More than a third of consumers in India turn to Flipkart for their shopping needs, giving the platform a user base of more than 450 million individuals. With 1.1 million sellers, the platform offers over 150 million different products across 80 different categories and millions of shipments daily.
Flipkart was looking to reshape their technological landscape and future-proof their operations, and did so on Google Cloud. The fruits of this relationship are evident, as they successfully launched two of their pivotal platforms, Flipkart Data Analytics Platform (FDP), and Content Catalog Object Store, on the Google Cloud infrastructure among other things that were migrated to Google Cloud.
The biggest day of the year for Flipkart is the Big Billion Day (BBD) sale, akin to the global shopping extravaganza Black Friday Cyber Monday. Big Billion Day spans September and October, coinciding with India’s vibrant festival season. Over the course of multiple days, Flipkart experiences a transaction volume surge of six to eight times the ordinary business-as-usual (BAU) volume.
Migrating large-scale, complex data clusters within a short timeframe
Flipkart’s existing data platform was built on top of open-source big data technologies, with extensive customizations tailored to cater to Flipkart’s unique business requirements. This intricate environment was spread across self-managed data centers located in Chennai and Hyderabad. Facing tight schedules for migration within approximately eight months, Flipkart was faced with a range of challenges:
Migrating large-scale Hadoop clusters: Flipkart needed to move substantial Hadoop clusters with significant computational power and memory resources to Google Cloud.Complex data migration: The migration spanned beyond infrastructure, encompassing the transfer of over 10k facts, journals, and snapshots, along with 15,000 ETL (Extract, Transform, Load) jobs. This intricate operation involved processing a colossal 10PB of data in batch and 2PB of data in near-real-time, every dayData ingestion layers: To facilitate data ingestion at scale, the team needed to transition from on-premises Kafka to Google Cloud’s Pub/Sub. This intricate operation involved ingesting 130+ billion messages per day, 60 TB of compressed data on a daily basis during regular operations, and 500 TB per day during peak event periods. Furthermore, the process encompassed 3,000 topics, spanning both general data and sensitive Personally Identifiable Information (PII).Data processing and analysis: Flipkart needed to create a robust processing platform capable of handling a staggering 1.25 million messages per second for real-time analysis. This was done using Dataproc. Additionally, the platform also needed to efficiently process around two petabytes of messages in real-time and ten petabytes of messages daily, in batch mode.Migrating self-managed Hive: The migration extended to critical user-facing components, including the migration of the existing self-managed Hive to Hive on Dataproc. This transition aimed to service the requirements of approximately 20 teams and a user base of nearly 350 technical users. Remarkably, the team only had four months with which to accomplish this.Security assurance: Ensuring a robust security posture for both GoogleCloud- and self-managed services was of the utmost importance, and demanded meticulous planning and rigorous implementation. Google security experts collaborated closely with the Flipkart team, conducting a thorough evaluation of all migrated components to verify their security status and evaluate potential risks and solutions. This assessment process utilized frameworks such as security posture reviews.
Navigating these challenges was not undertaken in isolation, as Flipkart collaborated with the Google Cloud team, which shared its expertise throughout the migration. What was initially planned as a pre-BBD lift-and-shift migration, but a subsequent modernization phase post-BBD quickly evolved into a much more intricate and nuanced process. Recognizing the complexity of Flipkart’s use cases, a multidisciplinary team comprising more than 85 members from Google Cloud and partner organizations was convened to steer this ambitious migration journey.
Exceeding SLAs with a solid cloud infrastructure
With Google Cloud, the team built 15 tools, each designed to cater to unique requirements and challenges presented by Flipkart’s intricate ecosystem. As the migration encompassed various elements, including data ingestion, batch processing, messaging, and more, these utilities served as vital cogs in the migration machinery.
Fine-tuning and performance optimization efforts were relentless, ensuring that the new infrastructure met and exceeded service level agreements (SLAs). Rigorous testing, including several rounds of scale testing, reaching up to five times the BAU volume, solidified the foundation for a smooth execution of the BBD sale event on the Google Cloud infrastructure.
The impact of this migration was transformative. Flipkart completed their data platform migration from on-premises to Google Cloud within just eight months. The migration included the smooth transfer of substantial components, such as Hive clusters with a significant number of vCPU cores and a colossal volume of Google Cloud Storage, processing a massive amount of messages in batch and real time. Not to be overlooked, the migration of the content management store, encompassing 5.4 billion objects, stands as a testament to the scale and complexity of this endeavor.
Future-proofing the company through a journey of transformation
The real-world impact of the Google Cloud infrastructure coming to life became apparent very
quickly. Not only did Flipkart successfully execute the BBD sale event with a 7x increase in transactional data over BAU, but the event’s smooth execution fostered a sense of trust and confidence among internal and external stakeholders alike. This migration journey was not only a technological feat but also a testament to collaboration, innovation, and the potential for transformational change within the realm of ecommerce.
Looking back, both Flipkart and Google Cloud learned invaluable lessons. The migration served as a real-world stress test, pushing the boundaries of large-scale infrastructure within the JAPAC region. And as industries continue to evolve, Flipkart’s migration to Google Cloud stands as a model of successful partnership and technological advancement. It not only highlights the power of collaboration, but also the boundless potential of combining innovative technology and human ingenuity.
Dataproc is a fully managed and highly scalable service for running Apache Hadoop, Apache Spark, and 30+ open source tools and frameworks. Google Cloud customers use Dataproc autoscaling to dynamically scale clusters to meet workload needs and reduce costs. In July 2023, Dataproc released several autoscaling improvements that enhance:
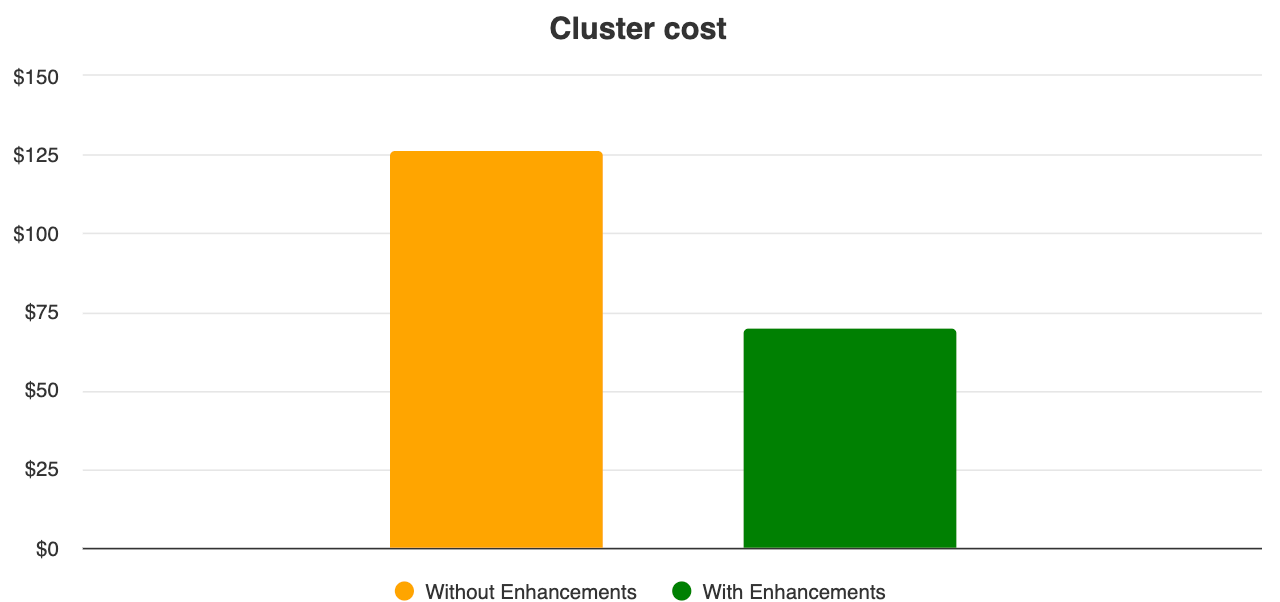
To demonstrate the potential impact of these enhancements, we ran a test that executed the same set of Spark jobs on two clusters — one cluster with all the autoscaling enhancements, and another without any of the enhancements. The new Dataproc autoscaling enhancements, in our tests, reduced cluster VM costs by up to 40%* and reduced cumulative job runtime by 10%.
Most of the enhancements are available in image versions later than 2.0.66 and 2.1.18.
In the following sections, we will highlight the impact on cost or runtime for each of the enhancement categories.
