When running Apache Hadoop and Spark, it is important to tune the configs, perform cluster planning, and right-size compute. Thorough benchmarking is required to make sure the utilization and performance are optimized. In Dataproc, you can run Spark jobs in a semi-long-running cluster or ephemeral Cloud Dataproc on Google Compute Engine (DPGCE) cluster or via Dataproc Serverless Spark. Dataproc Serverless for Spark runs a workload on an ephemeral cluster. An ephemeral cluster means the cluster’s lifecycle is tied to the job. A cluster is started, used to run the job, and then destroyed after completion. Ephemeral clusters are easier to configure, since they run a single workload or a few workloads in a sequence. You can leverage Dataproc Workflow Templates to orchestrate this. Ephemeral clusters can be sized to match the job’s requirements. This job-scoped cluster model is effective for batch processing. You can create an ephemeral cluster and configure it to run specific Hive workloads, Apache Pig scripts, Presto queries, etc., and then delete the cluster when the job is completed.
Ephemeral clusters have some compelling advantages:
They reduce unnecessary storage and service costs from idle clusters and worker machines.
Every set of jobs runs on a job-scoped ephemeral cluster with job-scoped cluster specifications, image version, and operating system.
Since each job gets a dedicated cluster, the performance of one job does not impact other jobs.
Persistent History Server (PHS)
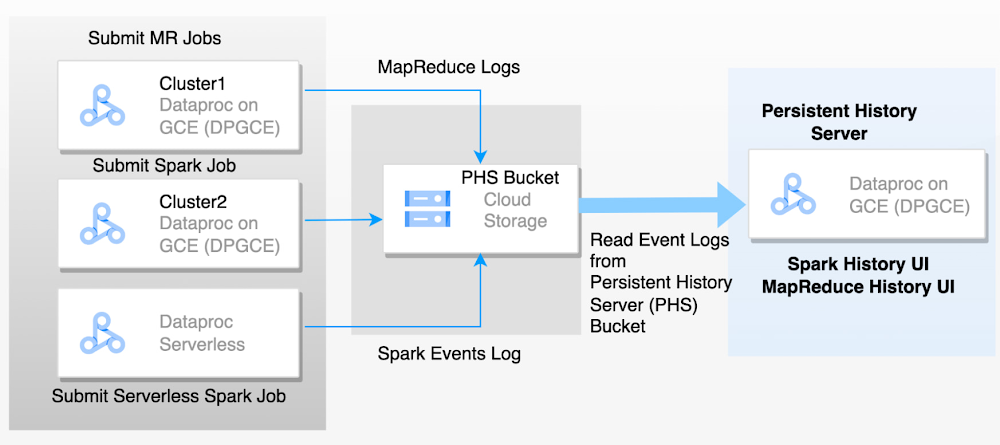
The challenge with ephemeral clusters and Dataproc Serverless for Spark is that you will lose the application logs when the cluster machines are deleted after the job. Persistent History Server (PHS) enables access to the completed Hadoop and Spark application details for the jobs executed on different ephemeral clusters or serverless Spark. It can list running and completed applications. PHS keeps the history (event logs) of all completed applications and its runtime information in the GCS bucket, and it allows you to review metrics and monitor the application at a later time. PHS is nothing but a standalone cluster. It reads the Spark events from GCS, then parses and presents application details, scheduler stages, and task level details, as well as environment and executor information, in the Spark UI. These metrics are helpful for improving the performance of the application. Both the application event logs and the YARN container logs of the ephemeral clusters are collected in the GCS bucket. These log files are important for engaging Google Cloud Technical Support to troubleshoot and explore. If PHS is not set up, you have to re-run the workload, which adds to support cycle time. If you have set up PHS, you can provide the logs directly to Technical Support.
The following diagram depicts the flow of events logged from ephemeral clusters to the PHS server:
In this blog, we will focus on Dataproc PHS best practices. To set up PHS to access web interfaces of MapReduce and Spark job history files, please refer to Dataproc documentation.
PHS Best Practices
Cluster Planning and Maintenance
It’s common to have a single PHS for a given GCP project. If needed, you can create two or more PHSs pointing to different GCS buckets in a project. This allows you to isolate and monitor specific business applications that run multiple ephemeral jobs and require a dedicated PHS.
For disaster recovery, you can quickly spin up a new PHS in another region in the event of a zonal or regional failure.
If you require High Availability (HA), you can spin up two or more PHS instances across zones or regions. All instances can be backed by the dual-regional or multi-regional GCS bucket.
You can run PHS on a single-node Dataproc cluster, as it is not running large-scale parallel processing jobs. For the PHS machine type:
N2 are the most cost-effective and performant machines for Dataproc. We also recommend 500-1000GB pd-standard disks.
For <1000 apps and if there are apps with 50K-100K tasks, we suggest n2-highmem-8.
For <1000 apps and there are apps with 50K-100K tasks, we suggest n2-highmem-8.
For >10000, we suggest n2-highmem16.
We recommend you benchmark with your Spark applications in the testing environment before configuring PHS in production. Once in production, we recommend monitoring your GCE backed PHS instance for memory and CPU utilization and tweaking machine shape as required.
In the event of significant performance degradation within the Spark UI due to a large amount of applications or large jobs generating large event logs, you can recreate the PHS with increased machine size with higher memory.
As Dataproc releases new sub-minor versions on a bi-weekly cadence or greater, we recommend recreating your PHS instance so it has access to the latest Dataproc binaries and OS security patches.
As PHS services (e.g. Spark UI, MapReduce History Server) are backwards compatible, it’s suggested to create a Dataproc 2.0+ based PHS cluster for all instances.
Logs Storage
Configure spark:spark.history.fs.logDirectory to specify where to store event log history written by ephemeral clusters or serverless Spark. You need to create the GCS bucket in advance.
Event logs are critical for PHS servers. As the event logs are stored in a GCS bucket, it is recommended to use a multi-Region GCS bucket for high availability. Objects inside the multi-region bucket are stored redundantly in at least two separate geographic places separated by at least 100 miles.
Configuration
PHS is stateless and it constructs the Spark UI of the applications by reading the application’s event logs from the GCS bucket. SPARK_DAEMON_MEMORY is the memory to allocate to the history server and has a default of 3840m. If too many users are trying to access the Spark UI and access job application details, or if there are long-running Spark jobs (iterated through several stages with 50K or 100K tasks), the heap size is probably too small. Since there is no way to limit the number of tasks stored on the heap, try increasing the heap size to 8g or 16g until you find a number that works for your scenario.
