Cloud technology is changing the state of the healthcare sector. A number of hospitals are using the cloud for a variety of purposes, including improving data scalability, offering employees the opportunity to work remotely and improving patient engagement.
Due to these many benefits, healthcare organizations are expected to spend over $128 billion on cloud services this year. Patient engagement is one of the biggest reasons healthcare companies are investing in cloud computing. Keep reading to learn why cloud technology is becoming vital for hospitals and clinics trying to maintain stronger relationships with customers.
Cloud Computing Pays Huge Dividends for Companies Trying to Boost Patient Engagement
The term “patient engagement” is used to describe a scenario in which patients are actively involved in making decisions about their health care and are aware of and actively participating in all aspects of their treatment, recovery, medication, and other related systems.
According to the Healthcare Information and Management Systems Society (HIMSS), patient engagement occurs when “providers and patients work together to improve health.” Furthermore, it is claimed that people who actively participate as decision-makers in their medical care are healthier and experience better health outcomes.
The use of information technology has the potential to play a more significant role in fostering such patient participation. Cloud technology, wearables, mobile applications, patient portals, and smart devices are just a few examples of the technology being used by healthcare facilities to educate and involve their patients.
The benefits of cloud computing for improving patient engagement cannot be overstated. A 2014 study published in The Journal of Medical Practice Management discussed some of the benefits of using cloud technology to make things easier for patients.
“A patient portal is a cloud-based application that allows secure, confidential, and efficient access to personal medical information and communication between patient and provider,” the authors write.
The Current State of Health IT and the Challenges in Patient Engagement that Cloud Computing Can Address
There are many benefits of using cloud technology to improve patient engagement. However, before we can delve into them, it is important to address some of the challenges with patient engagement.
Patients are becoming knowledgeable when it comes to technology and want constant instruction and help from their healthcare providers throughout the duration of their treatment. They can use cloud technology to facilitate this, since many healthcare portals are accessible via private cloud networks.
The healthcare sector recognizes this truth and has started to invest enormously in developing patient investment strategies and solutions. Many novel patient engagement tactics are employed to suit the demands of the patients, which can be optimized through cloud computing. However, there are a few operational and implementation problems that hold down the overall process.
Cultural change — The difficulty in changing from the conventional behavioral patterns to the new system is sometimes an obstacle to successful patient involvement.
Lack of preset parameters – There is a fair bit of ambiguity regarding patient participation and how to execute it in order to obtain the intended results.
Lack of evidence — It makes more sense if healthcare professionals have an evidence-based measurement of patient engagement. As of today, there is no evidence-based procedure which is often a burden for the administration.
Ignorance – The patient’s demographics and health literacy are important factors in successful patient engagement, but few people realize this. Their technological literacy is also an important consideration.
Patient’s view — Many times, the patient will have predefined conceptions that their position and status are subordinate to the medical experts.
Workers’ resistance – The success of patient engagement initiatives is heavily dependent on the education and outlook of the healthcare staff.
Fortunately, cloud technology can address many of these problems by making essential information more accessible to both patients and staff.
The Importance of Patient Participation in Healthcare
In this scenario, a patient has been diagnosed with a long-term illness such as COPD (COPD). The patient may know nothing about the illness at all, may know a little bit about it from various media sources, or may know a lot about it through close relatives or friends who are also afflicted.
As part of the standard practice, doctors have always explained the patient’s problem and prescribed treatment. Hypothetically, the healthcare service provider may provide a pulse oximeter for use by the patient or carer to track blood oxygen levels independently at home. As a result, they will be able to keep better tabs on their health and better control their COPD. Also, both the doctor and the patient will save time by not having to schedule as many checkups. In addition, the patient can participate in community activities using modern media to increase their understanding of how to manage COPD effectively.
A straightforward and practical illustration of the value of patient participation in healthcare. At this pivotal moment in healthcare history, patients are gaining the ability to play an increasingly important role in both the decision-making process and the delivery of their care.
All healthcare workers have a responsibility to do their best for each patient they treat. Increased participation from patients is essential to enhancing health outcomes. Patients who are actively involved in their care are more likely to take an active interest in their health, adhere to treatment regimens, and experience positive outcomes. For this reason, 70% of doctors say that encouraging patient participation is a major priority in their practice. Engaging patients is helpful for both the healthcare providers and the patients themselves.
The idea of patient engagement might be compared to that of consumer engagement or customer satisfaction in commercial settings. More broadly, it encompasses a range of resources, activities, and procedures designed to aid both healthcare professionals and patients in making well-informed decisions. Find out why and how patient participation helps everyone involved in this article.
Future of Patient Engagement in Healthcare Relies on the Cloud
The focus in healthcare has typically been on doctors and hospitals. It ignored the importance of people as active participants in their own health care. Patient participation is essential in the modern healthcare system, which has shifted its focus to a value-based system. According to Deloitte’s recent Global healthcare outlook report, medical professionals all over the world are exploring new, more efficient ways to provide high-quality, patient-centered care that makes use of cutting-edge technological advancements, both inside and outside of traditional healthcare facilities.
Experts agree that improved patient outcomes can be achieved by putting responsibility for one’s health in the hands of the patient. In addition, it has been demonstrated that patient involvement is critical to the sustainability of healthcare systems.
One needs a well-defined plan that revolves around the organization’s vision if patient involvement is to be successful. Improved and individualized patient communication is key to achieving these goals, so it’s important to use the appropriate technology and tools. As a result, it’s important to work with a healthcare provider that has experience developing patient management solutions.
Therefore, companies are going to need to find creative ways to incorporate cloud technology into their patient engagement models.
Cloud technology has led to a number of amazing benefits for companies all over the world. Therefore, it is hardly surprising that global companies are projected to spend over $1.2 trillion on cloud solutions in 2027. One of the many reasons companies are utilizing cloud technology is that it allows them to take advantage of remote working opportunities.
As more businesses take advantage of the benefits of cloud technology, they are able to use remote workers to provide a number of services that previously required workers that were onsite. Virtual receptionists are among the workers that are currently able to assist companies offsite through the use of cloud technology.
But are virtual assistants actually useful? How does cloud technology help them serve their employers or clients?
Cloud Technology Helps Virtual Receptionists Offer Excellent Value to Customers Around the Globe
When missing a single phone call can cost your business £1,200 on average (at least according to BT Business), you must be able to answer calls professionally. But when you’re a small business or working for yourself, that’s not always easy.
If you’re with a client, in a meeting, travelling, working on a project, or even just accidentally miss the call because you don’t hear your phone ringing, you’re potentially losing money.
Using BT Business’ estimate as a baseline, even missing one call a week could cost your business £62,400.
Miss one a day (not even counting the weekend), and you’re looking at an average of £312,000 lost a year.
The good news is that cloud technology has made it easier than ever for receptionists to handle these tasks from afar. Many virtual receptionist services talk about the benefits that cloud computing brings to their business models. They point out that the cloud has helped them maximize the uptime of their call service models and connect to customers anywhere in the world.