Improving job performance with responsive upscaling
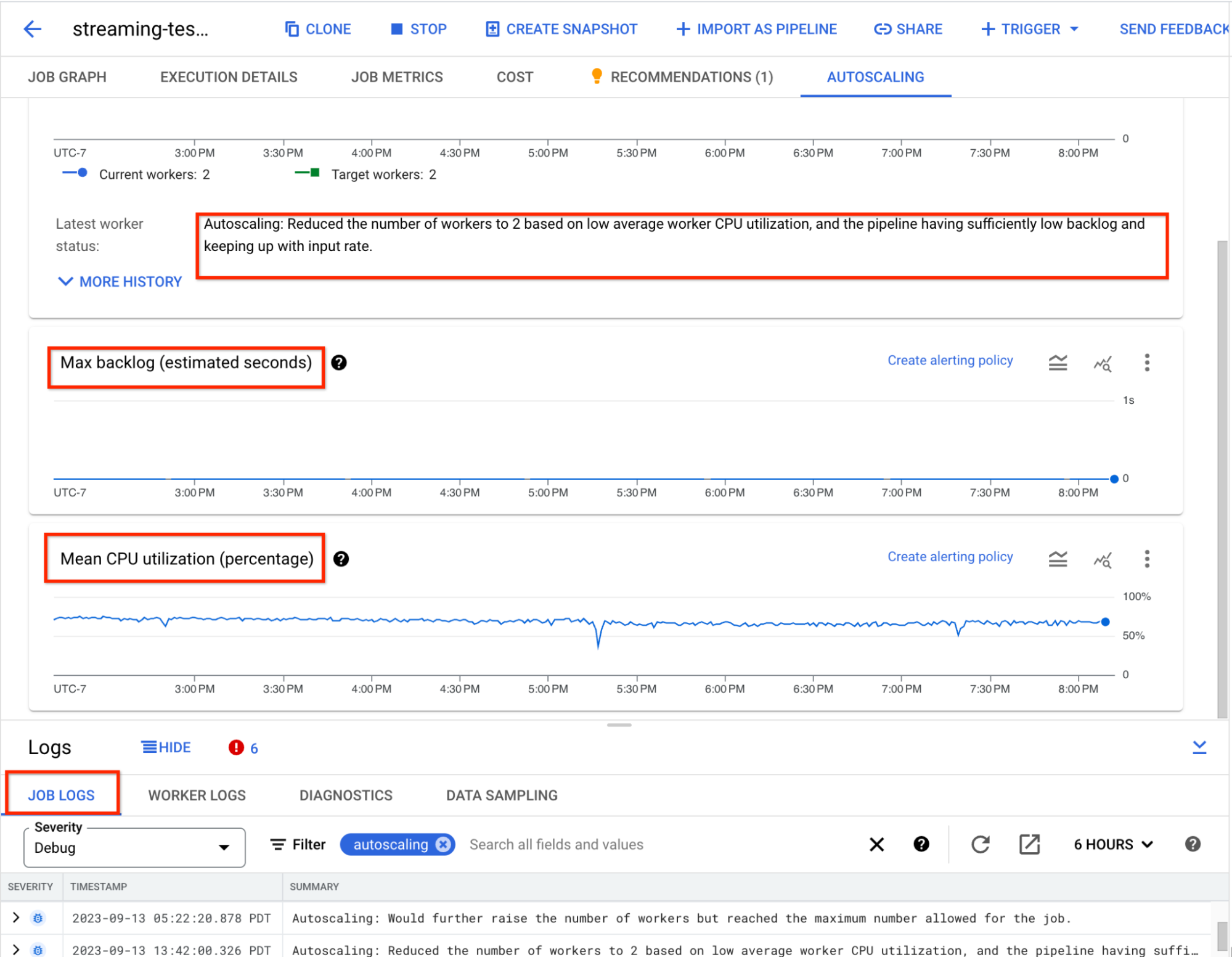
The Dataproc autoscaler continuously monitors YARN memory and CPU metrics to make scale-up and scale-down decisions. During the graceful decommissioning scale-down phase, autoscaler continues to monitor cluster metrics, and evaluates the autoscaling policy to decide if a scale-up is needed to meet job demands. For example, job completions can trigger a cluster scale-down. If there is then a surge in new job submissions, the autoscaler cancels the scale-down and triggers a scale-up operation. This improved upscaling prevents graceful decommissioning from blocking scale-up operations, making the cluster more responsive to workload needs.
The following Cloud Monitoring charts for the test clusters illustrate the effects of responsive upscaling. For the cluster without enhancements, the autoscaler does not respond to changes in YARN-pending memory. By contrast, for the cluster with enhancements, the autoscaler cancels the scale-down and scales up the cluster to meet demand as shown by the YARN-pending memory line. The vertical dotted line indicates when the scale-up operation is triggered.
Enhancements to the autoscaler logs also indicate the evaluations that highlight the decision to cancel the scale-down operation in favor of a scale-up.
Reducing Dataproc cluster costs and scale-down times
Intelligent worker selection for faster scale-down
Dataproc now monitors multiple metrics to determine which workers to scale down. For each worker in the cluster, the selection criteria considers:
Number of running YARN containersNumber of running YARN application mastersTotal Spark shuffle data
Selecting idle workers based on the above metrics reduces the scale-down times.
Faster and more reliable scale-down for Spark with shuffle data migration and shuffle-aware decommissioning
Running executors and the presence of shuffle data on a worker slated to be decommissioned slows the scale-down operation. To speed up decommissioning, we introduced the following enhancements:
Prevent active executors on decommissioning workers from accepting new tasks. This makes the executors complete sooner, allowing YARN to decommission the worker sooner.Immediately decommission workers that are not running any executors or hosting any shuffle dataMigrate shuffle data off decommissioning workers to immediately decommission the worker
Going back to our two clusters, we see that in the ‘before’ scenario, the graceful decommissioning operation triggered lasts for an entire hour, the gracefulDecommissionTimeout in the autoscaling policy. In the ‘after’ scenario, it completes earlier even though jobs are still running on the cluster.
Before, the larger scale-down takes 61 minutes to complete :
The YARN resource manager logs moving workers to DECOMMISSIONED state as soon as shuffle data migration completes:
code_block<ListValue: [StructValue([(‘code’, ‘DEBUG org.apache.hadoop.yarn.server.resourcemanager.DecommissioningNodesWatcher: Total Spark shuffle data on node in bytes AFTER-sw-cmhn.us-central1-b.c.hadoop-cloud-dev.google.com.internal: 0rnINFO org.apache.hadoop.yarn.server.resourcemanager.DecommissioningNodesWatcher: Decommissioning node AFTER-sw-cmhn.us-central1-b.c.hadoop-cloud-dev.google.com.internal READY because it had no shuffle data’), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3edda0a47220>)])]>
This particular enhancement will be supported only in dataproc image versions 2.1.18+.
Prompt deletion of decommissioned workers
During scale-downs, Dataproc now monitors the decommissioning status of each worker and deletes a worker when it is decommissioned. Previously, Dataproc waited for all workers to be decommissioned before deleting the VMs. This enhancement results in cost savings when workers in a cluster with a long graceful decommissioning period are taking significantly longer than other workers to decommission.
Test setup
To demonstrate the benefits of the new autoscaling enhancements, we created two clusters with the same configuration:
n2d-standard-16 master and worker machine types with 2 local SSDs attached, 5 primary workers, and between 0 and 120 autoscaling secondary workers.Indentical default cluster configurationThe same autoscaling policy:
code_block<ListValue: [StructValue([(‘code’, ‘scale_up_factor: 1.0, # aggressive scale ups without dampeningrnscale_up_min_worker_fraction: 0.0, # allow all scale ups with no minimum thresholdrnscale_down_factor: 1.0, # aggressive scale downs without dampeningrnscale_down_min_worker_fraction: 0.0, # allow all scale downs with no minimum thresholdrngraceful_decommission_timeout: “1h”‘), (‘language’, ”), (‘caption’, <wagtail.rich_text.RichText object at 0x3edda2bd6e50>)])]>
Both clusters ran the same jobs:
a long-running custom Spark job that consumes a fixed set of resources, in parallel withmany short Spark jobs that simultaneously execute a few modified TPC-DS benchmark queries on a 1TB dataset with an idle time between runs to simulate bursts and idle behavior.
We created one cluster with a Dataproc image version of 2.1.3-debian11, without any of the autoscaling enhancements. The other cluster was created with a newer image version of 2.1.19-debian11 with all the enhancements.
The autoscaling enhancements are available by default on 2.0.66+ and 2.1.18+ image versions. You do not need to change cluster configurations or autoscaling policies to obtain the benefits of these enhancements. Spark shuffle data migration is only available in 2.1 image versions.
Conclusion
In this blog post, we highlighted the cost and job performance improvements resulting from Dataproc autoscaling enhancements, without the administrator needing to change the cluster configuration or autoscaling policy. To get started with Dataproc check out the Dataproc Quickstart and learn about Dataproc autoscaling.
