As consumer data privacy regulations tighten and the end of third-party cookies looms, organizations of all sizes may be looking to carve a path toward consent-positive, privacy-centric ways of working. Consumer-facing brands should look more closely at the customer data they’re collecting, and learn to embrace a first-party data-driven approach to doing business.
But while brands today recognize the privacy and consumer consent imperative, many may not know where to start. What’s worse is that many don’t know what consumers really want when it comes to data privacy. Today, 40% of consumers do not trust brands to use their data ethically (KPMG)1.There is room, however, for improvement.
Although the gap between how brands and consumers think about privacy is evident, it doesn’t need to continue to widen. Organizations must begin to treat consumer data privacy as a pillar of their business: as a core value that guides the way data is used, processes are run, and teams behave. By implementing a cross-functional data advocacy panel, brands can ensure that the protection of consumer data is always top of mind — and that a dedicated team remains accountable for guaranteeing privacy-centricity throughout the organization.
Why a data advocacy panel?
Winning brands see the customer data privacy imperative as an opportunity, not a threat. Consumers today are clear about what they want, and it’s simply up to brands to deliver. First and foremost, transparency is key. Most consumers are already demanding more transparency from the brands they frequent, but as many as 40% of consumers would willingly share personal information if they knew how it would be used (KPMG)1.This simple value exchange could be the key to a first-party data-driven future. So what’s deterring businesses from taking action?
Organizational change can seem like a daunting undertaking, and many businesses who do recognize the importance of consumer data privacy simply don’t know how to move forward. What steps can they take? Where do they start? How can they prepare? In addition, how can they make sure the improvements they invest in have an impact now and in the long term? A data advocacy panel, woven into the DNA of the organization, can serve as a north star for consent-positivity.
How can I implement a data advocacy panel?
A data advocacy panel’s mission focuses on building and maintaining a consent-positive culture across an organization. It can serve as a way to hone the power of customer data for your business while also giving the power of consent to your customers. And in an era when most business decisions are (and should be) driven by data, having a data advocacy panel makes a world of sense.
But what exactly does a data advocacy panel look like? Importantly, you need to include the right players. Your data advocacy panel should include representatives from every business unit that has responsibility for protecting, collecting, creating, sharing, or accessing data of any kind. These members might include marketing, IT/security, Legal, HR, accounting, customer service, sales, and/or partner relations.
These team members should then come together to tackle two key goals: to set the strategy and policies for how data is handled throughout the organization, and to react quickly to new data developments such as:
a potential data breach,
shifting market sentiments, or
new compliance requirements
It should be the responsibility of the data advocacy panel to help decide how, when, why, and where data is used in your business.
Once a company has established a data advocacy panel, they’ve also built a foundation upon which to create a new and future-ready organizational structure that will provide maximal transparency and auditability, explainability, and expanded support for how first-party consumer data is collected, joined, stored, managed, and activated.
The value of consumer consent, data advocacy, and privacy-centricity
How do you become, not just a privacy-minded, but a consent-positive brand?
According to Google Cloud’s VP of Consumer Packaged Goods, Giusy Buonfantino, “The changing privacy landscape and shifting consumer expectations mean companies must fundamentally rethink how they collect, analyze, store, and manage consumer data to drive better business performance and provide customers with personalized experiences.”
The changing privacy landscape and shifting consumer expectations mean companies must fundamentally rethink how they collect, analyze, store, and manage consumer data to drive better business performance and provide customers with personalized experiences. Giusy Buonfantino Google Cloud’s VP of Consumer Packaged Goods
Companies are adopting Customer Data Platforms (CDP) to enable a privacy-centric engagement with their customers. Lytics’ customer data platform solution is built with Google Cloud BigQuery to help enterprises continue to evolve how they capture and use consumer data in our changing environment. Lytics on BigQuery helps businesses collect and interpret first-party behavioral customer data on a secure and scalable platform with built-in machine learning.
Reggie Wideman, Head of Strategy, Lytics noted, “By design, traditional CDPs create enormous risk by asking the company to collect and unify customer data in the CDP system, separate from all other customer data and outside of your internal controls and governance. We think there’s a better, smarter way. By taking a composable CDP approach we enable companies to layer our tools into their existing martech ecosystems, rather than being forced to build around a proprietary, external CDP toolset.”
By design, traditional CDPs create enormous risk by asking the company to collect and unify customer data in the CDP system, separate from all other customer data and outside of your internal controls and governance. We think there’s a better, smarter way. Reggie Wideman Head of Strategy, Lytics
Wideman continues, ”This allows us to enable developers and data managers to create a ‘Customer 360’ in their own secure, privacy-compliant data warehouse. The advantage of this approach is a privacy-centric architecture that collects and unifies customer data creating a profile schema that is synced to the customer’s data warehouse, helping internal data teams build and manage a secure, persistent ‘Customer 360’, while also providing a direct sync to marketing tools and channels for targeted advertising and activation.”
In short, it’s not just about small tweaks and minor changes. It’s about starting with a catalyst that will drive larger-scale change. That catalyst is your data advocacy panel, and it is and will continue to be at the center of the value exchange between your brand and your customers.
“The importance of ‘consumer consent’ and ‘value exchange’ is front and center in the conversations we are having with our customers,” shares Buonfantino, “And first-party data done right can help drive more meaningful high-value consumer engagement.”
For more information on data advocacy panels, how to implement them, and how they bring the power of your customer data to every employee, readthe whitepaper. In addition, we invite you to explore the Lytics CDP on the Google Cloud Marketplace.
Today we are announcing Data Studio, our self-service business intelligence and data visualization product, as a Google Cloud service, enabling customers to get Data Studio on the Google Cloud terms of service, simplifying product acquisition and integration in their company’s technology stack.
Why are we doing this?
Google Cloud customers of all types widely use Data Studio today as a critical piece of their business intelligence measurement and reporting workflow. Many of our customers have asked for Data Studio on Google Cloud terms, to ensure Google supports the same privacy and security commitments for Data Studio as for other Google Cloud products. Now, that’s possible.
What benefits do customers get?
Data Studio now supports additional compliance standards for internal auditing, controls and information system security, including SOC 1, SOC 2, SOC 3 and PCI DSS, with more compliance certifications coming soon. Data Studio can be used under the same terms as other Google Cloud services, reducing procurement complexity and enabling it to be covered by customers’ existing Cloud Master Agreement.
If customers are subject to HIPAA and have signed a Google Cloud Business Associate Amendment (BAA), it will apply to Data Studio as well. Data Studio is still free to use, although as a free offering, it is not currently supported through Google Cloud support.
What’s not changing
This additional certification does not change a single pixel of the end-user experience for Data Studio. Customers can still analyze their data, create beautiful reports, and share insights using all of Data Studio’s self-service BI functionality with no disruption. For customers who aren’t yet using Google Cloud, Data Studio will continue to be available under our existing terms and conditions as well.
When everyone is empowered to dig into data, the results can be transformational. This is just the beginning of our investment in making the power of Google Cloud accessible to everyone through easy-to-use cloud BI.
Google Cloud CLI makes it very quick and easy for engineers to get started with initial development on Google Cloud Platform and perform many common cloud tasks. The majority of the initial development experience is via the command line interface using tools like gsutil, gcloud, but getting the code to production requires writing ceremonial code or building API-level integration.
Developers often come across scenarios where they need to run simple commands in their production environment on a scheduled basis. In order to execute on this successfully, they are required to code and create schedules in an orchestration tool such as Data Fusion or Cloud Composer.
One such scenario is copying objects from one bucket to another (e.g. GCS to GCS or S3 to GCS), which is generally achieved by using gsutil. Gsutil is a Python application that is used to interact with Google Cloud Storage through the command line. It can be used to perform a wide range of functions such as bucket and object management tasks, including: creating and deleting buckets, uploading, downloading, deleting, copying and moving objects.
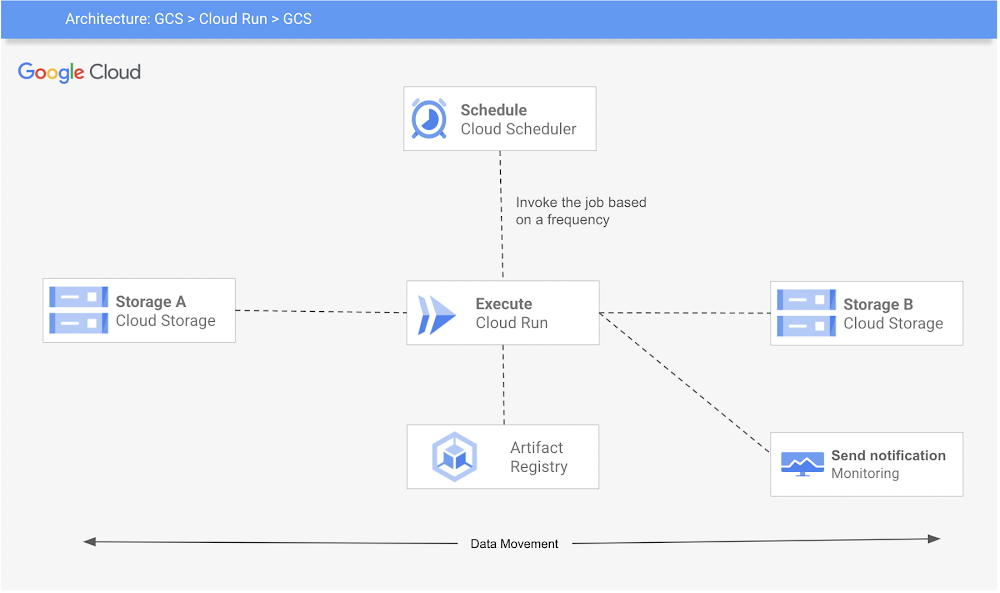
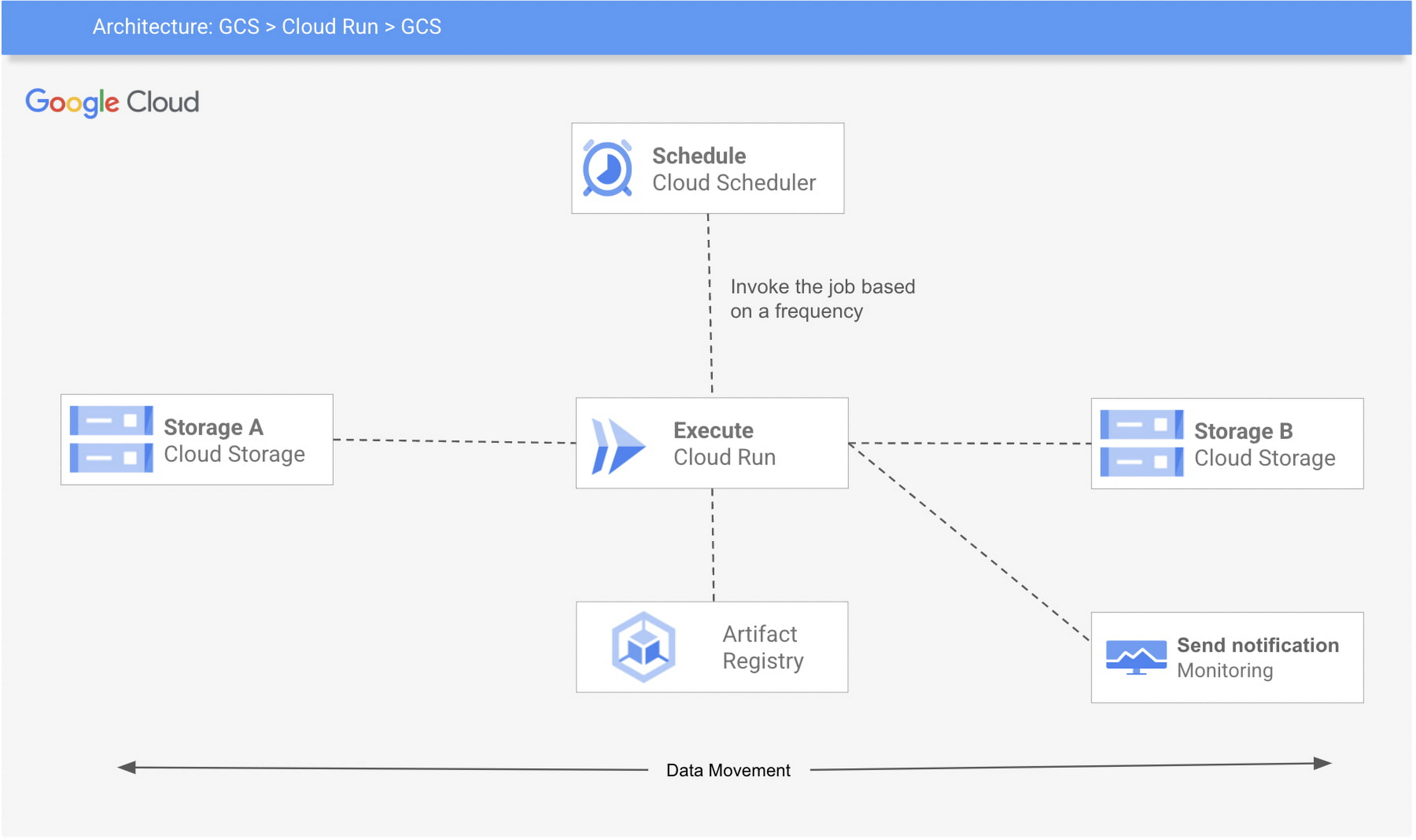
In this post, we will describe an elegant and efficient way to schedule commands like Gsutil using Cloud Run and Cloud Scheduler. This methodology saves time and reduces the amount of effort required for pre-work and setup in building API level integration.