You might have heard of virtual receptionists before. However, you might not have thought about the benefits that they can bring to your organization as they use cloud technology to engage with your customers.
They work the same way an office receptionist would, dealing with incoming calls and handling customer enquiries efficiently and professionally. Whether that’s taking messages, transferring calls to the correct team member, or sometimes providing answers to customer questions directly. They can also help with some of your business admin, like diary management and booking meetings.
But is it really worth investing in a virtual receptionist? And what benefits can you expect to see if you do?
Let’s find out.
How Does Cloud Technology Help Virtual Receptionists Do their Job?
The cloud helps receptionists serve their clients in a variety of ways. The biggest way that virtual receptionists use the cloud is through cloud telephony. You can learn more about this practice on TechTarget.
Cloud telephony essentially allows people to place calls anywhere they have an internet connection through the use of cloud interfaces. Receptionists are effectively able to take and place calls anywhere, as long as they have internet access.
The cloud also helps receptionists store data about customer messages. They may even store recordings on the cloud, provided they have received consent.
What Are the Benefits of Using Virtual Receptionists that Operate Over the Cloud?
You should have a better understanding of the technical aspects of virtual receptionists using cloud technology. However, you might still not appreciate the benefits of their services. You can learn more below.
Never Miss Another Call
Try as you might, it can be impossible to answer every call yourself, or to have your team answer it. Sometimes you just can’t get to the phone.
And as we’ve discussed, that can be costly.
With a virtual receptionist, you don’t need to worry about these missed calls because they’ll handle them all for you.
So whether you’re with another client, travelling, or simply need a break in the day to recharge, you can do so without worrying about missing calls and losing money while you’re away.
Keep your business open for longer
If your customers can’t call you during regular office hours (for example, because they’re at work themselves), you have a few options.
Let the calls go to an answering machine and hope the customer leaves a message.
Extend your business hours and work longer.
Or, you could use a virtual receptionist to deal with out-of-hours calls.
This allows your business to stay open for longer and deal with more customers without you or your team needing to work all hours of the day.
Even if the customer’s issue can’t be resolved on that first call, they’ll be reassured that they’ve spoken to a real person and that their enquiry has been logged properly.
Professionalize your call answering
It’s not just enough to answer customer calls. Every call needs to be handled professionally to maintain customer service and protect your business’ reputation.
But when you or your team is stressed, running around, and busy, it can be easy to sound harried on the phone or give the impression the caller is an inconvenience you’re trying to get rid of quickly.
You don’t need to worry about this with a virtual receptionist.
Virtual receptionists can deal with all your calls professionally and efficiently and take as much time as it takes to get the customer’s details or provide them with information.
Answer more than one call at once
If you need professional call handling, you might be tempted to hire an office receptionist and have a single person answer the phone.
And there can still be a place for that.
But the problem is, as soon as your receptionist is on the phone, they can’t deal with another call when it comes in.
And calls tend not to come one at a time, so you could very quickly find yourself without your professional call handling.
Virtual receptionists work in teams to answer your calls and can cover each other when one is dealing with a call or has gone on a break.
This means you can deal with every call that comes into your business.
Save on hiring and employment costs
Again, you might be tempted to hire a full-time receptionist to sit behind a desk and deal with calls.
But hiring full-time staff members is expensive (especially when you consider that they can only handle one call at a time, as we’ve already mentioned).
An experienced receptionist can cost anything up to – and above – £30,000, and hiring a receptionist with specific industry experience can be even more expensive.
Not to mention all the additional costs of tax, insurance, holiday pay, sick pay, pension etc and the administration that comes with employment laws and regulations.
With a virtual receptionist service, you only need to pay for the time or volume of calls you need, so the price is considerably lower, and you get a more comprehensive phone answering service.
Have opportunity to scale
Another reason a virtual receptionist service can be a better choice than a full-time receptionist is the scalability of your call handling.
If your receptionist struggles with the number of calls they have to deal with, what are your options?
It’s likely you or your team will have to deal with the overflow of calls – which is what your receptionist is supposed to stop from happening.
Or you could hire another receptionist. But again, that’s expensive, and then there’s the time to train your new hire. Then if things quieten down later, you’ve got an extra employee with nothing to do.
A virtual receptionist service is much more scalable.
When you need more support, you can simply invest more hours and instantly have more resources at your disposal. When things calm down, scale back your investment.
Improve business processes with a virtual receptionist
Virtual receptionists are a perfect addition to modern offices.
With more employees working fully remote or hybrid and more businesses being based out of co-working spaces or having no physical office space, having a virtual receptionist ensures your employees and customers can remain connected.
Far from being just a tool for answering calls, a virtual receptionist service can be scaled to create an outsourced switchboard and diary management function, allowing you to get on with completing projects and helping customers without worrying about missing calls.
Discover the Benefits of Working with Virtual Receptionists Over the Cloud
Cloud technology has provided many benefits to businesses all over the world. One of the most overlooked benefits is that it allows virtual receptionists to take calls remotely. The advantages listed above should help you appreciate the reasons companies use their services.
With technological advancement, data revolutionizes many business processes. Experts assert that one of the leverages big businesses enjoy is using data to re-enforce the monopoly they have in the market. Big data is large chunks of information that cannot be dealt with by traditional data processing software. It needs to be analyzed with premium tech tools to deduce insights germane to user experience as well as scaling businesses. Big data analytics is finding applications in eLearning. By analyzing big data, Edutech businesses discover interesting ways to revolutionize learning as we know it.
Year after year, the volume of data in eLearning (and the need to analyze it) increases. In 2017, 77% of U.S. corporations were using eLearning, and 98% planned to adopt it by 2020. Statistics show that Edutech will have an average compound growth rate of 16.5% between 2022 and 2030. Post-pandemic, it is a fact that there is the rapid adoption of eLearning and a growing base of users. The big data market is projected to reach $325 billion by 2025.
Leap forward since the adoption of big data analytics.
Twinslash helps Edtech businesses build eLearning apps that leverage big data analytics. With two decades of experience in the industry, this software development company uses the latest technology to create solutions for SMBs and large companies. Some of their solutions include:
big data functionality capable of processing national and state-district level statistics,
AI algorithms to formulate automatic solutions,
combining data analytics tools with data visualization to show hidden and profound insights to business managers.
The Internet giants dominate the eLearning software market. Still, there’s plenty of room for startups and SMBs to launch web-based learning apps, provide corporate training functionality, or build LMS. You can carve an EdTech niche for your project with a reliable development company.
What Is Big Data in the eLearning Context?
As established earlier, big data goes beyond the volume of processed data — it’s more strategic. It shows hidden insights by intuitively collecting data sets capable of improving learning. For example, big data analytics can show demographic information of a project’s eLearning participants (the distribution across states in the country, age, etc.). This assists in understanding why a segment of the audience responds more to a set of courses. Big data analytics can also analyze what platforms people use the most to learn online. Is it a web or a mobile version? What devices are they signing in from? What features of the course get the most interaction from users? The details are collected in big analytics to present new opportunities for eLearning businesses.
