
Built with BigQuery: How Tinyclues and Google Cloud deliver the CDP capabilities that marketers need

Editor’s note: The post is part of a series highlighting our awesome partners, and their solutions, that are Built with BigQuery.
What are Customer Data Platforms (CDPs) and why do we need them?
Today, customers utilize a wide array of devices when interacting with a brand. As an example, think about the last time you bought a shirt. You may start with a search on your phone as you take the subway to work. During that 20 minute ride, you narrow down the type of shirt . Later, as you take your lunch break, you spend a few more minutes refining your search on your work laptop and you are able to find two shirt models of interest. Pressed for time, you add both to your shopping cart at an online retailer to review at a later point. Finally, after you arrive back home and as you are checking your physical mail, you stumble across a sales advertisement for the type of shirt that you are looking for, available at your local brick and mortar store. The next day you visit that store during your lunch break and purchase the shirt.
Many marketers face the challenge of creating a consistent 360 customer view that captures the customer lifecycle, as illustrated in the example above – including their online/offline journey, interacting with multiple data points across multiple data sources.
The evolution of managing customer data reached a turning point in the late 90’s with CRM software that sought to match current and potential customers with their interactions. Later as a backbone of data-driven marketing, Data Management Platforms (DMPs) expanded the reach of data management to include second and third party datasets including anonymous IDs. A Customer Data Platform combines these two types of systems, creating a unified, persistent customer view across channels (mobile, web etc) that provide data visibility and granularity at individual level.
A new approach to empowering marketing heroes
Tinyclues is a company that specializes in empowering marketers to drive sustainable engagement from their customers and generate additional revenue, without damaging customer equity. The company was founded in 2010 on a simple hunch: B2C marketing databases contain sufficient amounts of implicit information (data unrelated to explicit actions) to transform the way marketers interact with customers, and a new class of algorithms based on Deep Learning (sophisticated machine learning that mimics the way humans learn) holds the power to unlock this data’s potential. Where other players in the space have historically relied – and continue to rely – on a handful of explicit past behaviors and more than a handful of assumptions, Tinyclues’ predictive engine uses all of the customer data that marketers have available in order to formulate deeply precise models, down even to the SKU level. Tinyclues’ algorithms are designed to detect changes in consumption patterns in real-time, and adapt predictions accordingly.
This technology allows marketers to find precisely the right audiences for any offer during any timeframe, increasing engagement with those offers and, ultimately, revenue; additionally, marketers are able to increase campaign volume while decreasing customer fatigue and opt-outs, knowing that audiences are receiving only the most relevant messages. Tinyclues’ technology also reduces time spent building and planning campaigns by upwards of 80%, as valuable internal resources can be diverted away from manual audience-building.
Google Cloud’s Data Platform, spearheaded by BigQuery, provides a serverless, highly scalable, and cost-effective foundation to build this next generation of CDPs.
Tinyclues Architecture:
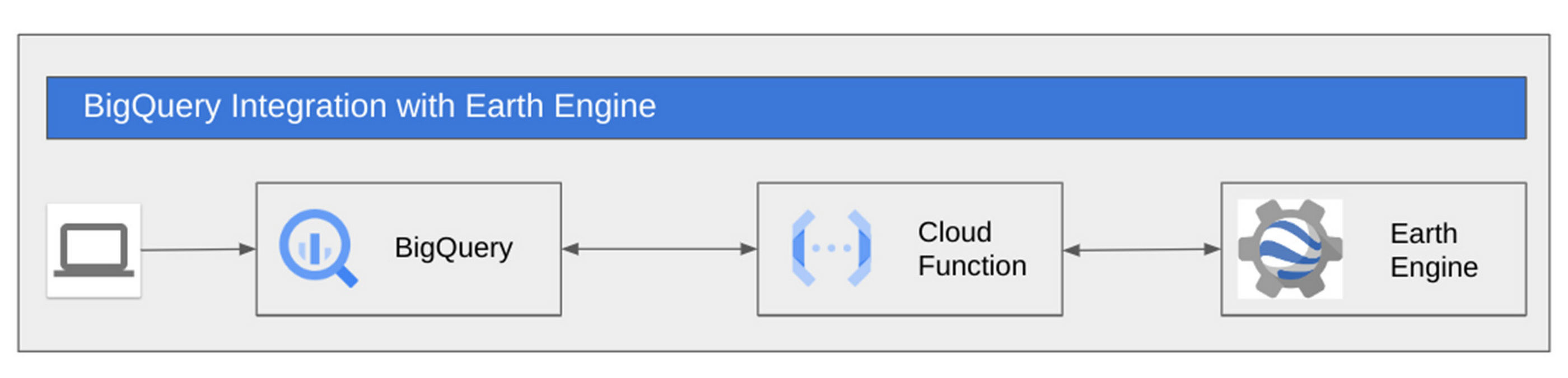
To enable this scalable solution for clients, Tinyclues receives purchase and interaction logs from clients in addition to product and user tables. In most cases, this data is already in the client’s BigQuery instance, in which case they can be easily shared with Tinyclues utilizing BigQuery authorized views.