You can find the complete source code for this solution within our Github.
Here’s a look at the architecture of this process:
The 3 Google Cloud Platform (GCP) services used are:
Cloud Run: The code will be wrapped in a container, gcloud SDK will be installed ( or you can also use a base image with gcloud SDK already installed). Cloud Scheduler: A Cloud Scheduler job invokes the job created in Cloud Run on a recurring schedule or frequency.Cloud Storage: Google Cloud Storage (GCS) is used for storage and retrieval of any amount of data.
This example requires you to set up your environment for Cloud Run and Cloud Scheduler, create a Cloud Run job, package it into a container image, upload the container image to Container Registry, and then deploy to Cloud Run. You can also build monitoring for the job and create alerts. Follow below steps to achieve that:
Step 1: Enable services (Cloud Scheduler, Cloud Run) and create a service account
code_block[StructValue([(u’code’, u’export REGION=<<Region>>rnexport PROJECT_ID=<<project-id>>rnexport PROJECT_NUMBER=<<project-number>>rnexport SERVICE_ACCOUNT=cloud-run-sarnrngcloud services enable cloudscheduler.googleapis.com run.googleapis.com cloudbuild.googleapis.com cloudscheduler.googleapis.com –project ${PROJECT_ID}rnrngcloud iam service-accounts create ${SERVICE_ACCOUNT} \rn –description=”Cloud run to copy cloud storage objects between buckets” \rn –display-name=”${SERVICE_ACCOUNT}” –project ${PROJECT_ID}rnrngcloud projects add-iam-policy-binding ${PROJECT_ID} \rn –member serviceAccount:${SERVICE_ACCOUNT}@${PROJECT_ID}.iam.gserviceaccount.com \rn –role “roles/run.invoker”‘), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e20a44c5f10>)])]
To deploy a Cloud Run service using a user-managed service account, you must have permission to impersonate (iam.serviceAccounts.actAs) that service account. This permission can be granted via the roles/iam.serviceAccountUser IAM role.
Step 3: Create a job with the GCS_SOURCE and GCS_DESTINATION for gcs-to-gcs bucket. Make sure to give the permission (roles/storage.legacyObjectReader) to the GCS_SOURCE and roles/storage.legacyBucketWriter to GCS_DESTINATION
code_block[StructValue([(u’code’, u’export GCS_SOURCE=<<Source Bucket>>rnexport GCS_DESTINATION=<<Source Bucket>>rnrngsutil iam ch \rnserviceAccount:${SERVICE_ACCOUNT}@${PROJECT_ID}.iam.gserviceaccount.com:objectViewer \rn ${GCS_SOURCE}rnrngsutil iam ch \rnserviceAccount:${SERVICE_ACCOUNT}@${PROJECT_ID}.iam.gserviceaccount.com:legacyBucketWriter \rn ${GCS_DESTINATION}rnrngcloud beta run jobs create gcs-to-gcs \rn –image gcr.io/${PROJECT_ID}/gsutil-gcs-to-gcs \rn –set-env-vars GCS_SOURCE=${GCS_SOURCE} \rn –set-env-vars GCS_DESTINATION=${GCS_DESTINATION} \rn –max-retries 5 \rn –service-account ${SERVICE_ACCOUNT}@${PROJECT_ID}.iam.gserviceaccount.com \rn –region $REGION –project ${PROJECT_ID}’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3e20a44c5310>)])]
Step 4: Finally, create a schedule to run the job.
Step 5: Create monitoring and alerting to check if the cloud run failed.
Cloud Run is automatically integrated with Cloud Monitoring with no setup or configuration required. This means that metrics of your Cloud Run services are captured automatically when they are running.
You can view metrics either in Cloud Monitoring or in the Cloud Run page in the console. Cloud Monitoring provides more charting and filtering options. Follow these steps to create and view metrics on Cloud Run.
The steps described in the blog present a simplified method to invoke the most commonly used developer-friendly CLI commands on a schedule, in a production setup. The code and example provided above are easy to use and help avoid the need of API level integration to schedule commands like gsutil, gcloud etc.
Iteration and innovation fuel the data-driven culture at Mercado Libre. In our first post, we presented our continuous intelligence approach, which leverages BigQuery and Looker to create a data ecosystem on which people can build their own models and processes.
Using this framework, the Shipping Operations team was able to build a new solution that provided near real-time data monitoring and analytics for our transportation network and enabled data analysts to create, embed, and deliver valuable insights.
The challenge
Shipping operations are critical to success in e-commerce, and Mercado Libre’s process is very complex since our organization spans multiple countries, time zones, and warehouses, and includes both internal and external carriers. In addition, the onset of the pandemic drove exponential order growth, which increased pressure on our shipping team to deliver more while still meeting the 48-hour delivery timelines that customers have come to expect.
This increased demand led to the expansion of fulfillment centers and cross-docking centers, doubling and tripling the nodes of our network (a.k.a. meli-net) in the leading countries where we operate. We also now have the largest electric vehicle fleet in Latin America and operate domestic flights in Brazil and Mexico.
We previously worked with data coming in from multiple sources, and we used APIs to bring it into different platforms based on the use case. For real-time data consumption and monitoring, we had Kibana, while historical data for business analysis was piped into Teradata. Consequently, the real-time Kibana data and the historical data in Teradata were growing in parallel, without working together. On one hand, we had the operations team using real-time streams of data for monitoring, while on the other, business analysts were building visualizations based on the historical data in our data warehouse.
This approach resulted in a number of problems:
The operations team lacked visibility and required support to build their visualizations. Specialized BI teams became bottlenecks.
Maintenance was needed, which led to system downtime.
Parallel solutions were ungoverned (the ops team used an Elastic database to store and work with attributes and metrics) with unfriendly backups and data bounded for a period of time.
We couldn’t relate data entities as we do with SQL.
Striking a balance: real-time vs. historical data
We needed to be able to seamlessly navigate between real-time and historical data. To address this need, we decided to migrate the data to BigQuery, knowing we would leverage many use cases at once with Google Cloud.
Once we had our real-time and historical data consolidated within BigQuery, we had the power to make choices about which datasets needed to be made available in near real-time and which didn’t. We evaluated the use of analytics with different time windows tables from the data streams instead of the real-time logs visualization approach. This enabled us to serve near real-time and historical data utilizing the same origin.
We then modeled the data using LookML, Looker’s reusable modeling language based on SQL, and consumed the data through Looker dashboards and Explores. Because Looker queries the database directly, our reporting mirrored the near real-time data stored in BigQuery. Finally, in order to balance near real-time availability with overall consumption costs, we analyzed key use cases on a case-by-case basis to optimize our resource usage.
This solution prevented us from having to maintain two different tools and featured a more scalable architecture. Thanks to the services of GCP and the use of BigQuery, we were able to design a robust data architecture that ensures the availability of data in near real-time.
