved) physicians and data scientists at the hospital and is not used by Haga for any other purposes than medical research during the study.2 With user consent, the data, which includes the amount of physical activity a patient is undertaking, will be monitored by Haga ’s physicians against other clinical information already gathered about the individual by the hospital during prior consultations.
With user consent, Haga Teaching Hospital will also compare the data against its other relevant pseudonymized experience data, so the hospital can learn more about potential patterns and abnormalities associated with certain heart conditions. This is made possible by Google Cloud’s infrastructure, which will be used to store the encrypted data at scale, while artificial intelligence (AI) and data analytics tools will power near real-time analysis. For example, predictive analytics on this data could help identify early signs of a life-threatening disease such as a heart attack or stroke, so doctors can investigate further and provide preventative treatment—even before symptoms arise.
Haga is using Device Connect for Fitbit, a new solution from Google Cloud, as part of the trial. Now available for healthcare and life sciences enterprises, the solution empowers business leaders and clinicians with accelerated analytics and insights from consenting users’ Fitbit data, powered by Google Cloud.3
The project is in collaboration with partner Omnigen who has supported Haga with deployment, in addition to processing and analysis of data.
Other hospitals in the Netherlands are already expressing interest in participating in similar projects. Longer term, we see applications to help with deeper understanding of overall population health for healthcare professionals, reducing unnecessary visits to the hospital – and better operation of the wider healthcare system. Preliminary results of the project may be available as early as the end of this year.
“Health is a precious commodity. You realise that all the more if you are struck down by an illness. If you can prevent it or catch it in time so that it can be treated, you have gained a great deal,” said cardiologist, Dr. Ivo van der Bilt of Haga Teaching Hospital, who has been leading on this collaboration. “Digital tools and technologies like those provided by Google Cloud and Fitbit open up a world of possibilities for healthcare and a new era of even more accessible medicine is possible.”
“This collaboration shows how Fitbit can help support innovation in population health, helping healthcare systems & care programmes create more efficient and effective care pathways that aren’t always tied to primary or secondary care settings. Plus it provides patients with tools to help them with their health and wellbeing each day, with metrics which can be overseen by clinical care teams.” said Nicola Maxwell, Head of Fitbit Health Solutions Europe, Middle East & Africa.
This collaboration is an important step towards a goal of creating a more dynamic, rich, and holistic understanding of human health for hospitals, carried out with a strong emphasis on transparency. We are proud to be part of a project that we expect can help patients and healthcare workers alike. We believe this is only the start of what’s possible in healthcare with digital tools like Fitbit and cloud computing.
1. The Fitbit ECG app is only available in select countries. Not intended for use by people under 22 years old. See fitbit.com/ecg for additional details. 2. Haga Teaching Hospital is responsible for any consents, notices or other specific conditions as may be required to permit any accessing, storing, and other processing of this data. Google Cloud does not have control over the data used in this study, which belongs to Haga Teaching Hospital. More generally, Google’s interactions with Fitbit are subject to strict legal requirements, including with respect to how Google accesses and handles relevant Fitbit health and wellness data. Details on these obligations can be found here. 3. This is the same data as that made available through the Fitbit Web API, which the Device Connect integration is built on.
Healthcare is at the beginning of a fundamental transformation to become more patient-centered and data-driven than ever before. We now have better access to healthcare, thanks to improved virtual care, while wearables and other tools have dramatically increased our ability to take control of our own health and wellness.
Healthcare alone generates as much as 30% of the world’s data and much of this will come from the Internet of Medical Things (IoMT) and consumer wearable devices. Gaining insights from wearable data can be challenging, however, due to the lack of a common data standard for health devices resulting in different data types and formats. So what do we do with all this data, and how do we make it most useful?
Today, Fitbit Health Solutions and Google Cloud are introducing Device Connect for Fitbit, which empowers healthcare and life sciences enterprises with accelerated analytics and insights to help people live healthier lives. Fitbit data from their consenting users is made available through the Fitbit Web API, providing users with control over what data they choose to share and ensuring secure data storage and protection. Unlocking actionable insights about patients can help support management of chronic conditions, help drive population health impact, and advance clinical research to help transform lives.
