There are many benefits of leveraging analytics in healthcare. Hospitals and individual healthcare providers are using analytics tools to predict the likelihood a patient will develop a disease, minimize medical error rates, reduce costs of delivering treatment and provide a better overall patient experience.
However, there are some downsides to shifting towards a data-driven healthcare delivery model. One of the biggest issues is that the system can break down when healthcare organizations have trouble accessing data.
These problems become more pronounced when healthcare providers have Wi-Fi problems. Their data delivery models become disrupted, which hinders the entire organization.
Wi-Fi Connectivity Problems Can Cripple Data-Driven Healthcare Organizations
With the rise in telehealth services, a doctor’s visit no longer has to be an in-person affair. No more fighting traffic, taking time off from work, or finding a sitter for the kids or unruly pets. You can launch an app or a web browser and go through a medical consultation from the comfort of home.
Digital technology has not just made things more convenient for the patient. It has also made it easier for healthcare companies to store data and improve the efficiency of their business models. They can easily collect data through the company intranet or Internet services that engage with patients and third-party services.
But what happens when your Wi-Fi isn’t working properly? Is your data-driven healthcare organization going to suffer?
Although telehealth and online healthcare options offer patients more conveniences, they depend on reliable internet. Problems like slow and spotty connections can get in the way and make telehealth sessions difficult to impossible. Even if you just need to refill a prescription or schedule an appointment online, Wi-Fi issues create obstacles to healthcare. They can also create problems for companies that rely on the connection to collect data. Since data collection is vital to modern healthcare, this can be a huge problem for hospitals and other healthcare service providers.
Let’s look at some of the ways Wi-Fi difficulties could impact online medical services.
Weak Signal Strengths Equal Poor Connections
Most home Wi-Fi setups involve a single router or modem. While this solution may work OK in smaller apartments and condos, it’s more challenging in single-family homes. Even condos or townhomes with basements might struggle with poor signal strength if the modem is on the main floor. Symptoms of weak signal strength include dropped and slow connections.
This might not be a huge problem for regular consumers that don’t depend on data to be seamlessly transmitted for their lives to function. A poor connection might be annoying when it prevents you from streaming your favorite show. But it’s a real impediment when you’re discussing your medical history or trying to go over lab results. It can be a huge problem when you need to collect real-time data for your stakeholders. It can also be a problem when you need to make sure the data you are collecting is complete, so your data-driven healthcare organization can function properly. In addition, a virtual healthcare appointment is still an appointment in the eyes of providers and insurance companies. A doctor might reschedule, but you’re more likely to delay or give up on things without a stable connection.
Some people use signal boosters or mesh systems to solve Wi-Fi signal strength problems. However, a smart home Wi-Fi solution takes things a step further. The solution’s artificial intelligence learns how you use Wi-Fi in your home and adjusts the signal strength accordingly. Need more capacity in your home office at 10 a.m. and a boost in the living room during evening hours? Smart Wi-Fi’s on it. Slow and unreliable connections will become a distant memory.
Data Caps and Network Limitations Might Lead to Throttling
You may have heard about data caps and network limitations but don’t pay much attention to them. That is, until your Wi-Fi suddenly starts moving at the speed of a tortoise just as you’re showing the doctor your nasty rash. Or you look at your bill from last month and see extra charges for going over your plan’s data limits.
Data caps are something that service providers implement to discourage extensive network use. That’s because there’s only so much capacity, especially in areas with antiquated or insufficient infrastructure. During the pandemic, the FCC’s Keep America Connected Pledge encouraged ISPs to temporarily suspend data limits. The goal was to accommodate increased network activity from remote learning, work-from-home arrangements, and telehealth.
However, now that pandemic concerns have waned, data limits and ISP throttling practices are mostly back in place. Throttling is when your service provider slows down your Wi-Fi connection because of high network use. It could be because you’re over your data cap or the network is busy. Throttling can make it difficult to stream a telehealth session or use a health app.
Fortunately, some ISPs don’t impose data limits on a few plans, pandemic or no pandemic. They might also restrict their throttling practices to extreme circumstances related to infrastructure problems. Investigate your current provider’s practices and their competitors’ policies. If you can, switch your plan or carrier to one that better suits your needs.
To help expand healthcare access, the FCC gave out over $350 million in grants to medical organizations. These grants were meant to increase telehealth capabilities and services, particularly in remote areas with limited facilities. Yet these grants don’t help expand broadband access, which is what many people need to make telehealth work.
More bandwidth and higher speeds are necessary for videoconferencing and viewing or downloading graphic-intensive files. Just try to pull up a CT scan or MRI image on a slow connection, and you’ll struggle. But over 14 million homes in urban cities and another 4 million in remote areas still don’t have broadband internet.
Technically, broadband speeds begin at 25 Mbps for downloads and 3 Mbps for uploads. However, some say it’s not enough for telehealth services. That’s because homes are putting more strain on internet connections with multiple smart devices, remote work, gaming, and streaming. In areas where broadband infrastructure like fiber may be lacking, alternatives from cellular carriers can be viable options.
Wireless carriers leverage existing cell towers to provide broadband speed and capacity through fixed wireless or small cell technology. Some providers are doing this at a lower or stable cost for subscribers. People in remote towns don’t necessarily have to resort to DSL or satellite, which is prone to latency. That’s good news for those trying to keep telehealth appointments with far-off providers.
Wi-Fi Problems Create Problems for Data-Driven Healthcare Organizations
Online medical services are convenient and can reach patients who don’t live near doctors’ offices. However, telehealth isn’t possible without reliable internet and Wi-Fi connections. Issues like spotty signal strength, data caps, and a lack of broadband infrastructure create obstacles to adequate healthcare.
Getting around those obstacles requires innovative and alternative solutions, such as smart or adaptive Wi-Fi. More people can take advantage of online healthcare’s offerings and capabilities with these solutions. Healthcare providers will have more accurate data and can deliver more seamless services. After all, the promise of telehealth rests on more than its availability.
A growing number of businesses are discovering the importance of big data. Thirty-two percent of businesses have a formal data strategy and this number is rising year after year.
Unfortunately, they often have to deal with a variety of challenges when they manage their data. One of the biggest issues is with managing the tables in their SQL servers.
Renaming Tables is Important for SQL Server Management
Renaming a table in a database is one of the most common tasks a DBA will carry out. There are a lot of issues that you have to face when trying to manage an SQL database. One of them is knowing how to backup your data.
However, renaming tables is arguably even more important, since it is something that you will have to do regularly. In this article, you will see how to rename tables in SQL Server.
Depending upon the client application that you use to manage your SQL Server, there are multiple ways of renaming data tables in SQL Server. Some of the ways involve text queries while the other ways allow you to rename data tables in SQL Server via GUI.
In this article, you will see five main ways to rename tables in SQL Server to better manage your data:
Rename a table with SQLCMD UtilityRename a table with SQL Server Management Studio Query WindowRename a table with SQL Server Management Studio GUIRename a table with SQL Query Window in dbForge Studio for SQL ServerRename a Tables with GUI in dbForge Studio for SQL Server
As an example, you will be renaming a fictional “Item” table in the SALES database. The following script can be used to create such a table.