If you’ve increased the heap size and still see performance issues, you can configure spark.history.retainedApplications and lower the number of retained applications in the PHS.
Configure mapred:mapreduce.jobhistory.read-only.dir-pattern to access MapReduce job history logs written by ephemeral clusters.
By default, spark:spark.history.fs.gs.outputstream.type is set to BASIC. The job cluster will send data to GCS after job completion. Set this to FLUSHABLE_COMPOSITE to copy data to GCS at regular intervals while the job is running.
Configure spark:spark.history.fs.gs.outputstream.sync.min.interval.ms to control the frequency at which the job cluster transfers data to GCS.
To enable the executor logs in PHS, specify the custom Spark executor log URL for supporting external log service. Configure the following properties:
code_block[StructValue([(u’code’, u’spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}} and spark.history.custom.executor.log.url.applyIncompleteApplication=False’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e9920ac7ed0>)])]
Lifecycle Management of Logs
Using GCS Object Lifecycle Management, configure a 30d lifecycle policy to periodically clean up the MapReduce job history logs and Spark event logs from the GCS bucket. This will improve the performance of the PHS UI considerably.
Note: Before doing the cleanup, you can back up the logs to a separate GCS bucket for long-term storage.
PHS Setup Sample Codes
The following code block creates a Persistent History server with the best practices suggested above.
With the Persistent History server, you can monitor and analyze all completed applications. You will also be able to use the logs and metrics to optimize performance and to troubleshoot issues related to strangled tasks, scheduler delays, and out of memory errors.
If you’re self-managing relational databases such as MySQL, PostgreSQL or SQL Server, you may be thinking about the pros and cons of cloud-based database services. Regardless of whether you’re running your databases on premises or in the cloud, self-managed databases can be inefficient and expensive, requiring significant effort around patching, hardware maintenance, backups, and tuning. Are managed database services a better option?
To answer this question, Google Cloud sponsored a business value white paper by IDC, based on the real-life experiences of eight Cloud SQL customers. Cloud SQL is an easy-to-use, fully-managed database service for running MySQL, PostgreSQL and SQL Server workloads. More than 90% of the top 100 Google Cloud customers use Cloud SQL.
The study found that migration to Cloud SQL unlocked significant efficiencies and cost reductions for these customers. Let’s take a look at the key benefits in this infographic.
Infographic: IDC business value study highlights the business benefits of migrating to Cloud SQL
You can use our Database Migration Service for an easy, secure migration to Cloud SQL. Since Cloud SQL supports the same database versions, extensions and configuration flags as your existing MySQL, PostgreSQL and SQL Server instances, a simple lift-and-shift migration is usually all you need. So let Google Cloud take routine database administration tasks off your hands, and enjoy the scalability, reliability and openness that the cloud has to offer.
AI technology has become an incredibly important part of most IT functions. One of the many reasons IT professionals are investing in AI is to fortify their digital security.
One of the best ways that cybersecurity professionals are leveraging AI is by utilizing SAST strategies.
AI Solidifies Network Security with Better SAST Protocols
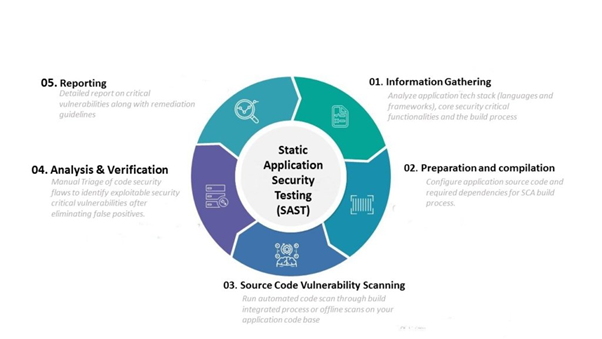
Every single day, a wide variety of new applications and lines of code are being released. A big part of what enables this constant deployment of new applications is a testing process known as static application security testing, or SAST. It analyzes the source code created by developers or organizations to locate security flaws. An application is analyzed by SAST prior to having its code built. It is frequently referred to as “white box testing.”
These days, organizations wish to adopt the shift left method, which requires problems to be corrected as soon as they are discovered. Because of this, SAST takes place extremely early on in the software development lifecycle (SDLC).
This works because SAST does not require a well-functioning software; rather, it simply needs machine learning codes that are currently being developed, which it then analyzes to find vulnerabilities. These AI codes also help developers detect SAST vulnerabilities in the early stages of development, so they may quickly resolve the issues without releasing vulnerable code into production, which could pose a threat to the infrastructure of the company.
For modern-day applications that use containers and Kubernetes, SAST is used for Kubernetes security to protect deployments by identifying potential vulnerabilities in the codebase before the code is put into production. This allows organizations to fix issues early on and prevents any potential vulnerabilities from affecting the final product. This is one of the best ways for companies to use AI to improve network security.
How Does a Modern SAST Strategy Work and What Role Does AI Play in It?
The present SAST technique is quite well developed, especially as it has improved due to new advances in AI. This technology also helps it make use of a wide variety of tools, all of which contribute to the process of fixing smaller bugs and vulnerabilities that may exist in the code.
There are a number of potential vulnerabilities that need to be addressed, such as open source supply chain attacks, that could happen because of things like outdated packages. New developments in AI have made it easier to detect these problems, which helps improve the security of the overall application.
What are some of the ways that AI has helped improve SAST? Some of the benefits have been developed by AI scientists at IBM.
These experts used IBM’s AI application known as “Watson” to better identify security vulnerabilities. They came up with an Intelligent Finding Analytics (IFA) tool, which had a 98% accuracy with detecting security vulnerabilities.
You can learn more about the benefits of using AI for SAST in the following YouTube video by IBM.
Reduce your application security risk with IBM’s cognitive capabilities
Let’s have a conversation about the approaches that are currently being taken to address problems of this nature.
Securing the Dependencies
Applications rely on a large number of different dependencies in order to function properly. Not only do they make the task easier for the software developers, but they also assist developers in writing code that is reliable and effective. Due to the fact that the majority of these dependencies are open source and therefore could include vulnerabilities, it is necessary to perform regular updates on them.
There could be a large number of dependents within an application. Thus, it is impossible for those dependencies to be monitored manually. Doing so would involve a significant amount of effort and could also lead to errors caused by manual intervention. In light of this, businesses typically make use of dependency management tools.