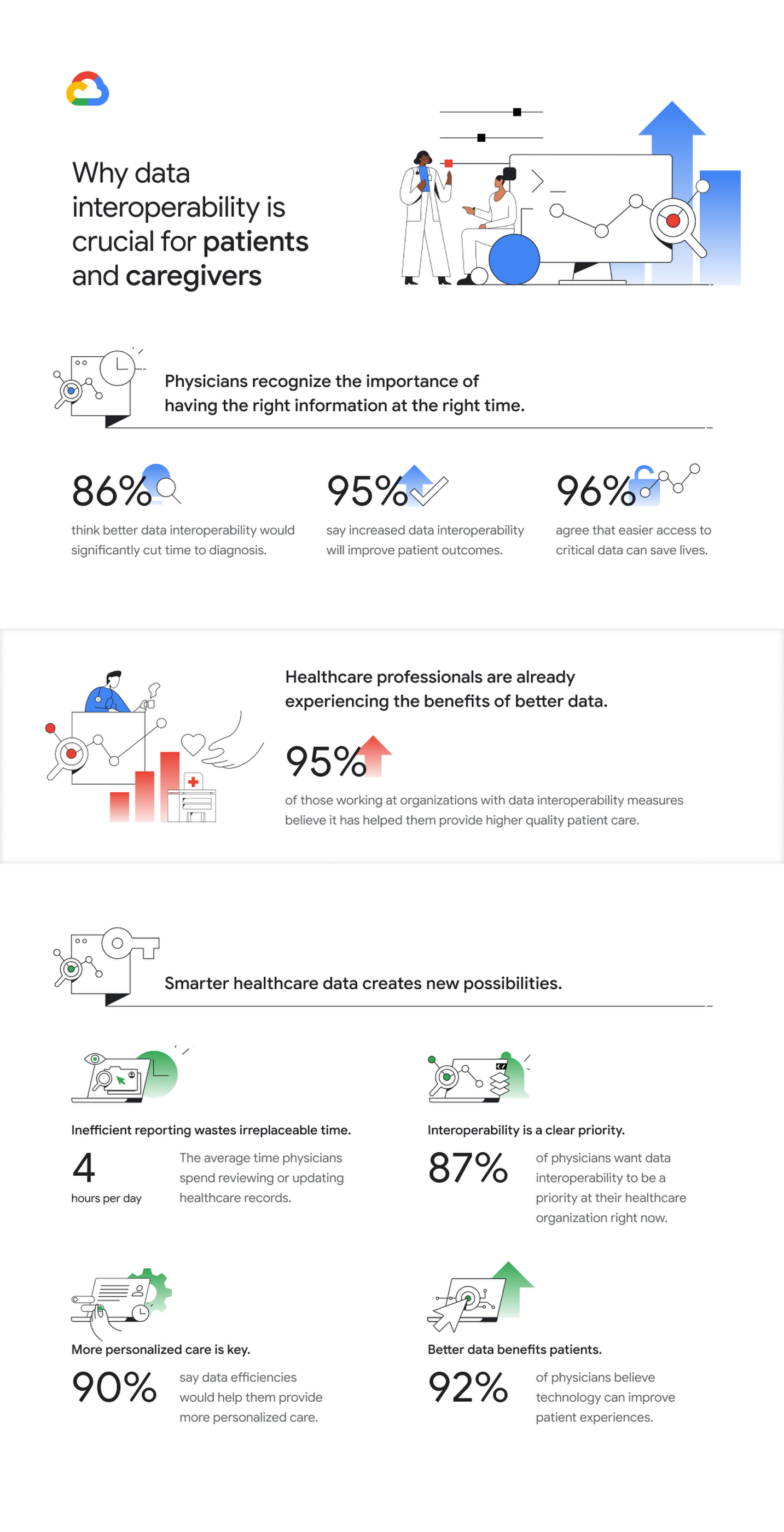
With this solution, healthcare organizations will be increasingly able to gain a more holistic view of their patients outside of clinical care settings. These insights can enhance understanding of patient behaviors and trends while at home, enabling healthcare and life science organizations to better support care teams, researchers, and patients themselves. Based on a recent Harris poll, more than 9 in 10 physicians (92%) believe technology can have a positive impact on improving patient experiences, and 96% agree that easier access to critical information may help save someone’s life.