5 Main Benefits of Big Data Analytics in eLearning
The benefits of big data analytics in eLearning are bi-directional. On the one hand, it helps effective data management of Edtech companies while providing useful insights to leverage for business growth. On the other hand, it keeps track of users, assesses their experience, and guides developers on how to improve it even more. The five key benefits of big data analytics in eLearning are listed below.
Showing hidden patterns and collecting relevant data. Big data analytics collects a wide range of data on eLearning platforms. As the users navigate through different interfaces of a platform, data is collected to give comprehensive analytical information on the overall usage of your service. Thus, Edtech companies are confident that they can improve the experience, get critical feedback, and be abreast of opportunities through data.
Assess performance and provide feedback. With big data analytics, teachers, educational managers, and educational content creators can receive real-time feedback about the performance of their courses. Thankfully, with big data analytics, performance goes beyond registration or the number of active learners. It can show the features they enjoy the most on your platform and what courses they choose more frequently. Suppose eLearning is the future and holds the potential to replace unnecessary on-site learning. In that case, this feedback is pertinent to the industry’s overall success.
Real-time information about the performance of students. Big data analytics affords Edtech companies the luxury of tracking individual engagement and performance of students taking courses online. Teachers and educational managers can now assess the effectiveness of their students relative to the quality of engaging content on their eLearning platforms.
Assessment and behavioral learning. Big data analytics can be used to assess learners on the eLearning platform. Even better, beyond these assessments, course creators can learn about the behavior of users and make necessary changes to help/improve their learning experience on eLearning platforms.
Analyzing the performance of individual courses. Teachers can now see real-time statistics about individual courses on their eLearning platforms. They can determine specific aspects of each course that need improvement and see whether their users understand the information.
How Big Data Analytics Influences eLearning
The influence of big data analytics on eLearning cannot be overemphasized. Ultimately, it helps Edtech content creators deliver the right content and target them to the audience that needs it the most based on previous observations. This means that users will get value for their money. In turn, Edtech companies will get immense possibilities (backed up by big data analytics) for improving their services. Through thorough assessment and data visualization of the performance of course contents, learners’ behavior and experience, big data analytics guarantees the ultimate level of service for Edtech companies leveraging this solution.
Big data analytics’ influence is two-sided as well. It will not only ensure a smooth data management process in a company but make eLearning more interesting for students. Combined with VR or AI, it can do wonders. Visual representation of ideas and concepts helps learners to memorize and understand them better, which is extremely beneficial for medical students, for example.
Big data can also make basic levels of education cheaper by eliminating the need for teachers and professors. There are numerous free apps that can be downloaded in a few clicks, and popular services like Udemy or Coursera offer free courses for everyone interested in the topic.
Conclusion
EdTech companies not using big data analytics stand more to lose than gain. The eLearning sector will definitely undergo progressive transformations when the technology will be widely adopted and studied. It offers us many ways to not only reconsider our approaches to learning but make the process itself more interesting, effective, and personalized.
Technology is quickly becoming a critical component of our existence. Today, technology powers every important aspect of our life, from business to education to medicine. It has greatly aided in the automation of formerly manual activities, making everything more smooth and efficient.
However, computerization in the digital age creates massive volumes of data, which has resulted in the formation of several industries, all of which rely on data and its ever-increasing relevance. Data analytics and visualization help with many such use cases.
It is the time of big data. Everything is driven by data in business. Here is where data analytics and visualization come into play. While most people are unfamiliar with these terms, investing in data analytics and visualization can mean the difference between success and failure.
What Is Data Analytics?
As previously said, the rise of technology is a crucial driving factor in every aspect of today’s world, which has resulted in huge data generation. Organizations cannot understand this huge amount of data without the help of the data analytics process.
Analytics is a wide phrase that includes several subfields. It encompasses all the data products, tools, and actions required in data processing to provide significant insights and interpretations. It is important to note that data analytics relies on computer tools and software to collect and analyze data so that business choices may be made properly.
Data analytics is widely used in business since it allows organizations to better understand their consumers and improve their advertising strategies. Because of the various advances, this is a highly dynamic sector.
Five Best Practices for Data Analytics
1. Select a Storage Platform
Extracted data must be saved someplace. There are several choices to consider, each with its own set of advantages and disadvantages:
Data warehouses are used to store data that has been processed for a specific function from one or more sources. Data lakes hold raw data that has not yet been altered to meet a specific purpose. Data marts are smaller versions of warehouses that are frequently devoted to a particular team or department. To support a data-intensive system, databases are frequently used to store data from a single source.
2. Prioritize
More data is available to your brand than it knows how to handle. Rather than attempting to include everything in your data analysis process, eliminate what is unnecessary. Determine which data inputs are most valuable to your brand, in other words.
Key performance indicators (KPIs) help with that. So, how KPIs assist in determining what is essential for your organization will shape much of your company’s future decision-making.
Remember that what is important to the marketing team may not be important to the sales team, which may not be important to the customer service department, and so forth. You must ensure that every department is on board because different teams will give different KPIs varying amounts of weight.
Make better business decisions using the insights given by the data you’ve acquired and evaluated. These judgments should not feel like guesses but rather cold, calculating movements based on data.
This is all about customer data management, which we’ll go into in depth later. For the time being, all you need to know is that data segregated in separate systems and platforms is data squandered. Mining various data sources for useful insights is both challenging and inefficient. What you need for your brand is a truly unified data management platform that allows you to understand customers on an individual level and take smart, decisive action.
3. Real-time AI Revision and Optimization
You may alter and improve your brand’s interaction with specific customers in real time by implementing artificial intelligence and machine learning into your procedures for managing and analyzing customer data.
A self-correcting user experience powered by AI and machine learning data analysis has tremendous advantages. Personalized, pertinent interactions will make it possible to boost short- and long-term sales volume, per-sale value, customer pleasure, customer retention, and many other factors.
4. Understand Your Audience
It is critical to keep your audience in mind while developing visualizations. Please answer the following questions: Who will be reviewing the data? What difficulties does the audience face? How can dashboards help them overcome obstacles? Resist the urge to create generic dashboards and instead make sure they meet the needs of decision-makers.
To capture attention, make sure that vital sections are emphasized. You have the option of placing crucial data points in popular regions.
Increase dwell time and facilitate better data understanding by directing attention with conditional formatting, reference lines, trends, or forecasts.
Summary
Following the best practices for customer data analysis and the recommended strategy for selecting a customer data management solution will revolutionize your organization. However, it will not revolutionize your company overnight. It takes time and work to achieve your large-scale customer-centric goals and ongoing effort to gain a deeper understanding of each client.
But if you’re ready to follow the best practices outlined in this article, this transition will occur, and your consumers will thank you later.
As a network of social businesses, NTUC Enterprise is on a mission to harness the capabilities of its multiple units to meet pressing social needs in areas like healthcare, childcare, daily essentials, cooked food, and financial services. Serving over two million customers annually, we seek to enable and empower everyone in Singapore to live better and more meaningful lives.