CREATE DATABASE SALES USE SALES CREATE TABLE Item ( Id INT, Name varchar(255), Price FLOAT );
Renaming Table Using SQLCMD Utility
SQLCMD is a command-line tool that can be used to perform various operations on SQL Server. The SQLCMD utility can also be used to rename tables in SQL. You can download the SQLCMD utility from the following link:
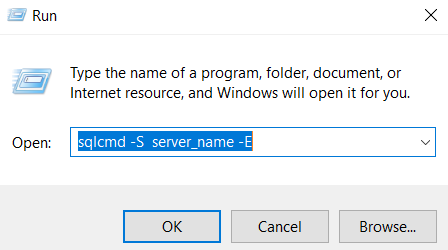
To open the utility in windows, open the “Run” shell, and enter the command:
“sqlcmd -S server_name -E”. Here E specifies that windows authentication is enabled to access the SQL Server. If Windows Authentication is not enabled, you will have to replace -E with the “-U your_user -P your_password” command.
The SQLCMD utility will open where you can execute SQL commands to perform different operations on your SQL Server instance.
Before we rename our Item table from the SALES table, let’s first print the table name. You can do so like this.
SELECT name FROM SALES.sys.tables
In the output, you will see the names of all the tables in the SALES database, as shown in the output below:
There is no direct SQL Query that can be used to rename a table in SQL Server. You need to execute the “sp_rename” stored procedure to rename a table in SQL Server.
The syntax for renaming a table in SQL Server via the “sp_rename” stored procedure is as follows:
EXEC sp_rename ‘old_table_name’, ‘new_table_name’
As an example, you will rename the “Item” table as “Product”. Here is how you can do it via SQLCMD utility:
From the output of the above command, you can see a warning which says that changing any part of an object’s name has the potential to break scripts and stored procedures.
This warning is important because if you have a script that interacts with the “Item” table using the name “Item”, that script will no longer execute since the table name is changed.
Finally, to see if the table has actually been renamed, you can again execute the following script:
SELECT name FROM SALES.sys.tables
As you can see above the table “Item” has been renamed to “Product”.
It is important to mention that if your original table name contains a dot [.] in it, you won’t be able to rename it directly.
For instance, if your SALES table has a table “Product.Items” that you want to rename as “Items” the following script will through an error
USE SALES EXEC sp_rename ‘Product.Items’, ‘Items’
The error says that no item with the name “Product.Items” could be found in the current database.
To rename a table that contains a dot in its name, you have to enclose the table name within square brackets as shown in the following script:
USE SALES EXEC sp_rename ‘[Product.Items]’, ‘Items’
From the output below, you can see no error or warning which means that the table has successfully been renamed.
Renaming Table Using SQL Server Management Studio
SQL Server Management Studio is a GUI-based tool developed by Microsoft that allows you to interact with SQL Server instances. SQL Server Management Studio can also be used to rename tables in SQL Server.
There are two main methods of renaming SQL Server tables via SQL Server Management Studio. You can either use the SQL Server query window, or you can directly rename a table via a mouse’s right click in the GUI. You will see both the methods in the following sections:
Renaming Table Using SQL Query Window
To rename a table via SQL query window in SQL Server Management Studio, click the “New Query” option from the main dashboard of your SQL Server Management Studio as shown in the following screenshot.
You can also see the “Item” table in the “SALES” database in the following screenshot. This is the table that you will be renaming.
The script for renaming a table via SQL query window is the same as the query you executed in SQLCMD. You have to execute the “sp_rename” stored procedure as shown in the following script.
USE SALES EXEC sp_rename ‘Item’, ‘Product’
In the output message window as shown in the following screenshot, you can again see the message which warns you that changing an object name can break the script.
You can use the command below to see if your table is renamed.
Alternatively, you could right click the database i.e. SALES -> Tables, click “Refresh” button from the list of options. You will see your renamed table.
SELECT name FROM SALES.sys.tables
It is worth mentioning that just as you saw with SQLCMD utility, renaming a table whose name contains a dot operator, requires enclosing the table name inside square brackets.
For instance, if you want to rename the “Product.Items” table to “Items”, the following query will through an error:
USE SALES EXEC sp_rename ‘Product.Items’, ‘Items’
On the other hand, enclosing the table name inside the square brackets will result in successful renaming of table, as shown in the output of the script below:
Renaming Table Using SSMS GUI
SQL Server Management Studio provides a lot of one-click options to perform different tasks. You can rename a table via SQL Server Management Studio GUI.
To do so, right click on the table that you want to rename. From the list of options that appear select “Rename” as shown in the following screenshot.
You will see that the text editing option will be enabled for the table that you want to rename, as shown in the below screenshot.
Here enter the new name for your table and click enter. Your table will be renamed.
Rename Table Using dBForge Studio for SQL Server
DBForge Studio for SQL Server is a flexible IDE that allows you to perform a range of database management, administration, and manipulation tasks on SQL Server using an easy-to-use GUI.
DBForge Studio for SQL Server also allows you to rename tables in SQL Server.
Just like SQL Server Management Studio, you have two options for renaming tables. You can either use the query window where you can execute SQL scripts for renaming tables, or you can directly rename a table by right-clicking a table name and then renaming it. You will see both the options in this section.
Connecting dBForge Studio with SQL Server
Before you can perform any operations on SQL Server via the dbForge Studio, you first have to connect the dbForge Studio with the SQL Server instance.
To do so, click the “New Connection” button from the main dashboard of dBForge studio.
You will see the “Database Connection Properties” window as shown below. Here enter the name of your SQL Server instance that you want to connect to, along with the authentication mode. Enter user and password if needed and click the “Test Connection” button.
If your connection is successful, you will see the following message.
Renaming Tables Using SQL Query Window in dbForge Studio
To rename tables using the SQL query window in dbForge Studio for SQL Server, click the “New SQL” option from the top menu. An empty query window will open where you can execute your SQL queries. Look at the following screenshot for reference.
The query to rename a table remains the same as you in the previous sections.
You use the “sp_rename” stored procedure.
The following script renames your “Item” table in th SALES database to “Product”.
USE SALES EXEC sp_rename ‘Item’, ‘Product’
The output below shows that the query was successful.
To see if the “Item” table has actually been renamed, run the script below:
SELECT name FROM SALES.sys.tables
In the output, the SALES database now contains the “Product” table instead of “Item” table.
As you saw with SQLCMD, and SQL Server Management Studio, if the table that has to be rename contains a dot (.) sign, you will have to enclose the table name inside square brackets in your SQL script.
Renaming Tables Using GUI in dbForge Studio
To rename tables via the GUI interface in SQL manager, simply right click the table that you want to rename. From the list of options, select “Rename”, as shown in the screenshot below:
Enter the new name for your table. In the following screenshot, we rename the “Item” table to “Product”. Click the Enter Key.
Finally, click the “Yes” button from the following message box to rename your table.
Knowing How to Rename Tables is Essential as a Data-Driven Business
There are many powerful big data tools that companies can use to improve productivity and efficiency. However, big data capabilities are not going to offer many benefits if you don’t know how to manage your SQL databases properly.
In this article we’ve looked at five different ways that you can rename a table in SQL Server using SQLCMD, SSMS, and dbForge Studio for SQL. You should follow these guidelines if you want to run a successful data-driven business that manages its data properly.
A growing number of businesses are relying on big data technology to improve productivity and address some of their most pressing challenges. Global companies are projected to spend over $297 billion on big data by 2030. Data technology has proven to be remarkably helpful for many businesses.
However, companies also encounter a number of challenges as they try to leverage the benefits of big data. One of their biggest frustrations is trying to manage their IT resources to store data effectively.
One of the biggest challenges they face is managing their SQL servers. This entails knowing how to use their cast functions properly. Keep reading to learn more.
Problem Statement
When dealing with Structured Query Language (SQL) and programming in general knowing the data types available to you in a given framework is pivotal to being efficient at your job.
Using the wrong data types for your tables can cause issues in the downstream applications which connect to the database, other databases joining to your data and Extract Transform Load (ETL) packages that extract data out.