Help people live healthier lives
This new solution can support care teams and empower patients to live healthier lives in several critical ways:
Pre- and post-surgery: Supporting the patient journey before and after surgery can lead to higher patient engagement and more successful outcomes.1 However, many organizations lack a holistic view of patients. Fitbit tracks multiple behavioral metrics of interest, including activity level, sleep, weight and stress, and can provide visibility and new insights for care teams to what’s happening with patients outside of the hospital. Chronic condition management: For people living with diabetes, maintaining their blood glucose levels within an acceptable range is a constant concern. It’s just one of countless examples, from heart diseases to high blood pressure, where care teams want to promote healthy behaviors and habits to improve outcomes. Better understanding how lifestyle factors may impact disease indicators such as blood glucose levels can enable organizations to deliver more personalized care and tools to support healthy lifestyle changes. Population health: Supporting better management of community health outcomes with a focus on preventive care can help reduce the likelihood of getting a chronic disease and improve quality of life.2 Fitbit users can choose to share their data with organizations that deliver lifestyle behavior change programs aimed at both prevention and management of chronic or acute conditions.Clinical research: Clinical trials depend on rich patient data. Collection in a physician’s office captures a snapshot of the participant’s data at one point in time and doesn’t necessarily account for daily lifestyle variables. Fitbit, used in more than 1,500 published studies–more than any other wearable device–can enrich clinical trial endpoints with new insights from longitudinal lifestyle data, which can help improve patient retention and compliance with study protocols.Health equity: Addressing healthcare disparities is a priority across the healthcare ecosystem. Analyzing a variety of datasets, such as demographic and social determinants of health (SDOH) alongside Fitbit data has the potential to provide organizations and researchers with new insights regarding disparities that may exist across populations—such as obesity disparities that exist among children in low-income families, or increased risk of complications among Black women related to pregnancy and childbirth. Learn more about Fitbit’s commitment to health equity research here.
Accelerate time to insight
Gaining a more holistic view of the patient can better support people on their health and wellness journeys, identify potential health issues earlier, and provide clinicians with actionable insights to help increase care team efficiency. Device Connect for Fitbit addresses data interoperability to “make the invisible visible” for organizations, providing users with consent management and control over their data. Leveraging world-class Google Cloud technologies, Device Connect for Fitbit offers several pre-built components that help make Fitbit data accessible, interoperable and useful—with security and privacy as foundational features.
Enrollment & consent app for web and mobile: The pre-built patient enrollment and consent app enables organizations to provide their users with the permissions, transparency, and frictionless experience they expect. For example, users have control over what data they share and how that data is used.Data connector: Device Connect for Fitbit offers an open-source data connector3, with automated data normalization and integration with Google Cloud BigQuery for advanced analytics. Our data connector can support emerging standards like Open mHealth and enables interoperability with clinical data when used with Cloud Healthcare API for cohort building and AI training pipelines.Pre-built analytics dashboard: The pre-built Looker interactive visualization dashboard can be easily customized for different clinical settings and use cases to provide faster time to insights.AI and machine learning tools: Use AutoML Tables to build advanced models directly from BigQuery or build custom models with 80% fewer lines of code required using Vertex AI—the groundbreaking ML tools that power Google, developed by Google Research.
Google Cloud’s ecosystem of delivery partners will provide expert implementation of services for Device Connect for Fitbit to help customers deploy at scale, and includes BlueVector AI, CitiusTech, Deloitte, and Omnigen.
Potential to help predict and prevent disease
The Hague’s Haga Teaching Hospital in the Netherlands is one of the first organizations to use Device Connect for Fitbit. The solution is helping the organization support a new study on early identification and prevention of vascular disease.
“Collaborating with Google Cloud allows us to do our research, with the help of data analytics and AI, on a much greater scale,” cardiologist Dr. Ivo van der Bilt said. “Being able to leverage the new solution makes it easier than ever to gain the insights that will make this trial a success. Health is a precious commodity. You realize that all the more if you are struck down by an illness. If you can prevent it or catch it in time so that it can be treated, you have gained a great deal.”
Fitbit innovation continues
Since becoming part of the Google family in January 2021, Fitbit has continued to help people around the world live healthier, more active lives and to introduce innovative devices and features, including FDA clearance for the new PPG AFib algorithm for irregular heart rhythm detection, released in April of this year. Fitbit metrics including activity, sleep, breathing rate, cardio fitness score (Vo2 Max), heart rate variability, weight, nutrition, SP02 and more will be accessible through Device Connect Fitbit. Google’s interactions with Fitbit are subject to strict legal requirements, including with respect to how Google accesses and handles relevant Fitbit health and wellness data. You can find details on these obligations here.