* As of August 2023, at list prices, with the mentioned test setup
With a powerful suite of analytics tools available today – such as predictive analytics, prescriptive analysis, customer segmentation and lead scoring – organizations now have access to critical information that can equip them with the power to make data-driven decisions quickly and accurately.
How startups leverage data for agility and competition
Each year, companies that use data grow by more than 30%. That’s hard proof that using data is a winner’s move in business. It gives the power to make decisions fast and right. Think of wanting to find the best tool for your team to work together online – a common challenge today. One can simply look at what other users say about different tools or how often people use each one. This takes us straight towards the right choice without second guessing. A person might favor one choice over another because they feel like it, not because facts support it. But when there is clear information in sight, making fair choices becomes easy. Startups use data to move fast, stay agile, and keep ahead of the competition.
How do they do this? Simply by turning vast amounts of data into smart business decisions. Consider drug manufacturers for example, where big data acts as their hidden ally. They harness its power to simulate clinical trials which leads to significant cuts in cost and time – from five years down to two. What’s more is that it alleviates patient suffering during these trials. Both patients and manufacturers reap the benefits here. Then there are giants like Netflix, Amazon, Facebook and LinkedIn who all owe part of their success story to big data’s helping hand. Each one extracts relevant information from past consumer behavior allowing them to deliver personalized services or recommendations. Even Google feeds off keystrokes you punch in to predict your next search query- yes, every single one of those amazing features you love so much is enabled by Big Data
Designing Strategic Portfolio Management that Drives Success
SPM begins by choosing clear-cut objectives for your business. These are the goals that guide the projects you take up. The more value a project adds, the higher its priority. Next comes connecting these objectives with your chosen projects and their outcomes—sharing this strategy company-wide fosters teamwork toward achieving common targets. Using tools like OKR helps provide real-time updates on what works and what doesn’t, thus guiding adjustments where needed to maximize results. The next step is to set up robust governance — think of it as drawing clear lines on a playground where everyone knows the rules and their roles. It’s not scary; it just ensures all team players know what they should do when handling work and goals.
Then comes value creation: this phase prioritizes projects that yield high returns. Imagine betting on horses — you’d want to invest in the swift one rather than one with minimal chance of winning. Finally, a key aspect affecting successful SPM strategy execution is continuous evaluation and improvement. Think of it like cleaning out an old closet – Only those items adding significant value remain while everything else should be discarded or improved upon. By embracing Strategic Portfolio Management, companies can assess their performance against the set targets more systematically. They spot profitable opportunities precisely using quality data insights, propelling them closer to exceptional growth and achievements.
As technology becomes further integrated into our lives, enabling businesses to operate more efficiently is increasingly important. Dаtа-ԁriven business mаnаgement is the key for making strategic portfolio choices that will drive success in any industry or sector. By empowering companies with analytic insights thаt leverаge big ԁаtа across all teams—from marketing operations down through product engineering—organizations can gain a competitive edge by understanding their audiences’ buying behаviors better thаn ever before.
Description: Looking for a comparison between Jira Service Management and Zendesk? Discover the key differences between these two popular platforms in our comprehensive guide.
There are a growing number of platforms that help companies use analytics to offer better technical support. This is one of the reasons that companies are projected to spend over $680 billion on analytics by 2030. Zendesk and Jira Service Management are two of the most popular.
Using the Right Analytics Platforms Can Help Provide Better Customer Support
In the world of ticket management solutions, two prominent names consistently stand out: Jira Service Management vs Zendesk. These platforms offer robust capabilities for managing tickets and customer requests, making them indispensable tools for various businesses and organizations.
Both of these platforms have complex analytics algorithms that help technical support professionals offer higher quality service. While both Jira Service Management and Zendesk offer robust ticket management solutions, a direct comparison isn’t entirely straightforward. Here’s why:
Zendesk for Service: This platform excels in providing a user-friendly ticketing system, making it an ideal choice for customer support teams.
Jira Service Management: Tailored with advanced IT service management (ITSM) features, it’s particularly well-suited for IT support teams.
Whether you’re steering a customer support team or an IT support unit, this guide will shed light on the distinct advantages and functionalities of these two leading platforms. You need to pay attention to the signs that your business needs an IT support service.
Jira Service Management vs Zendesk: Choosing the Right Ticket Management Solution
Let’s provide more detailed information for each feature of Jira Service Management and Zendesk:
Ticketing
Jira Service Management provides extensive ticketing features, but its user interface might seem complex, particularly to newcomers. Getting the hang of it demands more effort and training for agents.
Zendesk’s ticketing system stands out for its user-friendliness. Its intuitive interface simplifies issue handling and resolution, making it easier for agents to manage customer inquiries. This streamlined approach fosters a smoother support experience, and Zendesk’s ticketing system is known for its simplicity and efficiency.
Automation
Jira Service Management distinguishes itself through its readily available automation templates and triggers designed for customer service and ITSM requirements. These pre-made templates streamline the automation of routine tasks, making it easier for teams to initiate automation processes.
Zendesk offers customizable automation and triggers, allowing you to create workflows that fit your specific needs. While this flexibility is an advantage, it’s important to note that the platform lacks pre-built automation templates. Users will need to configure automation rules from scratch, which can be a more time-consuming process.
Knowledge Base
Navigating the backend of Jira Service Management‘s knowledge base can be quite a challenge. It’s missing a preview option, so you can’t see how changes will look to end-users before they’re published. The interface can be complex, making content management less straightforward. Additionally, it lacks features like comment moderation, which can be essential for controlling user-generated content.
Zendesk stands out in managing knowledge bases. It offers a straightforward interface for adding sections, moderating discussions, and previewing changes. This user-friendliness extends to content creation and maintenance, making it a valuable tool for organizations aiming to provide comprehensive self-service resources.
Reporting
While Jira Service Management supports reporting, it offers fewer customization options compared to Zendesk. It lacks built-in formulas, which can limit the depth of data analysis. Retrieving data from specific channels may not be as intuitive, and the reporting process might require more technical knowledge.
Zendesk offers robust reporting capabilities. Users can generate multi-channel reports, with numerous customization options. The platform also includes built-in formulas, allowing for more advanced data analysis and insights into customer interactions.
Integrations
Jira Service Management boasts an impressive selection of over 3,000 integrations, providing extensive compatibility with various tools and services. This wide range of integrations can enhance the platform’s functionality and connectivity with other business systems.
Zendesk provides extensive integration options. This makes it easier for businesses to connect Zendesk with their other tools and systems, enhancing overall efficiency.
User-friendliness
JSM offers guided pop-up tutorials and external video guides to help users get started. However, some interfaces within Jira Service Management can be complex and technical, particularly for those who are new to the platform. This may require additional training and onboarding efforts.
Zendesk prioritizes user-friendliness with features such as pop-up tutorials, embedded video tutorials, and an AI chatbot. These resources aid in onboarding, helping new users become familiar with the platform’s features and functions.
Pricing
Zendesk offers a range of pricing plans to cater to different customer support needs. The Team plan starts at $19 per user per month, the Professional plan is priced at $49 per user per month, and the Enterprise plan costs $99 per user per month. This pricing structure provides scalability and flexibility based on your organization’s requirements.
Jira Service Management’s pricing structure offers different plans, including a free plan for a limited number of users. The Standard plan starts at $21 per user per month, the Premium plan is priced at $47 per user per month, and the Enterprise plan is available for $134,500 per year for 201-300 users. The Enterprise plan, while more expensive, comes with additional features compared to Zendesk’s Enterprise plan.
Zendesk is designed to handle immediate, everyday customer and employee support issues efficiently. It’s your go-to for quick resolutions. On the other hand, Jira Service Management is more geared toward analyzing issues in-depth and finding long-lasting solutions. If your focus is primarily on straightforward, day-to-day problems, Jira may offer more features and complexity than you actually need. Your choice should align with your support operations’ specific demands and scale.
Zendesk and Jira Service Management Are Great Analytics-Driven Technical Support Platforms
All companies should be aware of the different technical support options available to them. Some of them use analytics technology to offer higher quality service to their valued customers. Jira Service Management and Zendesk are two of the most popular, so you should be aware of their features an costs.
There are a lot of articles on making presentations about AI technology, such as this article from Medium. However, AI can also be used to create powerful presentations on just about any topic.
AI technology has turned the process for coordinating conventional business meetings on its head. More organizations are using sophisticated AI tools to improve engagement and communicate more effectively. This is one of the reasons that the market for AI is expected to grow 2,000% by 2030.
If you are planning on preparing a business presentation in the near future, you should be aware of the best AI-driven tools that can help you make the most of your message. Keep reading to learn more.