With so many lines of business, each running on different computing architectures, we found ourselves struggling to integrate data across our enterprise ecosystem and enable internal stakeholders to access the data. We deemed this essential to our mission of empowering our staff to collaborate on digital enterprise transformation in ways that enable tailor-made solutions for customers.
The central issue was that our five main business lines, including retail, health, food, supply chain, and finance, were operating on different combinations of Google Cloud, on-premises, and Amazon Web Services (AWS) infrastructure. The complex setup drove us to create a unified data portal that would integrate data from across our ecosystem, so business units could create inter-platform data solutions and analytics, and democratize data access for more than 1,400 NTUC data citizens. In essence, we sought to create a one-stop platform where internal stakeholders can easily access any assets they require from over 25,000 BigQuery tables and more than 10,000 Looker Studio dashboards.
Here is a step-by-step summary of how we deployed DataHub, an open-source metadata platform alongside Google Cloud solutions to establish a unified Data Portal that allows seamless access for NTUC employees across business lines, while enabling secure data ingestion and robust data quality.
DataHub’s built-in data discovery function provides basic functionality to locate specific data assets from BigQuery tables and Looker Studio dashboards for storage on DataHub. However, we needed a more seamless way to ingest the metadata of all data assets automatically and systematically.
We therefore carried out customizations and enhancements on Cloud Composer, a fully managed workflow orchestration service built on Apache Airflow, and Google Kubernetes Engine (GKE) Autopilot, which helps us scale out easily and efficiently based on our dynamic needs.
Next, we built data lineage, which enables the end-to-end flow of data across our tech stack, drawing data from Cloud SQL into Cloud Storage, then channeling the data back through BigQuery into Looker Studio dashboards for easy visibility. This was instrumental in enabling users across NTUC’s business lines to access data securely and intuitively on Looker Studio.
Having set up the basic platform architecture, our next task was to enable secure data ingestion. Sensitive data needed to be encrypted and stored in Cloud Storage before populating BigQuery tables. The system needed to be flexible enough to securely ingest data in a multi-cloud environment, including Google Cloud, AWS, and our on-premises infrastructure.
Our solution was to build an in-house framework to fit requirements of Python and YML, as well as GKE and Cloud Composer. We created the equivalent of a Collibra data management platform to suit NTUC’s data flow (from Cloud Storage to BigQuery). The system also needed to conform to NTUC data principles, which are as follows:
All data in our Cloud Storage data lake must be stored in a compressed form like Avro, a data security service
Sensitive columns must be hashed using Secure Hash Algorithm 256-bit (SHA-256)
The solution must be flexible for customization depending on needs
Connection must be made by username and password
Connection must be made with certificates (public key and private key), including override functions in code
Connections require one logical table from hundreds of physical tables (MSSQL sharding tables)
Our next task for the Data Portal was creating an automated Data Quality Control service to enable us to check data in real-time whenever a BigQuery table is updated or modified. This liberates our data engineers, who were previously building BigQuery tables by manually monitoring hundreds of table columns for changes or anomalies. This was a task that used to take an entire day, but is now reduced to just five minutes. We enable seamless data quality in the following way:
Activity in BigQuery tables is automatically written into Cloud Logging, a fully managed, real-time log management service with storage, search, analysis, and alerts
The logging service can then filter out events from BigQuery into Pub/Sub for datastreams that are then channeled into Looker Studio, where users can easily access the specific data they need
In addition, the Data Quality Control service sends notifications to users whenever someone updates BigQuery tables incorrectly or against set rules, whether that is deleting, changing or adding data to columns. This enables automated data discovery, without engineers needing to go intoBigQuery to look up tables
These steps enable NTUC to create a flexible, dynamic, and user-friendly Data Portal that democratizes data access across business lines for more than 1,400 platform users, opening up vast potential for creative collaboration and digital solution development. In the future, we plan to look at how we can integrate even more data services into the Data Portal, and leverage Google Cloud to help develop more in-house solutions.
Financial institutions have vast amounts of data about their customers. However, many of them struggle to leverage data to their advantage. Data may be sitting in silos or trapped on costly mainframes. Customers may only have access to a limited quantity of data, or service providers may need to search through multiple systems of record to handle a simple customer inquiry. This creates a hazard for providers and a headache for customers.
Elastic and Google Cloud enable institutions to manage this information. Powerful search tools allow data to be surfaced faster than ever – Whether it’s card payments, ACH (Automated Clearing House), wires, bank transfers, real-time payments, or another payment method. This information can be correlated to customer profiles, cash balances, merchant info, purchase history, and other relevant information to enable the customer or business objective.
This reference architecture enables these use cases:
1. Offering a great customer experience: Customers expect immediate access to their entire payment history, with the ability to recognize anomalies. Not just through digital channels, but through omnichannel experiences (e.g. customer service interactions).
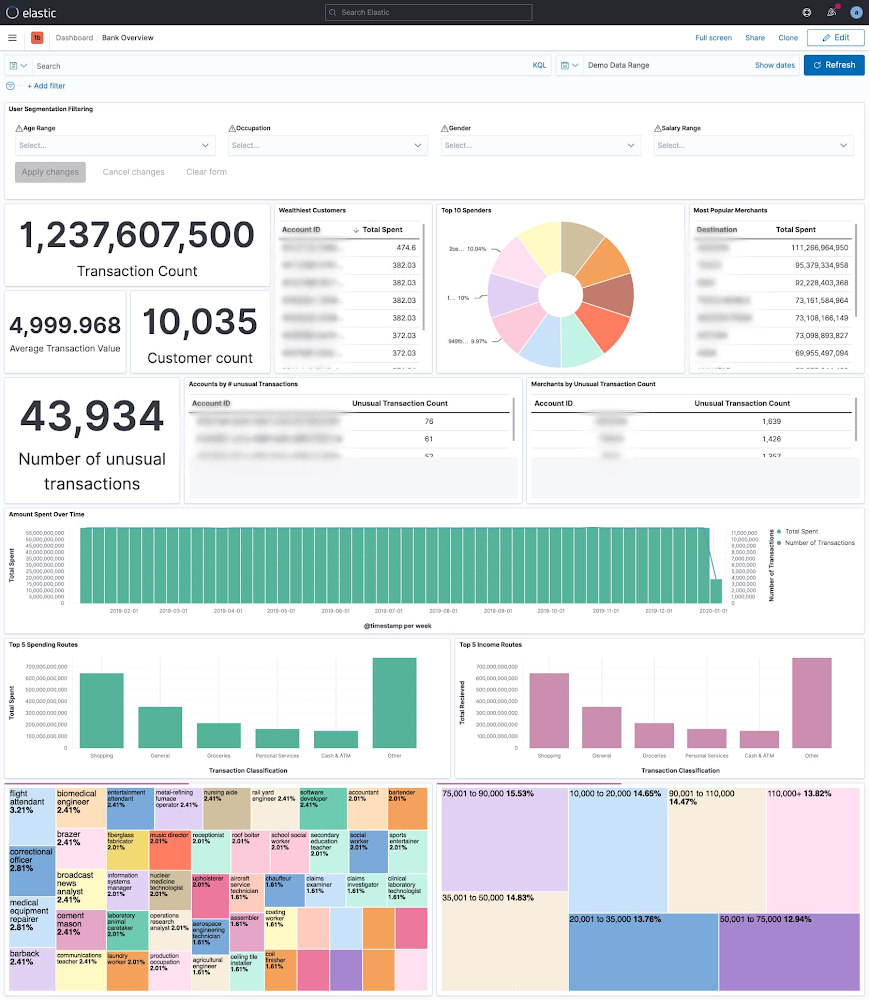
2. Customer 360: Real-time dashboards which correlates transaction information across multiple variables, offering the business a better view into their customer base, and driving efforts for sales, marketing, and product innovation.