Such tools, after checking for available updates in the dependencies within a predetermined amount of time, open a pull request for each update that is available. They are also able to combine requests if that has been permitted by the user. Therefore, they find ways to eliminate the risks associated with the dependencies.
Performing Code Reviews
Code is the sole determinant of an application’s behavior, and errors in the code are the root cause of security flaws. If these vulnerabilities were to be sent to production, they might create a wide variety of problems, such as SQL injection, and could even compromise the infrastructure of the entire organization. Because of this, it is absolutely necessary to use the shift-left technique before putting code into production.
A significant number of SAST tools are being utilized by organizations for the purpose of deploying code reviews. These code review tools perform an in-depth analysis of the code before it is added to any repository. If the code has any of the known vulnerabilities, they will not allow it to be deployed until the flaws have been fixed. Therefore, it is useful for the shift-left strategy, which is based on the concept of remedying a vulnerability as soon as it is discovered, and only pushing secure code into production.
There is a large variety of softwares available on the market, and some of them enable companies and other organizations to patch their code as soon as security flaws are found. The patch can be deployed with just a few mouse clicks, and there are often several distinct options available to choose from when fixing a particular vulnerability.
Secret Scannings
These days, application are dependent on a significant amount of integration, such as payment gateways, error detection, and so on. In most cases, these APIs will execute, and authentication will be carried out using the API key and the secret.
These keys ought to be required to have an adequate level of security, such as the Live API key for Stripe payment needing to have an adequate level of protection. If this information is leaked, anybody can access the sensitive payment data and withdraw or view it. As a result, several businesses have begun using secret scanning tools.
These tools basically go through the code to see whether it contains any of the known API keys; if it does, the tool prevents the code from being published into production. It is possible for the code review tool itself to provide these features. Alternatively, an organization may easily write their own proprietary tool in order to identify problems of this kind.
Since companies are now transitioning to a shift-left strategy, they are employing SAST tools, which, in a nutshell, discover vulnerabilities as soon as they are coded and fix them. This is causing the shift left approach to become increasingly popular. If the code has any flaws that could be exploited by malicious actors, the deployment will be blocked until the problems are fixed.
Companies now have access to a wide variety of different methods, such as dependency management tools, secret scanning tools, and so on, which not only produce the proper secure code deployment but also produce the proper patches for vulnerabilities as soon as they are discovered in the coding phase.
Machine translation has come a long way since it was first developed in the 1950s. It’s said that the machine translation market will have a compound annual growth rate of 7.1% from 2022 to 2027. Neural machine translation is the latest development in this sector.
Today, we will discuss Neural Machine Translation (NMT) and how it’s a key player in software localization. If you’re interested in how NMT and post-editing translation can speed up the localization process in software while ensuring its quality, then keep on reading!
What is Neural Machine Translation (NMT)?
But before we continue our discussion, let’s define Neural Machine Translation (NMT). Unlike previous iterations of machine translation, NMT runs under a neural network that uses artificial intelligence when translating text. The neural networks mimic a human brain in the way. The neurons do machine learning and interpret several languages quickly as each network is used for different processes. It makes the translation process very efficient.
Past machine translations ran under rule-based or statistical-based programming, so when it predicted the sequences of a translated sentence, the output would be more rigid and contain more inaccuracies. NMT systems don’t experience the same issues as they can be trained to process large quantities of data from previous translations conducted by human translators. This is one of the reasons that marketers use big data to aid in translating content.
Due to how advanced NMTs are, many fear that they will replace human translators. However, like with any technology, they’re not perfect. It’s been reported that NMTs “hallucinate” because even if the translated text sounds natural, it can make errors in the information it supplements.
For example, in the translated text it contains wrong dates or inaccurate information due to how the NMT processed the data from the internet or from previous encounters on the subject matter. This is why scientists call this phenomenon “hallucinating.” It’s also why many experts in the translation industry recommend incorporating post editing translation when you use NMT to translate or localize content.
Why Software Localization is Important for Any Software Company Seeking to Enter a New Market
Despite what many people think, the internet’s language isn’t English. Over the years, with more markets becoming more available on the internet, it has become more multilingual due to our globalized and digitalized economy.
Because of this, it’s not surprising that many companies across various industries have begun to make their businesses more available in several languages. We’ve listed some data and information that support these claims:
Around 360 million out of 7.2 billion are native English speakers, making up only 5% of the world’s population. (Twistedsifter)
76% of online buyers said that they prefer reading information about products in their native language. (CSA Research)
Japanese users reported to be less likely to engage with content that’s not in Japanese, and about 1 out of 7 said they use online translation tools weekly as they browse the internet. (Data Reportal)
About 6 out of 10 Columbian users said they used translation tools weekly, as Latin Americans were reported to likely use online translation tools while browsing the internet. (Data Reportal)
The Chinese content found online only makes up 2.8% of the internet even though there are about 988.99 million Chinese users. (The Translation People)
If you were to translate or localize your software to these 4 countries: the US, Germany, China, and Japan will give your business access to 50% of the global economy’s sales,increasing 80% of the global purchasing power. (Translated)
Despite having a population with high English proficiency, 80% of Sweden’s online shoppers still prefer buying in Swedish rather than English. (Oneskyapp)
For this reason, many software companies are investing in localizing their software and business due to the opportunities it presents.
What is Software Localization? It’s adapting an app or software’s user interface for a target market. It’s not just translating the content but making it feel natural like a native speaker created it. It’s achieved through creating content based on your target users’ cultural and linguistic preferences.
In the past, software localization took a significant amount of time to ensure its quality. Even though companies started using machine translation, solely relying on it wasn’t an option as its output contained several inaccuracies and mistranslations.
But with the rise of NMT, many are seeking to use this new technology in the software industry to quickly localize software and ensure its quality due to its artificial intelligence program. The development of these advancements led to a rise in educating and training translators in machine translation post-editing, which we will discuss later in the article.
How Translators are Using NMTs to Accelerate Software Localization
Because of its advanced neural network systems, many software companies use Neural Machine Translation because they can be tailored for specialized industries and market research sentiment analysis. There are free neural translation engines that you can use, like Google Translate, Microsoft Translator, and DeepL Pro. After having it translated by an NMT, you will need post-editors to check and edit for any inconsistencies and errors in the translated text.
