The Internet of Things (IoT) has changed our lives in extraordinary ways. A number of new IoT devices have made it easier to manage smart homes and have improved or lives.
According to Dell Technologies, there will be over 41.6 billion IoT devices online by 2025, as more people discover their benefits. More homeowners and businesses are looking for IoT devices to invest in.
A number of IoT temperature sensors have reached the market in recent years. These sensors can be great additions to smart homes, which will make it easier to manage them efficiently. T-Mobile has some information on the benefits of these devices.
What Are the Best IoT Sensors for Smart Homes?
Keeping track of the temperature on your cooling equipment and other temperature-sensitive gear is no longer a matter of placing blind trust in your thermometers. Today, you need to rely on sensitive digital sensors that can remotely monitor the temperature of your commercial and residential equipment in real time. Some of these IoT devices can even be used to program smart devices such as smart ovens.
The second the temperature drops out of its appropriate range, you will receive an instant notification over your smartphone and your laptop. This goes for reach-in coolers, walk-in fridges and freezers, prep stations, greenhouses, and more. It also goes for your home refrigerator, freezer, and heated swimming pool.
With this in mind, what are some of the best remote temperature sensors you can invest in for your business or residence in the 2020s, and why should you spend your hard-earned money on them during a time of spiking inflation? Before we answer these questions, it might be useful to explain just what a temperature sensor is and how it’s changing both the commercial and residential cooling/heating landscape. These IoT devices offer a lot of benefits for homeowners and businesses.
According to a new report by TechCult, at the base, a WiFi or wireless temperature sensor is an electronic IoT device that is able to record and monitor temperature changes in the place where it’s installed. For instance, in both commercial enterprises and residences located in areas that have four seasons, temperature sensors are a necessity.
They will post real-time information on your smartphone. You might be able to physically feel changes in temperature in your equipment, but without a sensor, you won’t be able to determine the correct temperature.
That said, here are some of what TechCult believes are the top temperature sensors you can purchase in the 2020s.
The Temp Stick Wireless Remote Temperature and Humidity Sensor
This IoT temperature sensor is said to be one of the most dependable, simple to use, and accurate temperature sensors. The Temp Stick is considered a high-end IoT device when it comes to both commercial and residential cooling and heating equipment. It features many nice features, including the following:
The sensor can be placed just about anywhere and is easy to set up,
You have total control over the information you want and don’t want.
Depending upon where you call home, you can calibrate your sensor to Fahrenheit or Celsius.
The Temp Stick can be temperature programmed.
If you utilize high-quality batteries, the sensor will give you accurate information for up to a year.
Ruggedly constructed, the Temp Stick can deal with extreme temperatures of -40 to 140 degrees Fahrenheit.
Create your own hi/lo triggers depending on your needs and wants.
The system allows you to send emails and messages to as many accounts as you choose.
The SensorPush Thermometer/Hygrometer
Having been engineered to be small, the SensorPush Wireless Thermometer/Hygrometer is said to be a good choice for monitoring instrument cases, display cabinets, art storage cabinets, instrument storage cases, or any other mega-sensitive environments.
Says TechCult; its diminutive size gives it an edge over similar devices. This IoT sensor also offers the following advantages:
Battery life can be extended well over 12 months.
While the SensorPush isn’t waterproof, under the right conditions, it can be utilized outside.
The sensor collects data minute by minute, making it one of the more accurate real-time temperature sensors on the market.
It will save the past 20 days of temperature data on your smartphone.
It’s said to be easy to install. Download the SensorPush app and simply connect with your Bluetooth.
The range is 325 feet so long as the wireless connection is unobstructed.
The SensorPush is said to be engineered for people who don’t wish to place their hands on their hygrometer or thermometer for fear of throwing off their accuracy.
The La Crosse Alerts Mobile 926 25101 GP
The La Crosse is said to be reasonably priced for such a reliable temperature sensor. It is also armed with new capabilities that other sensors don’t have. For example, it is capable of detecting temperature in soil and water, which makes it the perfect choice for greenhouses and swimming pools.
You can choose how often you would like to receive your real-time date based on the settings you choose. The time intervals are said to be between five and 60 minutes. It is a truly remarkable IoT temperature sensor. The La Crosse also offers the following:
If you choose to have the device deliver data less often, it will automatically save on battery life.
All it takes is three easy steps to start receiving humidity and temperature notifications on your smartphone.
Its range is up to 200 feet, unobstructed.
Your La Crosse’s capability can be expanded by adding more sensors to cover more area and more equipment.
La Crosse sends you emails, app notifications, and SMS texts if it detects a problem, such as a weak battery or a bad sensor.
The IoT Has Led to a New Generation of Temperature Sensors
The IoT is one of the most important technological breakthroughs of this century. It has manifested in a number of ways, including the development of remarkably useful temperature sensors that can be monitored and controlled remotely. There are a lot of great benefits of IoT temperature sensors. They can help you track temperatures remotely or even adjust settings on other devices.
Geospatial data analytics lets you use location data (latitude and longitude) to get business insights. It’s used for a wide variety of applications in industry, such as package delivery logistics services, ride-sharing services, autonomous control of vehicles, real estate analytics, and weather mapping.
BigQuery, Google Cloud’s large-scale data warehouse, provides support for analyzing large amounts of geospatial data. This blog post discusses two geography functions we’ve recently added in order to expand the capabilities of geospatial analysis in BigQuery: ST_IsClosed and ST_IsRing.
BigQuery geospatial functions
In BigQuery, you can use the GEOGRAPHY data type to represent geospatial objects like points, lines, and polygons on the Earth’s surface. In BigQuery, geographies are based on the Google S2 Library, which uses Hilbert space-filling curves to perform spatial indexing to make the queries run efficiently. BigQuery comes with a set of geography functions that let you process spatial data using standard ANSI-compliant SQL. (If you’re new to using BigQuery geospatial analytics, start with Get started with geospatial analytics, a tutorial that uses BigQuery to analyze and visualize the popular NYC Bikes Trip dataset.)
The new ST_IsClosed and ST_IsRing functions are boolean accessor functions that help determine whether a geographical object (a point, a line, a polygon, or a collection of these objects) is closed or is a ring. Both of these functions accept a GEOGRAPHY column as input and return a boolean value.