Customer 360: The dashboard above looks at 1.2 billion bank transactions and gives a breakdown of what they are, who executes them, where they go, when and more. At a glance we can see who our wealthiest customers are, which merchants our customers send the most money to, how many unusual transactions there are – based on transaction frequency and transaction amount, when folks spend money and what kind spending and income they have.
3. Partnership management: Merchant acceptance is key for payment providers. Having better access to present and historical merchant transactions can enhance relationships or provide leverage in negotiations. With that, banks can create and monetize new services.
4. Cost optimization: Mainframes are not designed for internet-scale access. Along-side with technological limitation, the cost becomes a prohibitive factor. While Mainframes will not be replaced any time sooner, this architecture will help to avoid costly access to data to serve new applications.
5. Risk reduction: By standardizing on the Elastic Stack, banks are longer limited in the number of data sources they can ingest. With this, banks can better respond to call center delays and potential customer-facing impacts like natural disasters. By deploying machine learning and alerting features, banks can detect and stamp out financial fraud before it impacts member accounts.
Fraud detection: The Graph feature of Elastic helped a financial services company to identify additional cards that were linked via phone numbers and amalgamations of the original billing address on file with those two cards. The team realized that several credit unions, not just the original one where the alert originated from, were being scammed by the same fraud ring.
Architecture
The following diagram shows the steps to move data from Mainframe to Google Cloud, process and enrich the data in BigQuery, then provide comprehensive search capabilities through Elastic Cloud.
This architecture includes the following components:
Move Data from Mainframe to Google Cloud
Moving data from IBM z/OS to Google Cloud is straightforward with the Mainframe Connector, by following simple steps and defining configurations. The connector runs in z/OS batch job steps and includes a shell interpreter and JVM-based implementations of gsutil, bq and gcloud command-line utilities. This makes it possible to create and run a complete ELT pipeline from JCL, both for the initial batch data migration and ongoing delta updates.
A typical flow of the connector includes:
Reading the mainframe dataset
Transcoding the dataset to ORC
Uploading ORC file to Cloud Storage
Register ORC file as an external table or load as a native table
Submit a Query job containing a MERGE DML statement to upsert incremental data into a target table or a SELECT statement to append to or replace an existing table
Here are the steps to install the BQ MainFrame Connector:
copy mainframe connector jar to unix filesystem on z/OS
copy BQSH JCL procedure to a PDS on z/OS
edit BQSH JCL to set site specific environment variables
BigQuery is a completely serverless and cost-effective enterprise data warehouse. Its serverless architecture lets you use SQL language to query and enrich Enterprise scale data. And its scalable, distributed analysis engine lets you query terabytes in seconds and petabytes in minutes. An integrated BQML and BI Engine enables you to analyze the data and gain business insights.
Ingest Data from BQ to Elastic Cloud
Dataflow is used here to ingest data from BQ to Elastic Cloud. It’s a serverless, fast, and cost-effective stream and batch data processing service. Dataflow provides an Elasticsearch Flex Template which can be easily configured to create the streaming pipeline. This blog from Elastic shows an example on how to configure the template.
Cloud Orchestration from Mainframe
It’s possible to load both BigQuery and Elastic Cloud entirely from a mainframe job, with no need for an external job scheduler.
To launch the Dataflow flex template directly, you can invoke the gcloud dataflow flex-template run command in a z/OS batch job step.
If you require additional actions beyond simply launching the template, you can instead invoke the gcloud pubsub topics publish command in a batch job step after your BigQuery ELT steps are completed, using the –attribute option to include your BigQuery table name and any other template parameters. The pubsub message can be used to trigger any additional actions within your cloud environment.
To take action in response to the pubsub message sent from your mainframe job, create a Cloud Build Pipeline with a pubsub trigger and include a Cloud Build Pipeline step that uses the gcloud builder to invoke gcloud dataflow flex-template run and launch the template using the parameters copied from the pubsub message. If you need to use a custom dataflow template rather than the public template, you can use the git builder to checkout your code followed by the maven builder to compile and launch a custom dataflow pipeline. Additional pipeline steps can be added for any other actions you require.
The pubsub messages sent from your batch job can also be used to trigger a Cloud Run service or a GKE service via Eventarc and may also be consumed directly by a Dataflow pipeline or any other application.
Mainframe Capacity Planning
CPU consumption is a major factor in mainframe workload cost. In the basic architecture design above, the Mainframe Connector runs on the JVM and runs on zIIP processor. Relative to simply uploading data to cloud storage, ORC encoding consumes much more CPU time. When processing large amounts of data it’s possible to exhaust zIIP capacity and spill workloads onto GP processors. You may apply the following advanced architecture to reduce CPU consumption and avoid increased z/OS processing costs.
Remote Dataset Transcoding on Compute Engine VM
To reduce mainframe CPU consumption, ORC file transcoding can be delegated to a GCE instance. A gRPC service is included with the mainframe connector specifically for this purpose. Instructions for setup can be found in the mainframe connector documentation. Using remote ORC transcoding will significantly reduce CPU usage of the Mainframe Connector batch jobs and is recommended for all production level BigQuery workloads. Multiple instances of the gRPC service can be deployed behind a load balancer and shared by all Mainframe Connector batch jobs.
Transfer Data via FICON and Interconnect
Google Cloud technology partners offer products to enable transfer of mainframe datasets via FICON and 10G ethernet to Cloud Storage. Obtaining a hardware FICON appliance and Interconnect is a practical requirement for workloads that transfer in excess of 500GB daily. This architecture is ideal for integration of z/OS and Google Cloud because it largely eliminates data transfer related CPU utilization concerns.
We really appreciate Jason Mar from Google Cloud who provided rich context and technical guidance regarding the Mainframe Connector, and Eric Lowry from Elastic for his suggestions and recommendations, and the Google Cloud and Elastic team members who contributed to this collaboration.
StreamNative, a company founded by the original developers of Apache Pulsar and Apache BookKeeper, is partnering Google Cloud to build a streaming platform on open source technologies. We are dedicated to helping businesses generate maximum value from their enterprise data by offering effortless ways to realize real-time data streaming. Following the release of StreamNative Cloud in August 2020, which provides scalable and reliable Pulsar-Cluster-as-a-Service, we introduced StreamNative Cloud for Kafka. This is to enable a seamless switch between Kafka API and Pulsar. We then launched StreamNative Platform to support global event streaming data platforms in multi-cloud and hybrid-cloud environments.