1. Harris Poll 2. CDC 3. Device Connect for Fitbit is built on the Fitbit Web API and data available from consenting users is the same as that made available for third parties through the Fitbit Web API, and enables the enterprise customer services through Google Cloud.
The products around us are growing more complex every year. Mechanical designs are increasingly intricate, software development is ever more powerful, not to mention more and more physical products are being incorporated into the internet of things or contain distinct software. As a result, manufacturers need to be more agile than ever, and most struggle to keep up.
Cloud technology is among the biggest changes. The market for cloud services is worth over $400 billion and growing.
While linear development processes have served manufacturers well for decades, future products require multidimensional planning. Now is the time for companies deploying limited tools to consider switching to cloud-based data storage and powerful product planning tools.
The Limitations of Linear Manufacturing Processes
Data silos have become one of the biggest restraints with using linear manufacturing processes. Even when a manufacturer adopts advanced process solutions, the legacy data collection problem remains in isolated channels. For example, if your company collects data from your new equipment while collecting data from other vendors separately, you may end up with incompatible file formats. How will you analyze your data to get a comprehensive picture of your products if you cannot combine your stats?
Problems with compatibility can also occur across internal departments. Your marketing, product, and design departments may be using the latest tools, but if their data is not compatible or integrated into the same destination, it can cause delays. You may have trouble organizing all your reports, and you may miss crucial information altogether.
Agility Is Important at Every Stage of Manufacturing
Agility is an essential quality at every stage of manufacturing. When your company is better equipped to make efficient, informed decisions, you’ll be better able to deliver competitive products to your markets in shorter time spans.
Agility Begins In the Cloud
When implemented correctly, the cloud enables organizations to eliminate data silos and create one source of truth for the entire organization, regardless of where your teams are located. The cloud also enables you to apply powerful analytics over your data to prevent anyone in your organization from having to interpret raw data. Rather than spending precious hours pouring over the figures, your teams can use the cloud to deliver the best interpretations of the stats automatically.
The Cloud Saves You Time
Using the cloud helps your teams communicate and collaborate more efficiently. Imagine your design team creates a 3D rendering of a prototype, then sends it to the cloud, where your factory in another time zone gets an automatic notice to download the file. They can then create a 3D physical version to analyze, test, and send immediate feedback to the design team while preparing their production line for the new product. Simultaneously, your marketing team can examine the design and build a campaign story around it.
The Cloud Increases Functionality
Product planning teams that use the cloud have much more flexibility in managing their teams than those still using a suite of rigid tools with separate functions. Instead, product planning teams can use the cloud to communicate, collaborate, analyze, and make decisions in one centralized location. Product management becomes agile, flexible, and functional with the right software platform.
Reliable and Trusted Security
The idea that the cloud lacks reliable security is completely outdated. Most cloud service providers deliver superior network security and safe infrastructure to resist cyber attacks and include disaster recovery contingency plans. Most manufacturers do not maintain nearly the same level of security for their on-site servers and systems as cloud service providers do. It’s fairly common knowledge nowadays that moving to the cloud will actually enhance your network and infrastructure security rather than decrease it.
When manufacturers embrace the possibilities using the cloud delivers, their systems and processes become far more efficient and flexible than before. Designs can evolve simultaneously, rather than in a linear, stunted function, making the manufacturing process much better equipped to handle the increasing complexity of products.
Choosing a Cloud platform
The cloud is not pre-equipped to make your manufacturing process more efficient. You’ll want to find the right cloud software that is designed for manufacturing. More and more cloud platforms offer manufacturers streamlined processes, so how do you find the right one for your company? When researching and testing the platform that is right for your company, there are several factors to consider:
Does the platform allow seamless integration of your existing data?Does the platform eliminate your data silos into one accessible source of truth?Can your teams work efficiently and collaboratively on product design?Do they prioritize security to protect your intellectual property?Do they create features that are useful for manufacturing? Do they offer helpful support and guidance when using their platform?
The SaaS solutions that offer the most agility, security, and powerful features use the cloud to power their apps and manage their data. With the possibilities of the cloud, SaaS companies can scale their service based on what each client needs for capacity. The cloud can be a game-changer for manufacturers who find the right software for their needs.