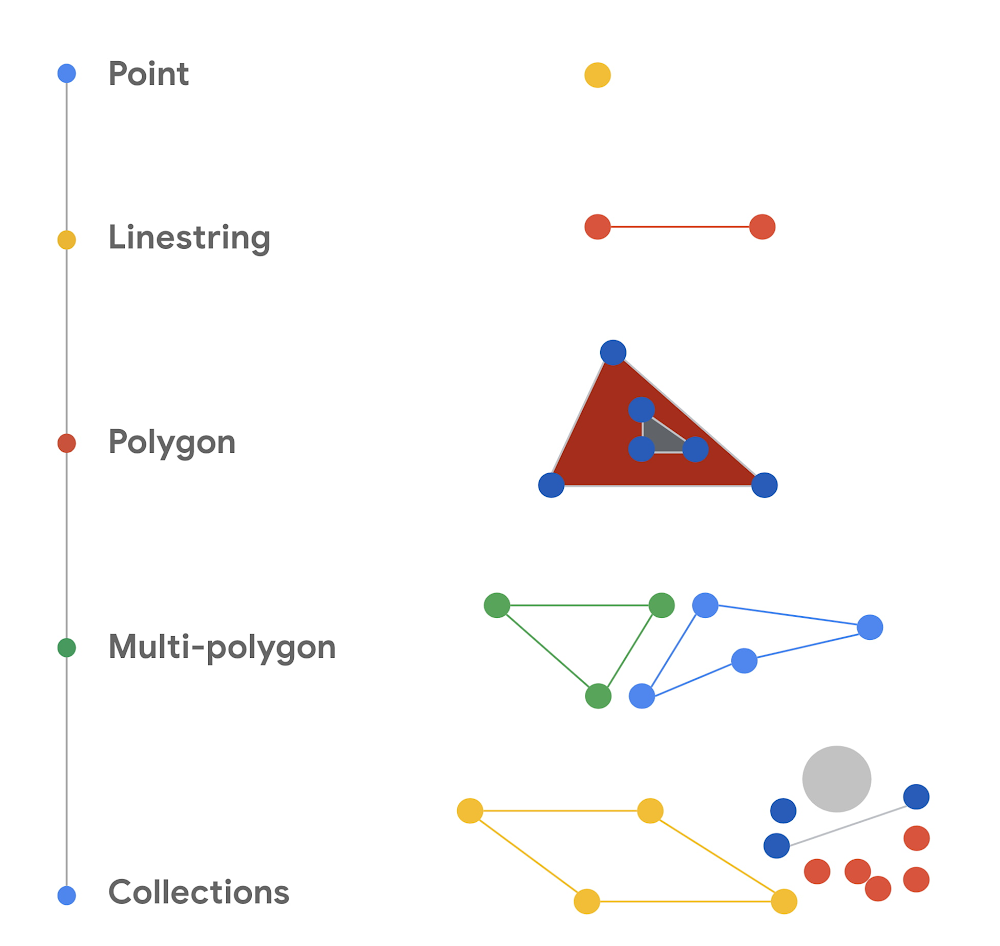
The following diagram provides a visual summary of the types of geometric objects.
The ST_IsClosed function examines a GEOGRAPHY object and determines whether each of the elements of the object has an empty boundary. The boundary for each element is defined formally in the ST_Boundary function. The following rules are used to determine whether a GEOGRAPHY object is closed:
A point is always closed.
A linestring is closed if the start point and end point of the linestring are the same.
A polygon is closed only if it’s a full polygon.
A collection is closed if every element in the collection is closed.
An empty GEOGRAPHY object is not closed.
Is the object a ring? (ST_IsRing)
The other new BigQuery geography function is ST_IsRing. This function determines whether a GEOGRAPHY object is a linestring and whether the linestring is both closed and simple. A linestring is considered closed as defined by the ST_IsClosed function. The linestring is considered simple if it doesn’t pass through the same point twice, with one exception: if the start point and end point are the same, the linestring forms a ring. In that case, the linestring is considered simple.
Seeing the new functions in action
The following query shows you what the ST_IsClosed and ST_IsRing function return for a variety of geometric objects. The query creates a series of ad-hoc geography objects and uses the UNION ALL statement to create a set of inputs. The query then calls the ST_IsClosed and ST_IsRing functions to determine whether each of the inputs are closed or are rings. You can run this query in the BigQuery SQL workspace page in the Google Cloud console.
code_block[StructValue([(u’code’, u”WITH example AS(rn SELECT ST_GeogFromText(‘POINT(1 2)’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘LINESTRING(2 2, 4 2, 4 4, 2 4, 2 2)’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘LINESTRING(1 2, 4 2, 4 4)’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘POLYGON((0 0, 2 2, 4 2, 4 4, 0 0))’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘MULTIPOINT(5 0, 8 8, 9 6)’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘MULTILINESTRING((0 0, 2 0, 2 2, 0 0), (4 4, 7 4, 7 7, 4 4))’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘GEOMETRYCOLLECTION EMPTY’) AS geographyrn UNION ALLrn SELECT ST_GeogFromText(‘GEOMETRYCOLLECTION(POINT(1 2), LINESTRING(2 2, 4 2, 4 4, 2 4, 2 2))’) AS geography)rnSELECTrn geography,rn ST_IsClosed(geography) AS is_closed, rn ST_IsRing(geography) AS is_ring rnFROM example;”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d11501f50>)])]
The console shows the following results. You can see in the is_closed and is_ring columns what each function returns for the various input geography objects.
The new functions with real-world geography objects
In this section, we show queries using linestring objects that represent line segments that connect some of the cities in Europe. We show the various geography objects on maps and then discuss the results that you get when you call ST_IsClosed and ST_IsRing for these geography objects.
You can run the queries by using the BigQuery Geo Viz tool. The maps are the output of the tool. In the tool you can click the Show results button to see the values that the functions return for the query.
Start point and end point are the same, no intersection
In the first example, the query creates a linestring object that has three segments. The segments are defined by using four sets of coordinates: the longitude and latitude for London, Paris, Amsterdam, and then London again, as shown in the following map created by the Geo Viz tool:
The query looks like the following:
code_block[StructValue([(u’code’, u”WITH example AS (rnSELECT ST_GeogFromText(‘LINESTRING(-0.2420221 51.5287714, 2.2768243 48.8589465, 4.763537 52.3547921, -0.2420221 51.5287714)’) AS geography)rnSELECT rn geography, rn ST_IsClosed(geography) AS is_closed,rn ST_IsRing(geography) AS is_ringrnFROM example;”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d11501ed0>)])]
In the example table that’s created by the query, the columns with the function values show the following:
ST_IsClosed returns true. The start point and end point of the linestring are the same.
ST_IsRing returns true. The geography is closed, and it’s also simple because there are no self-intersections.
Start point and end point are different, no intersection
Another scenario is when the start and end points are different. For example, imagine two segments that connect London to Paris and then Paris to Amsterdam, as in this map:
The following query represents this set of coordinates:
code_block[StructValue([(u’code’, u”WITH example AS (rnSELECT ST_GeogFromText(‘LINESTRING(-0.2420221 51.5287714, 2.2768243 48.8589465, 4.763537 52.3547921)’) AS geography)rnSELECT rn geography, rn ST_IsClosed(geography) AS is_closed,rn ST_IsRing(geography) AS is_ringrnFROM example;”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d112f9610>)])]
This time, the ST_IsClosed and ST_IsRing functions return the following values:
ST_IsClosed returns false. The start point and end point of the linestring are different.
ST_IsRing returns false. The linestring is not closed. It’s simple because there are no self-intersections, but ST_IsRing returns true only when the geometry is both closed and simple.
Start point and end point are the same, with intersection
The third example is a query that creates a more complex geography. In the linestring, the start point and end point are the same. However, unlike the earlier example, the line segments of the linestring intersect. A map of the segments shows connections that go from London to Zürich, then to Paris, then to Amsterdam, and finally back to London:
In the following query, the linestring object has five sets of coordinates that define the four segments:
code_block[StructValue([(u’code’, u”WITH example AS (rnSELECT ST_GeogFromText(‘LINESTRING(-0.2420221 51.5287714, 8.393389 47.3774686, 2.2768243 48.8589465, 4.763537 52.3547921, -0.2420221 51.5287714)’) AS geography)rnSELECT rn geography,rn ST_IsClosed(geography) AS is_closed,rn ST_IsRing(geography) as is_ringrnFROM example;”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d112f97d0>)])]
In the query, ST_IsClosed and ST_IsRing return the following values:
ST_IsClosed returns true. The start point and end point are the same, and the linestring is closed despite the self-intersection.