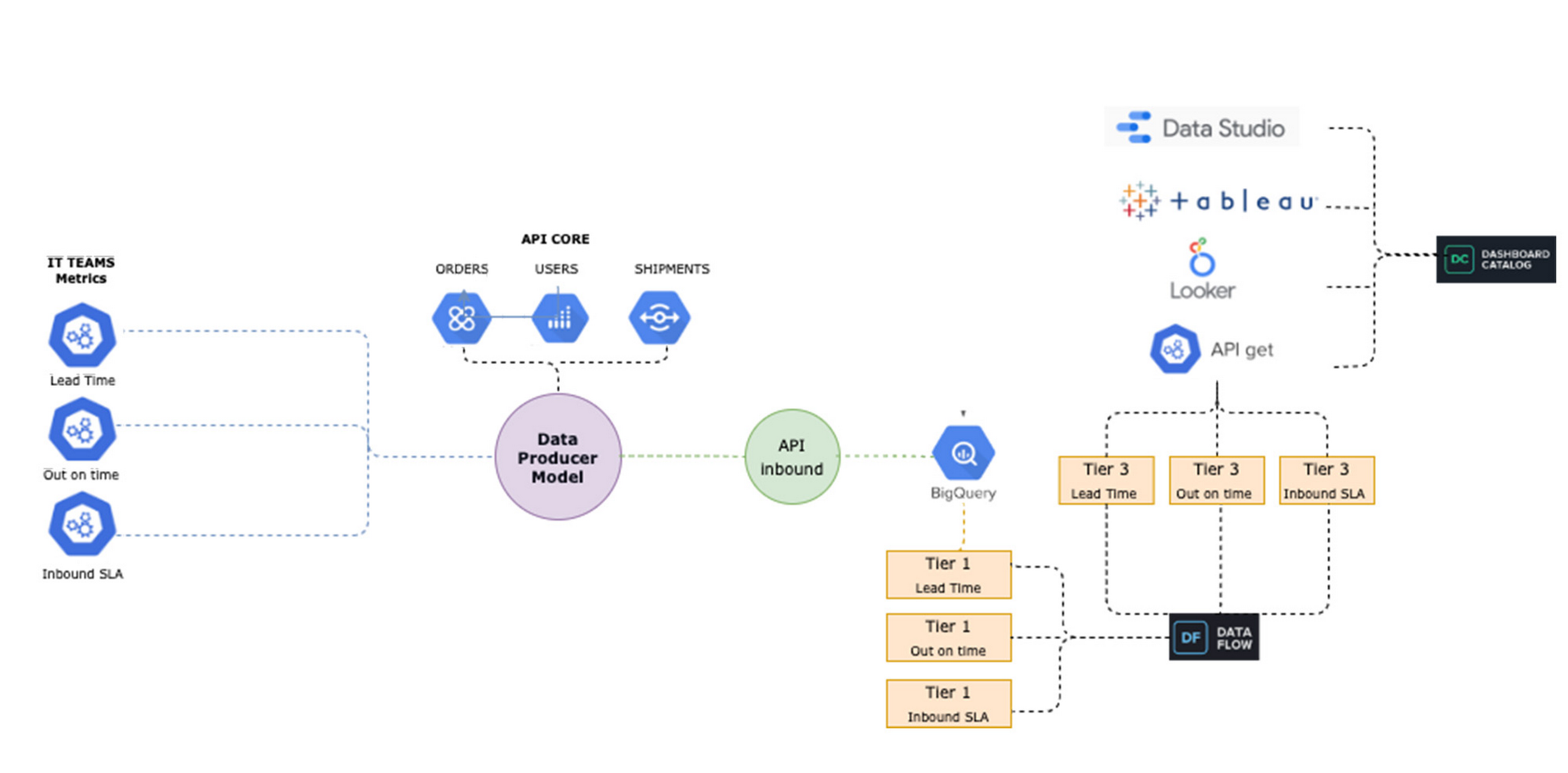
Streaming data with our own Data Producer Model: from APIs to BigQuery
To make new data streams available, we designed a process which we call the “Data Producer Model” (“Modelo Productor de Datos” or MPD) where functional business teams can serve as data creators in charge of generating data streams and publishing them as related information assets we call “data domains”. Using this process, the new data comes in via JSON format, which is streamed into BigQuery. We then use a 3-tiered transformation process to convert that JSON into a partitioned, columnar structure.
To make these new data sets available in Looker for exploration, we developed a Java utility app to accelerate the development of LookML and make it even more fun for developers to create pipelines.
The end-to-end architecture of our Data Producer Model.
The complete “MPD” solution results in different entities being created in BigQuery with minimal manual intervention. Using this process, we have been able to automate the following:
The creation of partitioned, columnar tables in BigQuery from JSON samples
The creation of authorized views in a different GCP BigQuery project (for governance purposes)
LookML code generation for Looker views
Job orchestration in a chosen time window
By using this code-based incremental approach with LookML, we were able to incorporate techniques that are traditionally used in DevOps for software development, such as using Lams to validate LookML syntax as a part of the CI process and testing all our definitions and data with Spectacles before they hit production. Applying these principles to our data and business intelligence pipelines has strengthened our continuous intelligence ecosystem. Enabling exploration of that data through Looker and empowering users to easily build their own visualizations has helped us to better engage with stakeholders across the business.
The new data architecture and processes that we have implemented have enabled us to keep up with the growing and ever-changing data from our continuously expanding shipping operations. We have been able to empower a variety of teams to seamlessly develop solutions and manage third party technologies, ensuring that we always know what’s happening – and more critically – enabling us to react in a timely manner when needed.
Outcomes from improving shipping operations:
Today, data is being used to support decision-making in key processes, including:
Carrier Capacity Optimization
Outbound Monitoring
Air Capacity Monitoring
This data-driven approach helps us to better serve you -and everyone- who expects to receive their packages on-time according to our delivery promise. We can proudly say that we have improved both our coverage and speed, delivering 79% of our shipments in less than 48 hours in the first quarter of 2022.
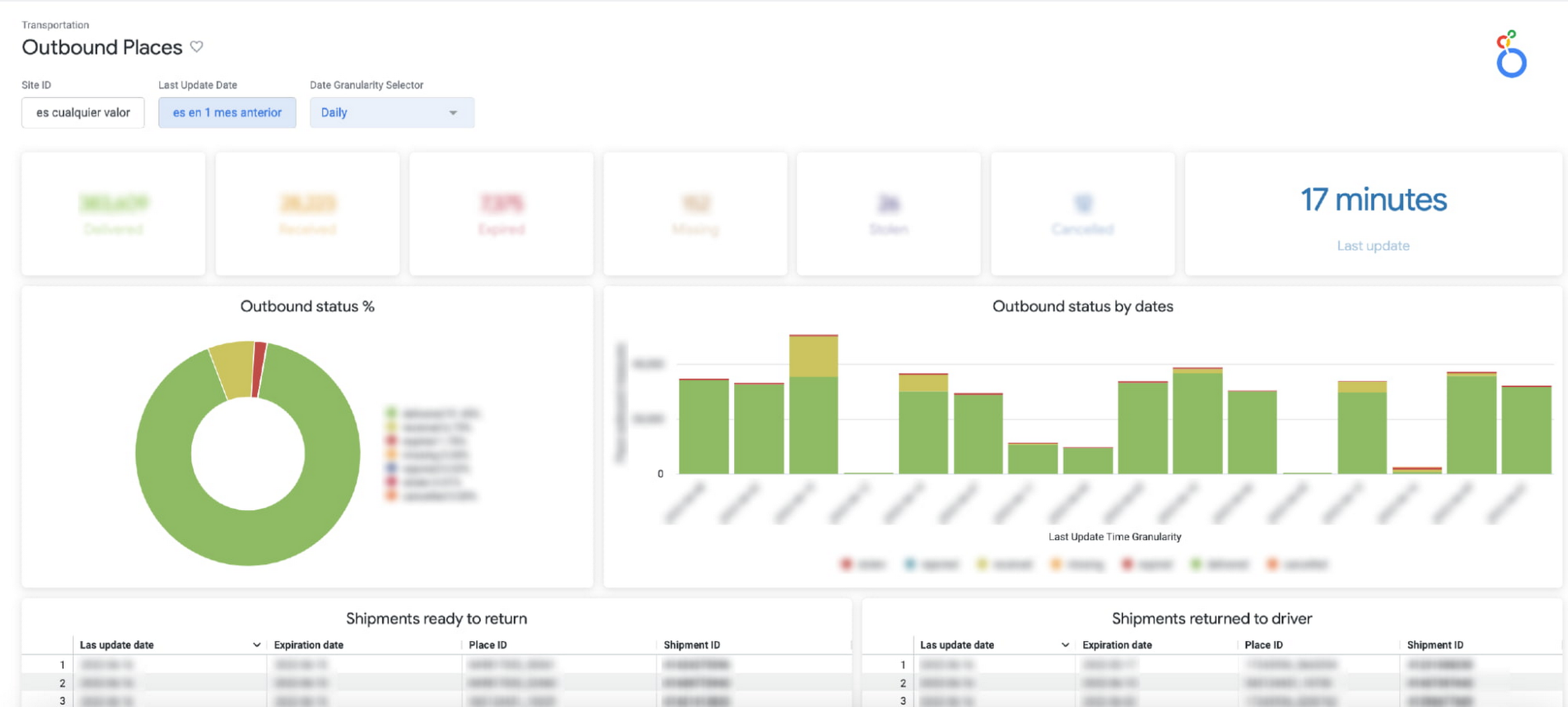
Here is a sneak peek into the data assets that we use to support our day-to-day decision making:
a. Carrier Capacity: Allows us to monitor the percentage of network capacity utilized across every delivery zone and identify where delivery targets are at risk in almost real time.
b. Outbound Places Monitoring: Consolidates the number of shipments that are destined for a place (the physical points where a seller picks up a package), enabling us to both identify places with lower delivery efficiency and drill into the status of individual shipments.
c. The Air Capacity Monitoring: Provides capacity usage monitoring for our aircrafts running each of our shipping routes.
Costs into the equation
The combination of BigQuery and Looker also showed us something we hadn’t seen before: overall cost and performance of the system. Traditionally, developers maintained focus on metrics like reliability and uptime without factoring in associated costs.
By using BigQuery’s information schema, Looker Blocks, and the export of BigQuery logs, we have been able to closely track data consumption, quickly detect underperforming SQL and errors, and make adjustments to optimize our usage and spend.
Based on that, we know the Looker Shipping Ops dashboards generate a concurrency of more than 150 queries, which we have been able to optimize by taking advantage of BigQuery and Looker caching policies.
The challenges ahead
Using BigQuery and Looker has enabled us to solve numerous data availability and data governance challenges: single point access to near real-time data and to historical information, self-service analytics & exploration for operations and stakeholders across different countries & time zones, horizontal scalability (with no maintenance), and guaranteed reliability and uptime (while accounting for costs), among other benefits.
However, in addition to having the right technology stack and processes in place, we also need to enable every user to make decisions using this governed, trusted data. To continue achieving our business goals, we need to democratize access not just to the data but also to the definitions that give the data meaning. This means incorporating our data definitions with our internal data catalog and serving our LookML definitions to other data visualizations tools like Data Studio, Tableau or even Google Sheets and Slides so that users can work with this data through whatever tools they feel most comfortable using.
If you would like a more indepth look at how we made new data streams available from a process we designed called the “Data Producer Model” (“Modelo Productor de Datos” or MPD) register to attend our webcast on August 31.
While learning and adopting new technologies can be a challenge, we are excited to tackle this next phase, and we expect our users will be too, thanks to a curious and entrepreneurial culture. Are our teams ready to face new changes? Are they able to roll out new processes and designs? We’ll go deep on this in our next post.