In cases where the data is not in BigQuery, flat files are sent to Tinyclues via GCS and are ingested in the client’s data set via a lightweight Cloud Function. The orchestration of all pipelines is implemented via Cloud Composer (Google’s managed Airflow). The transformation of data is accomplished by utilizing simple select statements in the Data Built Tool (DBT), which is wrapped inside an airflow DAG that powers all data normalization and transformations. There are several other DAGs to fulfill more functionalities, including:
Indexing the product catalog on Elastic Cloud (Elasticsearch managed service) on GCP to provide auto-complete search capabilities to TCs clients as shown below:
The export of Tinyclues-powered audiences to the clients’ activation channels, whether they are using SFMC, Braze, Adobe, GMP, or Meta.
Tinyclues AI/ML Pipeline powered by Google Vertex AI
TCs ML Training pipelines are used to train models that calculate propensity scores. They are composed using Airflow DAGs, powered by Tensorflow & Vertex AI Pipelines. BigQuery is used natively, without data movement, to perform as much feature engineering as possible in-place.
TC uses the TFX library to run ML Pipelines in Vertex AI. Building on top of Tensorflow as their main deep learning framework of choice due to its maturity, open source platform, scalability and support for complex data structures (Ragged and Spare Tensors).
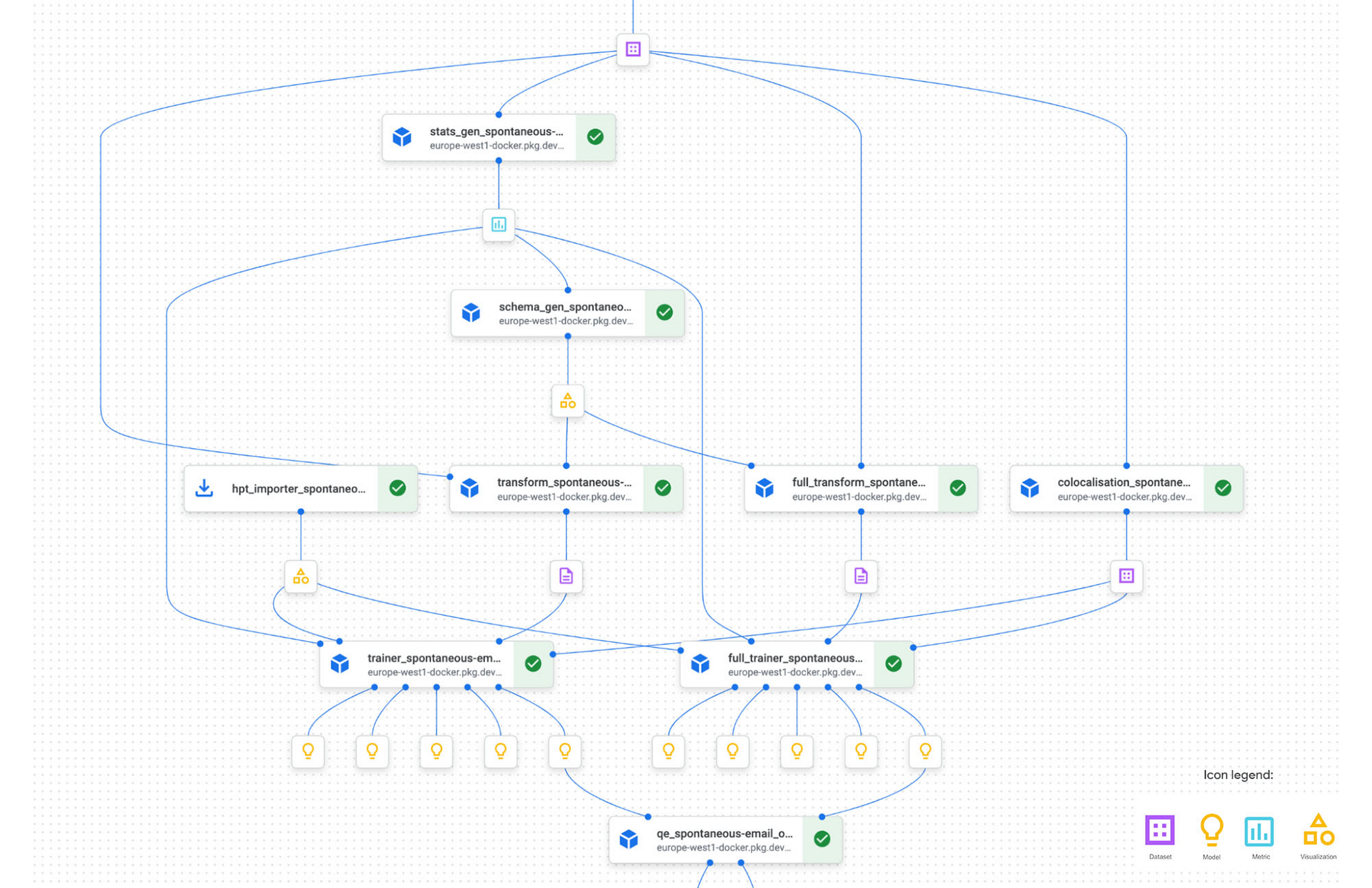
Below is a partial example of TC’s Vertex AI Pipeline graph, illustrating the workflow steps in the training pipeline. This pipeline allows for the modularization & standardization of functionality into easily manageable building blocks. These blocks are composed of TFX components (TC reuses most of the standard components in addition to customizing some such as a proprietary implementation of the Evaluator to compute both ML Metrics (which is part of the standard implementation) but also more Business Metrics like Overlap of clickers etc. The individual components/steps are chained with DSL to form a pipeline that is modular and easily orchestrated or updated as needed.
With the trained Tensorflow models available in GCS, TCs exposes these in BigQuery ML (BQML) to enable their clients to score millions of users for their propensity to buy X or Y within minutes. This would not be possible without the power of BigQuery and also frees TC from previously experienced scalability issues.
As an illustration, TC has the need to score thousands of topics among millions of users. This used to take north of 20 hours on their previous stack, and now takes less than 20 minutes thanks to the optimization work that TC has implemented in their custom algorithm and the sheer power of BQ to scale to any workload accordingly.