Gocious is an example of a tech start-up using the cloud to deliver specific application functionality. We’ve created Product Roadmap Management software to help manufacturers become more agile with clear data visualizations and unique competitive analysis features.
AI technology has led to some massive changes in recent years. Most of these developments have been good. Unfortunately, there are dark sides to the evolution of AI.
One of the drawbacks of AI has come in the realm of cybersecurity. On the one hand, AI has helped improve cybersecurity in some ways. On the other hand, hackers are weaponizing AI to create more horrifying attacks.
There are a number of ways hackers create more devastating attacks with AI. One of the biggest issues is that they are creating new forms of ransomware with machine learning capabilities.
Hackers Use AI to Create Terrifying Forms of Ransomware
In the world of cybercrime, the leading event is a phishing email, which accounts for the vast majority of security breaches in business. However, even though phishing is significantly more common, 85% of organizations are more worried about ransomware and the impacts a ransomware attack could have on their business going forward.
Much like a phishing event, ransomware is fairly easy to trigger. With phishing, a user will accidentally navigate to a false page, where they could give away information like their user login or password. Similarly, ransomware only takes a few clicks – with a user selecting a file and accidentally downloading an email attachment to their computer.
Hackers have used AI to create more effective phishing attacks. They can use machine learning to better understand the types of links users will click on and what time to send emails to get the most downloads. They can also use AI technology to make their ransomware more vicious. AI can train malware to evade antivirus protection software and bypass other elements of the computer security system.
The main purpose of ransomware is to take all computer systems and files hostage from a business, eliminating their ability to get work done and charging a (normally) fixed fee to recover the systems. Unlike phishing, which doesn’t seem to have a simple exit option, ransomware has a payment wall in place that could alleviate the problem.
AI has certainly made ransomware worse than ever. But that calls into question for a business – should they pay hackers when AI-driven ransomware is detected on their systems? In this article, we’ll explore the ransomware phenomenon, demonstrating why, ultimately, paying is very rarely the right decision to make.
Let’s get right into it.
Why Does Ransomware Powered by AI Frustrate Companies?
Ransomware is designed to completely shut down business operations for as long as possible. Most commonly, hackers will target user accounts that have access to the largest selection of company files. If a hacker gains access to an account that cannot then access any systems, they’ve essentially hit a dead end.
However, if a hacker gains access to an administrator account, they can then cause havoc for the business. From instantly privatizing all files and disabling all systems to downloading private financial data, hackers with administrator accounts can completely stall a business in its tracks.
Especially for businesses that need to actively deal with clients to continue their day-to-day work, disabling these systems and barring access to files means the business can’t make any more money. With high-turnover businesses, even a few hours of system downtime can cause a huge problem, let alone days or weeks at a time.
Without the ability to conduct business, and with costs mounting up without profit, many businesses see paying the ransom as the right thing to do.
Ransomware appears to be even more effective when it uses AI technology. Hackers depend on it to infect their users.
Why You Should Never Pay the Ransom
When your business is dealing with a ransomware event, it can often feel like you’re trapped in a corner. Without your systems and files to fall back on, many businesses don’t know where to go. This feeling of panic usually pushes them into making a rash decision and paying the fees.
In 2021, the average ransom payment for a business was over $800,000 USD, with this being no small sum for the vast majority of businesses. Typically, any business that could easily afford this amount would receive a much higher figure, meaning paying ransomware is always going to eat into profits a considerable amount.
While paying the ransom may seem like the simplest option, there are two main reasons that you should never submit:
No Guarantee – Even after you’ve paid the money, this is not a legal contract that you’re signing. There is no guarantee that once you pay the full figure, the hackers will give your system back. Worse, there is no guarantee that they haven’t hidden further ransomware deep in your systems, which would lead to further complications down the line.Creating a Target – When you pay a ransom to attackers, you’re sending a message to every other cybercriminal in the ecosystem that you’re a company that is willing to pay. Not only does this create a target on your back, but there is nothing to stop the attackers you’re paying from turning around and targeting you again right away.
Quite simply, paying the ransom almost always leads to even more problems, with this being the fastest way of making your business a target for future attacks. While it may seem like the best solution, this is rarely the case.
What Should You Do?
If you’re already in the midst of a ransomware attack, then your first point of contact should be the authorities. Most of the time, authorities are able to navigate the ransomware attack on your behalf and will have tools and structures to help you get through it.