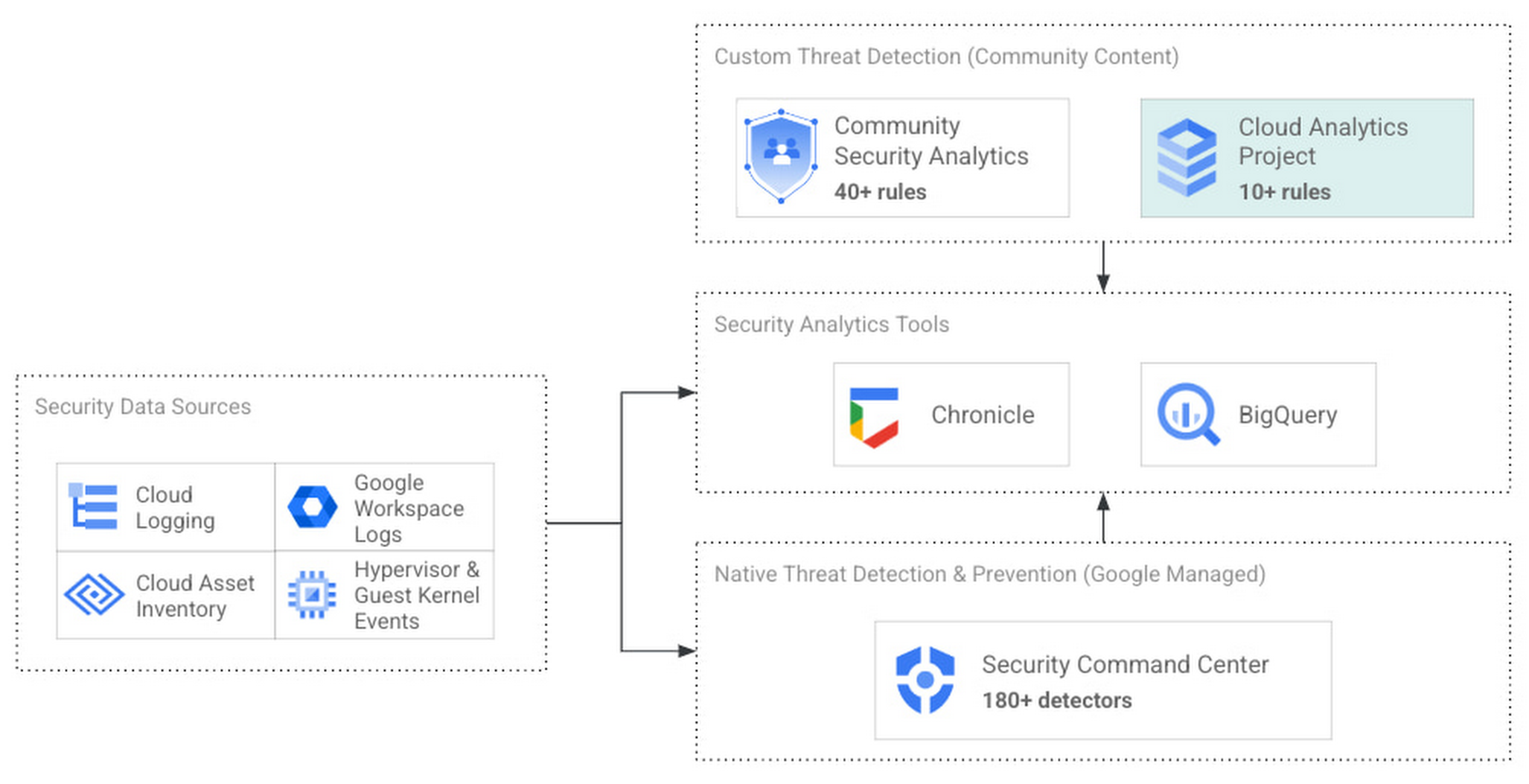
The cybersecurity industry is faced with the tremendous challenge of analyzing growing volumes of security data in a dynamic threat landscape with evolving adversary behaviors. Today’s security data is heterogeneous, including logs and alerts, and often comes from more than one cloud platform. In order to better analyze that data, we’re excited to announce the release of the Cloud Analytics project by the MITRE Engenuity Center for Threat-Informed Defense, and sponsored by Google Cloud and several other industry collaborators.
Since 2021, Google Cloud has partnered with the Center to help level the playing field for everyone in the cybersecurity community by developing open-source security analytics. Earlier this year, we introduced Community Security Analytics (CSA) in collaboration with the Center to provide pre-built and customizable queries to help detect threats to your workloads and to audit your cloud usage. The Cloud Analytics project is designed to complement CSA.
The Cloud Analytics project includes a foundational set of detection analytics for key tactics, techniques and procedures (TTPs) implemented as vendor-agnostic Sigma rules, along with their adversary emulation plans implemented with CALDERA framework. Here’s a overview of Cloud Analytics project, how it complements Google Cloud’s CSA to benefit threat hunters, and how they both embrace Autonomic Security Operations principles like automation and toil reduction (adopted from SRE) in order to advance the state of threat detection development and continuous detection and response (CD/CR).
Both CSA and the Cloud Analytics project are community-driven security analytics resources. You can customize and extend the provided queries, but they take a more do-it-yourself approach—you’re expected to regularly evaluate and tune them to fit your own requirements in terms of threat detection sensitivity and accuracy. For managed threat detection and prevention, check out Security Command Center Premium’s realtime and continuously updated threat detection services including Event Threat Detection, Container Threat Detection, and Virtual Machine Threat Detection. Security Command Center Premium also provides managed misconfiguration and vulnerability detection with Security Health Analytics and Web Security Scanner.
Google Cloud Security Foundation: Analytics Tools & Content
Cloud Analytics vs Community Security Analytics
Similar to CSA, Cloud Analytics can help lower the barrier for threat hunters and detection engineers to create cloud-specific security analytics. Security analytics is complex because it requires:
Deep knowledge of diverse security signals (logs, alerts) from different cloud providers along with their specific schemas;
Familiarity with adversary behaviors in cloud environments;
Ability to emulate such adversarial activity on cloud platforms;
Achieving high accuracy in threat detection with low false positives, to avoid alert fatigue and overwhelming your SOC team.
The following table summarizes the key differences between Cloud Analytics and CSA:
Target platforms and language support by CSA & Cloud Analytics project
Together, CSA and Cloud Analytics can help you maximize your coverage of the MITRE ATT&CK® framework, while giving you the choice of detection language and analytics engine to use. Given the mapping to TTPs, some of these rules by CSA and Cloud Analytics overlap. However, Cloud Analytics queries are implemented as Sigma rules which can be translated to vendor-specific queries such as Chronicle, Elasticsearch, or Splunk using Sigma CLI or third party-supported uncoder.io, which offers a user interface for query conversion. On the other hand, CSA queries are implemented as YARA-L rules (for Chronicle) and SQL queries (for BigQuery and now Log Analytics). The latter could be manually adapted to specific analytics engines due to the universal nature of SQL.
Getting started with Cloud Analytics
To get started with the Cloud Analytics project, head over to the GitHub repo to view the latest set of Sigma rules, the associated adversary emulation plan to automatically trigger these rules, and a development blueprint on how to create new Sigma rules based on lessons learned from this project.
The following is a list of Google Cloud-specific Sigma rules (and their associated TTPs) provided in this initial release; use these as examples to author new ones covering more TTPs.
Sigma rule example
Using the canonical use case of detecting when a storage bucket is modified to be publicly accessible, here’s an example Sigma rule (copied below and redacted for brevity):
The rule specifies the log source (gcp.audit), the log criteria (storage.googleapis.com service and storage.setIamPermissions method) and the keywords to look for (allUsers, ADD) signaling that a role was granted to all users over a given bucket. To learn more about Sigma syntax, refer to public Sigma docs.
However, there could still be false positives such as a Cloud Storage bucket made public for a legitimate reason like publishing static assets for a public website. To avoid alert fatigue and reduce toil on your SOC team, you could build more sophisticated detections based on multiple individual Sigma rules using Sigma Correlations.
Using our example, let’s refine the accuracy of this detection by correlating it with another pre-built Sigma rule which detects when a new user identity is added to a privileged group. Such privilege escalation likely occurred before the adversary gained permission to modify access of the Cloud Storage bucket. Cloud Analytics provides an example of such correlation Sigma rule chaining these two separate events.
What’s next
The Cloud Analytics project aims to make cloud-based threat detection development easier while also consolidating collective findings from real-world deployments. In order to scale the development of high-quality threat detections with minimum false positives, CSA and Cloud Analytics promote an agile development approach for building these analytics, where rules are expected to be continuously tuned and evaluated.
We look forward to wider industry collaboration and community contributions (from rules consumers, designers, builders, and testers) to refine existing rules and develop new ones, along with associated adversary emulations in order to raise the bar for minimum self-service security visibility and analytics for everyone.
Acknowledgements
We’d like to thank our industry partners and acknowledge several individuals across both Google Cloud and the Center for Threat-Informed Defense for making this research project possible:
– Desiree Beck, Principal Cyber Operations Engineer, MITRE – Michael Butt, Lead Offensive Security Engineer, MITRE – Iman Ghanizada, Head of Autonomic Security Operations, Google Cloud – Anton Chuvakin, Senior Staff, Office of the CISO, Google Cloud
In the past decade, we have experienced an unprecedented growth in the volume of data that can be captured, recorded and stored. In addition, the data comes in all shapes and forms, speeds and sources. This makes data accessibility, data accuracy, data compatibility, and data quality more complex than ever more. Which is why this year at our Data Engineer Spotlight, we wanted to bring together the Data Engineer Community to share important learning sessions and the newest innovations in Google Cloud.
Did you miss out on the live sessions? Not to worry – all the content is available on demand.
Interested in running a proof of concept using your own data? Sign up here forhands-on workshop opportunities.
#1: The next generation of Dataflow was announced, including Dataflow Go (allowing engineers to write core Beam pipelines in Go, data scientists to contribute with Python transforms, and data engineers to import standard Java I/O connectors). The best part, it all works together in a single pipeline. Dataflow ML (deploy easy ML models with PyTorch, TensorFlow, or stickit-learn to an application in real time), and Dataflow Prime (removes the complexities of sizing and tuning so you don’t have to worry about machine types, enabling developers to be more productive).
#2: Dataform Preview was announced (Q3 2022), which helps build and operationalize scalable SQL pipelines in BigQuery. My personal favorite part is that it follows software engineering best practices (version control, testing, and documentation) when managing SQL. Also, no other skills beyond SQL are required.
#3: Data Catalog is now part of Dataplex, centralizing security and unifying data governance across distributed data for intelligent data management, which can help governance at scale. Another great feature is that it has built-in AI-driven intelligence with data classification, quality, lineage, and lifecycle management.
#4: A how-to on BigQuery Migration Services was covered, which offers end-to-end migrations to BigQuery, simplifying the process of moving data into the cloud and providing tools to help with key decisions. Organizations are now able to break down their data silos. One great feature is the ability to accelerate migrations with intelligent automated SQL translations.
#5: The Google Cloud Hero Game was a gamified three hour Google Cloud training experience using hands-on labs to gain skills through interactive learning in a fun and educational environment. During the Data Engineer Spotlight, 50+ participants joined a live Google Meet call to play the Cloud Hero BigQuery Skills game, with the top 10 winners earning a copy of Visualizing Google Cloud by Priyanka Vergadia.
What was your biggest learning/takeaway from playing this Cloud Hero game?
It was brilliantly organized by the Cloud Analytics team at Google. The game day started off with the introduction and then from there we were introduced to the skills game. It takes a lot more than hands on to understand the concepts of BigQuery/SQL engine and I understood a lot more by doing labs multiple times. Top 10 winners receiving the Visualizing Google Cloud book was a bonus. – Shirish Kamath
Copy and pasting snippets of codes wins you competition. Just kidding. My biggest takeaway is that I get to explore capabilities of BigQuery that I may have not thought about before. – Ivan Yudhi
Would you recommend this game to your friends? If so, who would you recommend it to and why would you recommend it?