In this post we will investigate a key function to help with the complexity that is presented with all these data types. In SQL Server this comes in the form of the CAST command. Cast allows you to change data type X to data type Y with varying restrictions. Some data types are unable to be cast to others and there are implicit data conversions and potential precision loss effects to be mindful of.
Syntax
–THE EXPRESSION FOR THE CAST OPERATOR WILL BE THE FIELD OR VALUE BEING FOLLOWED BY “AS” AND THE TARGET DATA TYPE.
SELECT CAST(EXPRESSION)
–CREATE AN EXAMPLE TABLE TO TEST CAST EXPRESSIONS
IF OBJECT_ID(N’tempdb..#CASTEXAMPLE’) IS NOT NULL DROP TABLE #CASTEXAMPLE
CREATE TABLE #CASTEXAMPLE
(
ID INT IDENTITY(1,1),
XFLOAT FLOAT,
XVARCHAR VARCHAR(10),
XBIT BIT,
XXML XML,
XDATETIME DATETIME,
XDECIMAL DECIMAL(5,2),
XNUMERIC NUMERIC
)
–INSERT 1 ROW OF DATA
INSERT INTO #CASTEXAMPLE
(XFLOAT,XVARCHAR,XBIT,XXML,XDATETIME,XDECIMAL,XNUMERIC)
SELECT 3.14,’PIE’,1,'<?xml version=”1.0″?><Root><Location LocationID=”1″><CityState>Salem, Alabama</CityState></Location></Root>’,GETDATE(), 100,50.01
–VIEW THE TABLE DATA
SELECT * FROM #CASTEXAMPLE
–CREATE ANOTHER EXAMPLE TABLE
CREATE TABLE #CASTJOIN
(
ID INT IDENTITY(1,1),
YVARCHAR VARCHAR(10),
YFLOAT FLOAT
)
INSERT INTO #CASTJOIN
(YVARCHAR,YFLOAT)
SELECT ‘3.14’,3.14
SELECT * FROM #CASTJOIN
Examples
Now that we have some data loaded, let’s take a look at some examples.
First lets look at the concept of explicit casting, explicit casting means that you will have to use CAST() to change the data type.
–EXPLICTLY CONVERT THE XFLOAT FIELD TO BINARY
SELECT CAST(XDECIMAL AS VARBINARY) as VarBinaryResult FROM #CASTEXAMPLE
In this example the decimal value 100.00 is converted to its binary value.
–EXPLICTLY CONVERT THE XFLOAT FIELD TO BINARY
SELECT CAST(XDECIMAL AS VARBINARY) as VarBinaryResult FROM #CASTEXAMPLE
This example fails, because in the #CASTEXAMPLE table, the value is a string ‘PIE’ which cannot be represented as an integer data type. However, if the VARCHAR value happens to be a valid integer value the cast will be successful.
–EXPLICTLY CAST THE XVARCHAR FIELD TO INT
SELECT CAST(XVARCHAR AS INT) as IntResult FROM #CASTEXAMPLE
But how can we be sure that this value is indeed an integer?
To verify our cast was successful we can utilize the sp_describe_first_result_set stored procedure which accepts a tsql string argument. For this procedure we will need double ticks in our string literal `1` in our query string.
–CHECK THE RESULT DATATYPE WITH sp_describe_first_result_set
sp_describe_first_result_set @tsql = N’SELECT CAST(”1” AS INT) as IntResult FROM #CASTEXAMPLE’
We can also validate the original data types of the temporary table we created.
–CHECK THE #CASTEXAMPLE TABLE
sp_describe_first_result_set @tsql = N’SELECT * FROM #CASTEXAMPLE’
The contrast to explicit casting is implicit casting which means that this conversion is taken care of for you automatically by SQL Server.
An example of when implicit joining comes into effect is if you are joining on a table with different data types. In this situation SQL server will recognize the data types need to be converted and do the conversion for you. This can add some compute cost to your query, so when dealing with one-to-many relationships it’s good to keep this in mind.
–IMPLICITY CAST ON JOIN
SELECT CE.XFLOAT,CJ.YFLOAT
FROM #CASTEXAMPLE AS CE
JOIN #CASTJOIN AS CJ
ON CE.XFLOAT = CJ.YVARCHAR
–PRECIOUS LOSS
When using the CAST() function you should also be aware of the potential of lost precision. This occurs when converting decimal to numeric or numeric to decimal data types in SQL Server.
Use the Cast Function Properly
In this post we discussed the syntax and use case for the SQL Server CAST() function. We covered the implicit and explicit cast functionality and the performance impacts that different data types can have when joining tables. Also we covered how to check a query results of a TSQL query to validate data types from the CAST() function. This is an important part of SQL database management and monitoring.
Cast is a very widely used function in SQL Server, database objects such as views and stored procedures can also use the CAST() function so understanding the functionality and how to use the function efficiency can save you time and effort! Be sure to experiment with different implementations of CAST() and make note of what works well for your specific environment.
For a better experience, try SQL autocomplete to assist with the various data casting options.
Data analytics technology has changed many aspects of the modern workplace. A growing number of companies are using data to make more informed hiring decisions, track payroll issues and resolve internal problems.
One of the most important benefits of data analytics is that it can help companies monitor employee performance and provide more accurate feedback. Keep reading to learn more about the benefits of a data-driven approach to conducting employee performance reviews.
Data Analytics Helps Companies Improve their Employee Performance Reviews
Managers state that delivering employee performance reviews is the second most dreaded and despised task they need to do. The first is firing an employee. This is understandable knowing how flawed and unfair a traditional employee performance appraisal system is.
Chris Westfall, the author of numerous books on management, thinks that poor communication between managers and employees is a serious issue affecting numerous businesses. According to statistics, an astonishing 62% of managers are reluctant to talk to their employees about anything, while one in five business leaders feel uncomfortable when it comes to recognizing employees’ achievements. This communication breakdown may be the reason why traditional feedback isn’t working.
These findings illustrate the benefits of shifting towards a data-driven approach to monitoring employee performance. An article in HR Voices titled Data Analytics in HR: Impacting the Future of Performance Management underscores some of the benefits. The authors state that data analytics saves managers time and reduces the risk of inadvertent bias.
“Using a software platform for data gathering and analytics is a huge time saver, and the application of verifiable facts and numbers to measure progress minimizes the bias that’s inherent in the old-school method of performance management,” the authors write.
Andy Przystanski of Lattice makes a similar argument. New HR analytics tools can use data to make better assessments of employee performance. They can even use data visualization to get a better understanding of individual and collective employee performance. They can make some unexpected insights based on data analytics tools.
One of the biggest flaws of traditional employee performance reports is that managers usually deliver them annually, focusing on things that are fresh in their memory. This approach to performance evaluation can’t paint a real and comprehensive picture of employees’ efforts or results. Performance and productivity fluctuate and you need real-time insights into these metrics to better understand overall employee performance.
Furthermore, when feedback isn’t data-driven it can be susceptible to managers’ opinions of an employee. And when feelings rule over accurate information, employees receive biased data that can lead to conflict within your teams.
Finally, traditional employee reviews are often vague, containing a single sentence or a phrase. They can also be time-consuming, requiring managers and employees to fill out numerous forms and handle tons of paperwork.
If you want to transform the employee performance appraisal process and make it more actionable and insightful, you can reach out for data collected via monitoring software for employees. By analyzing this information you’ll gain a better understanding of how your employees spend their time at work and create a transparent, objective, and actionable feedback.
Here are three ways that software for employee monitoring can help you to modernize the employee performance evaluation process and meet the employees’ requirements for more frequent objective feedback.