ST_IsRing returns false. The linestring is closed, but it’s not simple because of the intersection.
Start point and end point are different, with intersection
In the last example, the query creates a linestring that has three segments that connect four points: London, Zürich, Paris, and Amsterdam. On a map, the segments look like the following:
The query is as follows:
code_block[StructValue([(u’code’, u”WITH example AS (rnSELECT ST_GeogFromText(‘LINESTRING(-0.2420221 51.5287714, 8.393389 47.3774686, 2.2768243 48.8589465, 4.763537 52.3547921)’) AS geography)rnSELECT rn geography, rn ST_IsClosed(geography) AS is_closed,rn ST_IsRing(geography) AS is_ringrnFROM example;”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e1d108378d0>)])]
The new functions return the following values:
ST_IsClosed returns false. The start point and end point are not the same.
ST_IsRing returns false. The linestring is not closed and it’s not simple.
Try it yourself
Now that you’ve got an idea of what you can do with the new ST_IsClosed and ST_IsRing functions, you can explore more on your own. For details about the individual functions, read the ST_IsClosed and ST_IsRing entries in the BigQuery documentation. To learn more about the rest of the geography functions available in BigQuery Geospatial, take a look at the BigQuery geography functions page.
Thanks to Chad Jennings, Eric Engle and Jing Jing Long for their valuable support to add more functions to BigQuery Geospatial. Thank you Mike Pope for helping review this article.
Zeotap’s mission is to help brands monetise customer data in a privacy-first Europe. Today, Zeotap owns three data solutions. Zeotap CDP is the next-generation Customer Data Platform that empowers brands to collect, unify, segment and activate customer data. Zeotap CDP puts privacy and security first while empowering marketers to unlock and derive business value in their customer data with a powerful and marketer-friendly user interface. Zeotap Data delivers quality targeting at scale by enabling the activation of 2,500 tried-and-tested Champion Segments across 100+ programmatic advertising and social platforms. ID+ is a universal marketing ID initiative that paves the way for addressability in the cookieless future. Zeotap’s CDP is a SaaS application that is hosted on Google Cloud. A client can use Zeotap CDP SaaS product suite to onboard its first-party data, use the provided tools to create audiences and activate them on marketing channels and advertising platforms.
Zeotap partnered with Google Cloud to provide a customer data platform that is differentiated in the market with a focus on privacy, security and compliance. Zeotap CDP, built with BigQuery, is empowered with tools and capabilities to democratize AI/ML models to predict customer behavior and personalize the customer experience to enable the next generation digital marketing experts to drive higher conversion rates, return on advertising spend and reduce customer acquisition cost.
The capability to create actionable audiences that are highly customized the first time, improve speed to market to capture demand and drive customer loyalty are differentiating factors. However, as the audiences get more specific it becomes more difficult to estimate and tune the size of the audience segment. Being able to identify the right customer attributes is critical for building audiences at scale.
Consider the following example, a fast fashion retailer has a broken size run and is at risk of taking a large markdown because of an excess of XXS and XS sizes. What if you are able to instantly build an audience of customers who have a high propensity for this brand or style, tend to purchase at full price, and match the size profile for the remaining inventory to drive full price sales and avoid costly markdowns.
Most CDPs provide size information only after a segment is created and its data processed. If the segment sizes are not relevant and quantifiable, the target audiences list has to be recreated impacting speed to market and capturing customer demand. Estimating the segment size and tuning the size of the audience segment is often referred to as the segment size estimation problem. The segment size needs to be estimated and segments should be available for exploration and processing with a sub-second latency to provide a near real-time user experience.
Traditional approaches to solve this problem relies on pre-aggregation database models which involve sophisticated data ingestion and failure management, thus wasting a lot of compute hours and requiring extensive pipeline orchestration. There are a number of disadvantages with this traditional approach:
Higher cost and maintenance as multiple Extract, Transform and Load (ETL) processes are involved
Higher failure rate and re-processing required from scratch in case of failures
Takes hours/days to ingest data at large-scale
Zeotap CDP relies on the power of Google Cloud Platform to tackle this segment size estimation problem using BigQuery for processing and estimation, the BI Engine to provide sub-second latency required for online predictions and Vertex AI ecosystem with BigQuery ML to provide a no-code AI segmentation and lookalike audiences. Zeotap CDP’s strength is to offer this estimation at the beginning of segment creation before any kind of data processing using pre-calculated metrics. Any correction in segment parameters can be made near real time, saving a lot of user’s time.
The data cloud, with BigQuery at its core, functions as a data lake at scale and the analytical compute engine that calculates the pre-aggregated metrics. The BI engine is used as a caching and acceleration layer to make these metrics available with near sub-second latency. Compared to the traditional approach this setup does not require a heavy data processing framework like Spark/Hadoop or sophisticated pipeline management. Microservices deployed on the GKE platform are used for orchestration using BigQuery SQL ETL capabilities. This does not require a separate data ingestion in the caching layer as the BI engine works seamlessly in tandem with BigQuery and is enabled using a single setting.
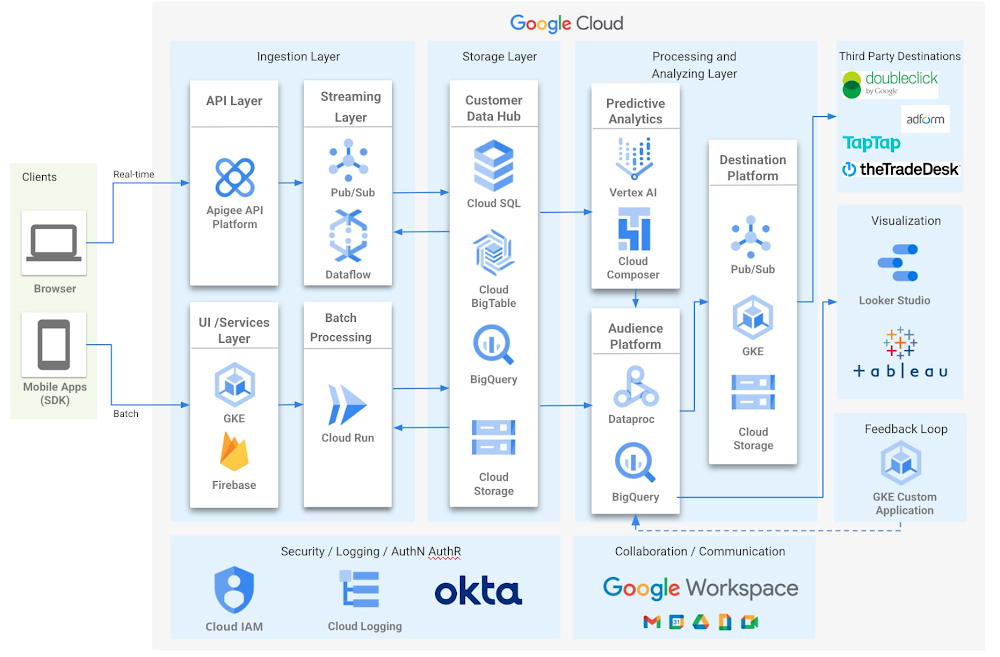
The below diagram depicts how Zeotap manages the first party data and solves for the segment size estimation problem.