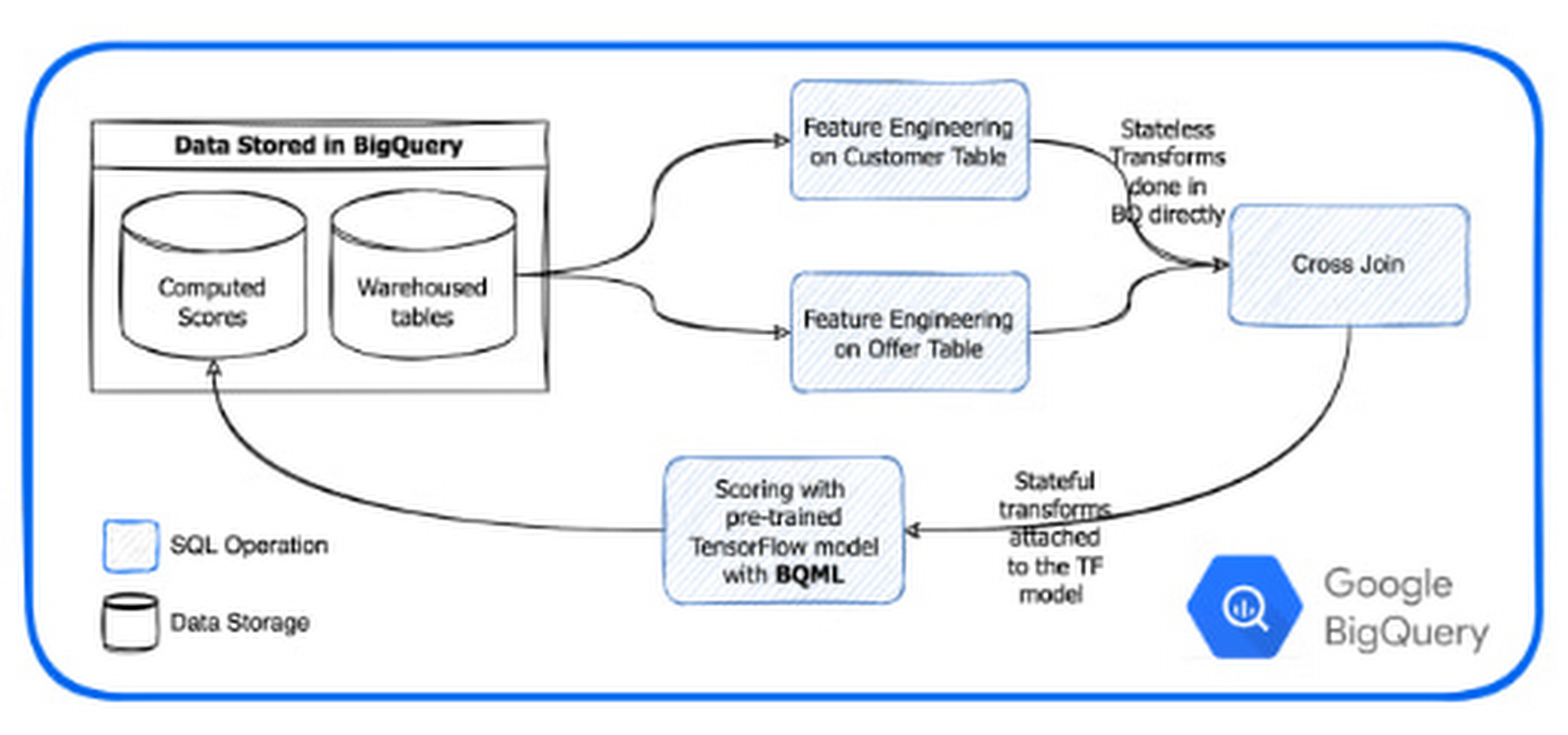
Data Gravity: Breaking the Paradigm – Bringing the Model to your Data
BQML enables TC to call pre-trained TensorFlow models within an SQL environment, thus avoiding exporting data in and out of BQ using already provisioned BQ serverless processing power. Using BQML removes the layers between the models and the data warehouse and allows them to express the entire inference pipe as a number of SQL requests. TC no longer has to export data to load it into their models. Instead, they are bringing their models to the data.
Avoiding the export of data in and out of BQ and the serverless provisioning and start of machines saves significant time. As an example, exporting an 11M lines campaign for a large client previously took 15 min or more to process. Deployed on BQML it now takes minutes with more than half of the processing time attributed to network transfers to our client system.