Annual Performance Evaluation is Time-Consuming
One of the reasons why managers may dread giving traditional feedback is that the entire process takes up so much of their precious time. If you want to be well prepared to deliver annual feedback, you and your employees need to fill out countless forms, wait for their approval, then you need to set and host performance appraisal meetings, and finally, deal with tons of paperwork.
And you’ll be doing this every year without any clear purpose or benefit for your employees or clients. This is because annual feedback isn’t based on relevant performance metrics and data that can show you what steps you need to take to improve employee performance or when it’s time to reward outstanding achievements.
Luckily, with the help of employee tracker data, you can create weekly, or monthly evaluations, identifying areas that need improvement and also recognizing effective practices. This monitoring software for employees can show you the time your employees spend on specific tasks, apps, and websites they use to complete these tasks and their productivity levels throughout a specific time.
You can use this information to create a real-time, objective, and most importantly timely feedback that can help your employees overcome specific issues and fulfill their potential. Or you can use it to celebrate stellar employee performance.
Traditional Feedback is Vague, Cryptic Without Clear Outcomes
Many employees state that their stress levels are skyrocketing when it’s time for annual performance reviews. They are worried that their managers will focus only on their most recent outcomes and productivity rates, forgetting to look at the big picture and recognize their overall contribution to the team or company. And their worries are justifiable.
This is especially true when managers compile annual evaluations in one sentence like “Good job” or “Your work needs improvements” without specifying what work aspects employees excel at or what steps they need to take to become more productive.
By doing this you show your employees that you aren’t invested in their professional development or, what’s worse, you fail to recognize their achievements. This attitude may frustrate your team members, motivating them to start looking for a more supportive and appreciative workplace.
If you want to prevent this worst-case scenario from happening, use real-time employee tracking system data to track your employees’ day-to-day performance, This information will help you record all the tasks and projects your employees have completed effectively over the year and also identify issues they’re struggling with, suggesting solutions on the spot.
In this way, you can set meaningful performance evaluation outcomes, provide additional support to employees in need, and promote top performers enabling them to develop personally and professionally. And you can use employee tracking data to keep an eye on their progress.
Data-Driven Approaches to Employee Performance Reviews Can Improve Fairness and Reduce Bias
There is no denying the fact that HR analytics is changing the state of the workforce. When your feedback isn’t data-driven it can often be clouded by your personal opinion about a specific employee. This is one of the main reasons why many employees think that traditional performance evaluations aren’t fair and they are a thing of the past.
Therefore, you should foster open communication, offering frequent feedback based among other significant factors on data collected via monitoring software for employees. This is especially important for managers running remote teams with employees that may feel unseen or detached from the rest of the team.
When using employee monitoring reports to complement employee feedback, you’ll eliminate bias by offering accurate and objective performance insights. This will promote much-needed equity in the workplace where every employee will be valued by their achievements and dedication to the team rather than by favoritism.
Editor’s note: In part one of this blog, Wayfair shared how it supports each of its 30 million active customers using machine learning (ML). Wayfair’s Vinay Narayana, Head of ML Engineering, Bas Geerdink, Lead ML Engineer, and Christian Rehm, Senior Machine Learning Engineer, take us on a deeper dive into the ways Wayfair’s data scientists are using Vertex AI to improve model productionization, serving, and operational readiness velocity. The authors would like to thank Hasan Khan, Principal Architect, Google for contributions to this blog.
When Google announced its Vertex AI platform in 2021, the timing coincided perfectly with our search for a comprehensive and reliable AI Platform. Although we’d been working on our migration to Google Cloud over the previous couple of years, we knew that our work wouldn’t be complete once we were in the cloud. We’d simply be ready to take one more step in our workload modernization efforts, and move away from deploying and serving our ML models using legacy infrastructure components that struggle with stability and operational overhead. This has been a crucial part of our journey towards MLOps excellence, in which Vertex AI has proved to be of great support.
Carving the path towards MLOps excellence
Our MLOps vision at Wayfair is to deliver tools that support the collaboration between our internal teams, and enable data scientists to access reliable data while automating data processing, model training, evaluation and validation. Data scientists need autonomy to productionize their models for batch or online serving, and to continuously monitor their data and models in production. Our aim with Vertex AI is to empower data scientists to productionize models and easily monitor and evolve them without depending on engineers. Vertex AI gives us the infrastructure to do this with tools for training, validating, and deploying ML models and pipelines.
Previously, our lack of a comprehensive AI platform resulted in every data science team having to build their own unique model productionization processes on legacy infrastructure components. We also lacked a centralized feature store, which could benefit all ML projects at Wayfair. With this in mind, we chose to focus our initial adoption of the Vertex AI platform on its Feature Store component.
An initial POC confirmed that data scientists can easily get features from the Feature Store for training models, and that it makes it very easy to serve the models for batch or online inference with a single line of code. The Feature Store also automatically manages performance for batch and online requests. These results encouraged us to evaluate the adoption of Vertex AI Pipelines next, as the existing tech for workflow orchestration at Wayfair slowed us down greatly. As it turns out, both of these services are fundamental to several models we build and serve at Wayfair today.
Empowering data scientists to focus on building world-class ML models
Since adopting Vertex AI Feature Store and AI Pipelines, we’ve added a couple of capabilities at Wayfair to significantly improve our user experience and lower the bar to entry for data scientists to leverage Vertex AI and all it has to offer:
1. Building a CI/CD and scheduling pipeline
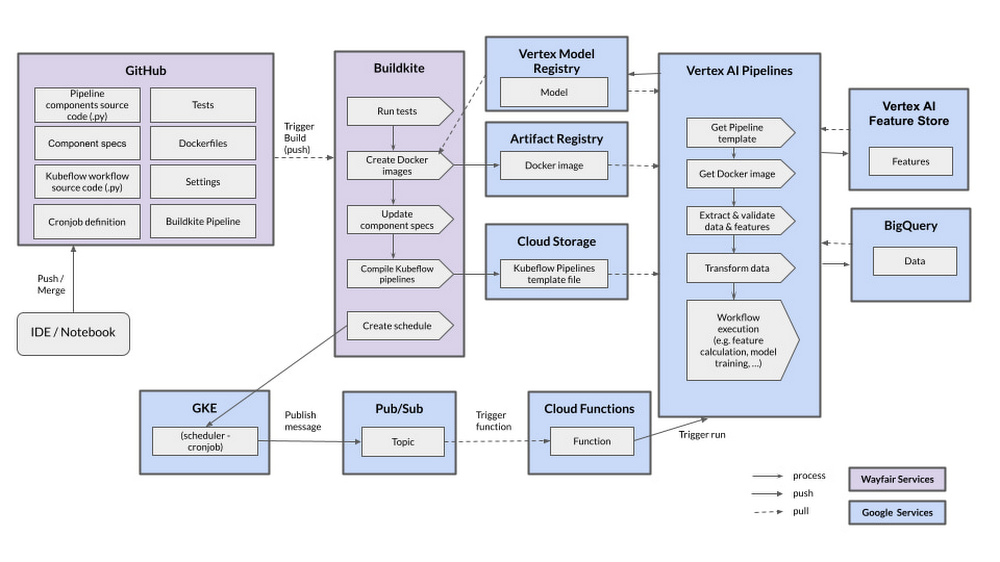
Working with the Google team, we built an efficient CI/CD and scheduling pipeline based on the common tools and best practices at Wayfair and Google. This enables us to release Vertex AI Pipelines to our test and production environments, leveraging cloud-native services.