The API layer, powered by Apigee provides secure client access to Zeotap’s API infrastructure to read and ingest first party data in real-time. The UI Services Layer, backed by GKE and Firebase provides access to Zeotap’s platform front-ending audience segmentation, real-time workflow orchestration / management, analytics & dashboards. The Stream & Batch processing manages the core data ingestion using PubSub, Dataflow and Cloud Run. Google BigQuery, Cloud SQL, BigTable and Cloud Storage make up all of the Storage layer.
The Destination Platform allows clients to activate its data across various marketing channels, data management and ad management platforms like Google DDP, TapTap, TheTradeDesk etc (plus more than 150+ such integrations). Google BigQuery is at the heart of the Audience Platform to allow clients to slice and dice its first party assets, enhance it with Zeotap’s universal ID graph or its third-party data assets and push to downstream destinations for activation and funnel analysis. The Predictive Analytics layer allows clients to create and activate machine-learned (e.g. CLV and RFM modeling) based segments with just a few clicks. Cloud IAM, Cloud Operations suite and Collaborations tools deliver the cross-sectional needs of security, logging and collaboration.
For segment/audience size estimation, the core data that is client’s first party data resides in its own GCP project. First step here is to identify low cardinality columns using BigQuery’s “approx count distinct” capabilities. At this time, Zeotap supports a sub-second estimation on only low cardinality ( represents the number of unique values) dimensions, like Gender with Male/Female/M/N values and Age with limited age buckets. A sample query looks like this,
Once pivoted by columns, the results look like this
Now the cardinality numbers are available for all columns, they are divided into two groups, one below the threshold (low cardinality) and one above the threshold (high cardinality). Next step is to run a reverse ETL query to create aggregates on low cardinality dimensions and corresponding HLL sketches for user count (measure) dimensions.
A sample query looks like this
The resultant data is loaded into a separate estimator Google Cloud project for further processing and analysis. This project contains a metadata store with datasets required for processing client requests and is front ended with BI engine to provide acceleration to estimation queries. With this process, the segment size is calculated using pre-aggregated metrics without processing the entire first party dataset and enables the end user to create and experiment with a number of segments without incurring any delays as in the traditional approach.
This approach obsoletes ETL steps required to realize this use-case which drives a benefit of over 90% time reduction and 66% cost reduction for the segment size estimation. Also, enabling BI engine on top of BigQuery boosts query speeds by more than 60%, optimizes resource utilization and improves query response as compared to native BigQuery queries. The ability to experiment with audience segmentation is one of the many capabilities that Zeotap CDP provides their customers. The cookieless future will drive experimentation with concepts like topics for IBA (Interest-based advertising) and developing models that support a wide range of possibilities in predicting customer behavior.
There is an ever increasing demand for shared data, where customers are requesting access to the finished data in the form of datasets to share both within and across the organization through external channels. These datasets unlock more opportunities where the curated data can be used as-is or coalesced with other datasets to create business centric insights or fuel innovation by enabling ecosystem or develop visualizations. To meet this need, Zeotap is leveraging Google Cloud Analytics Hub to create a rich data ecosystem of analytics-ready datasets.
Analytics Hub is powered by Google BigQuery, which provides a self-service approach to securely share data by publishing and subscribing to trusted data sets as listings in Private and Public Exchanges. It allows Zeotap to share the data in place having full control while end customers have access to fresh data without the need to move data at large scale.
Click here to learn more about Zeotap’s CDP capabilities or to request a demo.
The Built with BigQuery advantage for ISVs
Google is helping tech companies like Zeotap build innovative applications on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs through the Built with BigQuery initiative, launched in April as part of the Google Data Cloud Summit. Participating companies can:
Get started fast with a Google-funded, pre-configured sandbox.
Accelerate product design and architecture through access to designated experts from the ISV Center of Excellence who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable data warehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. And with a huge partner ecosystem and support for multi-cloud, open source tools and APIs, Google provides technology companies the portability and extensibility they need to avoid data lock-in.
We thank the Google Cloud and Zeotap team members who co-authored the blog: Zeotap: Shubham Patil, Engineering Manager; Google: Bala Desikan, Principal Architect and Sujit Khasnis, Cloud Partner Engineering
In today’s world, organizations view data sharing to be a critical component of their overall data strategy. Businesses are striving to unlock new insights and make more informed decisions by sharing and consuming data from partners, customers, and other sources. There are many organizations also looking to generate new revenue streams by monetizing their data assets. However, existing technologies used to exchange data pose many challenges for customers. Traditional data sharing techniques such as FTP, email, and APIs are expensive to maintain and often result in multiple copies of stale data, especially when sharing in scale. Organizations are looking for ways to make data sharing more reliable and consistent.
We recently announced the general availability of Analytics Hub. This fully-managed service enables organizations to securely exchange data and analytics assets within or across organizational boundaries. Backed by the unique architecture of BigQuery, customers can now share real-time data at scale without moving the data, leading to tremendous cost savings for their data management. As part of this launch, we have added functionality for both data providers and subscribers to realize the full potential of shared data, including:
Regional support: Analytics Hub service is now available in all the supported regions in BigQuery.
Subscription Management: Data providers can now easily view and manage subscriptions for all their shared datasets in a single view.
Governance & Access: Administrators can now monitor the usage of Analytics Hub through Audit Logging and Information Schema, while enforcing VPC Service Controls to securely share data.
Search & Discovery: We have revamped the search experience with filter facets to help subscribers quickly find relevant listings
Data Ecosystem: We added hundreds of new public and commercial listings in Analytics Hub across industries such as finance, geospatial, climate, retail, and more to help organizations consume data from third-party sources. We have also added first-party data from Google including Google Trends, Google’s Diversity Annual Report, Google Cloud Release Notes, Carbon-Free Energy Data for GCP Data Centers, COVID-19 Open Data: Vaccination Search Insights.
Publish-and-Subscribe model to securely share data
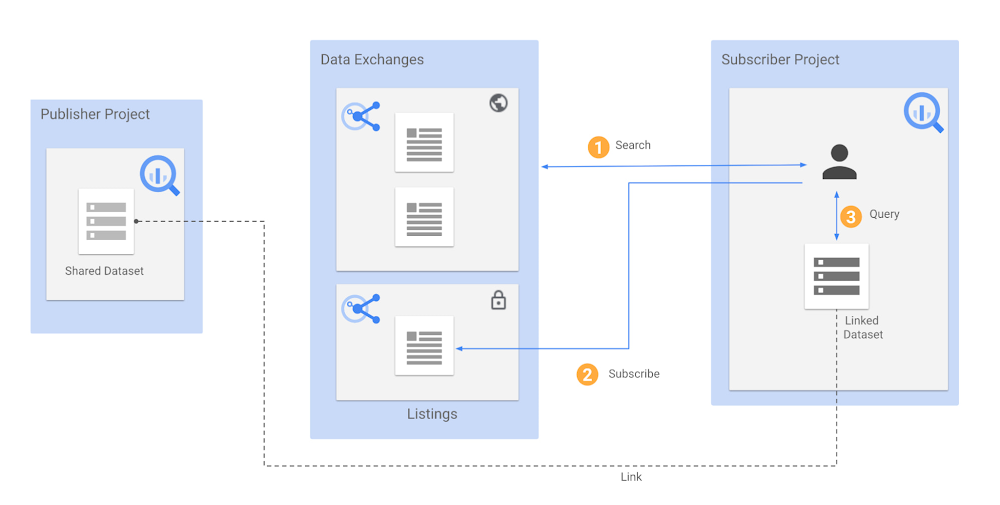
Analytics Hub uses a publish-and-subscribe model to distribute data at scale. As a data provider, you can create secure data exchanges and publish listings that contain the datasets you want to share. Exchanges enable you to control the users or groups that can view or subscribe to the listings. By default, exchanges are private in Analytics Hub. However, if you have public or commercial datasets that you want to make available for all Google Cloud customers, you can also request to make an exchange public. Organizations can create hundreds of exchanges to meet their data sharing needs.