This process is called Machine Translation Post-Editing (MTPE). It’s when content is first translated by a machine translation engine and then edited by a human translator or linguist. Some have considered it a “cyborg solution” to the increasing demand in the translation industry, as MTPE blends both human skill and machine efficiency to give the quickest and most cost-effective to achieve high-quality translations.
When you use Neural machine translators, the two forms of MTPE that businesses commonly use:
Light post-editing – It means the editor does proofreading and fixes grammatical errors. The documents are edited at a minimal level. They are usually for internal purposes or will be used for a short period, which is why it’s needed immediately.
Full post-editing – Editors conduct a more thorough approach to proofreading and editing to ensure that the translated text is accurate. The text appears more natural and has a more cohesive tone. It also considers the cultural and linguistic aspects of the text, which often get lost when processed by machine translation.
For software localization, we advise that you do full-post editing since the localized content has to appear as natural as possible. When you localize your software, there are about four things to look out for when using NMT for MTPE:
Choose a suitable NMT engine to use.
Train your NMT Engine so it can handle the kind of content you will be translating or localizing.
Employ a native translator for post-editing machine translation.
Pre-edit the source text and simplify it because NMT works better when the text isn’t convoluted and complex.
7 Tips that You Should Know about Software Localization
In our research, we have listed seven things you have to consider when localizing software.
1. Internationalization coding is vital
Internalization is when you strip away several elements that are tied to software, like the location or language. It involves adapting the software to your target market by considering the i18n code by reviewing your application framework to see if it can be supported by localization software.
2. Use Dynamic UI Expansion
Depending on the language you’re targeting, you might have to change it from having the format of UI have the text readable from right to left or top to bottom. Using dynamic UI expansion ensures that the text fits your iOS no matter what language.
3. Prepare String Extraction and Resource File Program
You will need to do string extraction and localize them before reinserting them into the code. Unicode helps encode a script for a language. After you have extracted the strings, you can have it processed through an NMT engine and have a native translator localize and post-edit it. Just be sure that when you do string extraction, it is within a resource file that’s compatible with the localization management software you’re using.
4. Try Out Localization Management Tools
If you have decided to localize your software on your own, we suggest that you look for localization management tools and platforms out there that you can use so that it will be easier to manage and you can better implement your agile software development strategy.
Here’s a list of well-known localization management platforms that you can use:
Lokalise
Smartling
Crowdin
Locize
Smartcat
Wordbee
POEditor
5. Conduct Localization Testing
Just like using tools and hiring professionals to conduct quality assurance for your software, you will also need to do localization testing.
It means you will need to do the following things to ensure the quality of your localized software:
Do verification testing and tryout the basics of your software.
Plan out your testing and how you will process your analysis based on what you have gathered.
We suggest you do the initial testing phase, evaluate specific use cases from your software, and do regression testing to identify if it has any bugs.
After you’ve done all that, you will need to create a report to document and provide references for future projects.
6.Have Local User Testers
Your target users are the best judge of whether you have successfully localized your software. Because of this, before you launch your software, you have it tested by local users. The sample size as your target locale will provide insight into the UI and UX of your software, like areas that worked and parts that need more improvement.
The feedback you get will provide a better perspective of your target users and how your business or software can better aid them.
7. Hire Professionals in Software Localization on NMT
If you can’t work on the localization of your software, you can always hire professionals in software localization and NMT. Outsourcing the task of software localization might seem risky, but it’s one of the most efficient ways to ensure its quality. You might not have the time or resources to do everything on your own so delegating the task to an agency specializing in software localization through MTPE is your best bet.
When selecting an agency or team that you will outsource software localization:
Check their credentials. Like how many years have they been doing software localization? Are they ISO certified to provide MTPE services?
Plan Ahead. Create a strategy and invest time and money in localizing your software projects.
Assign Outsourcing Roll. Have someone from your company be assigned to work with your outsourcing partners and work things with them to ensure there’s no miscommunication between you and your partners.
Have a Management Procedure. This means creating an efficient way to collect and send feedback to ensure that projects don’t get delayed and the software is properly localized.
Final Thoughts
For any software company seeking to expand internationally, they must make their software available in more than one language. Translating and localizing content has become quicker than ever before with NMT. However, like with any technology, it’s not perfect.
By implementing the MTPE process in software localization, you get the best out of NMT solutions and the expertise of native translators. Hopefully, the tips and advice provided in this article will be helpful when you get started in localizing your software.
In today’s digital world, businesses need to be able to access and analyze their data quickly and efficiently. Streamlining business data is an important part of achieving maximum efficiency. By streamlining your business data, you can save money and increase productivity with less overhead. Whether you’re running a small business or a large-scale multinational company, your data is an important part of your daily operations. In the business world, accessing real-time information related to your customers, operations, finances, and more allows you to make informed decisions that can greatly impact your business’s success. However, managing all that data can be a challenge. Fortunately, there are steps you can take to streamline your data and make it easier to manage.
Let’s look at five ways you can do this.
1. Analyze Your Data
Before you can make sense of the data you have, it’s important to analyze and understand it. This will help you know where your data is coming from, what it covers and how valuable it is for your business.
By taking a closer look at the numbers, you can identify trends and insights to help inform decisions about using the best data. A great way to start analyzing your data is to create a dashboard of key performance indicators (KPIs). KPIs are metrics tracked over time to measure the progress of a specific goal. This could include sales, customer satisfaction scores, engagement on social media, and website traffic. By tracking KPIs regularly, you can gain deeper insight into your business and make more informed decisions about how to use data in the future.
2. Use Cloud Computing
Cloud computing can be a game-changer for businesses of all sizes, as it allows you to store and access your data remotely from any device with an internet connection. This saves time and eliminates the need for costly hardware purchases or upgrades. When considering cloud computing, think about your data type and how you plan to access it. Private cloud options are available for businesses that need to store highly sensitive information, while public clouds may be sufficient for companies with more basic storage needs. Depending on your budget, many different storage solutions can help you streamline your business data.
3. Visualize Your Data
Visualizing data can be a powerful tool that helps you quickly make sense of complex or large amounts of information. There are many different ways to visualize data, from charts and graphs to infographics and interactive dashboards. The key is finding the format that best suits your needs and the best way to present the data in an engaging and user-friendly way. Many companies like Streamdal offer real-time monitoring and observability tools to help businesses better understand their data to make sense of your data quickly and easily. Visualizing your data can help you identify trends and anomalies, see relationships between different pieces of information, or appreciate the bigger picture.