By leveraging our fully-managed Pulsar infrastructure services, our enterprise customers can easily build their event-driven applications with Apache Pulsar and get real-time value from their data. There are solid reasons why Apache Pulsar has become one of the most popular messaging platforms in modern cloud environments, and we have strong beliefs in its capabilities of simplifying building complex event-driven applications. The most prominent benefits of using Apache Pulsar to manage real-time events include:
Single API: When building a complex event-driven application, it traditionally requires linking multiple systems to support queuing, streaming and table semantics. Apache Pulsar frees developers from the headache of managing multiple APIs by offering one single API that supports all messaging-related workloads.
Multi-tenancy: With the built-in multi-tenancy feature, Apache Pulsar enables secure data sharing across different departments with one global cluster. This architecture not only helps reduce infrastructure costs, but also avoids data silos.
Simplified application architecture: Pulsar clusters can scale to millions of topics while delivering consistent performance, which means that developers don’t have to restructure their applications when the number of topic-partitions surpasses hundreds. The application architecture can therefore be simplified.
Geo-replication: Apache Pulsar supports both synchronous and asynchronous geo-replication out-of-the-box, which makes building event-driven applications in multi-cloud and hybrid-cloud environments very easy.
Facilitating integration between Apache Pulsar and Google Cloud
To allow our customers to fully enjoy the benefits of Apache Pulsar, we’ve been working on expanding the Apache Pulsar ecosystem by improving the integration between Apache Pulsar and powerful cloud platforms like Google Cloud. In mid-2022, we added Google Cloud Pub/Sub Connector for Apache Pulsar, which enables seamless data replication between Pub/Sub and Apache Pulsar, and Google Cloud BigQuery Sink Connector for Apache Pulsar, which synchronizes Pulsar data to BigQuery in real time, to the Apache Pulsar ecosystem.
Google Cloud Pub/Sub Connector for Apache Pulsar uses Pulsar IO components to realize fully-featured messaging and streaming between Pub/Sub and Apache Pulsar, which has its own distinctive features. Using Pub/Sub and Apache Pulsar at the same time enables developers to realize comprehensive data streaming features on their applications. However, it requires significant development effort to establish seamless integration between the two tools, because data synchronization between different messaging systems depends on the functioning of applications. When applications stop working, the message data cannot be passed on to the other system.
Our connector solves this problem by fully integrating with Pulsar’s system. There are two ways to import and export data between Pub/Sub and Pulsar. The first, is the Google Cloud Pub/Sub source that feeds data from Pub/Sub topics and writes data to Pulsar topics. Alternatively, the Google Cloud Pub/Sub sink can pull data from Pulsar topics and persist data to Pub/Sub topics. Using Google Cloud Pub/Sub Connector for Apache Pulsar brings three key advantages:
Code-free integration: No code-writing is needed to move data between Apache Pulsar and Pub/Sub.
High scalability: The connector can be run on both standalone and distributed nodes, which allows developers to build reactive data pipelines in real time to meet operational needs.
Less DevOps resources required: The DevOps workloads of setting up data synchronization are greatly reduced, which translates into more resources to be invested in unleashing the value of data.
By using the BigQuery Sink Connector for Apache Pulsar, organizations can write data from Pulsar directly to BigQuery. This is unlike before, where developers could only use Cloud Storage Sink Connector for Pulsar to move data to Cloud Storage, and then query the imported data with external tables in BigQuery which had many limitations, including low query performance and no support for clustered tables.
Pulling data from Pulsar topics and persisting data to BigQuery tables, our BigQuery sink connector supports real-time data synchronization between Apache Pulsar and BigQuery. Just like our Pub/Sub connector, Google Cloud BigQuery Sink Connector for Apache Pulsar is a low-code solution that supports high scalability and greatly reduces DevOps workloads. Furthermore, our BigQuery connector possesses the Auto Schema feature, which automatically creates and updates BigQuery table structures based on the Pulsar topic schemas to ensure smooth and continuous data synchronization.
Simplifying Pulsar resource management on Kubernetes
All the products of StreamNative are built on Kubernetes, and we’ve been developing tools that can simplify resource management on Kubernetes platforms like Google Cloud Kubernetes (GKE). In August 2022, we introduced Pulsar Resources Operator for Kubernetes, which is an independent controller that provides automatic full lifecycle management for Pulsar resources on Kubernetes.
Pulsar Resources Operator uses manifest files to manage Pulsar resources, which allows developers to get and edit resource policies through the Topic Custom Resources that render the full field information of Pulsar policies. It enables easier Pulsar resource management compared with using command line interface (CLI) tools, because developers no longer need to remember numerous commands and flags to retrieve policy information. Key advantages of using Pulsar Resources Operator for Kubernetes include:
Easy creation of Pulsar resources: By applying manifest files, developers can swiftly initialize basic Pulsar resources in their continuous integration (CI) workflows when creating a new Pulsar cluster.
Full integration with Helm: Helm is widely used as a package management tool in cloud-native environments. Pulsar Resource Operator can seamlessly integrate with Helm, which allows developers to manage their Pulsar resources through Helm templates.
How you can contribute
With the release of Google Cloud Pub/Sub Connector for Apache Pulsar, Google Cloud BigQuery Sink Connector for Apache Pulsar, and Pulsar Resources Operator for Kubernetes, we have unlocked the application potential of open tools like Apache Pulsar by making them simpler to build, easier to manage, and extended their capabilities. Now, developers can build and run Pulsar clusters more efficiently and maximize the value of their enterprise data.
These three tools are community-driven services and have their source codes hosted in the StreamNative GitHub repository. Our team welcomes all types of contributions for the evolution of our tools. We’re always keen to receive feature requests, bug reports and documentation inquiry through GitHub, emails or Twitter.
When running Apache Hadoop and Spark, it is important to tune the configs, perform cluster planning, and right-size compute. Thorough benchmarking is required to make sure the utilization and performance are optimized. In Dataproc, you can run Spark jobs in a semi-long-running cluster or ephemeral Cloud Dataproc on Google Compute Engine (DPGCE) cluster or via Dataproc Serverless Spark. Dataproc Serverless for Spark runs a workload on an ephemeral cluster. An ephemeral cluster means the cluster’s lifecycle is tied to the job. A cluster is started, used to run the job, and then destroyed after completion. Ephemeral clusters are easier to configure, since they run a single workload or a few workloads in a sequence. You can leverage Dataproc Workflow Templates to orchestrate this. Ephemeral clusters can be sized to match the job’s requirements. This job-scoped cluster model is effective for batch processing. You can create an ephemeral cluster and configure it to run specific Hive workloads, Apache Pig scripts, Presto queries, etc., and then delete the cluster when the job is completed.
Ephemeral clusters have some compelling advantages:
They reduce unnecessary storage and service costs from idle clusters and worker machines.
Every set of jobs runs on a job-scoped ephemeral cluster with job-scoped cluster specifications, image version, and operating system.
Since each job gets a dedicated cluster, the performance of one job does not impact other jobs.