Analytics Hub also provides a seamless experience to browse and search listings across all exchanges. As a data subscriber, you can easily find the dataset of interest (1) and request access or subscribe to listings that you have access to (2). By subscribing to a listing, Analytics Hub creates a read-only linked dataset within your project that you can query (3). A linked dataset is not a copy of the data; it is just a symbolic link to the shared dataset that stays in sync with any changes made to the source.
Data sharing use cases for Analytics Hub
Over a one-week period in September 2022, BigQuery saw more than 6,000 organizations sharing over 275 petabytes of data across organizational boundaries. Many of these customers also used Analytics Hub in preview to share data at scale in various scenarios. Some of these use cases include:
Internal data sharing – Customers can create exchanges for various business functions or geographics to share data internally within an organization. For example, an organization can set up a marketing exchange to publish all the latest channel performance, customer profiles, product performance, etc.
Collaboration across organizations – When sharing data across organizational boundaries, customers can create private exchanges with each partner or business (B2B). A common example is a retailer sharing sales data with each of their suppliers.
Monetizing data assets – Data providers can also monetize their datasets and distribute the data through commercial exchanges. Today, commercial providers use an offline entitlement and billing process and provision access to the data using Analytics Hub.
Enriching insights with third-party data – Customers can discover new insights or gain a competitive advantage by leveraging external or third-party data. Analytics Hub and its rich data ecosystem provide easy access to analytics-ready public and commercial datasets. An example of a popular dataset on the platform has been Google Trends.
Here is what some of our customers and partners had to say:
“Analytics Hub allows data scientists to discover and subscribe to new data assets in the cloud with ease,” said Kimberly Bloomston, SVP of Product at LiveRamp. “With the addition of this offering, LiveRamp now fully supports GCP with a complete suite of native solutions that unlock greater accuracy, partner connectivity and audience activation for marketing and advertising. This expanded partnership provides a must-have analytic infrastructure that excels at unlocking more value from data while respecting strict global privacy regulations.”
“Securely sharing data with partners and clients is always a challenge. The questions of ownership, billing and security are not straightforward for any organization. Analytics Hub, with its publish/subscribe model, provides answers to these questions baked right into the platform.” said Jono MacDougall , Principal Software Engineer at Ravelin.
“One of our key driving factors for BigQuery adoption is availability of Analytics Hub (AH). In a prior model sharing and receiving data as flat files was laborious, inefficient and expensive. We changed that significantly with an early adoption of Analytics Hub, introducing its capabilities to our customers and partners who are also primarily on GCP, enabling multi-way data exchange between these entities and are on our way to monetizing the valuable insights we learn along the way.” said Raj Chandrasekaran, CTO at True Fit.
Next steps
Get started with Analytics Hub today by using this guide, starting a free trial with BigQuery, or contacting the Google Cloud sales team. Stay tuned for updates to our product with features such as usage metrics for providers, approval workflows, privacy-safe queries though data clean rooms, commercialization workflows, and much more.
Cloud technology has driven a number of changes in the financial sector. Alternative financial systems such as cryptocurrency trading have also changed as a result of cloud technology. We have talked about the benefits of using the cloud to trade bitcoins in developing economies like Algeria. However, it can be even more useful for trading newer currencies.
The cloud might help some of the newer cryptocurrencies achieve relevance. Nate Nead wrote an interesting post in InvestmentBank.com stating that cloud computing is the next frontier of cryptocurrency. He mostly focused on the benefits of using the cloud for bitcoin, but it could also be useful for other cryptocurrencies such as Solana.
Cloud Technology Could Help Make Solana a More Viable Cryptocurrency
The most popular Ethereum blockchain was actively used for development and deployment of decentralized apps and smart contracts on the top of it. Over time, the network has become too overloaded with projects running on it, which led to increased fees and reduced throughput. That was when other crypto projects emerged and tried to surpass the Ethereum network with better throughput, faster transactions, and minimal fees. One such successful Ethereum competitor was Solana. It is one of the most popular blockchains where developers massively deploy their products, NFT projects, blockchain games, decentralized apps, etc. SOL is the native coin of the Solana network, and it is traded on all large platforms, so you can buy Solana crypto using any crypto exchange. The Solana price today (November 15, 2022) is $14,59.
Cloud technology is making Solana a more popular cryptocurrency than ever. A growing number of investors are using cloud-based cryptocurrency trading platforms to buy and sell Solana coins.
Based on the asset’s price chart, experts have made the SOL price prediction, stating that the coin can reach $18 – 22 in 2023. So it is definitely worth buying some coins and holding them until the market trend changes in the future. Now let’s see where you can do this by leveraging cloud-based Solana trading platforms.
Where to Buy Solana on the Cloud?
You can use the WhiteBIT platform to check the Solana live price and buy this asset. According to Capterra, this is a cloud-based trading platform, which means you will get timely access and reliable support.
Why is WhiteBIT the best platform for buying Solana? Because it is an officially operating exchange providing clients safety and all possible trading tools, there are over 400 pairs to trade. Users who have passed verification have no limits on money withdrawal and access to various trading tools and financial instruments.
Besides, on WhiteBIT, you can buy Solana coins directly from your bank card. This option is obviously accessible for verified clients. The process of verification lasts for a couple of days.
To buy SOL on this cloud-based trading platform, follow the steps:
Register an account
Pass KYC
Add your bank card
Deposit the amount of money you want to spend on buying SOL
Pick SOL and fiat currency you have
See the Solana live price
See the fee
Pay the fee
Receive SOL to hour account.
Learn more about trading and the preferences of the Solana blockchain on the WhiteBIT blog.
Cloud Technology Helps Solana Traders
Solana is an up and coming cryptocurrency that has attracted a lot of support among investors. Cloud technology has made it easier to trade Solana, which is helping make the cryptocurrency more attractive.
Data analytics technology has had a profound effect on the nature of customer engagement. Analytics is especially important for companies trying to optimize their online presence.
Website optimization is absolutely vital for any brand striving to do business online. According to Northern Arizona University, 88% of customers will leave a website due to a poor user experience. The expectations are higher than ever, so brands need to invest in data analytics tools to ensure a great online user experience.
Data Analytics is Vital for Providing a Great User Experience
Website optimization has been a key part of a business’s strategy since the late 1990s. Online presence has become an even more vital component since the 2020 pandemic. With so much competition online and more people using the internet than ever before, it’s vital for your company to have a strong internet presence. While simply throwing everything at the wall and hoping that some of it sticks is a tactic favored by some, you’ll find you get far more organic traffic by optimizing your site with a fine brush rather than a roller.