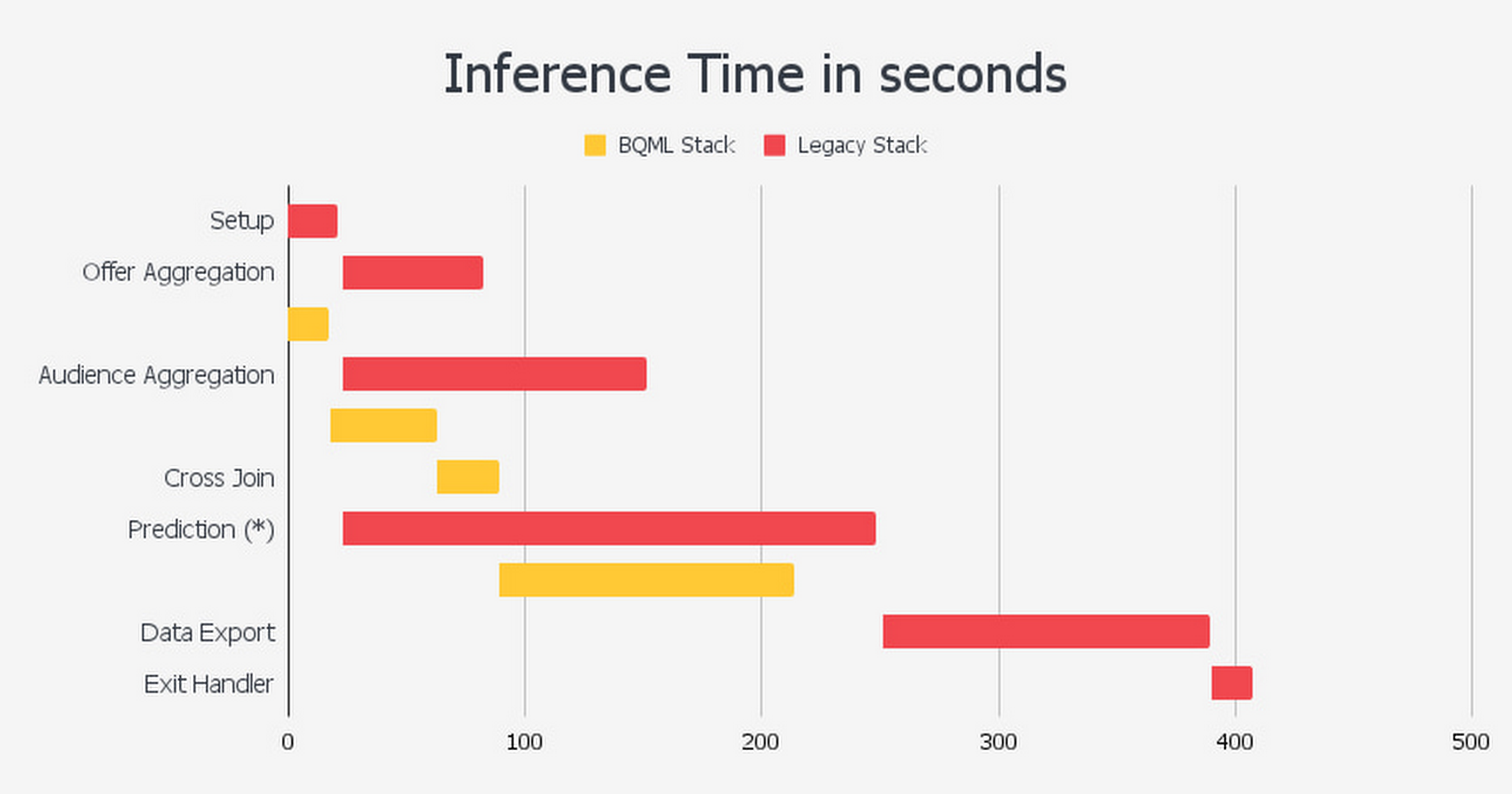
Inference times in BQML compared to TCs legacy stack:
As can be seen, using this approach enabled by BQML, the reduction in the number of steps leads to a 50% decrease in overall inference time, improving upon each step of the prediction.