Definitely, there is so much need for learning and awareness of such events and games around the world, as the need for Data Analysis through the cloud is increasing. A lot of my friends want to upskill themselves and these kinds of games can bring a lot of new opportunities for them. – Karan Kukreja
What was your favorite part about the Cloud Hero BigQuery Skills game? How did winning the Cloud Hero BigQuery Skills game make you feel?
The favorite part was working on BigQuery Labs enthusiastically to reach the expected results and meet the goals. Each lab of the game has different tasks and learning, so each next lab was giving me confidence for the next challenge. To finish at the top of the leaderboard in this game makes me feel very fortunate. It was like one of the biggest milestones I have achieved in 2022. – Sneha Kukreja
Many organizations struggle to create data-driven cultures where each employee is empowered to make decisions based on data. This is especially true for enterprises with a variety of systems and tools in use across different teams. If you are a leader, manager, or executive focused on how your team can leverage Google’s SRE practices or wider DevOps practices, definitely you are in the right place!
What do today’s enterprises or mature start-ups look like?
Today large organizations are often segmented into hundreds of small teams which are often working around data in the magnitude of several petabytes and in a wide variety of raw forms. ‘Working around data’ could mean any of the following: generating, facilitating, consuming, processing, visualizing or feeding back into the system. Due to a wide variety of responsibilities, the skill sets also vary to a large extent. Numerous people and teams work with data, with jobs that span the entire data ecosystem:
Centralizing data from raw sources and systemsMaintaining and transforming data in a warehouseManaging access controls and permissions for the dataModeling dataDoing ad-hoc data analysis and explorationBuilding visualizations and reports
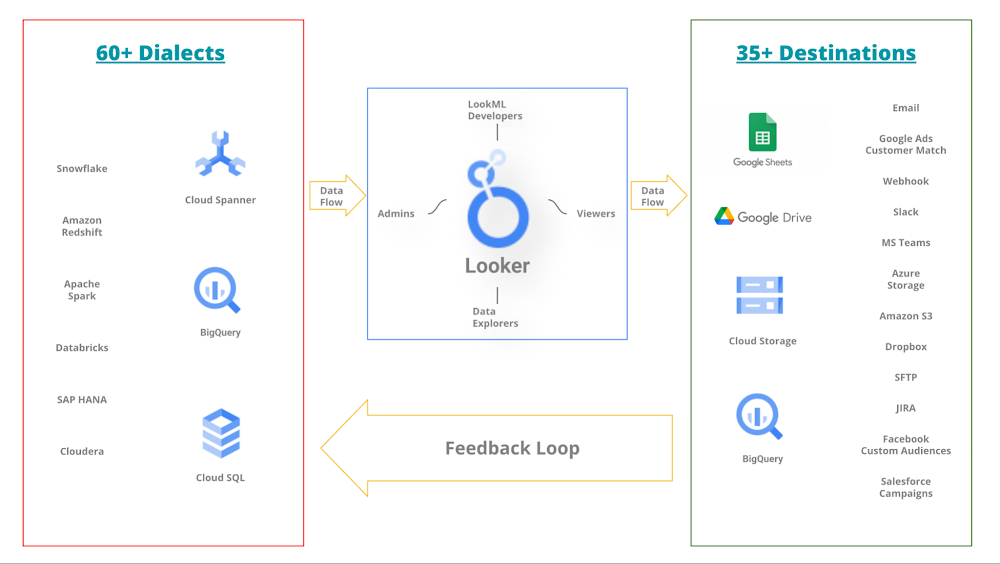
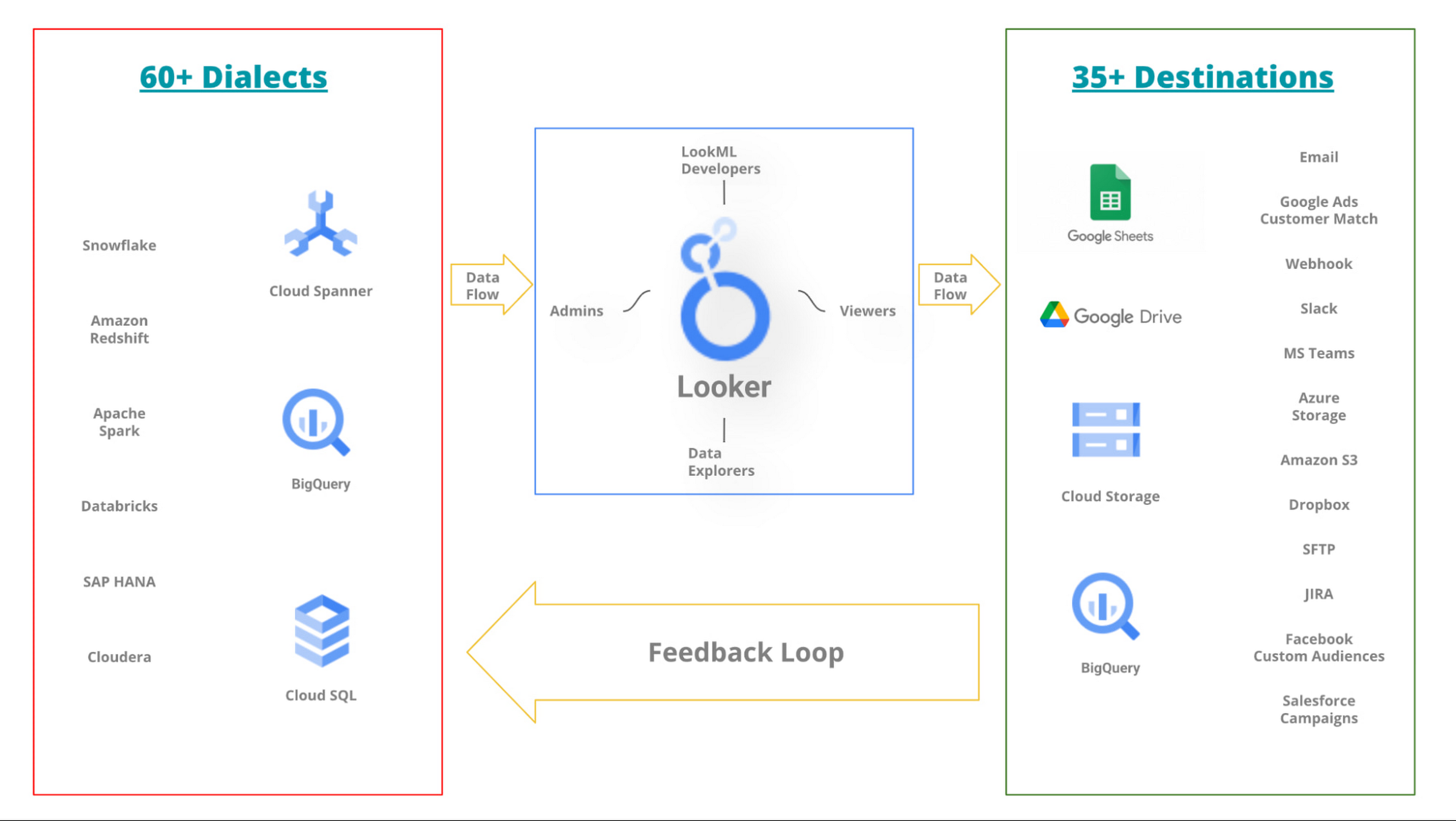
Nevertheless, a common goal across all these teams is keeping services running and downstream customers happy. In other words, the organization might be divided internally, however, they all have the mission to leverage the data to make better business decisions. Hence, despite silos and different subgoals, destiny for all these teams is intertwined for the organization to thrive. To support such a diverse set of data sources and the teams supporting them, Looker supports over 60 dialects (input from a data source) and over 35 destinations (output to a new data source).
Below is a simplified* picture of how the Looker ecosystem is central to a data-rich organization.
Simplified* Looker ecosystem in a data-rich environment
*The picture hides the complexity of team(s) accountable for each data source. It also hides how a data source may have dependencies on other sources. Looker Marketplace can also play an important role in your ecosystem.
What role can DevOps and SRE practices play?
In the most ideal state, all these teams will be in harmony as a single-threaded organization with all the internal processes so smooth that everyone is empowered to experiment (i.e. fail, learn, iterate and repeat all the time). With increasing organizational complexities, it is incredibly challenging to achieve such a state because there will be overhead and misaligned priorities. This is where we look up to the guiding principles of DevOps and SRE practices. In case you are not familiar with Google SRE practices, here is a starting point. The core of DevOps and SRE practices are mature communication and collaboration practices.
Let’s focus on the best practices which could help us with our Looker ecosystem.
Have joint goals. There should be some goals which are a shared responsibility across two or more teams. This helps establish a culture of psychological safety and transparency across teams.
Visualize how the data flows across the organization. This enables an understanding how each team plays their role and how to work with them better.
Agree on theGolden Signals (aka core metrics). These could mean data freshness, data accuracy, latency on centralized dashboards etc. These signals allow teams to set their error budgets and SLIs.
Agree on communication and collaboration methods that work across teams.
Focus on artifacts such as jointly owned documentations pages, shared roadmap items, reusable tooling, etc. For example, System Activity Dashboards could be made available to all the relevant stakeholders and supplemented with notes tailored to your organization.
Set up regular forums where commonly discussed agenda items include major changes, expected downtime and postmortems around the core metrics. Among other agenda items, you could define/refine a common set of standards, for example centrally defined labels, group_labels, descriptions, etc. in the LookML to ensure there is a single terminology across the board.
Promote informal sharing opportunities such as lessons learned, TGIFs, Brown bag sessions, and shadowing opportunities. Learning and teaching have an immense impact on how teams evolve. Teams often become closer with side projects that are slightly outside of their usual day-to-day duties.
Have mutually agreed upon change management practices. Each team has dependencies so making changes may have an impact on other teams. Why not plan those changes systematically? For example, getting common standards across the Advance deploy mode.
Promote continuous improvements. Keep looking for better, faster, cost-optimized versions of something important to the teams.
Revisit your data flow. After every major reorganization, ensure that organizational change has not broken the established mechanisms.
despite silos and different subgoals, destiny for all these teams is intertwined for the organization to thrive.
Are you over-engineering?
There is a possibility that in the process of maturing the ecosystem, we may end up in an overly engineered system – we may unintentionally add toil to the environment. These are examples of toil that often stem from communication gaps.
Meetings with no outcomes/action plans – This one is among the most common forms of toil, where the original intention of a meeting is no longer valid but the forum has not taken efforts to revisit their decision.
Unnecessary approvals – Being a single threaded team can often create unnecessary dependencies and your teams may lose the ability to make changes.
Unaligned maintenance windows – Changes across multiple teams may not be mutually exclusive hence if there is misalignment then it may create unforeseen impacts on the end user.
Fancy, but unnecessary tooling – Side projects, if not governed, may create unnecessary tooling which is not being used by the business. Collaborations are great when they solve real business problems, hence it is also required to refocus if the priorities are set right.
Gray areas – When you have a shared responsibility model, you also may end up in gray areas which are often gaps with no owner. This can lead to increased complexity in the long run. For example, having the flexibility to schedule content delivery still requires collaboration to reduce jobs with failures because it can impact the performance of your Looker instance.