Keeping in mind that all our code is managed in GitHub Enterprise, we have dedicated repositories for Vertex AI Pipelines where the Kubeflow code and definitions of the Docker images are stored. If a change is pushed to a branch, a build starts in the Buildkite tool automatically. The build contains several steps, including unit and integration tests, code linting, documentation generation and automated deployment. The most important artifacts that are released at the end of the build are the Docker image and the compiled Kubeflow template. The Docker image is released to the Google Cloud Artifact Registry and we store the Kubeflow template in a dedicated Google Cloud Storage Bucket, fully versioned and secured. This way, all the components we need to run a Vertex AI Pipeline are available once we run a pipeline (manually or scheduled).
To schedule pipelines, we developed a dedicated Cloud Function that has the permissions to run the pipeline. This Function listens to a Pub/Sub topic where we can publish messages with a defined schema that indicates which pipeline to run with which parameters. These messages are published from a simple cron job that runs according to a set schedule on Google Kubernetes Engine. This way, we have a decoupled and secure environment for scheduling pipelines, using fully-supported and managed infrastructure.
2. Abstracting Vertex AI services with a shared library
We abstracted the relevant Vertex AI services currently in use with a thin shared Python library to support the teams that develop new software or migrate to Vertex AI. This library, called `wf-vertex`, contains helper methods, examples, and documentation for working with Vertex AI, as well as guidelines for Vertex AI Feature Store, Pipelines, and Artifact Registry.
One example is the `run_pipeline` method, which publishes a message with the correct schema to the Pub/Sub topic so that a Vertex AI pipeline is executed. When scheduling a pipeline, the developer only needs to call this method without having to worry about security or infrastructure configuration:
code_block[StructValue([(u’code’, u’@cli.command()rndef trigger_pipeline() -> None:rn from wf_vertex.pipelines.pipeline_runner import run_pipelinernrn run_pipeline(rn template_bucket= f”wf-vertex-pipelines-{env}/{TEAM}”, # this is the location of the template, where the CI/CD has written the compiled templates torn template_filename=”sample_pipeline.json”, # this is the filename of the pipeline template to runrn parameter_values= {“import_date”: today()} # itu2019s possible to add pipeline parametersrn )’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e90dc959c50>)])]
Most notable is the establishment of a documented best practice for enabling hyperparameter tuning in Vertex AI Pipelines, which speeds up hyperparameter tuning times for our data scientists from two weeks to under one hour.
Because it is not yet possible to combine the outputs of parallel steps (components) in Kubeflow, we designed a mechanism to enable this. It entails defining parameters at runtime and executing the resulting steps in parallel via the Kubeflow parallel-for operator. Finally, we created a step to combine the results of these parallel steps and interpret the results. In turn, this mechanism allows us to select the best model in terms of accuracy from a set of candidates that are trained in parallel:
Our CI/CD, scheduling pipelines, and shared library have reduced the effort of model productionization from more than three months to about four weeks. As we continue to build the shared library, and as our team members continue to gain expertise in using Vertex AI, we expect to further reduce this time to two weeks by the end of 2022.
Looking forward to more MLOps capabilities
Looking ahead, our goal is to fully leverage all the Vertex AI features to continue modernizing our MLOps stack to a point where data scientists are fully autonomous from engineers for any of their model productionization efforts. Next on our radar are Vertex AI Model Registry and Vertex ML Metadata alongside making more use of AutoML capabilities. We’re experimenting with Vertex AI for AutoML models and endpoints to benefit some use cases at Wayfair next to the custom models that we’re currently serving in production.
We’re confident that our MLOps transformation will introduce several capabilities to our team, including: automated data and model monitoring steps to the pipeline, as well as metadata management, and architectural patterns in support of real-time models requiring access to Wayfair’s network. We also look forward to performing continuous training of models by fully automating the ML pipeline that allows us to achieve continuous integration, delivery, and deployment of model prediction services.
We’ll continue to collaborate and invest in building a robust Wayfair-focused Vertex AI shared library. The aim is to eventually migrate 100% of our batch models to Vertex AI. Great things to look forward to on our journey towards MLOps excellence.
Modern businesses are increasingly relying on real-time insights to stay ahead of their competition. Whether it’s to expedite human decision-making or fully automate decisions, such insights require the ability to run hybrid transactional analytical workloads that often involve multiple data sources.
BigQuery is Google Cloud’s serverless, multi-cloud data warehouse that simplifies analytics by bringing together data from multiple sources. Cloud Bigtable is Google Cloud’s fully-managed, NoSQL database for time-sensitive transactional and analytical workloads.
Customers use Bigtable for a wide range of use cases such as real time fraud detection, recommendations, personalization and time series. Data generated by these use cases has significant business value.
Historically, while it has been possible to use ETL tools like Dataflow to copy data from Bigtable into BigQuery to unlock this value, this approach has several shortcomings, such as data freshness issues and paying twice for the storage of the same data, not to mention having to maintain an ETL pipeline. Considering the fact that many Bigtable customers store hundreds of Terabytes or even Petabytes of data, duplication can be quite costly. Moreover, copying data using daily ETL jobs hinders your ability to derive insights from up-to-date data which can be a significant competitive advantage for your business.
Today, with the General Availability of Bigtable federated queries with BigQuery, you can query data residing in Bigtable via BigQuery faster, without moving or copying the data, in all Google Cloud regions with increased federated query concurrency limits, closing a longstanding gap between operational data and analytics.
During our feature preview period, we heard about two common patterns from our customers.
Enriching Bigtable data with additional attributes from other data sources (using SQL JOIN operator) such as BigQuery tables and other external databases (e.g. CloudSQL, Spanner) or file formats (e.g. CSV, Parquet) supported by BigQuery
Combining hot data in Bigtable with cold data in BigQuery for longitudinal data analysis over long time periods (using SQL UNION operator)
Let’s take a look at how to set up federated queries so BigQuery can access data stored in Bigtable.