4. Invest in Data Security
In today’s digital world, data security is more important than ever. Investing in the right tools and technologies can help to protect your data from cyber threats such as hacking or unauthorized access. This could include implementing firewalls, antivirus software, encryption methods, secure passwords, and intrusion detection systems. Additionally, it is vital to establish clear policies for data usage in the workplace and train staff on best practices for keeping sensitive information safe. These steps can help ensure that your business data is secure and protected from potential threats.
5. Automate Your Data Entry
Automating your data entry is a great way to streamline your business data. It saves you time and money and eliminates the potential for human error. When automating your data entry process, look for a user-friendly system that allows you to enter information quickly without inputting any of it manually. Many options are available on the market today, from enterprise solutions to smaller solutions for small businesses. Once you have found the best solution, please test it out before fully implementing it into your business. It will help ensure that the system is running smoothly and efficiently.
There are many ways to streamline your business data for maximum efficiency, from automating your data entry process to investing in the right security measures. Finding the right solution that fits your needs can help you save time and money and eliminate potential human errors. By utilizing these tips, you can ensure that your business is running smoothly and efficiently.
Conclusion:
Streamlining your business data can help you improve efficiency and save time, allowing you to focus on what really matters. By following the five tips outlined in this article and integrating them into your daily workflow, you can increase productivity and better manage your overall data. You will also be able to track progress more precisely, helping to make informed decisions for the future. Implementing these strategies can take some getting used to, but it is worth the effort in the long run.
The future of blockchain is here. In 2021, funding to blockchain startups skyrocketed to 713% Year-Over-Year (YoY), leading the market to reach $25.2 billion. However, blockchain isn’t solely used for banking and crypto, as many industries are guaranteed to benefit from this technology.
According latest study by Statista revealed that blockchain will grow in value relentlessly over the next decade, reaching over 39 billion U.S. dollars by 2025. Banking has become a prime location for blockchain investments, as its amount within the total industry’s overall value is approximately 30 percent of the total.
How Blockchain Will be Used in 6 Different Industries
The blockchain revolution is upon us. In the past decade, blockchain technology has revolutionized how businesses operate and interact with customers, and its potential is only just beginning to be tapped. It’s likely that in the next few years – by 2023 at least – we’ll see a massive shift towards blockchain as more industries look to harness its power. So, how can blockchain be used in business? Here’s an overview of six different industries where we’re likely to see a big impact from the blockchain industrial revolution.
The top blockchain trends of 2022 included the Metaverse, NFTs, and digital identity, but will we continue to see them in 2023 and beyond? What industries will use blockchain, and how?
1. Blockchain in Banking
Blockchain will impact banking more than any other industry. Banks like Citigroup, and Goldman Sachs are already diving into the crypto space because it promises more secure mobile payment methods. Crypto exchanges are commonplace and widely used in the United States.
The financial industry is experimenting with crypto-based crowdfunding, secure smart contracts for insurance, and non-editable wills on the blockchain. One of the most interesting ventures is P2P lending on the blockchain, which makes loans more accessible to 150 million Americans.
2. Blockchain in Real Estate
The infrastructure and energy sector will adopt blockchain over the next decade to distribute ledgers and handle more complicated construction projects. Real estate blockchain applications can be used to record, track, and transfer property deeds, land titles, liens, and much more.
In the end, blockchain can mitigate real estate fraud because it allows transparency during and after transactions. Artificial and virtual reality applications make it possible to buy virtual land, giving investors another way to diversify their portfolios (and live right next to big celebrities).
3. Blockchain in Retail
While retail businesses can use cryptocurrency as payment for items, blockchain is capable of so much more in this industry. It could decentralize the trust consumers have in businesses, as it gives buyers the power to connect to manufacturers, brands, retailers, and third-party sellers.
What’s more, blockchain technology makes it easy to monitor the food supply chain and trace issues (i.e., contamination) to the source. It can control the source and sale of regulated items, like cannabis, and crack down on gift cards or loyalty program fraud in the eCommerce sector.
4. Blockchain in Health Care
HIPAA and similar healthcare information protection laws do what they can to secure patient data, but nothing offers more protection than blockchain. Blockchain technology can share patient information across platforms securely, enabling cost-effective treatments and diagnosis.
The backend of healthcare is complex, slow, and expensive, but blockchain could speed up its processes, especially when it comes to claims management. There’s a possibility it could lead to improved healthcare before the treatment phase, as it opens the door to faster innovation.
5. Blockchain in Entertainment
Entertainment entrepreneurs can use blockchain to create smart contracts. Since they can attach a crypto wallet to said contracts, content creators will receive payment directly into their accounts rather than producers. This ensures the people who make the content get their cut.
Blockchain in entertainment is well documented. It’s used in gaming, social media, gambling, sports management, art, and photography. After 2023, we may see blockchain used in video streaming. A decentralized media streaming platform could disrupt Netflix and Youtube.
6. Blockchain in Communication
In the communications industry, blockchain will be used to collaborate and engage with different sectors. We’re seeing the rise in smart contracts in telecommunications as it automates the negotiation and implementation process, especially with international service-level agreements.
Messaging apps, like Signal and Status, are already integrating blockchain and crypto into their systems, enhancing user privacy and security. Blockchain can help verify academic credentials automatically, which shortens the interview process for schools, governments, and employers.
Conclusion:
In conclusion, blockchain technology has the potential to revolutionize a wide range of industries in 2023 and beyond. Its unique combination of distributed ledgers, consensus mechanisms, smart contracts, and cryptography create opportunities for efficient data storage and decentralization. From healthcare to finance, blockchain’s promise of secure, trustless transactions and improved data access is only beginning to be realized. As more innovative applications are developed, the potential for blockchain technology to catalyze transformation across industries will continue to expand.
Customers have been using BigQuery for their data warehousing needs since it was introduced. Many of these customers routinely load very large data sets into their Enterprise Data Warehouse. Whether one is doing an initial data ingestion with hundreds of TB of data or incrementally loading from systems of record, performance of bulk inserts is key to quicker insights from the data. The most common architecture for batch data loads uses Google Cloud Storage(Object storage) as the staging area for all bulk loads. All the different file formats are converted into an optimized Columnar format called ‘Capacitor’ inside BigQuery.