The Proof is in the pudding
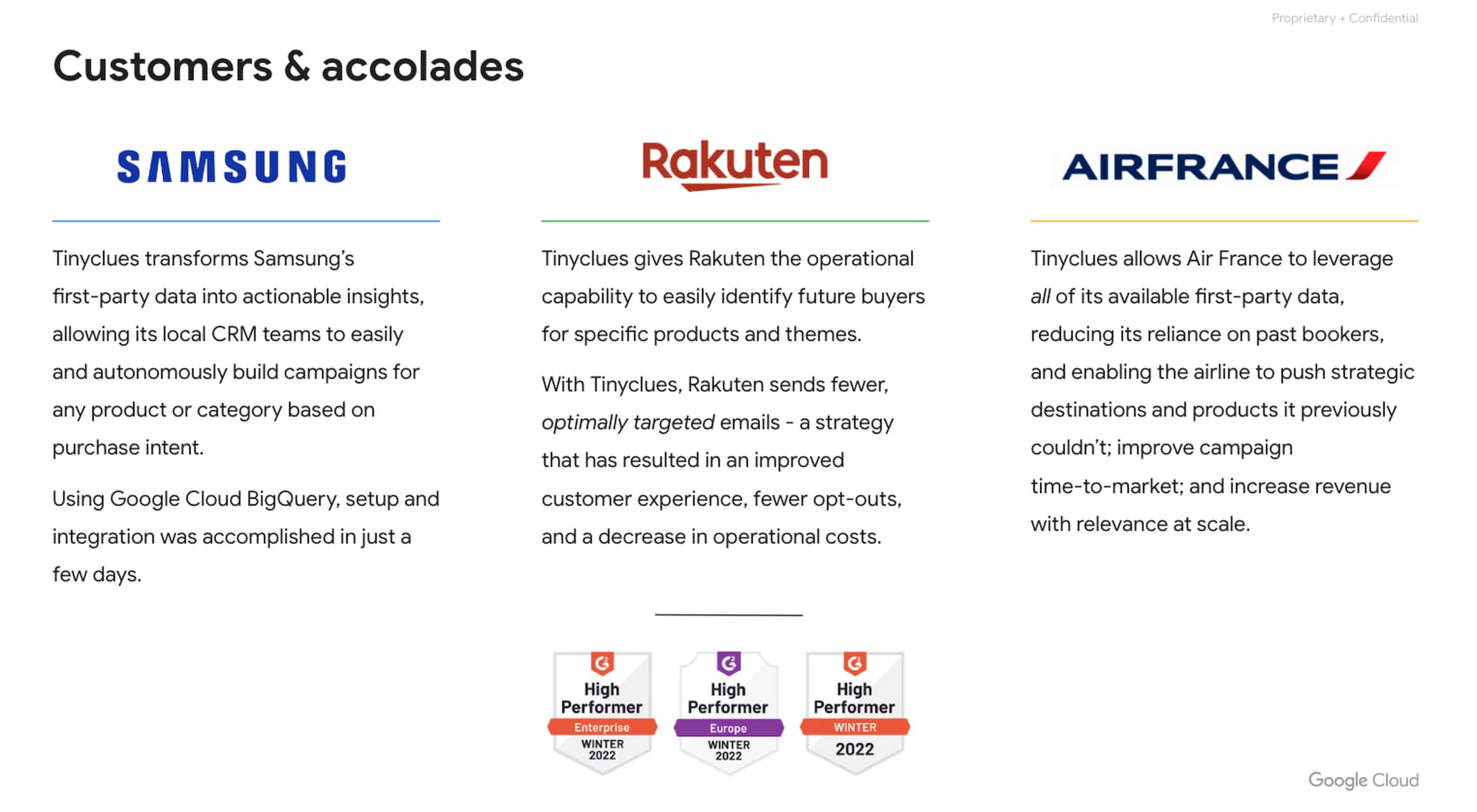
Tinyclues has consistently delivered on its promises of increased autonomy for CRM teams, rapid audience building, superior performance against in-house segmentation, identification of untapped messaging and revenue opportunities, fatigue management, and more, working with partners like Tiffany & Co, Rakuten, and Samsung, among many others.
Conclusion
Google’s data cloud provides a complete platform for building data-driven applications like the headless CDP solution developed by Tinyclues — from simplified data ingestion, processing, and storage to powerful analytics, AI, ML, and data sharing capabilities — all integrated with the open, secure, and sustainable Google Cloud platform. With a diverse partner ecosystem, open-source tools, and APIs, Google Cloud can provide technology companies the portability and differentiators they need to serve the next generation of marketing customers.
To learn more about Tinyclues on Google Cloud, visit Tinyclues. Click here to learn more about Google Cloud’s Built with BigQuery initiative.
We thank the many Google Cloud team members who contributed to this ongoing data platform collaboration and review, especially Dr. Ali Arsanjani in Partner Engineering.
Source : Data Analytics Read More





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}