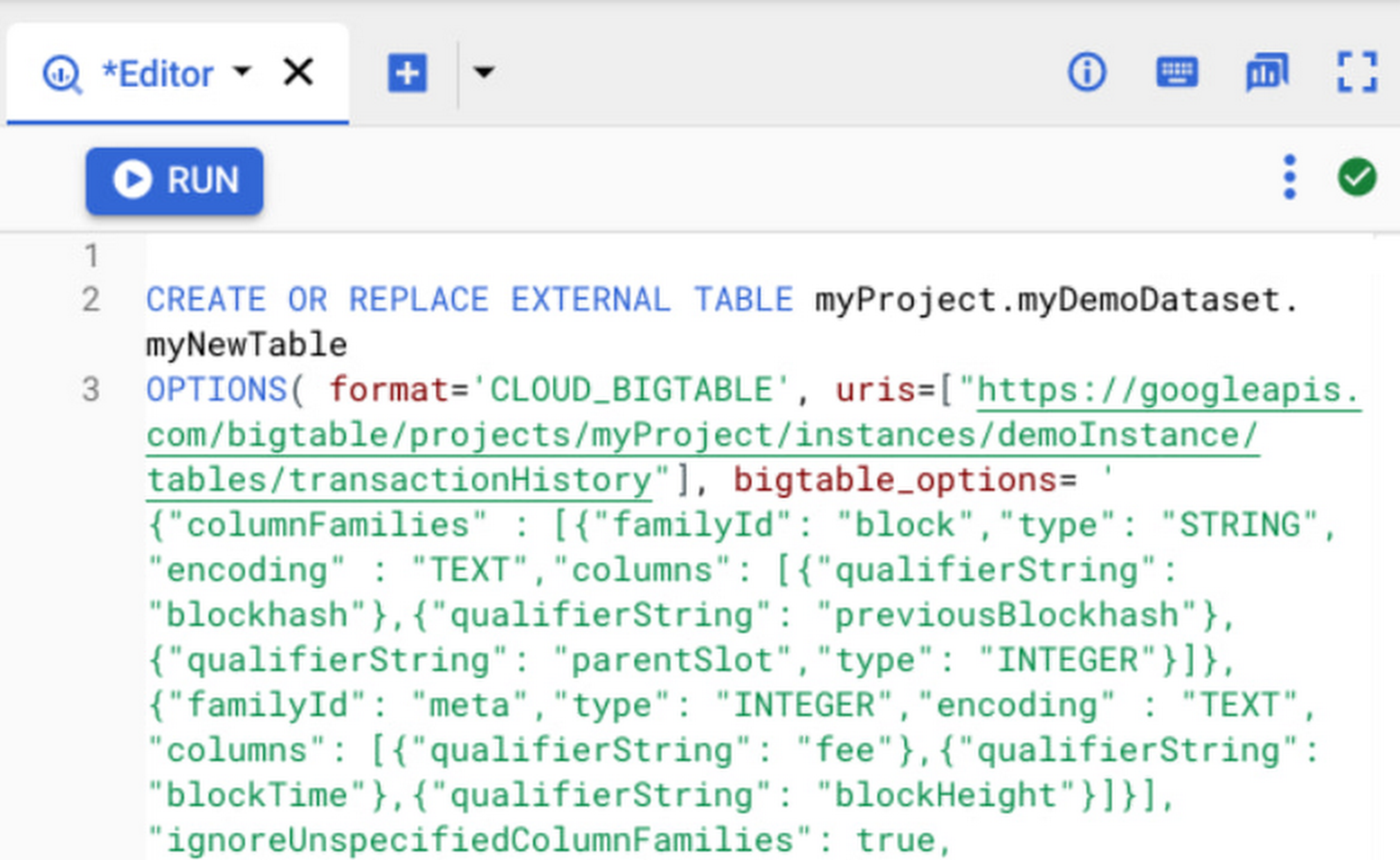
Setting up an external table
Suppose you’re storing digital currency transaction logs in Bigtable. You can create an external table to make this data accessible inside BigQuery using a statement like the following.
External table configuration provides BigQuery with information like column families, whether to return multiple versions for a record, column encoding and data types given Bigtable allows for a flexible schema with 1000s of columns and varying encodings with version history. You can also specify app profiles to reroute these analytical queries to a different cluster and/or track relevant metrics like CPU utilization separately.
Writing a query that accesses the Bigtable data
You can query external tables backed by Bigtable just like any other table in BigQuery.
code_block[StructValue([(u’code’, u’SELECT *rn FROM `myProject.myDataset.TransactionHistory`’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e45dd909650>)])]
The query will be executed by Bigtable, so you’ll be able to take advantage of Bigtable’s high throughput, low-latency database engine and quickly identify the requested columns and relevant rows within the selected row range even across a petabyte dataset. However note that unbounded queries like the example above could take a long time to execute over large tables so to achieve short response times make sure a rowkey filter is provided as part of the WHERE clause.
code_block[StructValue([(u’code’, u”SELECT SPLIT(rowkey, ‘#’)[OFFSET(1)] AS TransactionID,rn SPLIT(rowkey, ‘#’)[OFFSET(2)] AS BillingMethodrn FROM `myProject.myDataset.TransactionHistory`rn WHERE rowkey LIKE ‘2022%'”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e45cde1fe50>)])]
Query operators not supported by Bigtable will be executed by BigQuery with the required data streamed to BigQuery’s database engine seamlessly.
The external table we created can also take advantage of BigQuery features like JDBC/ODBC drivers and connectors for popular Business Intelligence and data visualization tools such as DataStudio, Looker and Tableau, in addition to AutoML tables for training machine learning models and BigQuery’s Spark connector for data scientists to load data into their model development environments.
To use the data in Spark you’ll need to provide a SQL query as shown in the PySpark example below. Note that the code for creating the Spark session is excluded for brevity.
In some cases, you may want to create views to reformat the data into flat tables since Bigtable is a NoSQL database that allows for nested data structures.
code_block[StructValue([(u’code’, u’SELECT rowkey as AccountID, i.timestamp as TransactionTime, rn i.value as SKU, m.value as Merchant, c.value AS Chargern FROM `myProject.myDataset.TransactionHistory`, rn UNNEST(transaction.Item.cell) AS i rn LEFT JOIN UNNEST(transaction.Merchant.cell) AS m rn ON m.timestamp = i.timestamprn LEFT JOIN UNNEST(transaction.Charge.cell) AS c rn ON m.timestamp = c.timestamp’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e45ded85f90>)])]
If your data includes JSON objects embedded in Bigtable cells, you can use BigQuery’s JSON functions to extract the object contents.
You can also use external tables to copy the data over to BigQuery rather than writing ETL jobs. If you’re exporting one day worth of data for the stock symbol GOOGL for some exploratory data analysis, the query might look like the example below.
code_block[StructValue([(u’code’, u”INSERT INTO `myProject.myDataset.MyBigQueryTable` rn (symbol, volume, price, timestamp) rn SELECT ‘GOOGL’, volume, price, timestamprn FROM `myProject.myDataset.BigtableView` rn WHERE rowkey >= ‘GOOGL#2022-07-07’ rn AND rowkey < ‘GOOGL#2022-07-08′”), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e45ded85890>)])]
Learn more
To get started with Bigtable, try it out with a Qwiklab.
You can learn more about Bigtable’s federated queries with BigQuery in the product documentation.
Today we are announcing Data Studio, our self-service business intelligence and data visualization product, as a Google Cloud service, enabling customers to get Data Studio on the Google Cloud terms of service, simplifying product acquisition and integration in their company’s technology stack.
Why are we doing this?
Google Cloud customers of all types widely use Data Studio today as a critical piece of their business intelligence measurement and reporting workflow. Many of our customers have asked for Data Studio on Google Cloud terms, to ensure Google supports the same privacy and security commitments for Data Studio as for other Google Cloud products. Now, that’s possible.
What benefits do customers get?
Data Studio now supports additional compliance standards for internal auditing, controls and information system security, including SOC 1, SOC 2, SOC 3 and PCI DSS, with more compliance certifications coming soon. Data Studio can be used under the same terms as other Google Cloud services, reducing procurement complexity and enabling it to be covered by customers’ existing Cloud Master Agreement.
If customers are subject to HIPAA and have signed a Google Cloud Business Associate Amendment (BAA), it will apply to Data Studio as well. Data Studio is still free to use, although as a free offering, it is not currently supported through Google Cloud support.
What’s not changing
This additional certification does not change a single pixel of the end-user experience for Data Studio. Customers can still analyze their data, create beautiful reports, and share insights using all of Data Studio’s self-service BI functionality with no disruption. For customers who aren’t yet using Google Cloud, Data Studio will continue to be available under our existing terms and conditions as well.
When everyone is empowered to dig into data, the results can be transformational. This is just the beginning of our investment in making the power of Google Cloud accessible to everyone through easy-to-use cloud BI.
As consumer data privacy regulations tighten and the end of third-party cookies looms, organizations of all sizes may be looking to carve a path toward consent-positive, privacy-centric ways of working. Consumer-facing brands should look more closely at the customer data they’re collecting, and learn to embrace a first-party data-driven approach to doing business.
But while brands today recognize the privacy and consumer consent imperative, many may not know where to start. What’s worse is that many don’t know what consumers really want when it comes to data privacy. Today, 40% of consumers do not trust brands to use their data ethically (KPMG)1.There is room, however, for improvement.