This blog will focus on various file types for best performance. Data files that are uploaded to BigQuery, typically come in Comma Separated Values(CSV), AVRO, PARQUET, JSON, ORC formats. We are going to use two large datasets to compare and contrast each of these file formats. We will explore loading efficiencies of compressed vs. uncompressed data for each of these file formats. Data can be loaded into BigQuery using multiple tools in the GCP ecosystem. You can use the Google Cloud console, bq load command, using the BigQuery API or using the client libraries. This blog attempts to elucidate the various options for bulk data loading into BigQuery and also provides data on the performance for each file-type and loading mechanism.
Introduction
There are various factors you need to consider when loading data into BigQuery.
Data file format
Data compression
Level of parallelization of data load
Schema autodetect ‘ON’ or ‘OFF’
Wide tables vs narrow(fewer columns) tables.
Data file format
Bulk insert into BigQuery is the fastest way to insert data for speed and cost efficiency. Streaming inserts are however more efficient when you need to report on the data immediately. Today data files come in many different file types including Comma Separated(CSV), JSON, PARQUET, AVRO to name a few. We are often asked how the file format matters and whether there are any advantages in choosing one file format over the other.
CSV files (comma-separated values) contain tabular data with a header row naming the columns. When loading data one can parse the header for column names. When loading from csv files one can use the header row for schema autodetect to pick up the columns. With schema autodetect set to off, one can skip the header row and create a schema manually, using the column names in the header. CSV files can use other field separators(like ; or |) too as a separator, since many data outputs already have a comma in the data. You cannot store nested or repeated data in CSV file format.
JSON (JavaScript object notation) data is stored as a key-value pair in a semi structured format. JSON is preferred as a file type because it can store data in a hierarchical format. The schemaless nature of JSON data rows gives the flexibility to evolve the schema and thus change the payload. JSON formats are user-readable. REST-based web services use json over other file types.
PARQUET is a column-oriented data file format designed for efficient storage and retrieval of data. PARQUET compression and encoding is very efficient and provides improved performance to handle complex data in bulk.
AVRO: The data is stored in a binary format and the schema is stored in JSON format. This helps in minimizing the file size and maximizes efficiency.
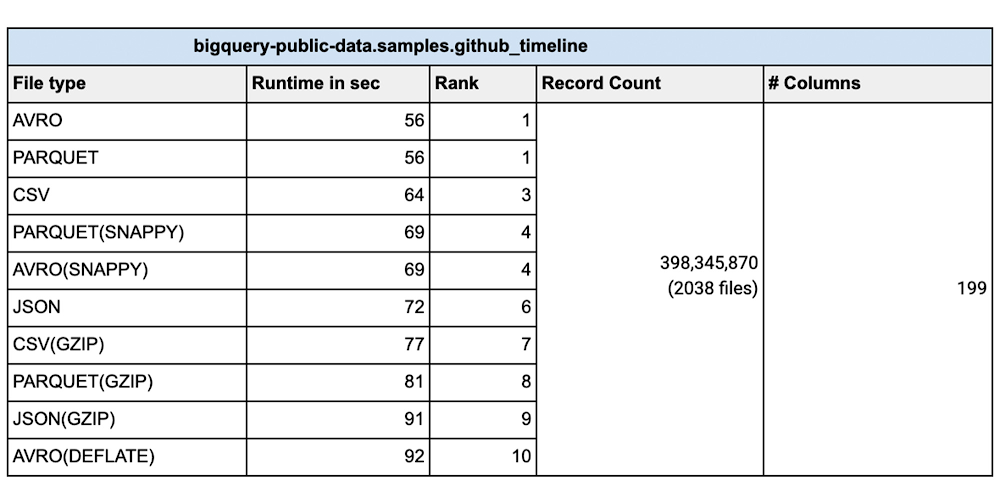
From a data loading perspective we did various tests with millions to hundreds of billions of rows with narrow to wide column data .We have done this test with a public dataset named `bigquery-public-data.samples.github_timeline` and `bigquery-public-data.wikipedia.pageviews_2022`. We used 1000 flex slots for the test and the number of loading(called PIPELINE slots) slots is limited to the number of slots you have allocated for your environment. Schema Autodetection was set to ‘NO’. For the parallelization of the data files, each file should typically be less than 256MB uncompressed for faster throughput and here is a summary of our findings:
Do I compress the data?
Sometimes batch files are compressed for faster network transfers to the cloud. Especially for large data files that are being transferred, it is faster to compress the data before sending over the cloud Interconnect or VPN connection. In such cases is it better to uncompress the data before loading into BigQuery? Here are the tests we did for various file types with different file sizes with different compression algorithms. Shown results are the average of five runs:
How do I load the data?
There are various ways to load the data into BigQuery. You can use the Google Cloud Console, command line, Client Library or use the REST API. As all these load types invoke the same API under the hood so there is no advantage of picking one way over the other. We used 1000 PIPELINE slots reservations, for doing the data loads shown above. For workloads that require predictable load times, it is imperative that one uses PIPELINE slot reservations, so that load jobs are not dependent on the vagaries of available slots in the default pool. In the real world many of our customers have multiple load jobs happening concurrently. In those cases, assigning PIPELINE slots to individual jobs has to be done carefully keeping a balance between load times and slot efficiency.
Conclusion: There is no distinct advantage in loading time when the source file is in compressed format for the tests that we did. In fact for the most part uncompressed data loads in the same or faster time than compressed data. For all file types including AVRO, PARQUET and JSON it takes longer to load the data when the file is compressed. Decompression is a CPU bound activity and your mileage varies based on the amount of PIPELINE slots assigned to your load job. Data loading slots(PIPELINE slots) are different from the data querying slots. For compressed files, you should parallelize the load operation, so as to make sure that data loads are efficient. Split the data files to 256MB or less to speed up the parallelization of the data load.
From a performance perspective AVRO and PARQUET files have similar load times. Fixing your schema does load the data faster than schema autodetect set to ‘ON’. Regarding ETL jobs, it is faster and simpler to do your transformation inside BigQuery using SQL, but if you have complex transformation needs that cannot be done with SQL, use Dataflow for unified batch and streaming, Dataproc for streaming based pipelines, or Cloud Data Fusion for no-code / low-code transformation needs. Wherever possible, avoid implicit/explicit data types conversions for faster load times. Please also refer to Bigquery documentation for details on data loading to BigQuery.