Contradicting metrics – You may want to pay special attention to how teams are rewarded for internal metrics. For example, if a team focuses on accuracy of data and other one on freshness then at scale they may not align with one another.
Conclusion
To summarize, we learned how data is handled in large organizations with Looker at its heart unifying a universal semantic model. To handle large amounts of diverse data, teams need to start with aligned goals and commit to strong collaboration. We also learned how DevOps and SRE practices can guide us navigate through these complexities. Lastly, we looked at some side effects of excessively structured systems. To go forward from here, it is highly recommended to start with an analysis of how data flows under your scope and how mature the collaboration is across multiple teams.
Pub/Sub’s ingestion of data into BigQuery can be critical to making your latest business data immediately available for analysis. Until today, you had to create intermediate Dataflow jobs before your data could be ingested into BigQuery with the proper schema. While Dataflow pipelines (including ones built with Dataflow Templates) get the job done well, sometimes they can be more than what is needed for use cases that simply require raw data with no transformation to be exported to BigQuery.
Starting today, you no longer have to write or run your own pipelines for data ingestion from Pub/Sub into BigQuery. We are introducing a new type of Pub/Sub subscription called a “BigQuery subscription” that writes directly from Cloud Pub/Sub to BigQuery. This new extract, load, and transform (ELT) path will be able to simplify your event-driven architecture. For Pub/Sub messages where advanced preload transformations or data processing before landing data in BigQuery (such as masking PII) is necessary, we still recommend going through Dataflow.
Get started by creating a new BigQuery subscription that is associated with a Pub/Sub topic. You will need to designate an existing BigQuery table for this subscription. Note that the table schema must adhere to certain compatibility requirements. By taking advantage of Pub/Sub topic schemas, you have the option of writing Pub/Sub messages to BigQuery tables with compatible schemas. If schema is not enabled for your topic, messages will be written to BigQuery as bytes or strings. After the creation of the BigQuery subscription, messages will now be directly ingested into BigQuery.
Better yet, you no longer need to pay for data ingestion into BigQuery when using this new direct method. You only pay for the Pub/Sub you use. Ingestion from Pub/Sub’s BigQuery subscription into BigQuery costs $50/TiB based on read (subscribe throughput) from the subscription. This is a simpler and cheaper billing experience compared to the alternative path via Dataflow pipeline where you would be paying for the Pub/Sub read, Dataflow job, and BigQuery data ingestion. See the pricing page for details.
To get started, you can read more about Pub/Sub’s BigQuery subscription or simply create a new BigQuery subscription for a topic using Cloud Console or the gcloud CLI.
R is one of the most widely used programming languages for statistical computing and machine learning. Many data scientists love it, especially for the rich world of packages from tidyverse, an opinionated collection of R packages for data science. Besides the tidyverse, there are over 18,000 open-source packages on CRAN, the package repository for R. RStudio, available as desktop version or on theGoogle Cloud Marketplace, is a popular Integrated Development Environment (IDE) used by data professionals for visualization and machine learning model development.
Once a model has been built successfully, a recurring question among data scientists is: “How do I deploy models written in the R language to production in a scalable, reliable and low-maintenance way?”
In this blog post, you will walk through how to use Google Vertex AI to train and deploy enterprise-grade machine learning models built with R.
Overview
Managing machine learning models on Vertex AI can be done in a variety of ways, including using the User Interface of the Google Cloud Console, API calls, or the Vertex AI SDK for Python.
Since many R users prefer to interact with Vertex AI from RStudio programmatically, you will interact with Vertex AI through the Vertex AI SDK via the reticulate package.
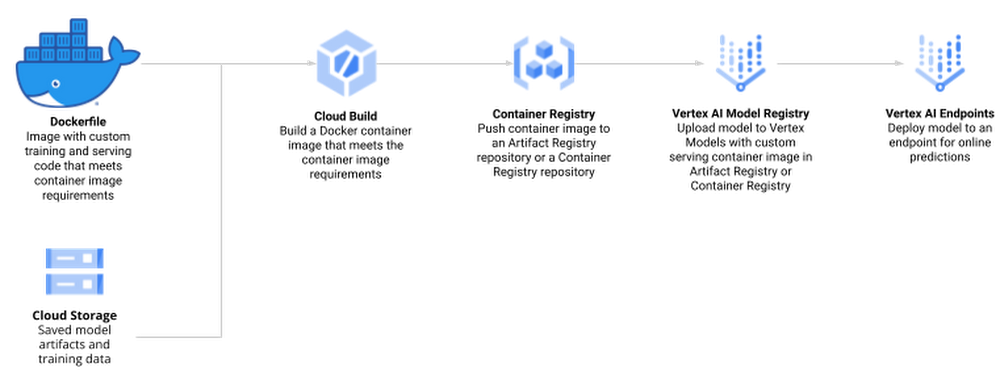
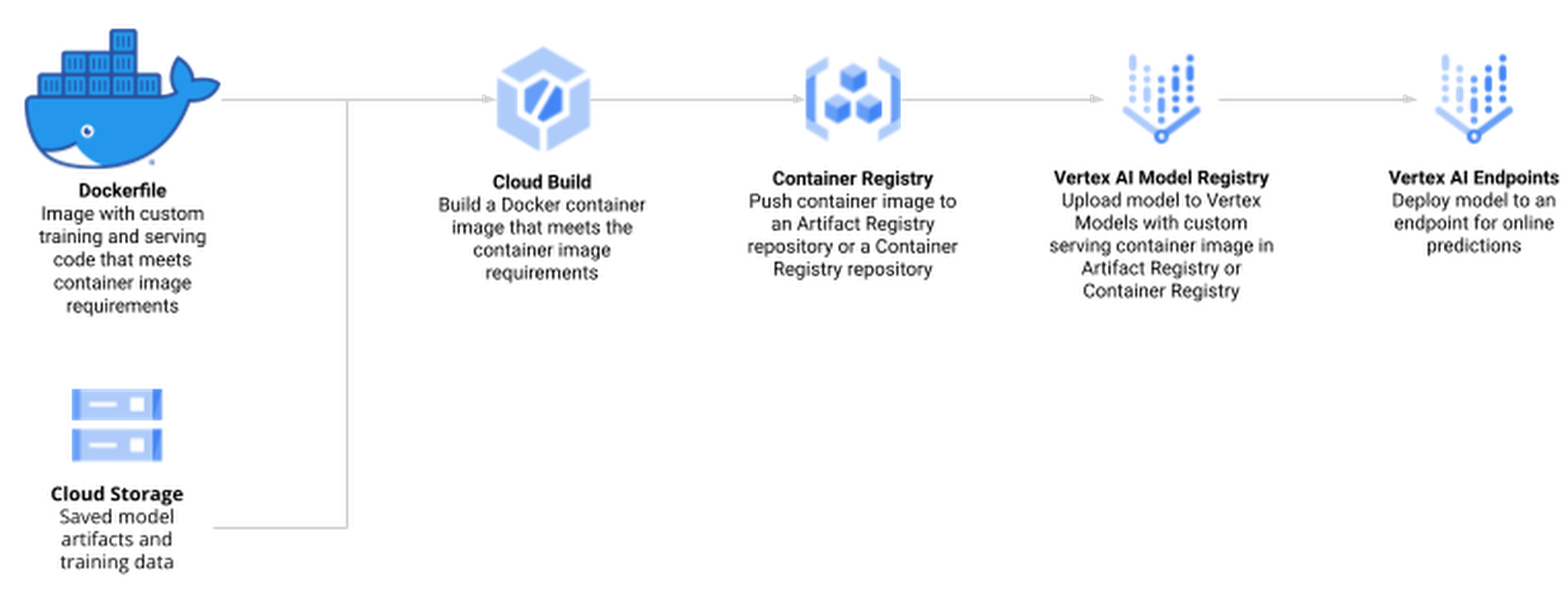
Train a model locally and import it as a custom model into Vertex AI Model Registry, from where it can be deployed to an endpoint for serving predictions.
Create a TrainingPipeline that runs a CustomJob and imports the resulting artifacts as a Model.
In this blog post, you will use the second method and train a model directly in Vertex AI since this allows us to automate the model creation process at a later stage while also supporting distributed hyperparameter optimization.
The process of creating and managing R models in Vertex AI comprises the following steps:
Enable Google Cloud Platform (GCP) APIs and set up the local environment
Create custom R scripts for training and serving
Create a Docker container that supports training and serving R models with Cloud Build and Container Registry
Train a model using Vertex AI Training and upload the artifact to Google Cloud Storage
Create a model endpoint on Vertex AI Prediction Endpoint and deploy the model to serve online prediction requests
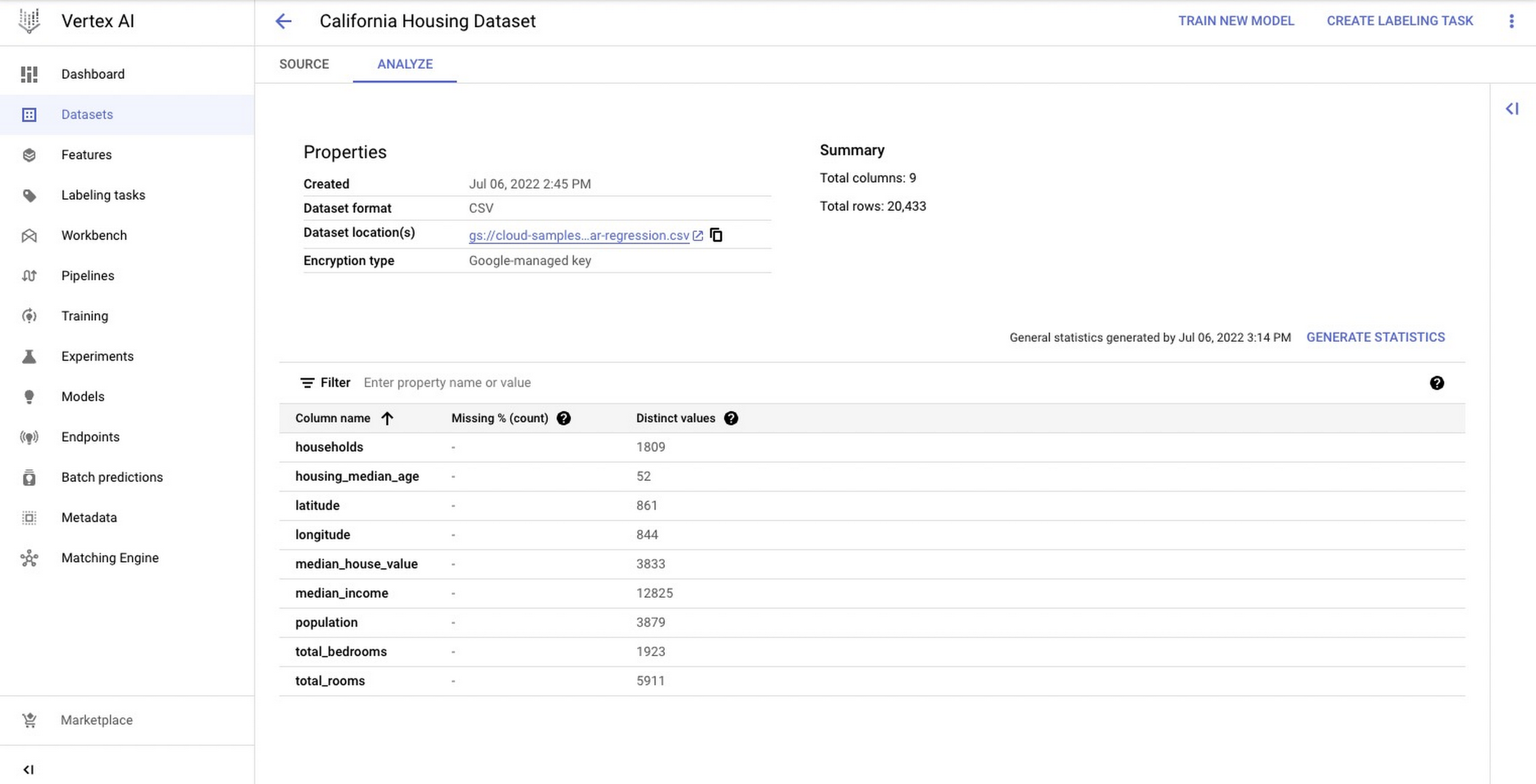
To showcase this process, you train a simple Random Forest model to predict housing prices on the California housing data set. The data contains information from the 1990 California census. The data set is publicly available from Google Cloud Storage at gs://cloud-samples-data/ai-platform-unified/datasets/tabular/california-housing-tabular-regression.csv
The Random Forest regressor model will predict a median housing price, given a longitude and latitude along with data from the corresponding census block group. A block group is the smallest geographical unit for which the U.S. Census Bureau publishes sample data (a block group typically has a population of 600 to 3,000 people).