Although the gap between how brands and consumers think about privacy is evident, it doesn’t need to continue to widen. Organizations must begin to treat consumer data privacy as a pillar of their business: as a core value that guides the way data is used, processes are run, and teams behave. By implementing a cross-functional data advocacy panel, brands can ensure that the protection of consumer data is always top of mind — and that a dedicated team remains accountable for guaranteeing privacy-centricity throughout the organization.
Why a data advocacy panel?
Winning brands see the customer data privacy imperative as an opportunity, not a threat. Consumers today are clear about what they want, and it’s simply up to brands to deliver. First and foremost, transparency is key. Most consumers are already demanding more transparency from the brands they frequent, but as many as 40% of consumers would willingly share personal information if they knew how it would be used (KPMG)1.This simple value exchange could be the key to a first-party data-driven future. So what’s deterring businesses from taking action?
Organizational change can seem like a daunting undertaking, and many businesses who do recognize the importance of consumer data privacy simply don’t know how to move forward. What steps can they take? Where do they start? How can they prepare? In addition, how can they make sure the improvements they invest in have an impact now and in the long term? A data advocacy panel, woven into the DNA of the organization, can serve as a north star for consent-positivity.
How can I implement a data advocacy panel?
A data advocacy panel’s mission focuses on building and maintaining a consent-positive culture across an organization. It can serve as a way to hone the power of customer data for your business while also giving the power of consent to your customers. And in an era when most business decisions are (and should be) driven by data, having a data advocacy panel makes a world of sense.
But what exactly does a data advocacy panel look like? Importantly, you need to include the right players. Your data advocacy panel should include representatives from every business unit that has responsibility for protecting, collecting, creating, sharing, or accessing data of any kind. These members might include marketing, IT/security, Legal, HR, accounting, customer service, sales, and/or partner relations.
These team members should then come together to tackle two key goals: to set the strategy and policies for how data is handled throughout the organization, and to react quickly to new data developments such as:
a potential data breach,
shifting market sentiments, or
new compliance requirements
It should be the responsibility of the data advocacy panel to help decide how, when, why, and where data is used in your business.
Once a company has established a data advocacy panel, they’ve also built a foundation upon which to create a new and future-ready organizational structure that will provide maximal transparency and auditability, explainability, and expanded support for how first-party consumer data is collected, joined, stored, managed, and activated.
The value of consumer consent, data advocacy, and privacy-centricity
How do you become, not just a privacy-minded, but a consent-positive brand?
According to Google Cloud’s VP of Consumer Packaged Goods, Giusy Buonfantino, “The changing privacy landscape and shifting consumer expectations mean companies must fundamentally rethink how they collect, analyze, store, and manage consumer data to drive better business performance and provide customers with personalized experiences.”
The changing privacy landscape and shifting consumer expectations mean companies must fundamentally rethink how they collect, analyze, store, and manage consumer data to drive better business performance and provide customers with personalized experiences. Giusy Buonfantino Google Cloud’s VP of Consumer Packaged Goods
Companies are adopting Customer Data Platforms (CDP) to enable a privacy-centric engagement with their customers. Lytics’ customer data platform solution is built with Google Cloud BigQuery to help enterprises continue to evolve how they capture and use consumer data in our changing environment. Lytics on BigQuery helps businesses collect and interpret first-party behavioral customer data on a secure and scalable platform with built-in machine learning.
Reggie Wideman, Head of Strategy, Lytics noted, “By design, traditional CDPs create enormous risk by asking the company to collect and unify customer data in the CDP system, separate from all other customer data and outside of your internal controls and governance. We think there’s a better, smarter way. By taking a composable CDP approach we enable companies to layer our tools into their existing martech ecosystems, rather than being forced to build around a proprietary, external CDP toolset.”
By design, traditional CDPs create enormous risk by asking the company to collect and unify customer data in the CDP system, separate from all other customer data and outside of your internal controls and governance. We think there’s a better, smarter way. Reggie Wideman Head of Strategy, Lytics
Wideman continues, ”This allows us to enable developers and data managers to create a ‘Customer 360’ in their own secure, privacy-compliant data warehouse. The advantage of this approach is a privacy-centric architecture that collects and unifies customer data creating a profile schema that is synced to the customer’s data warehouse, helping internal data teams build and manage a secure, persistent ‘Customer 360’, while also providing a direct sync to marketing tools and channels for targeted advertising and activation.”
In short, it’s not just about small tweaks and minor changes. It’s about starting with a catalyst that will drive larger-scale change. That catalyst is your data advocacy panel, and it is and will continue to be at the center of the value exchange between your brand and your customers.
“The importance of ‘consumer consent’ and ‘value exchange’ is front and center in the conversations we are having with our customers,” shares Buonfantino, “And first-party data done right can help drive more meaningful high-value consumer engagement.”
For more information on data advocacy panels, how to implement them, and how they bring the power of your customer data to every employee, readthe whitepaper. In addition, we invite you to explore the Lytics CDP on the Google Cloud Marketplace.
A report by Entrepreneur shows that companies that use big data have 8% higher profits. They also cut expenses by an average of 10%.
There are tons of great benefits of using big data to run your company. You can improve marketing strategies with big data, improve employee productivity, meet compliance targets and track trends more easily.
However, running a data-driven startup is not easy. You have to have the right infrastructure in place. This includes investing in the best electronic devices.
Data-Driven Startups Have to Invest in the Right Electronic Tools
When it comes to shopping online for electronic products, we need to be extra careful. These products have a higher chance of failure because they involve a combination of technologies from multiple fields. Micro components, electronic circuitry, mechanical and thermal strength, and logic are only some of the factors that must be taken into consideration.
This can be a huge issue for data-driven startups. They rely on their electronic devices even more than your average consumer. If their device is compromised, they can lose access to loads of valuable data. The entire future of their company could be at risk.
The good news is that there are also several ways for you to shop online and get your hands on some of the finest electronic products. You will also be able to find some of these retailers offer some amazing deals. Read on ahead to learn about some of these ways that are briefly listed below.
Buy Directly From Manufacturer Websites
The last on this list, which according to us, is one of the best (if not the best) ways of shopping online. Due to the communication advantages of using the internet, it is much easier to get in contact directly with the manufacturers. Buying directly from the manufacturer’s website can serve many advantages. The first and most important one is their expertise. Since they are the ones making and designing the product they have expertise that wholesalers or retailers might not be able to offer. In addition, you can easily request bespoke and custom-made designs to suit your requirements. Another benefit is that you can cut out the middleman, which means that you can even shop at lower prices.
As a data-driven startup, this could be a great idea. You want to find quality suppliers that can give you electronic devices that can reliably store your sensitive data. What better supplier can you find than the manufacturers themselves?
Shop at TME Electronics
TME Electronics is one of the biggest manufacturers and suppliers of electronic products in all of Europe. The business first started off as a family company that offered electronic components for service and small production purposes back in 1990. Over the years, TME Electronics has established itself as the primary distributor of electronic, electromechanical, industrial, automatic, and workplace equipment. Data-driven companies may find that they are one of the best electronic suppliers to work with.
As of July 2022, it serves 133 countries and ships 3,700 packages each day for local as well as overseas deliveries. Finally, it offers 190 unique products for single and bulk orders while the stock for a single product, such as the microswitches or other electronic components.
Shop at Online Stores
This category needs little to no introduction as most of us are familiar with famous online stores such as Amazon.com. You can find almost any product here and at competitive prices as well. They offer a lot of great electronic devices that can make it easier to store vast amounts of data that your company will need to run efficiently.