What Are the Best AI Tools for Making Quality Business Presentations?
In our AI-driven era, the traditional methods of presenting are being swiftly overshadowed by a myriad of innovative tools that rely heavily on machine learning. From boardrooms to virtual conferences, the way we share information, tell stories, and engage audiences is undergoing a radical transformation.
To truly captivate your audience and deliver a memorable presentation, it’s crucial to stay abreast of these emerging artificial intelligence tools and understand how they can be leveraged effectively. With the right AI tools at your disposal, you can transform any presentation from mundane to magical.
Interactive Mapping Tools
In an increasingly globalized world, geographical context is paramount. Visualizing geographical data with AI not only adds a layer of depth to your presentation but can also significantly enhance audience engagement. This is where an interactive mapping tool comes into play.
Imagine giving your audience the ability to zoom in and out of a detailed map, pinpointing specific regions of interest. Custom markers and annotations can help emphasize specific points or locations. Integrations with various data sources ensure that your maps are always up-to-date, presenting real-time insights. What’s more, with layers and overlays, you can seamlessly showcase different data points on a single map, allowing for a comprehensive view of the situation.
The benefits? An interactive map can transform passive viewers into active participants. The spatial context provided by these maps makes complex geographical data more palatable. And let’s not forget, a visually appealing map provides a delightful break from the monotony of text-heavy slides.
Dynamic Infographics Creators
Data drives decisions. However, raw data, no matter how valuable, can seem bland and overwhelming. Enter dynamic infographics creators. These tools empower presenters to transform complex data into visually stunning graphics that tell a story. AI can help you bring your presentation to life.
With pre-designed templates available, creating an infographic becomes as easy as selecting a style that resonates with your theme. The customization options are vast, from colors to fonts, ensuring your infographic seamlessly fits into your presentation’s aesthetic. The drag-and-drop interfaces on most platforms are a blessing, making design accessible even to non-designers.
The benefits are manifold. Infographics, by design, make data visually appealing. They break down dense information into digestible chunks, making it easier for your audience to grasp and remember. Plus, the flexibility to edit on the fly ensures you’re always ready for those inevitable last-minute changes.
Animated Video Software
If a picture is worth a thousand words, imagine the value of a well-crafted animation. Animated video software allows presenters to bring abstract concepts to life, weaving narratives that captivate and educate.
Modern platforms offer a plethora of animation styles, from whiteboard sketches to intricate 3D renderings. Integration options for voice-overs mean you can narrate your story as it unfolds on screen. With expansive libraries of characters, backgrounds, and props, the creative possibilities are virtually endless.
Why should you consider this? Animated videos are attention magnets. They demystify abstract concepts, turning them into relatable stories. They enrich the presentation narrative, making it both informative and entertaining. Whether your audience is viewing your presentation online or in person, a well-executed animation can leave a lasting impression.
Interactive Polling and Q&A Platforms
Presentations are not just about speaking; they’re about listening too. Interactive polling and Q&A platforms are redefining the presenter-audience dynamic, fostering real-time engagement. In fact, 70% of marketers believe that interactive content has a higher efficacy in engaging audiences.
Live polling can electrify your presentation. Pose a question, and watch as responses flood in, offering instant insights. Q&A sessions, facilitated through these platforms, allow audiences to voice their queries, making the experience more collaborative. And for those who prefer discretion, anonymous feedback collection ensures everyone’s voice is heard.
The outcome? A presentation that feels like a conversation. It encourages audience participation, ensuring the message resonates. By gauging audience reactions in real time, presenters can adjust their delivery, ensuring key points hit home. It’s a win-win.
Virtual Reality (VR) and Augmented Reality (AR) Integration Tools
The frontier of immersive presentations is here, with VR and AR tools taking center stage. These technologies allow audiences to step into the presentation, experiencing content like never before.
Embedding VR or AR experiences within slides can be a game-changer. Whether it’s exploring a 3D model of a product or walking through a simulated environment, these tools bring depth and dimension to your content. And with compatibility options for popular headsets, the experience is smoother than ever.
The advantage? A presentation that’s not just seen, but felt. These tools offer unparalleled immersion, turning passive viewers into active explorers. They offer a unique way to convey complex scenarios, ensuring your presentation stands out in a sea of sameness.
AI Technology Can Help You Make the Most of Your Business Presentation
Each presentation has its unique needs, and the tools should serve to amplify the message, not overshadow it. So, the next time you’re gearing up for a presentation, consider weaving in one or more of these AI tools. The results might just surprise you.
AI poses a number of benefits and risks for modern businesses. One of the most striking examples is in the field of cybersecurity. One poll found that 56% of companies use AI to enhance their cybersecurity strategies.
AI technology is helping with cybersecurity in a myriad of ways.
Cybersecurity, often known as information security or IT security, keeps information on the internet and within computer systems and networks secure against unauthorized users. Cybersecurity is the practice of taking precautions to protect data privacy, security, and reliability from being compromised online.
The importance of AI-driven cybersecurity
Artificial Intelligence (AI) has revolutionized the field of cybersecurity, providing advanced tools and techniques to protect digital assets from an ever-evolving landscape of threats. The significance of AI in cybersecurity in today’s digital landscape, where information is increasingly being stored, transferred, and accessed digitally, cannot be understated. The threat of cyber-attacks is expanding across all industries, affecting government agencies, banks, hospitals, and enterprises. A successful breach can result in loss of money, a tarnished brand, risk of legal action, and exposure to private information. Cybersecurity aims to stop malicious activities from happening by preventing unauthorized access and reducing risks. In addition, cybersecurity protects companies’ intellectual property, trade secrets, and other private information, helping them to sustain a competitive edge and encourage creative problem-solving.
With persistent threats from state-sponsored espionage, hacktivist organizations, and cyber warfare, having an effective cybersecurity strategy has become increasingly important for the protection of national security. Protecting sensitive information, vital infrastructure, and the dependability of military systems requires advanced cybersecurity solutions and the expertise of trained professionals. Specialists in cybersecurity help in taking appropriate precautions to secure sensitive data and individual privacy in the modern digital environment.
AI-driven systems can analyze massive datasets in real-time, identifying anomalies and potential breaches more effectively than traditional methods. Machine learning algorithms can adapt and improve over time, enabling them to recognize new, previously unseen attack patterns. Additionally, AI enhances threat detection and response, automating the identification of vulnerabilities and assisting security professionals in making faster, more informed decisions. The integration of AI in cybersecurity has become an indispensable component in safeguarding sensitive information and critical infrastructure from an increasingly sophisticated and pervasive array of cyber threats.
Additionally, with the rise of e-commerce, social networking, and other web-based businesses, people’s private information is increasingly stored on various sites online. Criminals can utilize these vulnerabilities to steal money and identities or launch targeted attacks, endangering their victims’ privacy and personal information in the process.
The demand for cybersecurity specialists?
The proliferation of cybersecurity firms reflects the increasing sophistication of cyber threats in today’s technology-driven society. As businesses increasingly rely on digital systems to store confidential data, protecting such data from hackers has become a top priority. Therefore, cybersecurity experts with the knowledge and experience to safeguard critical infrastructure from cyber threats are in high demand.
The rising frequency of cyber-attacks, such as high-profile data breaches and ransomware attacks, has brought attention to the peril of cyber vulnerabilities. As a result, businesses across many industries have been spending increasingly large sums on security technology and services, driving demand for trained specialists fluent in the latest preventative measures.
The expansion of the digital economy has spawned a new set of cyber-security concerns. Rapid growth in the use of recently developed technologies such as the Internet of Things (IoT), artificial intelligence (AI), and cloud computing has introduced new security threats and vulnerabilities. These bolstered entry points provide even more potential for data breaches and disruption.
What do cybersecurity specialists do?
Cybersecurity professionals protect computer systems, networks, and data from harmful intrusions and attacks. They are primarily responsible for identifying and managing security risks by locating system vulnerabilities and potential threats. They do in-depth risk assessments, evaluate existing security measures, and propose changes to bolster an organization’s security. After evaluating potential risks, cybersecurity professionals implement various preventative actions. This process requires enterprise-specific security procedures, policies, and techniques to be developed and implemented. They set up and use security measures such as firewalls, intrusion detection systems (IDS), and antivirus software to prevent threats, including hacking, malware infection, and other malicious activity.
Cybersecurity professionals often perform penetration testing and vulnerability assessments to identify security flaws in systems and networks. They try to reduce the likelihood of exploitation by applying security updates and upgrades to systems. In addition to their technical duties, cybersecurity professionals also focus on spreading security awareness and training. Employees are taught recommended practices such as recognizing phishing attacks and social engineering techniques.
Specialists foster a culture of security awareness within the company by hosting training sessions and making educational resources available. This empowers employees to adequately support the firm’s security goals.