Data analytics technology is crucial for companies trying to optimize their online presence. Here are some of the benefits of using analytics as part of your UX strategy:
You can use data analytics to measure overall engagement with your website. Google Analytics and other data analytics tools can track how long customers spend on your site, what links they click and whether they convert.
You can also use data analytics to get a more granular understanding of different visitor demographics and traffic sources. This can help you develop custom pages with responsive content that appeal to each segment of your customer base.
Crazy Egg and similar analytics tools can track what elements of your content customers engage with.
Of course, there are two roads to consider here – hiring a professional team with SEO and UX optimization experience or learning how to do it yourself. The former can be a great option if you can afford it or, alternatively, you may decide to take out a business cash advance to fund it. But with a little time and the right knowledge, there’s no reason why you shouldn’t be able to learn how to optimize your own site. Fortunately, the process is easier than ever if you have the right tools at your disposal.
Here are some ways that you can use data analytics to better optimize your website.
Optimize for mobile
It will come as little surprise that most of us access the internet using our smartphones now. The problem is that most websites are designed to sit on a landscape screen that’s 14 inches or larger and not via touch controls.
If a customer struggles to view or navigate your site on their phone, they could very well easily leave and try a competitor with a more mobile-focused interface. Their negative experiences will also affect your rankings. The solution is to think mobile-first and design your site to work perfectly on a smartphone. Then you can think about the desktop.
The good news is that there are a lot of great data analytics tools designed for mobile UX optimization. Some of the best include UXCam, Pendio, Mixpanel, Firebase and Flurry.
Have a call to action
Every landing page on your website should have a solid call to action, which essentially means directing them to perform an action like signing up for a service, buying a product, downloading a document or contacting your company. The invitation should be obvious (form, button, link, etc.) and shouldn’t be hidden away. Make it big, clear and obvious.
Google Analytics and other analytics tools can help you determine the effectiveness of given calls-to-action. One of the best ways to use data analytics to test your CTA is to create separate landing pages with different ones and create conversion goals. This will help you see which CTAs offer the best conversion rates.
Make it relevant
Make it so that your site is easy to find – the domain name should mean something to your brand or be an exact match, if possible. You could even buy different domains that direct back to your main website to stop competitors from buying alternate domain names and confusing your potential customers.
Then there is SEO or search engine optimization. This is the practice of specifically tailoring your site so that Google and other search engines look at it more favorably when ranking it in their search engine results. This is a very deep subject and a practice that is constantly changing but it’s certainly worth investing in.
Data analytics can help boost relevance in a number of ways. You can use AI and analytics tools like Grammarly to assess the quality and readability of your content. You can also use analytics tools to find similar content to make sure that your content resonates with the expectations both search engine crawlers and users.
Contact information should be easy to find
Don’t hide your contact info under a bushel. People need to be able to contact you and your sales or support team. Without details, you can miss out on transactions, lose existing clients, and be left with poor reviews. Also, don’t be afraid to use social media to engage with customers and create a sharing platform that is more transparent and brings people to your site in a more organic way.
Data Analytics is Vital for Successful Website UX Optimization
Analytics is very important for website optimization. The aforementioned guidelines will help you leverage data analytics to create the best possible user experience.
Editor’s note: We’re hearing today from Auto Trader UK, the UK and Ireland’s largest online automotive marketplace, about how BigQuery’s robust performance has become the data engine powering real-time inventory and pricing information across the entire organization.
Auto Trader UK has spent nearly 40 years perfecting our craft of connecting buyers and sellers of new and used vehicles. We host the largest pool of sellers, listing more than 430,000 cars every day and attract an average of over 63 million cross platform visits each month. For the more than 13,000 retailers who advertise their cars on our platform, it’s important for them (and their customers) to be able to quickly see the most accurate, up-to-date information about what cars are available and their pricing.
BigQuery is the engine feeding our data infrastructure
Like many organizations, we started developing our data analytics environment with an on-premise solution and then migrated to a cloud-based data platform, which we used to build a data lake. But as the volume and variety of data we collected continued to increase, we started to run into challenges that slowed us down.
We had built a fairly complex pipeline to manage our data ingestion, which relied on Apache Spark to ingest data from a variety of data sources from our online traffic and channels. However, ingesting data from multiple data sources in a consistent, fast, and reliable way is never a straightforward task.
Our initial interest in BigQuery came after we discovered it integrated with a more robust event management tool for handling data updates. We had also started using Looker for analytics, which already connected to BigQuery and worked well together. As a result, it made sense to replace many parts of our existing cloud-based platform with Google Cloud Storage and BigQuery.
Originally, we had only anticipated using BigQuery for the final stage of our data pipeline, but we quickly discovered that many of our data management jobs could take place entirely within a BigQuery environment. For example, we use the command-line tool DBT, which offers support for BigQuery, to transform our data. It’s much easier for our developers and analysts to work with than Apache Spark since they can work directly in SQL. In addition, BigQuery allowed us to further simplify our data ingestion. Today, we mainly use Kafka Connect to sync data sources with BigQuery.
Looker + BigQuery puts the power of data in the hands of everyone
When our data was in the previous data lake architecture, it wasn’t easy to consume. The complexity of managing the data pipeline and running Spark jobs made it nearly impossible to expose it to users effectively. With BigQuery, ingesting data is not only easier, we also have multiple ways we can consume it through easy-to-use languages and interfaces. Ultimately, this makes our data more useful to a much wider audience.
Now that our BigQuery environment is in place, our analysts can query the warehouse directly using the SQL interface. In addition, Looker provides an even easier way for business users to interact with our data. Today, we have over 500 active users on Looker—more than half the company. Data modeled in BigQuery gets pushed out to our customer-facing applications, so that the dealers can log into a tool and manage stock or see how their inventory is performing.
Striking a balance between optimization and experimentation
Performance in BigQuery can be almost too robust: It will power through even very unoptimized queries. When we were starting out, we had a number of dashboards running very complex queries against data that was not well-modeled for the purpose, meaning every tile was demanding a lot of resources. Over time, we have learned to model data more appropriately before making it available to end-user analytics. With Looker, we use aggregate awareness, which allows users to run common query patterns across large data sets that have been pre-aggregated. The result is that the number of interactively run queries are relatively small.
The overall system comes together to create a very effective analytics environment — we have the flexibility and freedom to experiment with new queries and get them out to end users even before we fully understand the best way to model. For more established use cases, we can continue optimizing to save our resources for the new innovations. BigQuery’s slot reservation system also protects us from unanticipated cost overruns when we are experimenting.
One of the examples where this played out was when we rolled new analytic capabilities out to our sales teams. They wanted to use analytics to drive conversations with customers in real-time to demonstrate how advertisements were performing on our platform and show the customer’s return on their investment. When we initially released those dashboards, we saw a huge jump in usage of the slot pool. However, we were able to reshape the data quickly and make it more efficient to run the needed queries by matching our optimizations to the pattern of usage we were seeing.
Enabling decentralized data management
Another change we experienced with BigQuery is that business units are increasingly empowered to manage their own data and derive value from it. Historically, we had a centralized data team doing everything from ingesting data to modeling it to building out reports. As more people adopt BigQuery across Auto Trader, distributed teams build up their own analytics and create new data products. Recent examples include stock inventory reporting, trade marketing and financial reporting.