Still, this is far from ideal. The very best way to never have to pay the ransom is to take proper precautions with your business. As frustrating as it may be to realize, this attack was caused by someone in your business clicking on a file that they shouldn’t have. If your business is experiencing a ransomware attack, your first approach should be better prepared for next time.
There are a few things you should actively be encouraging in your business:
Security training – Always provide extensive security training for your employees. As the vast majority of cybersecurity events are triggered by human mistakes, bringing your teams up to speed on the best practices is always a great idea.Email defenses – Make sure your company has effective firewalls and email security software that scans for malware and ransomware.Backups – Backups are the easiest way of beating ransomware attacks for good. All you need to do if faced with ransomware is to revert to a previous backup to solve the problem. Frequent backups will ensure that data loss is as minimal as possible.AI security – AI may be deadly in the hands of hackers. However, it can also be very useful in your hands as a cybersecurity expert. You will want to use AI cybersecurity technology to your advantage.
By focusing on preventative strategies, you’ll be in a much better position if your company ever falls prey to a cybersecurity event. Education, preparation, and foresight are key when it comes to keeping your business safe.
AI Makes Ransomware Worse But You Should Never Pay the Ransom
AI has led to some horrifying developments in the field of cybercrime. Hackers are using AI to create more viciouus forms of ransomware than ever. Instead of paying the ransom, preemptively put some of that money into educating your staff, creating backups of all important files, and investing in preventive measures.







{kind=link}
{kind=link}
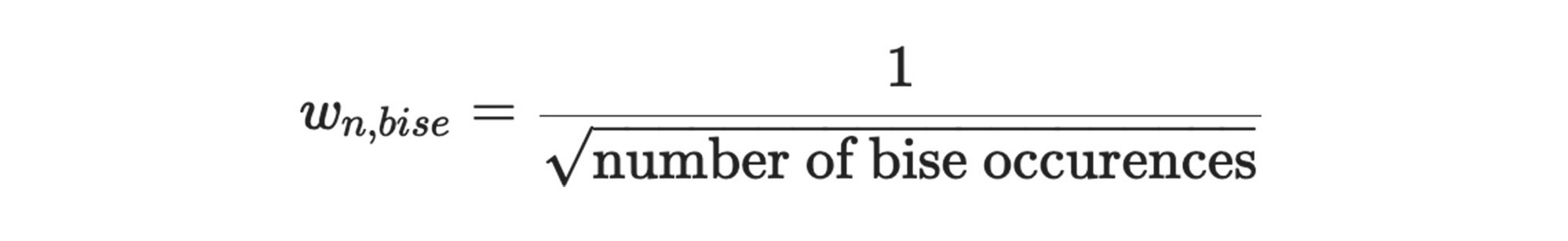{kind=link}
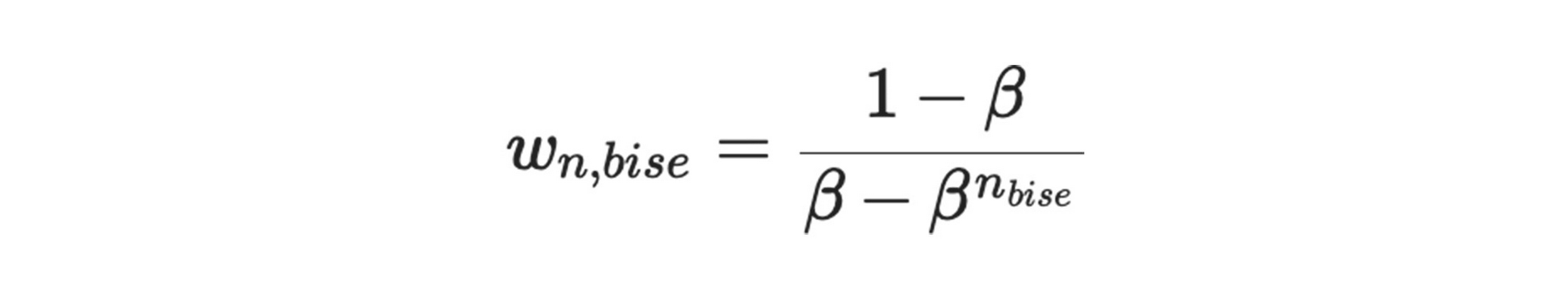{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}