Persistent History Server (PHS)
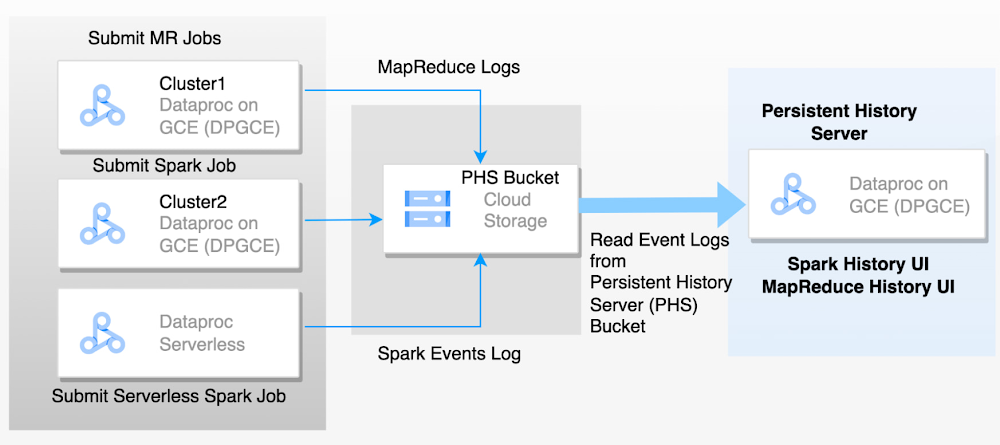
The challenge with ephemeral clusters and Dataproc Serverless for Spark is that you will lose the application logs when the cluster machines are deleted after the job. Persistent History Server (PHS) enables access to the completed Hadoop and Spark application details for the jobs executed on different ephemeral clusters or serverless Spark. It can list running and completed applications. PHS keeps the history (event logs) of all completed applications and its runtime information in the GCS bucket, and it allows you to review metrics and monitor the application at a later time. PHS is nothing but a standalone cluster. It reads the Spark events from GCS, then parses and presents application details, scheduler stages, and task level details, as well as environment and executor information, in the Spark UI. These metrics are helpful for improving the performance of the application. Both the application event logs and the YARN container logs of the ephemeral clusters are collected in the GCS bucket. These log files are important for engaging Google Cloud Technical Support to troubleshoot and explore. If PHS is not set up, you have to re-run the workload, which adds to support cycle time. If you have set up PHS, you can provide the logs directly to Technical Support.
The following diagram depicts the flow of events logged from ephemeral clusters to the PHS server:
In this blog, we will focus on Dataproc PHS best practices. To set up PHS to access web interfaces of MapReduce and Spark job history files, please refer to Dataproc documentation.
PHS Best Practices
Cluster Planning and Maintenance
It’s common to have a single PHS for a given GCP project. If needed, you can create two or more PHSs pointing to different GCS buckets in a project. This allows you to isolate and monitor specific business applications that run multiple ephemeral jobs and require a dedicated PHS.
For disaster recovery, you can quickly spin up a new PHS in another region in the event of a zonal or regional failure.
If you require High Availability (HA), you can spin up two or more PHS instances across zones or regions. All instances can be backed by the dual-regional or multi-regional GCS bucket.
You can run PHS on a single-node Dataproc cluster, as it is not running large-scale parallel processing jobs. For the PHS machine type:
N2 are the most cost-effective and performant machines for Dataproc. We also recommend 500-1000GB pd-standard disks.
For <1000 apps and if there are apps with 50K-100K tasks, we suggest n2-highmem-8.
For <1000 apps and there are apps with 50K-100K tasks, we suggest n2-highmem-8.
For >10000, we suggest n2-highmem16.
We recommend you benchmark with your Spark applications in the testing environment before configuring PHS in production. Once in production, we recommend monitoring your GCE backed PHS instance for memory and CPU utilization and tweaking machine shape as required.
In the event of significant performance degradation within the Spark UI due to a large amount of applications or large jobs generating large event logs, you can recreate the PHS with increased machine size with higher memory.
As Dataproc releases new sub-minor versions on a bi-weekly cadence or greater, we recommend recreating your PHS instance so it has access to the latest Dataproc binaries and OS security patches.
As PHS services (e.g. Spark UI, MapReduce History Server) are backwards compatible, it’s suggested to create a Dataproc 2.0+ based PHS cluster for all instances.
Logs Storage
Configure spark:spark.history.fs.logDirectory to specify where to store event log history written by ephemeral clusters or serverless Spark. You need to create the GCS bucket in advance.
Event logs are critical for PHS servers. As the event logs are stored in a GCS bucket, it is recommended to use a multi-Region GCS bucket for high availability. Objects inside the multi-region bucket are stored redundantly in at least two separate geographic places separated by at least 100 miles.
Configuration
PHS is stateless and it constructs the Spark UI of the applications by reading the application’s event logs from the GCS bucket. SPARK_DAEMON_MEMORY is the memory to allocate to the history server and has a default of 3840m. If too many users are trying to access the Spark UI and access job application details, or if there are long-running Spark jobs (iterated through several stages with 50K or 100K tasks), the heap size is probably too small. Since there is no way to limit the number of tasks stored on the heap, try increasing the heap size to 8g or 16g until you find a number that works for your scenario.
If you’ve increased the heap size and still see performance issues, you can configure spark.history.retainedApplications and lower the number of retained applications in the PHS.
Configure mapred:mapreduce.jobhistory.read-only.dir-pattern to access MapReduce job history logs written by ephemeral clusters.
By default, spark:spark.history.fs.gs.outputstream.type is set to BASIC. The job cluster will send data to GCS after job completion. Set this to FLUSHABLE_COMPOSITE to copy data to GCS at regular intervals while the job is running.
Configure spark:spark.history.fs.gs.outputstream.sync.min.interval.ms to control the frequency at which the job cluster transfers data to GCS.
To enable the executor logs in PHS, specify the custom Spark executor log URL for supporting external log service. Configure the following properties:
code_block[StructValue([(u’code’, u’spark:spark.history.custom.executor.log.url={{YARN_LOG_SERVER_URL}}/{{NM_HOST}}:{{NM_PORT}}/{{CONTAINER_ID}}/{{CONTAINER_ID}}/{{USER}}/{{FILE_NAME}} and spark.history.custom.executor.log.url.applyIncompleteApplication=False’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e9920ac7ed0>)])]
Lifecycle Management of Logs
Using GCS Object Lifecycle Management, configure a 30d lifecycle policy to periodically clean up the MapReduce job history logs and Spark event logs from the GCS bucket. This will improve the performance of the PHS UI considerably.
Note: Before doing the cleanup, you can back up the logs to a separate GCS bucket for long-term storage.
PHS Setup Sample Codes
The following code block creates a Persistent History server with the best practices suggested above.
With the Persistent History server, you can monitor and analyze all completed applications. You will also be able to use the logs and metrics to optimize performance and to troubleshoot issues related to strangled tasks, scheduler delays, and out of memory errors.