Going forward, we are focused on expanding BigQuery out into a self-service platform that enables analysts within the business to directly build what they need. Our central data team will then evolve into a shared service, focused on maintaining the data infrastructure and adding abstraction layers where needed so it is easier for those teams to perform their tasks and get the answers they need.
BigQuery kicks our data efforts into overdrive
At Auto Trader UK, we initially planned for BigQuery to play a specific part in our data management solution, but it has become the center of our data ingestion and access ecosystem. The robust performance of BigQuery allows us to get prototypes out to business users rapidly, which we can then optimize once we fully understand what types of queries will be run in the real world.
The ease of working with BigQuery through a well-established and familiar SQL interface has also enabled analysts across our entire organization to build their own dashboards and find innovative uses for our data without relying on our core team. Instead, they are free to focus on building an even richer toolset and data pipeline for the future.
For several decades, before the rise of cloud computing upended the way we think about databases and applications, Oracle and Microsoft SQL Server databases were a mainstay of business application architectures. But today, as you map out your cloud journey, you’re probably reevaluating your technology choices in light of the cloud’s vast possibilities and current industry trends.
In the database realm, these trends include a shift to open source technologies (especially to MySQL, PostgreSQL, and their derivatives), adoption of non-relational databases, and multi-cloud and hybrid-cloud strategies, and the need to support global, always-on applications. Each application may require a different cloud journey, whether it’s a quick lift-and-shift migration, a larger application modernization effort, or a complete transformation with a cloud-first database.
Google Cloud offers a suite of managed database services that support open source, third-party, and cloud-first database engines. At Next 2022, we published five new videos specifically for Oracle and SQL Server customers looking to either lift-and-shift to the cloud or fully free themselves from licensing and other restrictions. We hope you’ll find the videos useful in thinking through your options, whether you’re leaning towards a homogeneous migration (using the same database you have today) or a heterogeneous migration (switching to a different database engine).
Let’s dive into our five new videos.
#1 Running Oracle-based applications on Google Cloud
By Jagdeep Singh & Andy Colvin
Moving to the cloud may be difficult if your business depends on applications running on an Oracle Database. Some applications may have dependencies on Oracle for reasons such as compatibility, licensing, and management. Learn about several solutions from Google Cloud, including Bare Metal Solution for Oracle, a hardware solution certified and optimized for Oracle workloads, and solutions from cloud partners such as VMware and Equinix. See how you can run legacy workloads on Oracle while adopting modern cloud technologies for newer workloads.
#2 Running SQL Server-based applications on Google Cloud
By Isabella Lubin
Microsoft SQL Server remains a popular commercial database engine. Learn how to run SQL Server reliably and securely with Cloud SQL, a fully-managed database service for running MySQL, PostgreSQL and SQL Server workloads. In fact, Cloud SQL is trusted by some of the world’s largest enterprises with more than 90% of the top 100 Google Cloud customers using Cloud SQL. We’ll explore how to select the right database instance, how to migrate your database, how to work with standard SQL Server tools, and how to monitor your database and keep it up to date.
#3 Choosing a PostgreSQL database on Google Cloud
By Mohsin Imam
PostgreSQL is an industry-leading relational database widely admired for its permissive open source licensing, rich functionality, proven track record in the enterprise, and strong community of developers and tools. Google Cloud offers three fully-managed databases for PostgreSQL users: Cloud SQL, an easy-to-use fully-managed database service for open source PostgreSQL; AlloyDB, a PostgreSQL-compatible database service for applications that require an additional level of scalability, availability, and performance; and Cloud Spanner, a cloud-first database with unlimited global scale, 99.999% availability and a PostgreSQL interface. Learn which one is right for your application, how to migrate your database to the cloud, and how to get started.
#4 How to migrate and modernize your applications with Google Cloud databases
By Sandeep Brahmarouthu
Migrating your applications and databases to the cloud isn’t always easy. While simple workloads may just require a simple database lift-and-shift, custom enterprise applications may benefit from more complete modernization and transformation efforts. Learn about the managed database services available from Google Cloud, our approach to phased modernization, the database migration framework and programs that we offer, and how we can help you get started with a risk-free assessment.
#5 Getting started with Database Migration Service
By Shachar Guz & Inna Weiner
Migrating your databases to the cloud becomes very attractive as the cost of maintaining legacy databases increases. Google Cloud can help with your journey whether it’s a simple lift-and-shift, a database modernization to a modern, open source-based alternative, or a complete application transformation. Learn how Database Migration Service simplifies your migration with a serverless, secure platform that utilizes native replication for higher fidelity and greater reliability. See how database migration can be less complex, time-consuming and risky, and how to start your migration often in less than an hour.
We can’t wait to partner with you
Whichever path you take in your cloud journey, you’ll find that Google Cloud databases are scalable, reliable, secure and open. We’re looking forward to creating a new home for your Oracle- and SQL Server-based applications.
Marketing strategies based on complex and dynamic data get results. However, it’s no small task to extract easy-to-act-on insights from increasing volumes and ever-evolving sources of data including search engines, social media platforms, third-party services, and internal systems. That’s why organizations turn to us at Seer Interactive. We provide every client with differentiating analysis and analytics, SEO, paid media, and other channels and services that are based on fresh and reliable data, not stale data or just hunches.
More data, more ways
As digital commerce and footprints have become foundational for success over the past five years, we’ve experienced exponential growth in clientele. Keeping up with the unique analytics requirements of each client has required a fair amount of IT agility on our part. After outgrowing spreadsheets as our core BI tool, we adopted a well-known data visualization app only to find that it couldn’t scale with our growth and increasingly complex requirements either. We needed a solution that would allow us to pull hundreds of millions of data signals into one centralized system to give our clients as much strategic information as possible, while increasing our efficiency. After outlining our short- and long-term solution goals, we weighed the trade-offs of different designs. It was clear that the data replication required by our existing BI solution design was unsustainable.
Previously, all our customer-facing teams created their own insights. More than 200 consultants were spending hours each week pulling and compiling data for our clients, and then creating their own custom reports and dashboards. As data sets grew larger and larger, our desktop solutions simply didn’t have the processing power required to keep up, and we had to invest significant money in training any new employees in these complex BI processes. Our ability to best serve our customers was being jeopardized because we were having trouble serving basic needs, let alone advanced use cases.
We selected Looker, Google Cloud’s business intelligence solution, as our BI platform. As the direct query leader, Looker gives us the best available capabilities for real-time analytics and time to value. Instead of lifting and shifting, we designed a new, consolidated data analytics foundation with Looker that uses our existing BigQuery platform, which can scale with any amount and type of data. We then identified and tackled quick-win use cases that delivered immediate business value for our team and clients.
Meet users where they are in skills, requirements, and preferences
One of our first Looker projects involved redesigning our BI workflows. We built dashboards in Looker that automatically serve up the data our employees need, along with filters they use to customize insights and set up custom alerts. Users can now explore information on their own to answer new questions, knowing insights are reliable because they’re based on consistent data and definitions. More technical staff create ad hoc insights with governed datasets in BigQuery and use their preferred visualization tools like Looker Studio, Power BI, and Tableau. We’ve also duplicated some of our data lakes to give teams a sandbox that they can experiment in using Looker embedded analytics. This enables them to quickly see more data and uncover new opportunities that provide value to our clients. Our product development team is also able to build and test prototypes more quickly, letting us validate hypotheses for a subsection of clients before making them available across the company. And because Looker is cloud based, all our users can analyze as much data as they want without exceeding the computing power of their laptops.