Environment Setup
This blog post assumes that you are either using Vertex AI Workbench with an R kernel or RStudio. Your environment should include the following requirements:
The Google Cloud SDK
Git
R
Python 3
Virtualenv
To execute shell commands, define a helper function:
Next, you define variables to support the training and deployment process, namely:
PROJECT_ID: Your Google Cloud Platform Project ID
REGION: Currently, the regions us-central1, europe-west4, and asia-east1 are supported for Vertex AI; it is recommended that you choose the region closest to you
BUCKET_URI: The staging bucket where all the data associated with your dataset and model resources are stored
DOCKER_REPO: The Docker repository name to store container artifacts
IMAGE_NAME: The name of the container image
IMAGE_TAG: The image tag that Vertex AI will use
IMAGE_URI: The complete URI of the container image
When you initialize the Vertex AI SDK for Python, you specify a Cloud Storage staging bucket. The staging bucket is where all the data associated with your dataset and model resources are retained across sessions.
Create Docker container image for training and serving R models
The docker file for your custom container is built on top of the Deep Learning container — the same container that is also used for Vertex AI Workbench. In addition, you add two R scripts for model training and serving, respectively.
Before creating such a container, you enable Artifact Registry and configure Docker to authenticate requests to it in your region.
code_block[StructValue([(u’code’, u’# filename: Dockerfile – container specifications for using R in Vertex AIrnFROM gcr.io/deeplearning-platform-release/r-cpu.4-1:latestrnrnWORKDIR /rootrnrnCOPY train.R /root/train.RrnCOPY serve.R /root/serve.Rrnrn# Install FortranrnRUN apt-get updaternRUN apt-get install gfortran -yyrnrn# Install R packagesrnRUN Rscript -e “install.packages(‘plumber’)”rnRUN Rscript -e “install.packages(‘randomForest’)”rnrnEXPOSE 8080′), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ead93a41450>)])]
Next, create the file train.R, which is used to train your R model. The script trains a randomForest model on the California Housing dataset. Vertex AI sets environment variables that you can utilize, and since this script uses a Vertex AI managed dataset, data splits are performed by Vertex AI and the script receives environment variables pointing to the training, test, and validation sets. The trained model artifacts are then stored in your Cloud Storage bucket.
code_block[StructValue([(u’code’, u’#!/usr/bin/env Rscriptrn# filename: train.R – train a Random Forest model on Vertex AI Managed Datasetrnlibrary(tidyverse)rnlibrary(data.table)rnlibrary(randomForest)rnSys.getenv()rnrn# The GCP Project IDrnproject_id <- Sys.getenv(“CLOUD_ML_PROJECT_ID”)rnrn# The GCP Regionrnlocation <- Sys.getenv(“CLOUD_ML_REGION”)rnrn# The Cloud Storage URI to upload the trained model artifact tornmodel_dir <- Sys.getenv(“AIP_MODEL_DIR”)rnrn# Next, you create directories to download our training, validation, and test set into.rndir.create(“training”)rndir.create(“validation”)rndir.create(“test”)rnrn# You download the Vertex AI managed data sets into the container environment locally.rnsystem2(“gsutil”, c(“cp”, Sys.getenv(“AIP_TRAINING_DATA_URI”), “training/”))rnsystem2(“gsutil”, c(“cp”, Sys.getenv(“AIP_VALIDATION_DATA_URI”), “validation/”))rnsystem2(“gsutil”, c(“cp”, Sys.getenv(“AIP_TEST_DATA_URI”), “test/”))rnrn# For each data set, you may receive one or more CSV files that you will read into data frames.rntraining_df <- list.files(“training”, full.names = TRUE) %>% map_df(~fread(.))rnvalidation_df <- list.files(“validation”, full.names = TRUE) %>% map_df(~fread(.))rntest_df <- list.files(“test”, full.names = TRUE) %>% map_df(~fread(.))rnrnprint(“Starting Model Training”)rnrf <- randomForest(median_house_value ~ ., data=training_df, ntree=100)rnrfrnrnsaveRDS(rf, “rf.rds”)rnsystem2(“gsutil”, c(“cp”, “rf.rds”, model_dir))’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ead920dc110>)])]
Next, create the file serve.R, which is used for serving your R model. The script downloads the model artifact from Cloud Storage, loads the model artifacts, and listens for prediction requests on port 8080. You have several environment variables for the prediction service at your disposal, including:
AIP_HEALTH_ROUTE: HTTP path on the container that AI Platform Prediction sends health checks to.
Next, you build the Docker container image on Cloud Build — the serverless CI/CD platform. Building the Docker container image may take 10 to 15 minutes.
You create a Vertex AI Managed Dataset to have Vertex AI take care of the data set split. This is optional, and alternatively you may want to pass the URI to the data set via environment variables.
The next screenshot shows the newly created Vertex AI Managed dataset in Cloud Console.
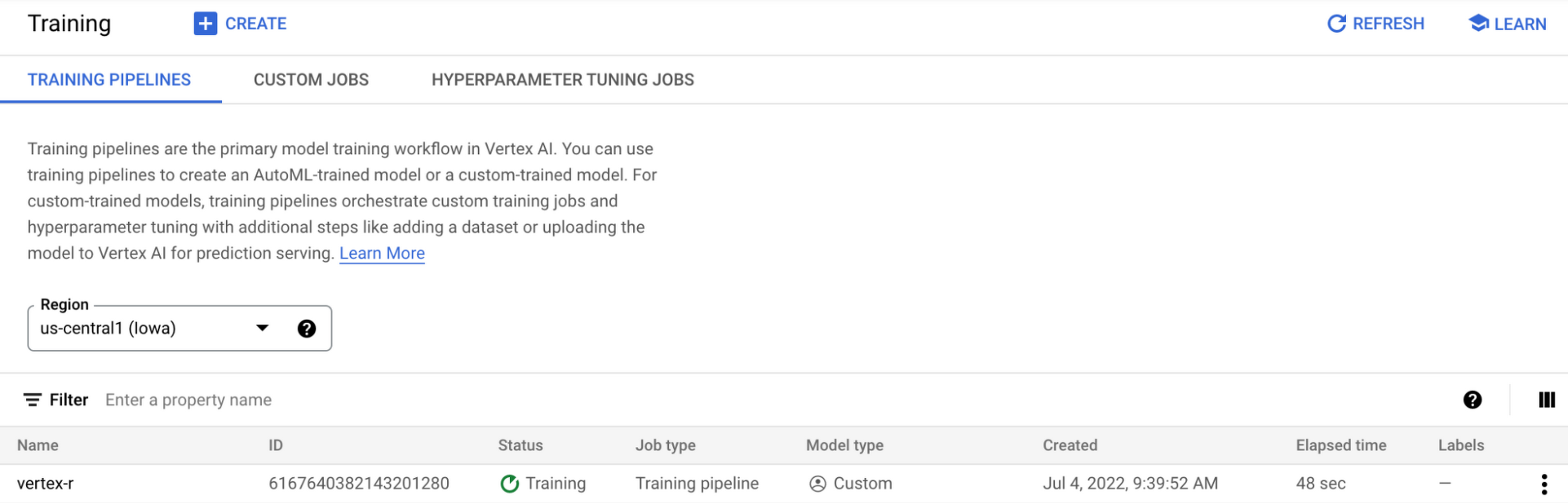
Train R Model on Vertex AI
The custom training job wraps the training process by creating an instance of your container image and executing train.R for model training and serve.R for model serving.
Note: You use the same custom container for both training and serving.
To train the model, you call the method run(), with a machine type that is sufficient in resources to train a machine learning model on your dataset. For this tutorial, you use a n1-standard-4 VM instance.
The model is now being trained, and you can watch the progress in the Vertex AI Console.
Provision an Endpoint resource and deploy a Model
You create an Endpoint resource using the Endpoint.create() method. At a minimum, you specify the display name for the endpoint. Optionally, you can specify the project and location (region); otherwise the settings are inherited by the values you set when you initialized the Vertex AI SDK with the init() method.
In this example, the following parameters are specified:
display_name: A human readable name for the Endpoint resource.
project: Your project ID.
location: Your region.
labels: (optional) User defined metadata for the Endpoint in the form of key/value pairs.
You can deploy one of more Vertex AI Model resource instances to the same endpoint. Each Vertex AI Model resource that is deployed will have its own deployment container for the serving binary.
Next, you deploy the Vertex AI Model resource to a Vertex AI Endpoint resource. The Vertex AI Model resource already has defined for it the deployment container image. To deploy, you specify the following additional configuration settings:
The machine type.
The (if any) type and number of GPUs.
Static, manual or auto-scaling of VM instances.
In this example, you deploy the model with the minimal amount of specified parameters, as follows:
model: The Model resource.
deployed_model_displayed_name: The human readable name for the deployed model instance.
machine_type: The machine type for each VM instance.
Due to the requirements to provision the resource, this may take up to a few minutes.
Note: For this example, you specified the R deployment container in the previous step of uploading the model artifacts to a Vertex AI Model resource.