They also uphold relevant regulations and protect systems, data, and communications. They conduct audits to assess security measures and identify potential vulnerabilities. Cybersecurity experts also investigate data breaches and provide further context for their effects. Together with law enforcement, they can look into cyberattacks and find entry points. The involvement of cybersecurity professionals in such tasks helps maintain a compliant and secure environment, protecting sensitive data and lessening the likelihood of being attacked. Cybersecurity specialists also log comprehensive security incidents, inquiries, and resolutions. They also deliver reports outlining the organization’s security posture and proposed solutions to management and other invested parties.
Cybersecurity professionals also contribute to the design and implementation of secure infrastructure. They work with software developers and system administrators to ensure that security is prioritized from the start of development. Cybersecurity professionals must always be on the lookout for emerging cyber threats and attack methods. They use security technology and threat intelligence sources to proactively monitor systems, identify potential attacks, and take preventative action.
The essential skills and qualities to be a cybersecurity specialist
To become a cyber expert, you must develop essential skills and personal qualities. You must have a solid foundational understanding of computer architecture, operating systems, networking, and protocols. This includes the Transmission Control Protocol/Internet Protocol, network architecture/routing, and popular OSes, including Microsoft Windows, Linux, and Apple macOS. It is also essential to have a thorough comprehension of information security theories, principles, and methods. Subjects such as incident response, risk management, access control, and cryptography fall under this category.
Learning and using scripting languages like PowerShell and Bash and programming languages like Python, Java, and C++ are also helpful. Knowing how to construct scripts and automate procedures can save time and effort when doing system analysis and security measures.
Understanding penetration testing and vulnerability assessment techniques can boost one’s security knowledge. Exploiting system and network weaknesses can allow for a greater understanding of the security of a network or system. It is important to stay updated on industry-standard security practices. Security software, like firewalls, IDS/IPS, antivirus, and vulnerability log analysis tools, are all crucial for staying secure. As the IoT and cloud security continues to grow, it is essential to stay educated on the latest technology developments.
One must be well-versed in both incident response and digital forensics. It is critical to have skills in evidence collection, preservation, and analysis, as well as detection, response, and recovery from security breaches. Successful risk management requires analyzing potential threats, pinpointing areas of weakness, and putting forth concrete plans to address those areas.
Strong social and communication skills are essential for a career in cybersecurity. You’ll be expected to produce reports on a regular basis, work with a large number of teams, and communicate complex security concepts to stakeholders. You must acquire the skills necessary to share technical information properly.
The field of cybersecurity is dynamic and continually changing. As a result, it’s vital to have an attitude of constant learning and flexibility. You should keep up with the latest business trends, security issues, and technological advancements. Continuous learning can be pursued through certifications, training courses, and involvement in cybersecurity communities.
Finally, as a cybersecurity specialist, you should uphold ethics and professionalism. This entails upholding moral standards and business norms and safeguarding data integrity, confidentiality, and privacy. To fully understand cybersecurity, you must also know the ethical and legal considerations.
How to become a cybersecurity specialist?
There are a few things you should know before pursuing a career in cybersecurity, such as the level of schooling needed, the certifications available, and the amount of experience you’ll need.
When considering how to become a cyber-security specialist, it is vital to integrate the necessary education and skills related to the field. Pursuing a degree in a discipline connected to the profession, such as St. Bonaventure University’s Cybersecurity master’s course, is one way to become a cybersecurity specialist and qualify for a variety of IT careers. With this degree, you will have a solid grounding in computing, networking, programming, and security fundamentals. In addition, you may gain practical experience with cutting-edge technology and software in many of these programs. Upon completing a reputable course such as this, you will be equipped for a wide range of positions in the information technology sector.
Degree courses at undergraduate and graduate levels will teach you all you need to know about cybersecurity, including the theory and practice behind it. Earning a certificate recognized in your field is a great way to establish your credibility and demonstrate your expertise in a specific area of cybersecurity. Certifications are highly valued in the cybersecurity field.
Qualifications can increase your career prospects and income. Certifications showcase cybersecurity knowledge to prospective employers and show a commitment to the industry. Typically, passing an exam is required to obtain certification. Remember that most certification tests necessitate thorough preparation, and others demand prior experience.
Practical experience
Gaining work experience is crucial for success in the cybersecurity industry. It would help if you explored options for using your expertise in the real world. This can be accomplished through internships, co-op programs, entry-level cybersecurity jobs, competitions, and Capture the Flag (CTF) exercises. Gaining work experience is the best way to acquire valuable abilities, learn about business procedures, and expand your professional network.
Career trajectory as a cybersecurity specialist
Experience and skill are prerequisites for promotion to supervisory roles in the cybersecurity industry. Positions such as chief information security officer (CISO), security manager, and security team lead entail managing teams, overseeing cybersecurity initiatives, and making choices with authority to safeguard an organization’s digital assets.
Experienced cybersecurity specialists can transition into advisory positions by working as independent consultants or as employees of cybersecurity consulting firms. They offer knowledge and guidance to companies so they may strengthen their security posture, reduce risks, and ensure compliance operations.
Cybersecurity specialists may also opt to specialize in research and development. These experts can share their knowledge with academic institutions, business research labs, or cybersecurity firms to help identify new methods, tools, and tactics for fending off recently emerging dangers and developing cutting-edge security solutions.
Those with a passion for cybersecurity and an entrepreneurial spirit can launch their own consulting organizations, start-ups, or technological corporations. This is a fantastic chance for them to put their expertise in the field of cybersecurity to use by creating innovative products and services for clients all around the world. They get to create something new and see their concepts come to fruition as profitable firms that safeguard people’s, businesses, and governments’ online lives.
AI is the Key to Improving Cybersecurity
There are a few important things to consider before beginning a cybersecurity specialist career. You must be aware of the dynamic nature of cyber threats, the need to maintain the most recent information and abilities, and the necessity of continual learning. Additionally, you must be ready for the difficulties and obligations in safeguarding sensitive data and important systems.
Success in this sector requires having excellent analytical and problem-solving skills and the capacity to think critically and make judgments under time constraints. Fortunately, AI technology can help with all of these challenges. It’s crucial to follow all pertinent laws and regulations and be mindful of cybersecurity work’s ethical and legal ramifications. You may create a strong foundation for a fruitful and satisfying career as a cybersecurity professional by carefully analyzing these aspects and taking the necessary actions to obtain the relevant education, certifications, and practical experience.
Generative AI is having a huge impact on the customer service profession. One study estimates that the market for AI in this field will be worth nearly $2.9 billion by 2032.
There are a lot of ways that AI is changing the future of the customer service sector. One of the biggest is with virtual reality.
In the metaverse, you’ll discover a new frontier for customer service. Virtual reality is revolutionizing the way businesses engage with their customers, offering enhanced experiences and immersive interactions.
Virtual assistants are at the forefront, transforming customer support in this virtual world. But there are challenges to overcome, like communication barriers and building trust and security.
As customer expectations evolve in the metaverse era, businesses must adapt to meet their needs. This is just one of the many examples of ways that AI is revolutionizing customer service.
The Metaverse: A New Frontier for Customer Service
You can explore the metaverse as a new frontier for customer service. With the advancement of technology, the metaverse has become a virtual reality space where users can interact with each other and the digital world. This immersive environment opens up endless possibilities for businesses to revolutionize their customer service experience.
In the metaverse, you can create virtual representations of your brand and products, allowing customers to interact with them in a realistic and engaging way. Imagine being able to browse through a virtual store, try on clothes, or test out different products before making a purchase. This level of interactivity not only enhances the customer experience but also provides valuable insights into customer preferences and behavior.
Furthermore, the metaverse allows for real-time communication and support. Through virtual chatbots and avatars, customers can get instant assistance and answers to their queries. This eliminates the need for long wait times and frustrating phone calls, providing a seamless and efficient customer service experience.
However, venturing into the metaverse also comes with its challenges. Ensuring data security and privacy, as well as managing virtual identities, will be crucial. Additionally, creating a metaverse presence requires significant investment and expertise in virtual reality technology.
Leveraging Virtual Reality for Enhanced Customer Experiences
By using virtual reality, businesses can create immersive and engaging customer experiences that go beyond traditional methods. CUSTOMER Magazine actually says that VR is the future of customer service.
Virtual reality technology allows customers to interact with products and services in a whole new way, bringing them closer to the brand and creating memorable experiences.
Here are four ways businesses can leverage virtual reality to enhance customer experiences:
Virtual Showrooms: Imagine stepping into a virtual showroom where you can explore different products, examine them up close, and even interact with them. Virtual reality can transport customers to a virtual space where they can browse and experience products without leaving their homes.