Seamless security and faster development
We leverage BigQuery’s access and permissioning capabilities. Looker can inherit data permissions directly from BigQuery and multiple third-party CRMs, so we’ve also been able to add granular governance strategies within our Looker user groups. This powerful combination ensures that data is accessed only by users who have the right permissions. And Looker’s unique “in-database” architecture means that we aren’t replicating and storing any data on local devices, which reduces both our time and costs spent on data management while bolstering our security posture.
Better services and hundreds of thousands of dollars in savings
Time spent on repetitive tasks adds up over months and years. With Looker, we automate reports and alerts that people frequently create. Not only does this free up teams to discover insights that they previously wouldn’t have time to pinpoint, but they have fresh reports whenever they are needed. For instance, we automated the creation of multiple internal dashboards and external client analyses that utilize cross-channel data. In the past, before we had automation capabilities, we used to only generate these analyses up to four times a year. With Looker, we can scale and automate refreshed analyses instantly—and we can add alerts that flag trends as they emerge. We also use Looker dashboards and alerts to improve project management by identifying external issues such as teams who are nearing their allocated client budgets too quickly or internal retention concerns like employees who aren’t taking enough vacation time.
Using back-of-the-napkin math, let’s say every week 50 different people spend at least one hour looking up how team members are tracking their time. By building a dashboard that provides time-tracking insights at a glance, we save our collective team 2,500 hours a year. And if we assume the hourly billable rate is $200 an hour, we’re talking $500,000 in savings—just from one dashboard. Drew Meyer Director of Product, Seer Interactive
The insights and new offerings to stay ahead of trends
Looker enables us to deliver better experiences for our team members and clients that weren’t possible even two years ago, including faster development of analytics that improve our services and processes. For example, when off-the-shelf tools could not deliver the keyword-tracking insights and controls we required to deliver differentiating SEO strategies for clients, we created our own keyword rank tracking application using Looker embedded analytics. Our application provides deep-dive SEO data-exploration capabilities and gives teams unique flexibility in analyzing data while ensuring accurate, consistent insights. Going forward, we’ll continue adding new insights, data sources, and automations with Looker to create even better-informed marketing strategies that fuel our clients’ success.
Last September, various news outlets picked up the story of an AI-generated painting taking first place at the Colorado State Fair’s art contest. To create the winning piece, the contestant entered some text into Midjourney, an online app that creates images based on text input. The result is a piece called ‘Théâtre D’opéra Spatial,’ one of the first AI-generated images to win an art contest.
While the blue-ribbon finish is a milestone-worthy achievement in AI technology, not everyone is happy. Some artists have accused him of cheating, even though the contest didn’t explicitly prohibit AI-generated imagery. Others were understandably worried that they might lose their artistic jobs to robots in the future—‘the death of artistry,’ they commented.
But this story spurs another problem. Who can be the legitimate owner of creations that anyone can create using such programs? Is the practice considered plagiarism? As it stands, intellectual property law is partly prepared to tackle this.
How AI Generation Works
Ahmed Elgammal, director of Rutgers Art and Artificial Intelligence Laboratory, explains in his article published in American Scientist that these programs employ one of two algorithm classes. The majority of these programs use generative adversarial networks (GAN).
Contrary to popular belief, some human input is still necessary for running these programs, and GAN is proof of that. The user feeds the algorithm hundreds of pictures, and the algorithm tries to imitate them as best it can. Then, the user goes through the generated images, tweaking the algorithm based on the ones they deem acceptable.
The later iteration is the artificial intelligence creative adversarial network (AICAN), which the laboratory has been developing since 2017. It takes human input out of the equation, forcing the AI to learn through the images fed to it alone. AICAN’s results have surprised researchers, as they were so accurate that people couldn’t tell that AI made it.
The Ownership Dilemma
In both GAN and AICAN, Elgammal presents an interesting thought. When his team exhibited AICAN’s works throughout the United States, people constantly asked for the artist’s name. He stressed that while he developed the algorithm, he didn’t have control over what it would do. In this instance, is the rightful artist the algorithm itself or its creator?
It wasn’t this complicated before, as the human artist would be credited even if they used tools like paintbrushes or even Photoshop. After all, these tools could only act with direct input from the user. But with AI generation, AI can make decisions regardless of human input.
Amid the lack of a clear answer to this dilemma, other AI generation programs have made steps to allow their outputs to be used for commercial purposes. OpenAI went down this route with its DALL-E 2 system, as per its announcement last July, coinciding with the creation of paid plans.
The proliferation of AI-generated creations—not just images—will profoundly affect copyright and trademark application processes. Since applying for a trademark involves searching for any conflicting application, the likelihood of stumbling upon one can increase. Businesses might get stuck in needless intellectual property conflicts—a ‘legal minefield,’ as legal experts say.
The Law As It Stands
The legal implications of AI-generated creations are slowly inspiring actions. Following the case of ‘A Recent Entrance to Paradise,’ another AI-generated work, the U.S. Copyright Office said last February that such works aren’t eligible for copyright due to the lack of human authorship. The program responsible, Creativity Machine, created it with virtually no human input.
Then, in September, media repository Getty Images followed the example of some websites by banning AI-generated content. Its official statement stated concerns with the copyright status of such works and unaddressed relevant issues as the reasons for the move. Other similar websites have done so mainly in support of human-based creativity.
In spite of these developments, some blanks in the relevant legalese have yet to be filled, namely on the matter of fair use. According to an article published in the Texas Law Review, there’s no law upholding fair use of training datasets at the moment.
As mentioned earlier, AI generation programs rely on inputted data—such as publicly available images—to produce results. AICAN was fed around 80,000 works that have embodied Western art for the past 500 years. Most of these, if not all, were made with human hands, but there’s a good chance that some have copyright protection.
Legal experts ponder the implications of AI-generated work that uses copyrighted training data. Not only is it ineligible in the eyes of the U.S. Copyright Office, but it also raises the question if it’s considered plagiarism. Is it plagiarism if a user takes credit for an AI-generated creation? Is the program committing plagiarism if it takes copyrighted work?
The AI generation programs’ developers are cautious about guarantees. According to DALL-E’s Terms of Use, the program doesn’t guarantee that it’ll work as the user intended. Others, like Midjourney, are reluctant to provide legal assistance if the work gets involved in legal trouble.
Current Legal Options
Experts say it’s highly likely that the ambiguity regarding AI-generated content will remain in the following years. According to the World Intellectual Property Organization (WIPO), as it stands, the world currently has two legal options to rely on.
The first is, as demonstrated by the U.S. Copyright Office’s decision, to deny copyright to all non-human-generated content. Apart from the U.S., authorities in Australia and the European Union have settled similar cases by rejecting copyright applications on the grounds of works not being entirely made by human hands.
The second is to credit the creator for any work generated by any AI programs. This option is evident in the United Kingdom, as stated in Section 9(3) of the Copyright, Designs and Patents Act 1988, which not only gives credit to the human creator but also grants the work copyright protection. Other countries that have taken this approach include India, Ireland, and New Zealand.
Conclusion
Intellectual property law will struggle to catch up with the proliferation of AI-generated creations in the digital age. WIPO asserts that as the technology behind the programs evolves, the fine line between human-made and AI-generated art will blur. A time will come when distinguishing the two will be practically impossible, for which the law might not have an answer.