If you’re self-managing relational databases such as MySQL, PostgreSQL or SQL Server, you may be thinking about the pros and cons of cloud-based database services. Regardless of whether you’re running your databases on premises or in the cloud, self-managed databases can be inefficient and expensive, requiring significant effort around patching, hardware maintenance, backups, and tuning. Are managed database services a better option?
To answer this question, Google Cloud sponsored a business value white paper by IDC, based on the real-life experiences of eight Cloud SQL customers. Cloud SQL is an easy-to-use, fully-managed database service for running MySQL, PostgreSQL and SQL Server workloads. More than 90% of the top 100 Google Cloud customers use Cloud SQL.
The study found that migration to Cloud SQL unlocked significant efficiencies and cost reductions for these customers. Let’s take a look at the key benefits in this infographic.
Infographic: IDC business value study highlights the business benefits of migrating to Cloud SQL
You can use our Database Migration Service for an easy, secure migration to Cloud SQL. Since Cloud SQL supports the same database versions, extensions and configuration flags as your existing MySQL, PostgreSQL and SQL Server instances, a simple lift-and-shift migration is usually all you need. So let Google Cloud take routine database administration tasks off your hands, and enjoy the scalability, reliability and openness that the cloud has to offer.
AI technology has become an incredibly important part of most IT functions. One of the many reasons IT professionals are investing in AI is to fortify their digital security.
One of the best ways that cybersecurity professionals are leveraging AI is by utilizing SAST strategies.
AI Solidifies Network Security with Better SAST Protocols
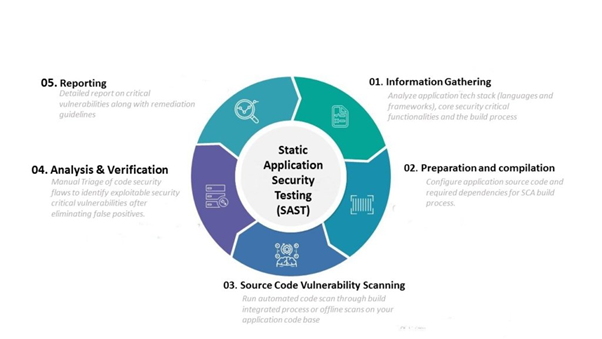
Every single day, a wide variety of new applications and lines of code are being released. A big part of what enables this constant deployment of new applications is a testing process known as static application security testing, or SAST. It analyzes the source code created by developers or organizations to locate security flaws. An application is analyzed by SAST prior to having its code built. It is frequently referred to as “white box testing.”
These days, organizations wish to adopt the shift left method, which requires problems to be corrected as soon as they are discovered. Because of this, SAST takes place extremely early on in the software development lifecycle (SDLC).
This works because SAST does not require a well-functioning software; rather, it simply needs machine learning codes that are currently being developed, which it then analyzes to find vulnerabilities. These AI codes also help developers detect SAST vulnerabilities in the early stages of development, so they may quickly resolve the issues without releasing vulnerable code into production, which could pose a threat to the infrastructure of the company.
For modern-day applications that use containers and Kubernetes, SAST is used for Kubernetes security to protect deployments by identifying potential vulnerabilities in the codebase before the code is put into production. This allows organizations to fix issues early on and prevents any potential vulnerabilities from affecting the final product. This is one of the best ways for companies to use AI to improve network security.
How Does a Modern SAST Strategy Work and What Role Does AI Play in It?
The present SAST technique is quite well developed, especially as it has improved due to new advances in AI. This technology also helps it make use of a wide variety of tools, all of which contribute to the process of fixing smaller bugs and vulnerabilities that may exist in the code.
There are a number of potential vulnerabilities that need to be addressed, such as open source supply chain attacks, that could happen because of things like outdated packages. New developments in AI have made it easier to detect these problems, which helps improve the security of the overall application.
What are some of the ways that AI has helped improve SAST? Some of the benefits have been developed by AI scientists at IBM.
These experts used IBM’s AI application known as “Watson” to better identify security vulnerabilities. They came up with an Intelligent Finding Analytics (IFA) tool, which had a 98% accuracy with detecting security vulnerabilities.
You can learn more about the benefits of using AI for SAST in the following YouTube video by IBM.
Reduce your application security risk with IBM’s cognitive capabilities
Let’s have a conversation about the approaches that are currently being taken to address problems of this nature.
Securing the Dependencies
Applications rely on a large number of different dependencies in order to function properly. Not only do they make the task easier for the software developers, but they also assist developers in writing code that is reliable and effective. Due to the fact that the majority of these dependencies are open source and therefore could include vulnerabilities, it is necessary to perform regular updates on them.
There could be a large number of dependents within an application. Thus, it is impossible for those dependencies to be monitored manually. Doing so would involve a significant amount of effort and could also lead to errors caused by manual intervention. In light of this, businesses typically make use of dependency management tools.
Such tools, after checking for available updates in the dependencies within a predetermined amount of time, open a pull request for each update that is available. They are also able to combine requests if that has been permitted by the user. Therefore, they find ways to eliminate the risks associated with the dependencies.
Performing Code Reviews
Code is the sole determinant of an application’s behavior, and errors in the code are the root cause of security flaws. If these vulnerabilities were to be sent to production, they might create a wide variety of problems, such as SQL injection, and could even compromise the infrastructure of the entire organization. Because of this, it is absolutely necessary to use the shift-left technique before putting code into production.
A significant number of SAST tools are being utilized by organizations for the purpose of deploying code reviews. These code review tools perform an in-depth analysis of the code before it is added to any repository. If the code has any of the known vulnerabilities, they will not allow it to be deployed until the flaws have been fixed. Therefore, it is useful for the shift-left strategy, which is based on the concept of remedying a vulnerability as soon as it is discovered, and only pushing secure code into production.
There is a large variety of softwares available on the market, and some of them enable companies and other organizations to patch their code as soon as security flaws are found. The patch can be deployed with just a few mouse clicks, and there are often several distinct options available to choose from when fixing a particular vulnerability.
Secret Scannings
These days, application are dependent on a significant amount of integration, such as payment gateways, error detection, and so on. In most cases, these APIs will execute, and authentication will be carried out using the API key and the secret.
These keys ought to be required to have an adequate level of security, such as the Live API key for Stripe payment needing to have an adequate level of protection. If this information is leaked, anybody can access the sensitive payment data and withdraw or view it. As a result, several businesses have begun using secret scanning tools.
These tools basically go through the code to see whether it contains any of the known API keys; if it does, the tool prevents the code from being published into production. It is possible for the code review tool itself to provide these features. Alternatively, an organization may easily write their own proprietary tool in order to identify problems of this kind.
Since companies are now transitioning to a shift-left strategy, they are employing SAST tools, which, in a nutshell, discover vulnerabilities as soon as they are coded and fix them. This is causing the shift left approach to become increasingly popular. If the code has any flaws that could be exploited by malicious actors, the deployment will be blocked until the problems are fixed.
Companies now have access to a wide variety of different methods, such as dependency management tools, secret scanning tools, and so on, which not only produce the proper secure code deployment but also produce the proper patches for vulnerabilities as soon as they are discovered in the coding phase.