These websites have a huge list of sellers selling electronic products of multiple variations. For the sellers, these websites offer the platform to run their shops online without having to go into the complexities of building a brand or a website and running paid ads. The platform will do it for them. The platform acts as a sort of middleman between the buyers and sellers.
Shop at Third Party Sites
Some third-party websites such as TechBargains offer the amazing opportunity to find an electronic product, that we are specifically searching for, and also at the best prices. These websites scour the internet to bring you results from hundreds of different stores. You can then compare the prices and choose from the one that seems the most attractive. Furthermore, these will also let you cash on limited-time deals if any are going on at a website.
That’s not all, some browser extensions such as Honey will also help you save money when shopping for electronic products online. These extensions will automatically search for coupons on a website. You can then easily add the coupon code on the payment page for some additional discount (yay!).
Shop at Community Driven Websites
Community-driven websites like Slickdeals work independently of any buyer or seller but rather through the community. On the first look, you will see the website looks like an online shop, but the deals you will see are submitted by members of the community. For quality purposes, the rest of the community voted on the deal so you will see the top-rated ones first.
These websites would often hire curators as well. These people review the product by testing it out. So, if you’re looking for a specific type of microswitch, for example, whether it is a snap action or tact, you will most likely find a review or at least a deal that hasn’t been listed by any retailer or seller. Instead, by a member who has probably used the product before.
Data-Driven Startups Must Invest in Quality Electronic Devices
You can find a lot of great electronic devices that make it easier to run a startup that depends on big data. These options will make it easier to find the ones that you need.
Artificial intelligence has led to some pivotal changes in the financial sector. Fintech companies are projected to spend over $12 billion on AI this year.
A growing number of traders are taking advantage of AI technology to make more informed trading decisions. AI technology has actually changed stock market investing as we know it.
Algorithmic trading refers to a method of trading based on pre-programmed instructions fed to a computer. It relies on sophisticated AI capabilities. It’s the inverse of the conventional type of trading where people make decisions based on sentiments and convictions.
Algorithmic trading aims to capitalize on the greater speed and mathematical power of computers relative to human traders to get better results. The AI algorithms that it uses can identify trading opportunities most humans would have missed. It’s a massive sector, worth $13 billion as of 2021, and yet still growing, projected to witness a compound annual growth rate (CAGR) of 10.5% from 2022 to 2027.
There are many requirements to be a successful algorithmic trader and the most critical one is knowledge of both the AI technology behind it and the strategies that help it work effectively. You must have detailed and up-to-date facts about the financial markets to make smart decisions. You also need sufficient computer programming knowledge and a background in AI to generate machine learning algorithms and implement them using codes the computer can understand directly.
You can get the required knowledge and skills to be an algorithmic trader in many venues, e.g., in college, a local library, coding boot camp, etc, which are fairly common. There are also some uncommon mediums, such as anonymous online communities, that are often overlooked.
We consider anonymous communities to be an excellent platform through which algorithmic traders can gain knowledge about their field, with clear reasons. They can create AI applications that can streamline their trading decisions.
Why anonymous online communities?
One of the best things about the internet is anonymity, although it has its downsides. An anonymous community is an equalizer, where people are judged primarily on their contributions instead of clout. This factor constitutes a motivation for users to help each other with solutions and maintain the vibrance of the community. They can help each other learn more about AI to develop valuable applications to improve their trading decisions.
Best online algorithmic trading communities
The key for algorithmic traders to learn through the web is to know which communities cater to their needs. There are many such communities to choose from, but some are better than others. Some of the better ones aren’t even popular but offer great value to their users.
The best online communities for algorithmic traders to learn more about AI include;
● QuantConnect Community
QuantConnect is one of the most popular platforms for algorithmic trading, and it includes an online community where users can converse in tandem. The trading platform has processed over $13 billion in trades since its inception, indicating a large user base. Many people can learn about the benefits of AI technology with it.
On the official QuantConnect community, you can find a vast range of discussions concerning automated trading and participate in them. The topics are categorized, making them easy to find. For example, you can find discussion threads on stock selection strategies and risk management.
One of the features that QuantConnect uses to encourage discussion is by providing cloud credits to active community members that they can use on the trading platform. This system encourages the most skillful traders to share their knowledge to earn credits.
You’re free to participate anonymously in the QuantConnect community as many people do. But, you can also use your real-world identity if you wish.
● Reddit
Reddit may need no introduction, as it’s very popular, with over 430 million monthly active users. It’s a news aggregation and discussion website containing thousands of distinct communities (called subreddits).
There are many people on Reddit with a strong background in AI development. With a massive user base, Reddit represents a hub of information for people that care to seek them. The key here is knowing which subreddits cater to algorithmic traders, and some of the best ones include r/algotrading, r/algorithmictrading, and r/python.
R/algotrading is the most popular algorithmic trading subreddit, with 1.5 million members. On it, you can find virtually unlimited discussions concerning every topic related to the sector. You can seek advice on trading strategies, recommendations for trading platforms, help with parsing data, etc. For example, check out this thread about effective strategies to get started in algorithmic trading.
R/algorithmictrading is a much smaller community compared to r/algotrading, with just nearly 8,000 members. Like the other, participants can discuss topics related to quantitative trading and exchange solutions to their respective problems. One of the advantages of participating in a smaller subreddit is the low noise-to-signal ratio that makes it easy to filter out mundane information.
R/python is primarily a subreddit for the eponymous computer programming language. But you can find a lot of discussions about algorithmic trading because Python is the primary language used in the sector.
● MQL5.community
MQL5 is a dedicated online community for algorithmic traders worldwide and one of the most popular. This community offers a great utility to users, including financial data, ready-made AI trading algorithms, articles, technical indicators, an official forum, and live chat.
Many people are often discouraged by the thought of creating trading algorithms from scratch and implementing them through AI-based computer programs. If you’re in this camp, don’t be distressed. One of the best features of this community is that you can buy trading algorithms built by other professionals and implement them on the MetaTrader 5 platform with your capital.
Likewise, if you have the skills to build functional trading algorithms, you can earn money by selling them to other members of the community. This way, you can make money trading and also by offering your expertise to a vast user base.
Having the right market data is inseparable from being a successful algorithmic trader, and the MQL5 community helps you in this aspect. It offers quotes for global asset markets, including securities, commodities, and derivatives. This data helps you decide the right way to trade.
On this platform, you can also access a loaded library of articles about algorithmic trading. For example, see this article on how to design a trading system from scratch. These writeups by industry professionals represent a practical source of knowledge to help you become a better algorithmic trader.
The community’s official forum allows users to create discussion threads and exchange ideas that other people (including non-registered users) can read. For example, here are discussion threads on signal systems and how to evaluate market conditions. These threads, often involving traders from around the globe, are also great places to gain knowledge.
AI Has Helped Traders Leverage Automation Via Algorithmic Trading
Knowledge is power rings true in every sector. You’re likely to make costly mistakes if you don’t have a good comprehension of the complexities of algorithmic trading, which requires you to have a background in AI. An algorithmic trader mustn’t just learn but must continue to stay updated on developments in the rapidly-evolving industry and the new AI capabilities that they can take advantage of.
AI and algorithmic trading is pervasive in all global asset markets. For example, it makes up 92% of forex trading activities worldwide. Though a massive one, the industry is yet still growing, with many more developments to come propelled by the increasing availability of sophisticated computing resources. If you’re up to the task, board the ship and take advantage of the increasing opportunities at hand. You will discover the great potential of using AI for algorithmic trading.







{kind=link}
{kind=link}
{kind=link}