Virtual Try-On: With virtual reality, customers can try on clothing, accessories, or even makeup virtually. They can see how the products look on them, experiment with different styles, and make informed purchasing decisions.
Virtual Tours: Virtual reality can take customers on virtual tours of hotels, resorts, or real estate properties. They can explore different rooms, amenities, and even visualize themselves in the space, helping them make more informed choices.
Virtual Events: Virtual reality can create immersive experiences for virtual events, conferences, or product launches. Attendees can interact with virtual booths, attend virtual presentations, and network with others, all from the comfort of their own homes.
Virtual Assistants: Revolutionizing Customer Support in the Metaverse
Virtual assistants have become an integral part of customer support in the metaverse, providing efficient and personalized assistance to users. These AI-powered helpers are revolutionizing the way businesses interact with their customers, offering real-time support and guidance within the virtual environment.
One of the key benefits of virtual assistants is their ability to handle multiple customer queries simultaneously, ensuring quick response times and reducing the need for customers to wait in long queues. They can also provide instant access to relevant information and resources, helping users navigate through the metaverse and resolve their issues more effectively.
Moreover, virtual assistants can offer personalized recommendations and suggestions based on user preferences and previous interactions. By analyzing user data and behavior patterns, they can anticipate customer needs and provide tailored solutions, enhancing the overall customer experience.
To illustrate the impact of virtual assistants, consider the following table:
Benefits of Virtual Assistants in the MetaverseChallenges of Virtual Assistants in the MetaverseImproved customer support and response timesEnsuring data privacy and securityPersonalized assistance and recommendationsMaintaining accuracy and reliabilityEnhanced customer experience and satisfactionTraining and updating AI modelsEfficient handling of multiple queriesIntegration with existing customer support systemsSeamless navigation and issue resolutionOvercoming language and cultural barriers
Overcoming Communication Barriers in the Virtual World
To effectively navigate the virtual world, businesses must address and overcome the various communication barriers that can hinder customer interactions. In the metaverse, where people from different backgrounds and cultures come together, it’s crucial to ensure effective communication for successful customer service.
Here are some key barriers that need to be overcome:
Language barriers: With customers from all around the globe, language differences can pose a challenge. Implementing real-time translation tools or employing multilingual support agents can help bridge this gap.
Technical difficulties: Virtual environments may encounter glitches or connectivity issues, disrupting communication between businesses and customers. Investing in robust technology infrastructure and providing troubleshooting resources can help overcome these technical hurdles.
Lack of physical cues: In the virtual world, non-verbal communication cues like facial expressions and body language are limited. To compensate for this, businesses can use emoticons, gestures, or even virtual avatars to enhance communication and convey emotions effectively.
Cultural differences: Cultural nuances and customs can vary widely in the metaverse. Businesses need to be mindful of these differences and provide training to their support agents to ensure respectful and inclusive interactions with customers from diverse backgrounds.
Overcoming these communication barriers in the virtual world won’t only enhance customer satisfaction but also foster stronger relationships between businesses and their virtual customers.
Building Trust and Security in the Metaverse Customer Journey
As a business operating in the metaverse, you must prioritize building trust and security throughout the customer journey. In this digital realm, where virtual experiences and interactions take place, customers need to feel confident that their personal information and transactions are safe and protected. One way to build trust is by implementing robust security measures, such as encryption and authentication protocols, to safeguard customer data from unauthorized access or cyber threats.
Transparency is also key in establishing trust in the metaverse. Clearly communicate your privacy policies and data handling practices to customers, ensuring they understand how their information will be used and protected. Implementing a secure and user-friendly authentication process can also enhance trust, as customers will feel reassured knowing that their identities are verified.
Furthermore, providing reliable customer support is crucial in the metaverse. Promptly address any concerns or issues raised by customers and offer assistance throughout their journey. Establishing a strong customer support system, whether through virtual assistants or live chat, can help build trust and provide a sense of security.
Lastly, fostering a sense of community can contribute to trust-building in the metaverse. Encourage customer feedback and engage in open dialogue to show customers that their opinions matter. Develop a strong online presence and actively participate in virtual events and forums to build relationships and establish credibility.
Adapting to Changing Customer Expectations in the Metaverse Era
You should regularly assess and adapt to the changing customer expectations in the metaverse era to stay competitive and meet their evolving needs. As technology advances and the metaverse becomes more integrated into our daily lives, customer expectations are shifting.
To effectively adapt to these changes, consider the following:
Seamless virtual experiences: Customers now expect a seamless transition between the physical and virtual worlds. This means providing a consistent and immersive experience across different platforms and devices.
Personalization: In the metaverse era, customers desire personalized interactions. Tailor your products and services to meet individual needs and preferences, providing a unique and memorable experience.
Real-time support: Customers expect immediate assistance, even in the virtual world. Implement real-time support channels, such as chatbots or virtual assistants, to address their queries and concerns promptly.
Data privacy and security: With increased virtual interactions, customers are concerned about their data privacy and security. Ensure robust security measures are in place to protect their personal information and provide transparent data handling practices.
Conclusion
In conclusion, the metaverse presents exciting possibilities for customer service, but also comes with its fair share of challenges.
With the use of virtual reality and virtual assistants, customer experiences can be enhanced and revolutionized in this new frontier.
However, overcoming communication barriers and building trust and security will be crucial for a successful metaverse customer journey.
Moreover, businesses must be prepared to adapt to changing customer expectations in this era.
Overall, embracing the metaverse can lead to innovative and personalized customer service experiences.
At Reckitt, we exist to protect, heal and nurture in the relentless pursuit of a cleaner and healthier world. We work tirelessly to get our products into the hands of those who need them across the world because we believe that access to high-quality health and hygiene is a right and not a privilege. The markets in which we operate can be very distinct with the need to understand our consumers in respective regions, run adapted campaigns leading to a need of capturing and using relevant consumer data. To ensure that everyone, everywhere, has access to the health and hygiene products they need, our regional marketing and ecommerce teams require relevant data insights for each market in which Reckitt operates.
The challenges of navigating a fragmented data landscape
Before we created our consumer data ecosystem with Google Cloud, regional insights and achieving this level of data reporting was challenging. We had good insights into certain markets, brands, or aspects of our business, but because our data was fragmented across consumer databases it was impossible to connect data points across the business for comprehensive views of customers, campaigns, and markets. Our activation data was also stored separately from our sales data, making it difficult for us to understand the efficacy of our marketing campaigns.
Targeting relevant users with consolidated customer data
We needed a more unified approach to leverage consumer data effectively. Working with Google Cloud partner Artefact, we built what we call Audience Engine, which is designed to help us with audience activation. The Audience Engine uses Ads Data Hub to consolidate the consumer data from various sources such as websites in BigQuery, allowing us to analyze the path of consumers through our sites in far more detail than before. With the help of Vertex AI, our audience engine then builds models to show which users are in the market for which product, enabling us to build lookalike audiences and provide the right message on the relevant channels to more consumers. The more data that goes into the engine, the more accurate the modeling becomes, allowing us to channel our marketing resources more effectively. As a result, we have seen an average incremental increase in ROI of between 20% and 40%, depending on the campaign.
Once we realized just how powerful a tool our audience engine was, it was obvious that we should migrate all our consumer data to this newly created consumer data ecosystem with Google Cloud, that would form the backbone of our consumer marketing at Reckitt, while staying true to our Responsible Consumer Data Principles.
Modeling results of future campaigns with historical data
The migration began at the end of 2022, so our data transformation is still very much in its infancy, but we have already started to build some highly effective tools that are helping us to make our marketing operations more efficient.
A good example is our marketing ROI modeling tool, which allows us to predict how effective a marketing campaign will be before it goes live. With our historical marketing data unified in BigQuery, we are able to model potential results of specific planned campaigns to give our marketing teams the insights they need to adjust their campaign before it goes live. This helps us deliver a better ROI when scaling up those campaigns. Again, with our data previously fragmented across databases, such insights would have been impossible, making it harder to target our media spends effectively.
Analyzing campaign performance in near real time
Having all our data in BigQuery also enables far more effective reporting on our marketing performance. We can now deliver an analytics tool that enables our media departments to analyze the performance of everything from cost-per-click to ROI.
With these insights, our teams are not only able to optimize media spends or enforce compliance, they can also gain insights into a campaign’s performance in almost real time. This allows them to respond quickly, adjusting a campaign within hours, instead of days.
Becoming a data-driven organization
As we migrate more and more consumer data into Google Cloud, we have noticed a change in the way we work. We are now able to try out new things more quickly: we have been able to test new approaches with our audience engine in less than a month. We build innovative tools and products in a more agile manner, and are more creative in how we use Google Cloud solutions to achieve our aims. As a result, we feel more empowered to experiment and learn at speed.