To learn more about how Google BigQuery can help your enterprise, try out Quickstarts page here
Disclaimer: These tests were done with limited resources for BigQuery in a test environment during different times of the day with noisy neighbors, so the actual timings and the number of rows might not be reflective of your test results. The numbers provided here are for comparison sake only, so that you can choose the right file types, compression for your workload. This testing was done with two tables, one with 199 columns (wide table) and another with 4 columns (narrow table). Your results will vary based on the datatypes, number of columns, amount of data, assignment of PIPELINE slots and various file types. We recommend that you test with your own data before coming to any conclusion.
Today, millions of users turn to Looker Studio for self-serve business intelligence (BI) to explore data, answer business questions, build visualizations and share insights in beautiful dashboards with others. Recently, we introduced enterprise capabilities, including the options to manage team content and gain access to enterprise support, with Looker Studio Pro.
Looker Studio Pro is designed to support medium and large scale enterprise environments, delivering team-level collaboration and sharing, while honoring corporate security and document management policies – all at a low price per user.
Looker Studio Pro empowers teams to work together on content, without worrying about visibility and manageability issues that can arise with self-serve BI. So, the next time you want to onboard a new hire and give them access to fifty BI reports at once, or want to know the downstream impact of deleting a BigQuery table on your reports, or get admin permissions to all reports in your organization, Looker Studio Pro enables you to do so in a matter of minutes. You also no longer need to go through ownership transfers every time an employee leaves the organization, since all assets are owned by the organization. Plus, Google Cloud’s support and service level agreements ensure you have the help you need available when you need it.
Let’s take a deeper dive into the benefits of Looker Studio Pro:
Bulk manage access to all content in Looker Studio
Team workspacesenable team collaboration in a shared space. Team workspaces provide new roles for granular permissions to manage content and manage members inside a team workspace.
A team workspace can be shared with individuals or Google Groups by adding members and assigning roles to the members of a team workspace. When you create new content in a team workspace or move existing content into a team workspace, all the members of that team workspace get access to that content.
The specific permissions provided depend on which role a user is granted, including Manager, Content Manager or Contributor. For a full list of detailed permissions aligned with each role, see our help center.
Additionally, with Looker Studio Pro, if employees leave the company, you no longer need to transfer ownership for assets they create. The organization owns content created in Looker Studio Pro, managed through the Google Cloud Platform project by default.
Get visibility across the organization
You can now link a Google Cloud project to Looker Studio, so everything that people in your organization create is in one place that you control.
Grant administrators permission to view or modify all assets in your organization using Identity and Access Management (IAM) — meaning no more orphaned reports or access headaches.
We are also working to bring Looker Studio content into Dataplex, so you can understand your company’s full data landscape in one place – including seeing how Looker Studio reports are linked to BigQuery tables. With Dataplex, you can better understand how Looker Studio and BigQuery connect, run impact analysis and see how data is transformed before it is used in reports. Integration with Looker Studio and Dataplex is currently in private preview, so reach out to your account team to learn more.
With these new integrations, we are making all the tools you need work better together, so you can realize the full value of your data cloud investments.
Support
Looker Studio Pro customers receive support through existing Google Cloud Customer Care channels so you can rely on Looker Studio Pro for business-critical reporting.
Getting started and next steps
If you are already a Google Cloud Platform customer, speak to your account team to sign up and get access today. Otherwise, complete this form to be notified when you can sign up for Looker Studio Pro.
We’re excited to announce that the Pub/Sub Group Kafka Connector is now Generally Available with active support from the Google Cloud Pub/Sub team. The Connector (packaged in a single jar file) is fully open source under an Apache 2.0 license and hosted on our GitHub repository. The packaged binaries are available on GitHub and Maven Central.
The source and sink connectors packaged in the Connector jar allow you to connect your existing Apache Kafka deployment to Pub/Sub or Pub/Sub Lite in just a few steps.
Simplifying data movement
As you migrate to the cloud, it can be challenging to keep systems deployed on Google Cloud in sync with those running on-premises. Using the sink connector, you can easily relay data from an on-prem Kafka cluster to Pub/Sub or Pub/Sub Lite, allowing different Google Cloud services as well as your own applications hosted on Google Cloud to consume data at scale. For instance, you can stream Pub/Sub data straight to BigQuery, enabling analytics teams to perform their workloads on BigQuery tables.
If you have existing analytics tied to your on-prem Kafka cluster, you can easily bring any data you need from microservices deployed on Google Cloud or your favorite Google Cloud services using the source connector. This way you can have a unified view across your on-prem and Google Cloud data sources.
The Pub/Sub Group Kafka Connector is implemented using Kafka Connect, a framework for developing and deploying solutions that reliably stream data between Kafka and other systems. Using Kafka Connect opens up the rich ecosystem of connectors for use with Pub/Sub or Pub/Sub Lite. Search your favorite source or destination system on Confluent Hub.
Flexibility and scale
You can configure exactly how you want messages from Kafka to be converted to Pub/Sub messages and vice versa with the available configuration options. You can also choose your desired Kafka serialization format by specifying which key/value converters to use. For use cases where message order is important, the sink connectors transmit the Kafka record key as the Pub/Sub message `ordering_key`, allowing you to use Pub/Sub ordered delivery and ensuring compatibility with Pub/Sub Lite order guarantees. To keep the message order when sending data to Kafka using the source connector, you can set the Kafka record key as a desired field.
The Connector can also take advantage of Pub/Sub’s and Pub/Sub Lite’s high-throughput messaging capabilities and scale up or down dynamically as stream throughput requires. This is achieved by running the Kafka Connect cluster in distributed mode. In distributed mode, Kafka Connect runs multiple worker processes on separate servers, each of which can host source or sink connector tasks. Configuring the `tasks.max` setting to greater than 1 allows Kafka Connect to enable parallelism and shard relay work for a given Kafka topic across multiple tasks. As message throughput increases, Kafka Connect spawns more tasks, increasing concurrency and thereby increasing total throughput.