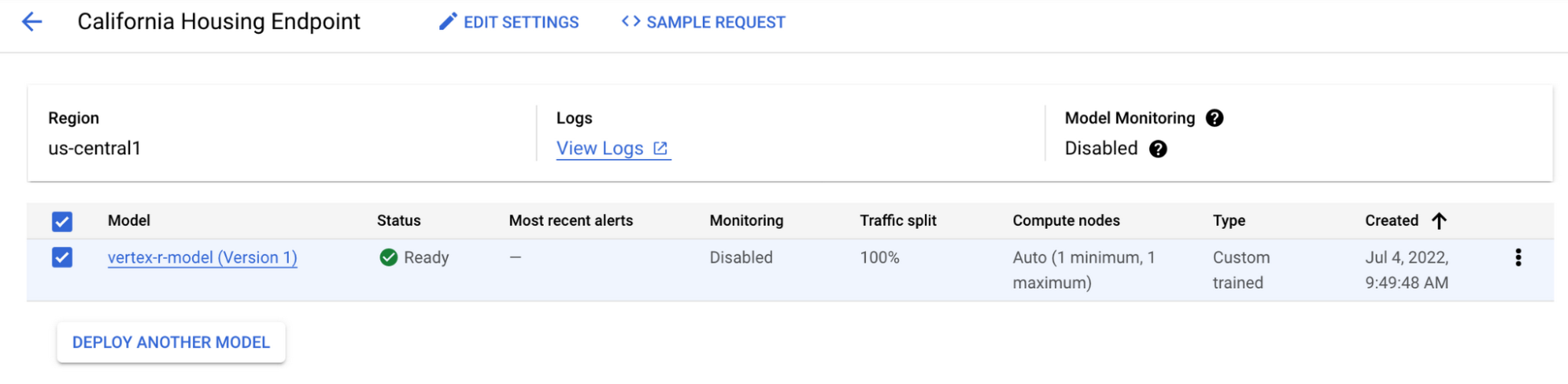
The model is now being deployed to the endpoint, and you can see the result in the Vertex AI Console.
Make predictions using newly created Endpoint
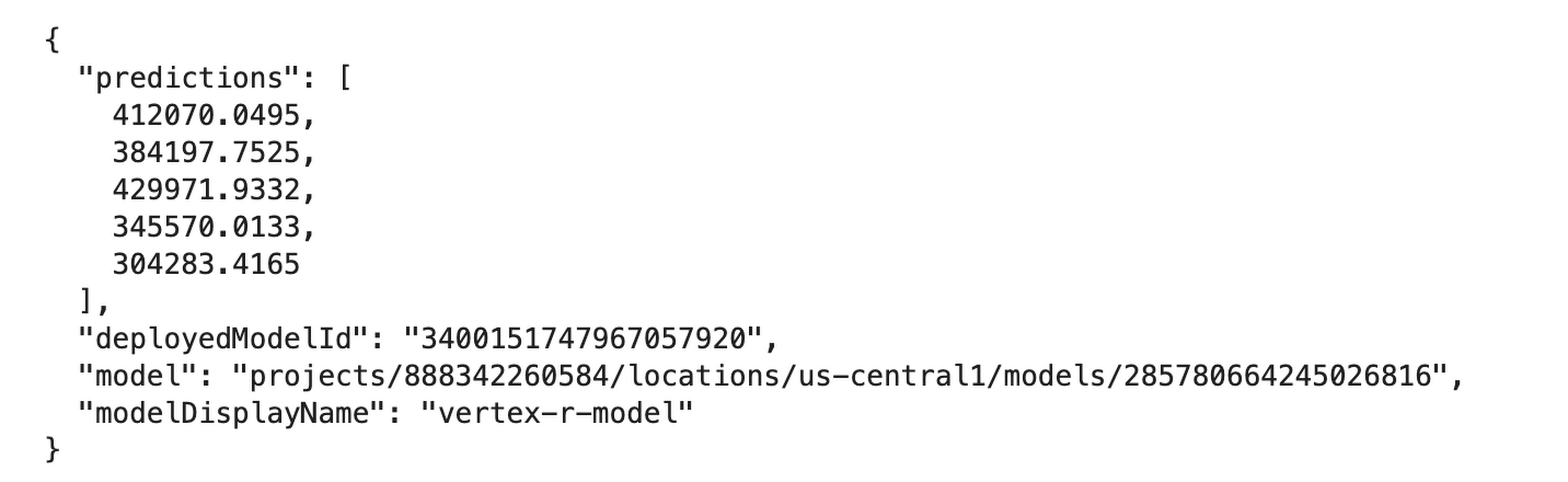
Finally, you create some example data to test making a prediction request to your deployed model. You use five JSON-encoded example data points (without the label median_house_value) from the original data file in data_uri. Finally, you make a prediction request with your example data. In this example, you use the REST API (e.g., Curl) to make the prediction request.
The endpoint now returns five predictions in the same order the examples were sent.
Cleanup
To clean up all Google Cloud resources used in this project, you can delete the Google Cloud project you used for the tutorial or delete the created resources.
code_block[StructValue([(u’code’, u’endpoint$undeploy_all()rnendpoint$delete()rndataset$delete()rnmodel$delete()rnjob$delete()’), (u’language’, u”), (u’caption’, <wagtail.wagtailcore.rich_text.RichText object at 0x3ead93078150>)])]
Summary
In this blog post, you have gone through the necessary steps to train and deploy an R model to Vertex AI. For easier reproducibility, you can refer to this Notebook on GitHub
Acknowledgements
This blog post received contributions from various people. In particular, we would like to thank Rajesh Thallam for strategic and technical oversight, Andrew Ferlitsch for technical guidance, explanations, and code reviews, and Yuriy Babenko for reviews.
Running time-based, scheduled workflows to implement business processes is regular practice at many financial services companies. This is true for Deutsche Bank, where the execution of workflows is fundamental for many applications across its various business divisions, including the Private Bank, Investment and Corporate Bank as well as internal functions like Risk, Finance and Treasury. These workflows often execute scripts on relational databases, run application code in various languages (for example Java), and move data between different storage systems. The bank also uses big data technologies to gain insights from large amounts of data, where Extract, Transform and Load (ETL) workflows running on Hive, Impala and Spark play a key role.
Historically, Deutsche Bank used both third-party workflow orchestration products and open-source tools to orchestrate these workflows. But using multiple tools increases complexity and introduces operational overhead for managing underlying infrastructure and workflow tools themselves.
Cloud Composer, on the other hand, is a fully managed offering that allows customers to orchestrate all these workflows with a single product. Deutsche Bank recently began introducing Cloud Composer into its application landscape, and continues to use it in more and more parts of the business.
“Cloud Composer is our strategic workload automation (WLA) tool. It enables us to further drive an engineering culture and represents an intentional move away from the operations-heavy focus that is commonplace in traditional banks with traditional technology solutions. The result is engineering for all production scenarios up front, which reduces risk for our platforms that can suffer from reactionary manual interventions in their flows. Cloud Composer is built on open-source Apache Airflow, which brings with it the promise of portability for a hybrid multi-cloud future, a consistent engineering experience for both on-prem and cloud-based applications, and a reduced cost basis.
We have enjoyed a great relationship with the Google team that has resulted in the successful migration of many of our scheduled applications onto Google Cloud using Cloud Composer in production.” -Richard Manthorpe, Director Workload Automation, Deutsche Bank
Why use Cloud Composer in financial services
Financial services companies want to focus on implementing their business processes, not on managing infrastructure and orchestration tools. In addition to consolidating multiple workflow orchestration technologies into one and thus reducing complexity, there are a number of other reasons companies choose Cloud Composer as a strategic workflow orchestration product.
First of all, Cloud Composer is significantly more cost-effective than traditional workflow management and orchestration solutions. As a managed service, Google takes care of all environment configuration and maintenance activities. Cloud Composer version 2 introduces autoscaling, which allows for an optimized resource utilization and improved cost control, since customers only pay for the resources used by their workflows. And because Cloud Composer is based on open source Apache Airflow, there are no license fees; customers only pay for the environment that it runs on, adjusting the usage to current business needs.
Highly regulated industries like financial services must comply with domain-specific security and governance tools and policies. For example, Customer-Managed Encryption Keys ensure that data won’t be accessed without the organization’s consent, while Virtual Private Network Service Controls mitigate the risk of data exfiltration. Cloud Composer supports these and many other security and governance controls out-of-the box, making it easy for customers in regulated industries to use the service without having to implement these policies on their own.
The ability to orchestrate both native Google Cloud as well as on-prem workflows is another reason that Deutsche Bank chose Cloud Composer. Cloud Composer uses Airflow Operators (connectors for interacting with outside systems) to integrate with Google Cloud services like BigQuery, Dataproc, Dataflow, Cloud Functions and others, as well as hybrid and multi-cloud workflows. Airflow Operators also integrate with Oracle databases, on-prem VMs, sFTP file servers and many others, provided by Airflow’s strong open-source community.
And while Cloud Composer lets customers consolidate multiple workflow orchestration tools into one, there are some use cases where it’s just not the right fit. For example, if customers have just a single job that executes once a day on a fixed schedule, Cloud Scheduler, Google Cloud’s managed service for Cron jobs, might be a better fit. Cloud Composer in turn excels for more advanced workflow orchestration scenarios.
Finally, technologies based on open source technologies also provide a simple exit strategy from cloud — an important regulatory requirement for financial services companies. With Cloud Composer, customers can simply move their Airflow workflows from Cloud Composer to a self-managed Airflow cluster. Because Cloud Composer is fully compatible with Apache Airflow, the workflow definitions stay exactly the same if they are moved to a different Airflow cluster.
Cloud Composer applied
Having looked at why Deutsche Bank chose Cloud Composer, let’s dive into how the bank is actually using it today. Apache Airflow is well-suited for ETL and data engineering workflows thanks to the rich set of data Operators (connectors) it provides. So Deutsche Bank, where a large-scale data lake is already in place on-prem, leverages Cloud Composer for its modern Cloud Data Platform, whose main aim is to work as an exchange for well-governed data, and enable a “data mesh” pattern.
At Deutsche Bank, Cloud Composer orchestrates the ingestion of data to the Cloud Data Platform, which is primarily based on BigQuery. The ingestion happens in an event-driven manner, i.e., Cloud Composer does not simply run load jobs based on a time-schedule; instead it reacts to events when new data such as Cloud Storage objects arrives from upstream sources. It does so using so-called Airflow Sensors, which continuously watch for new data. Besides loading data into BigQuery, Composer also schedules ETL workflows, which transform data to derive insights for business reporting.
Due to the rich set of Airflow Operators, Cloud Composer can also orchestrate workflows that are part of standard, multi-tier business applications running non-data-engineering workflows. One of the use cases includes a swap reporting platform that provides information about various asset classes, including commodities, credits, equities, rates and Forex. In this application, Cloud Composer orchestrates various services implementing the business logic of the application and deployed on Cloud Run — again, using out-of-the-box Airflow Operators.
These use cases are already running in production and delivering value to Deutsche Bank. Here is how their Cloud Data Platform team sees the adoption of Cloud Composer:
“Using Cloud Composer allows our Data Platform team to focus on creating Data Engineering and ETL workflows instead of on managing the underlying infrastructure. Since Cloud Composer runs Apache Airflow, we can leverage out of the box connectors to systems like BigQuery, Dataflow, Dataproc and others, making it well-embedded into the entire Google Cloud ecosystem.”—Balaji Maragalla, Director Big Data Platforms, Deutsche Bank








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}