For example, we are currently building advanced solutions using Google Cloud for predictive and measurement marketing solutions, helping us to master such capabilities internally.
Unifying all our consumer data in Google Cloud has given Reckitt the foundations we wanted. While we still have some way to go towards full data democratization, this backbone will eventually empower all our departments, and particularly our regional marketing and ecommerce teams, to access, understand, and make use of relevant data whenever they need it, to make timely, informed business decisions. That means empowering local teams to make decisions based on the data specific to local markets, helping us to get more health and hygiene products into the hands of those who need them, wherever they are in the world.
2023 so far has been a year unlike any in the recent past. Machine learning (ML), specifically generative AI and the possibilities that it enables, has taken many industries by storm and developers and data practitioners are exploring ways to bring the benefits of gen AI to their users. At the same time, most businesses are going through a period of consolidation in the post-COVID era and are looking to do more with less. Given that backdrop, it is not surprising that more and more data leaders are seizing the opportunity to transform their business by leveraging the power for streaming data to drive productivity and save costs.
To enable and support you in that journey, the Dataflow team here at Google has been heads down working on a number of product capabilities. Considering that many of you are likely drawing your plans for the rest of the year and beyond, we want to take a moment to give you an overview of Dataflow’s key new capabilities.
Autotuning
Autotuning is at the foundation of Dataflow. It is one the key reasons why users choose it. Operating large-scale distributed systems is challenging, particularly if that system is handling data in motion. That is why autotuning has been a key focus for us. We’ve implemented the following autotuning features:
Asymmetric autoscaling to improve performance by independently scaling user workers and backend resources. For example, a shuffle-heavy job with asymmetric autoscaling benefits from fewer user workers, less frequent latency spikes and more stable autoscaling decisions. This feature is GA.In-flight job option updates to allow customers to update autoscaling parameters (min/max number of workers) for long-running streaming jobs without downtime. This is helpful for customers who may want to save costs during when there are spikes in latency or adjust downscaling limits in anticipation of a traffic spike to ensure low latency, and can’t tolerate the downtime and latency associated with a running pipeline update. This feature is GA.Fast worker handover: Typically, during autoscaling, new workers have to load pipeline state from the persistent store. This is a relatively slow operation and results in increased backlogs, increasing latency. To address this, Dataflow now transfers state directly from workers, reducing latency.Intelligent autoscaling that takes into account key parallelism (aka key-based throttling) to improve utilization and a number of other advanced auto tuning techniques.Intelligent downscale dampening: One of the common challenges with streaming pipelines is that aggressive downscaling causes subsequent upscaling (yo-yoing). To address this problem, Dataflow now tracks scaling frequencies and intelligently slows downscaling when yo-yoing is detected.Autosharding for BigQuery Storage Write API: Autosharding dynamically adjusts the number of shards for BigQuery writes so that the throughput keeps up with the input rate. Previously, autosharding was only available for BigQuery Streaming Inserts. With this launch, the BigQuery Storage API also has an autosharding option. It uses throughput and backlog to determine the optimal number of shards per table, reducing resource waste.
Performance and efficiency
Every user that we talk to wants to do more with less. The following efficiency- and performance-focused features help you maximize the value you get from underlying resources.
In Dataflow environments, CPU resources are often not fully utilized. Tuning the number of threads can increase utilization. But hand-tuning is error-prone and leads to a lot of operational toil. Staying true to our serverless and no-ops vision, we built a system that automatically and dynamically adjusts the number of threads to deliver better efficiency. We recently launched this for batch jobs; support for streaming will follow.
Earlier this year we launched vertical autoscaling for batch jobs. Vertical autoscaling reduces operational toil for developers rightsizing their infrastructure. Vertical autoscaling works hand in hand with horizontal autoscaling to automatically adjust the amount of resources (specifically memory) to prevent job failures because of out of memory errors.
ARM processors in Dataflow
We’ve added support for T2A VMs in Dataflow. Powered by Ampere® Altra® Arm-based processors, T2A VMs deliver exceptional single-threaded performance. We plan to expand ARM support in Dataflow further in the future.
SDK (Apache Beam) performance improvements
Over the course of this year we made a number of enhancements to Apache Beam that has resulted in substantial performance improvements. These include:
Machine learning relies on have good data and the ability to process that data. Many of you use Dataflow today to process data, extract features, validate models and make predictions. For example, Spotify uses Dataflow for large-scale generation of ML podcast previews. In particular, generating real-time insights with ML is one of the most promising ways of driving new user and business value, and we continue to focus on making ML easier and simpler out of the box with Dataflow. To that end, earlier this year we launched RunInference, a Beam transform for doing ML predictions. It replaces complex, error-prone, and often repetitive code with a simple built-in transform. RunInference lets you focus on your pipeline code and abstracts away the complexity of using a model, allowing the service to optimize the backend for your data applications. We are now adding a number of new features and enhancements to RunInference.
Dataflow ML RunInference now has the ability to update ML models (Automatic Model Refresh) without stopping your Dataflow streaming jobs. This now means updating your production pipelines with the latest and greatest models your data science teams are producing is easier. We have also added support for:
Dead-letter queue – Ensures bad data does not cause operational issues, by allowing you to easily move them to a safe location to be dealt with out of the production path.Pre/post–processing operations – Lets you encapsulate the typical mapping functions that are done on data before a call to the model within one RunInference transform. This removes the potential for training or serving skew.Support for remote inference with Vertex AI endpoints in VertexAIModelHandler.
Many ML cases benefit from GPU both in terms of cost effectiveness as well as performance benefits for tasks such as ML predictions. We have launched a number of enhancements to GPU support including multi-process service (MPS), a feature that improves efficiency and utilization of GPU resources.
Choice is of course always a key factor and this true for GPUs, especially when you want to match the right GPU for your specific performance/efficiency needs. To this end we are also adding support for NVIDIA A100 80 Gig and the NVIDIA L4 GPU, which is rolling out this quarter.
Developer experience
Building and operating streaming pipelines is different from batch pipelines. Users need the right tooling to build and operate pipelines that can run 24*7 and offer high SLAs to downstream customers. The following new capabilities are designed with developers and data engineers in mind:
Data sampling – One common challenge that users have is the following knowing that there is a problem, but having no way of associating the problem with a particular set of data that was processed when the problem occurred. Data sampling is designed to address this specific problem. Data sampling lets you observe actual data at each step of a pipeline, so you can debug problems with your pipeline.Straggler detection – Stragglers are work items that take significantly longer to complete than other work items in the same stage. They reduce parallelism and block new work from starting. Dataflow can now detect stragglers and can also try to determine the cause of the straggler. You can view detected stragglers right in the UI, viewing them by stage or worker, for more flexibilityCost monitoring – Dataflow users have asked for the ability to easily look up estimated costs for their jobs. Billing data, including billing exports, is a reliable and authoritative source for billing data. Now, to support easy lookup of billing estimates for individual users who may not have billing data access, we have built cost estimation right into the Dataflow UI.Autoscaling observability – Understanding how autoscaling impacts a job is one frequently requested feature. You can now view autoscaling monitoring charts for streaming jobs within the Dataflow monitoring interface. These charts display metrics over the duration of a pipeline job and include information such as the number of worker instances used by your job at any point in time, autoscaling logs, estimated backlog over time, and average CPU utilization over time.
Job lifecycle Management – Thanks to Eventarc integration, you can now create event-driven workflows triggered by state changes in your Dataflow jobs.Regional placement for workers allow your jobs to automatically utilize all available zones within the region so that your jobs are not impacted by resource obtainability issues.UDF builder for templates – Many Dataflow users rely on Dataflow templates, either provided by Google or built by your organization for repetitive tasks and pipelines that can be easily templatized. One of the powerful features of templates is the ability to customize processing by providing an UDF. We have now made the experience even easier by allowing you to create and edit UDFs right in the UI. You continue to have the ability to use a previously created UDF. In addition we have published UDF samples in GitHub that cover many common cases.Cloud Code plug-in for Dataflow – Cloud Code makes it easier to create, deploy and integrate applications in Google Cloud using your favorite IDEs such as IntelliJ. The Dataflow plug-in allows you to execute and debug Dataflow pipelines from the IntelliJ IDE directly.
Ecosystem integration
None of these new capabilities are useful if you can’t get to the data that you need. That’s why we continue to expand the products and services Dataflow works. For instance:
To reduce the time it takes for you to architect and deploy solutions for your business problems, we partnered with Google’s Industry Solutions team to launch Manufacturing Data Engine, an end-to-end solution that uses Dataflow and other Google Cloud services to enable “connected factory” use cases from data acquisition to ingestion, transformation, contextualization, storage and use case integration, thereby accelerating time to value and enabling faster ROI. We plan to launch more solutions like Manufacturing Data Engine.