A better approach
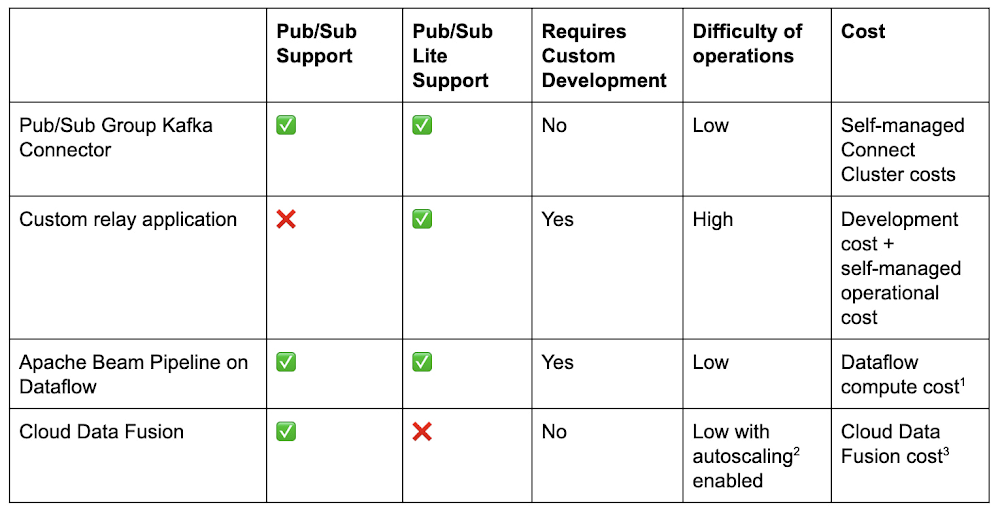
Compared to existing ways of transmitting data between Kafka and Google Cloud, the connectors are a step-change.
To connect Kafka to Pub/Sub or Pub/Sub Lite, one option is to write a custom relay application to read data from the source and write to the destination system. For developers with Kafka experience who want to connect to Pub/Sub Lite, we provide a Kafka Shim Client that can make the task of consuming from and producing to a Pub/Sub Lite topic easier using the familiar Kafka API. This approach has a couple of downsides. It can take significant effort to develop and can be challenging for high-throughput use-cases since there is no out-of-the-box horizontal scaling. You’ll also need to learn to operate this custom solution from scratch and add any monitoring to ensure data is relayed smoothly. Instead there are easier options to build or deploy using existing frameworks.
Pub/Sub, Pub/Sub Lite, and Kafka all have respective I/O connectors with Apache Beam. You can write a Beam pipeline using KafkaIO to move data between a cluster Pub/Sub or Pub/Sub Lite and then run it on an execution engine like Dataflow. This requires some familiarity with the Beam programming model, writing code to create the pipeline and possibly expanding your architecture to a supported runner like Dataflow. Using the Beam programming model with Dataflow gives you the flexibility to perform transformations on streams connecting your Kafka cluster to Pub/Sub or to create complex topologies like fan-out to multiple topics. For simple data movement especially when using an existing Connect cluster, however, the connectors offer a simpler experience requiring no development and low-operational overhead.
No code is required to set up a data integration pipeline in Cloud Data Fusion between Kafka and Pub/Sub, thanks to plugins that support all three products. Like a Beam pipeline that must execute somewhere, a Data Fusion pipeline needs to execute on a Cloud Dataproc cluster. It is a valid option most suitable for Cloud-native data practitioners who prefer drag-and-drop option in a GUI and who do not manage Kafka clusters directly. If you do manage Kafka clusters already, you may prefer a native solution, i.e., deploying the connector directly into a Kafka Connect cluster between your sources/sinks and your Kafka cluster, for more direct control.
To give the Pub/Sub connector a try, head over to the how-to guide.
Recruitment faced a large transformation, starting with moving from job boards posted in the newspaper or on bulletin boards to AI boosting the online process of finding jobs. The majority of companies now use artificial intelligence and machine learning to energize the process of recruitment online.
As mentioned above, most job listings are found online on job search sites such as Lensa. This has created a whole new reliant relationship between technology and those who use it. This reliance is for finding a workplace, in other words, surviving in the economy. Today we will look at how AI has made job recruitment what it is today: efficient, accurate, and engaging.
How is AI Used for Recruiting?
Essentially, what artificial intelligence has done to the world of recruitment is automate it to become more efficient. The once time-consuming task of repeatedly scouring through resumes and looking for key aspects has been greatly reduced to mere seconds per resume. It can be said this software was trained to function in place of a human for daunting, repetitive tasks.
The benefits of using a program instead of a human for these tasks are many. Namely, AI has high amounts of data processing power at its disposal, making it far more efficient and accurate at the repetitive tasks a recruiter would be burdened with. This doesn’t mean machines have replaced recruiters, though, since people are still needed to oversee the process and hold interviews.
The automation AI provides makes complex, repeated problems solvable through algorithmic bases. It also allows teams to find passive candidates and attempt to keep them engaged, as well as gather insights that are purely based on data without any biases. The mechanical decision-making ability of AI is what makes it such a useful tool for recruitment.
Building the most adequate team for a company isn’t easy, but artificial intelligence for recruitment is here to make the process as fast, accurate, and successful as possible.
The Difference Between Machine Learning and AI
Artificial intelligence is the umbrella program to run the element of machine learning. Machine learning does the tasks and training, while AI olds all the processes.
What Effects and Innovation Does AI Provide?
Having AI be a part of the recruiting process increases the competitive nature of job finding while being efficient. Work teams thriving is what this approach achieves, thus why it has become highly integrated into the job market. Let’s also look at the different innovative benefits AI can bring to recruitment.
Automating processes
The streamlining of the previously-mentioned tedious tasks is what makes AI such a leader in recruitment. From the speed it provides teams to its accuracy, there is no doubt as to why it got popular so fast.
This automation simplifies scheduling by using calendar integration as well as AI chatbots to skip the need for painstaking scheduling issues. It also screens and ranks candidates better and sources candidates that would suit the job description best.
Intelligent screening software
This automation happens through intelligent screening software that uses AI. The software screens candidates to see which one of the candidates went on to be a successful employee The software checks turnover rates and performance from the candidate’s history.
Chatbots
The recruiter chatbots save recruiters time while simulating real-time interaction between candidates and the job post. The reason these bots prove useful is for their improvement of user experience. Lots of companies skimp on replying to candidates whether they’re hired or not, which is a practice that is solved by chatbots.
Digital interviews
Interviewing can also be done digitally through the scheduling done by chatbots. Artificial intelligence now also has the power to analyze facial expressions, voices, and speech patterns used by candidates during interviews to assess whether the candidate is likely to be a successful fit for a team.
The Outcome of AI Recruiting
The average day of a recruiter now is more proactive than it has ever been, thanks to the innovative software they can use. This means more time is being spent on more important tasks, such as building personal relationships with candidates and focusing on the data insights the software provides to smooth the processes that happen with hiring managers.
It has been shown that the quality of hire has increased, not the quantity, making AI the best solution for recruitment we know of currently, and it continues to find new uses.