Learning and development
It’s easy to get started with Dataflow. Templates provide a turn-key mechanism to deploy pipelines, and Apache Beam is intuitive enough to write production-grade pipelines in a matter of hours. At the same time, you get more benefit out of the platform if you have a deep understanding of the SDK and the benefit of best practices. Here are some new developer learning and development assets:
Dataflow Cookbook: This comprehensive collection of code samples will help you learn, develop and solve sophisticated problems.We partnered with the Apache Beam community to launch Tour of Beam (an online, always-on, no-setup notebook environment that allow developers to interactively learn Beam code), Beam Playground (a free online tool to interactively try out Apache Beam examples and transforms), and Beam Starter Projects (easy-to-clone starter projects for all major Apache Beam languages to make getting started easier). Beam Quest certification complements these learning and development efforts, providing users recognition that will help them build accreditation,We hosted the Beam Summit in our New York Pier 53 campus on June 13-15. All of the content (30 sessions spread out across 2 days and 6 workshops) from the Beam Summit is now available online.Lastly, we are working with the Apache Beam community to host the annual Beam College. This virtual event will help developers with various levels of Beam expertise to learn and master new concepts with lectures, hands-on workshops, and expert Q&A sessions. Register here for the October 23-27 event.
Thanks for reading this far. We are excited to get these capabilities to you and looking forward to seeing all the ways in which you use the product to solve your hardest challenges.
It’s hard to imagine (or for some of us, remember) life without the internet. From work, to family, to leisure, the internet has become interwoven in the fabric of our routines. But what if all of that got cut off, suddenly and without warning?
For many people around the world, that’s a daily reality. In 2022, 35 countries cut off internet access, across at least 187 instances, with each outage lasting hours, days, or weeks.
Censored Planet Observatory, a team of researchers at the University of Michigan, has been working since 2010 to shine a spotlight on this problem. They measure and track how governments block content on the internet, and then make that data publicly accessible to analyze and explore from a dashboard developed in collaboration with Google’s Jigsaw. To help restore unfiltered access to the internet in the face of censorship, Jigsaw also builds open source circumvention tools like Outline.
aside_block<ListValue: [StructValue([(‘title’, ‘Learn more about Censored Planet and their work with Google Cloud’), (‘body’, <wagtail.rich_text.RichText object at 0x3ebccb9a1c70>), (‘btn_text’, ‘Read more’), (‘href’, ‘https://cloud.google.com/transform/cloud-and-consequences-internet-censorship-data-enters-the-transformation-age’), (‘image’, <GAEImage: Cloud_and_consequences_header_2436x1200>)])]>
Fighting internet blackouts around the world requires a variety of scalable, distributed tools to better understand the problem. Jigsaw and Censored Planet turned to the Google Cloud team to help create a data pipeline and dashboards to highlight the global impact of censorship campaigns.
How do we query that?
When the Google teams started working with the Michigan team in 2020, the main data outputs of their daily censorship measurements were large, flat files, some around 5 GB each. Loading all this data (around 10 TB total) required over 100 on-premises high-memory computers to achieve real-time querying capability. Just getting to this stage took heroic efforts: The project gathers censorship measurement data from over 120 countries every few days, and the records go back to 2018, so we’re talking about many files, from many sources, across many formats.
It was no small feat to build this consolidated dataset, and even harder to develop it so that researchers could query and analyze its contents. Vast troves of data in hand, the teams at Censored Planet and Google focused on how to make this tool more helpful to the researchers tracking internet censorship.
While open and freely shared, you needed specific technical expertise to manipulate or query the Censored Planet data: It wasn’t all in one place, and wasn’t set up for SQL-like analysis. The team and its partners needed a better way.
One day’s worth of data can be processed in just a few hours overnight.
Sarah Laplante, lead engineer for censorship measurement at Jigsaw, wondered if there was a quick and easy way to load this big dataset into BigQuery, where it could be made easily accessible and queryable.
“Building the dashboard would not have been possible without the cloud tech,” said Laplante. “The pipeline needs to reprocess the entire dataset in 24 hours. Otherwise, there’s suspect data scattered throughout.”
She figured out a sample workflow that led to the first minimum viable product:
Load the data into Dataprep, a cloud data service to visually explore, clean, and prepare data for analysis and machine learningUse Datarep to remove duplicates, fix errors, and fill in missing valuesExport the results to BigQuery
This workflow made analysis much easier, but there was a catch. Every day, the sources tracking censorship created new files, but those JSON files required domain knowledge, and parsing with code, in order to be used in BigQuery. This “minimum viable product” could not be scaled. Different kinds of filtering, restrictions, and network controls led to different outputs.
It was a problem in desperate need of a solution that included automation and standardization. The teams needed more and specific tools.
Creating a true data pipeline
With new data files being created every day, the team needed to develop a process to consolidate, process, and export these from JSON to BigQuery in under 24 hours. That way, researchers would be able to query and report on the day’s censorship data along with all historical data.
Designed to handle a mix of batch and stream data, Apache Beam gave the Censored Planet folks a way to process the dataset each night, making sure the latest data is ready in the morning. On Google Cloud, the team used Dataflow to make managing the Beam pipelines easier.
There were some snags at first. For example, some data files were so large they slowed down the processing pipeline. Others included metadata that wasn’t needed for the visualizations. Sarah and team put in place queries to shrink them down for faster processing and lower overhead, only parsing the data that would be useful for the tables and graphs they were generating. Today, the job can go out to thousands of workers at once, and finish quickly. One day’s worth of data can be processed in just a few hours overnight.
Optimizing the dashboards
They solved the problem of how to process the dataset, but to make that dataset useful required good reports and dashboards. To get started quickly the team began with rapid prototyping, testing out options and configurations with Looker Studio and iterating quickly. Using an easy-to-use tool let them answer practical, immediate questions.
Those early versions helped inform what the eventual final dashboard would look like. Reaching a final dashboard design involved some UX studies with researchers, where the Censored Planet team watched them use the dashboard to attempt to answer their questions, and adjust to improve usability, functionality or ease of use.
Researchers using the Censored Planet data wanted to see which governments were censoring the internet and what tools they were using in as close to real-time as possible. To make the dashboards load and render quickly, the team began clustering and partitioning data tables. By cutting out data that they didn’t need to display, they also cut down on Looker Studio costs.
The data pipeline, from original measurements to dashboards.
Within BigQuery, the team partitioned the data by date, so it was easy to exclude historical data that was not needed for most reports. Then they partitioned by data source, country, and network. Since tracking and response often focused on one country at a time, this made queries and loading dashboards smaller, which made them much faster.
Putting the data together
The goal was for all these queries to end up in a Looker Studio dashboard, with filters that let viewers select the data source they want to track. To make this work, the team merged the data sources into one table, then split that table out so that it was easier to filter and view.
There was more to this exercise than indulging internet censorship researchers’ need for speed.
Adding the ability to quickly reprocess the data, and then explore it through a speedy dashboard, meant the team could much more rapidly find and close gaps in their understanding of how the censors operated. They were able to notice where the analysis methodology missed out on certain measurements or data points, and then deploy, test, and validate fixes quickly. On top of creating a new dashboard and new data pipeline, Censored Planet also created a better analysis process. You can dive much deeper into that methodology in their paper published in Free and Open Communications on the Internet.
Building the dashboards in Looker Studio brought operational benefits, too. Because Looker Studio is a Google Cloud hosted offering, the team minimized creation and maintenance overhead and were able to quickly spin up new dashboards. That gave them more time to focus on gathering data, and delivering valuable reports for key use cases.
Looker Studio also lets them iterate quickly on the user experience for researchers, engineers, non-technical stakeholders, and partners. It was also easy to edit, so they could update or modify the dashboard quickly, and even give end users the opportunity to export it, or remix it to make the visualizations more helpful.
Censorship monitoring at cloud scale
Shifting to a cloud-based analysis pipeline has made sharing and filtering all this data much more efficient for the more than 60 global organizations that rely on Censored Planet to monitor internet freedom and advocate for increased internet access. The team used Google Cloud tools to quickly experiment, iterate, and shift their data pipeline, prototyping new tools and services.
Google’s data analysis toolkit also helped to keep costs down for the University of Michigan sponsors. To isolate inefficient queries, they exported all the billing logs into BigQuery and figured out which Looker Studio reports were pulling too much data, so they could filter and streamline.
What’s next for Censored Planet
Censored Planet is working on more data sources to add to the dashboard, including DNS censorship data. The organization encourages everybody interested in researching internet censorship to use their data, share screenshots, and publish their analyses. To build a data pipeline with Google Cloud similar to Censored Planet’s, you can start with these three guides: