
Building the most open data cloud ecosystem: Unifying data across multiple sources and platforms
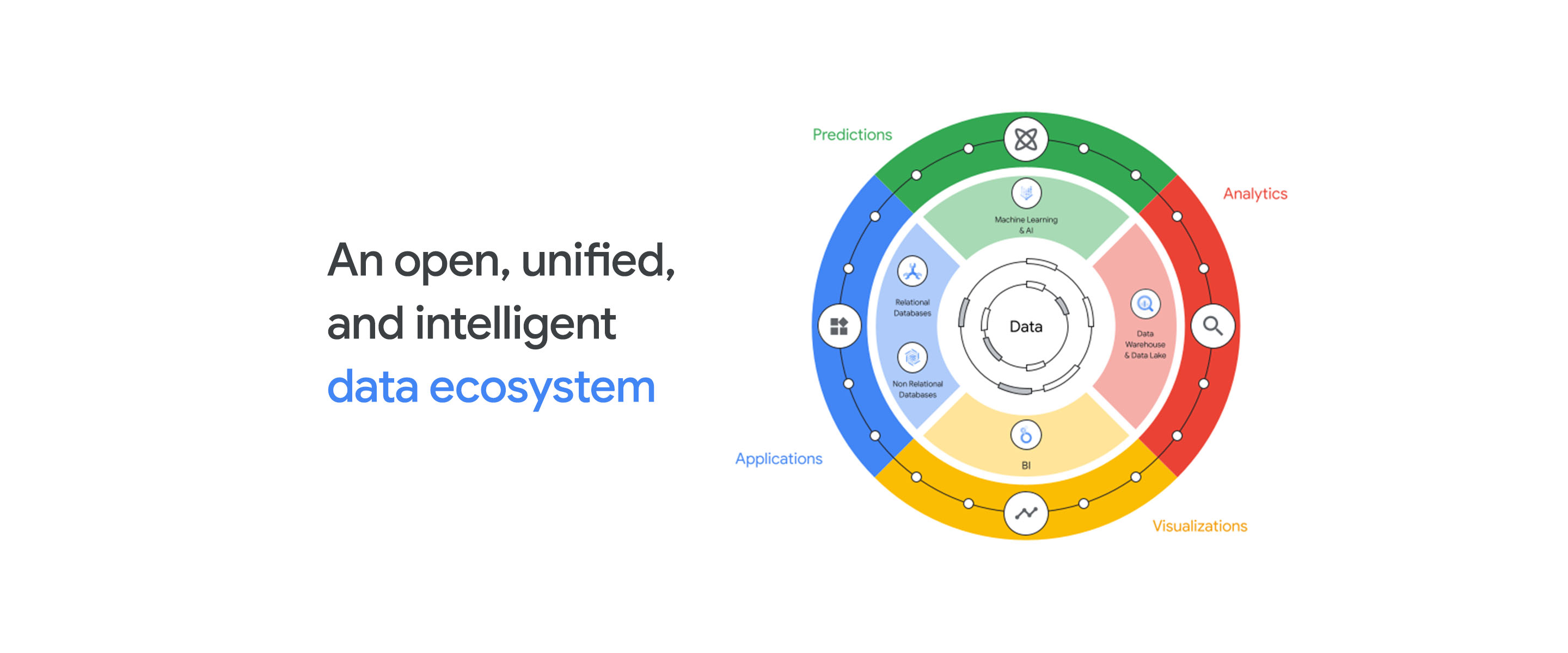
Data is the most valuable asset in any digital transformation. Yet limits on data are still too common, and prevent organizations from taking important steps forward — like launching a new digital business, understanding changes in consumer behavior, or even utilizing data to combat public health crises. Data complexity is at an all time high and as data volumes grow, data is becoming distributed across clouds, used in more workloads and accessed by more people than ever before. Only an open data cloud ecosystem can unlock the full potential of data and remove the barriers to digital transformation.
Already, more than 800 software companies are building their products using Google’s Data Cloud, and more than 40 data platform partners offer validated integrations through our Google Cloud Ready – BigQuery initiative. Earlier this year we launched the Data Cloud Alliance, now supported by 17 leaders in data working together to promote open standards and interoperability between popular data applications.
This week at Next, we’re announcing significant steps to our mission to provide the most open and extensible Data Cloud — that helps ensure customers can utilize all their data, from all sources, in all storage formats and styles of analysis, across all cloud providers and platforms of their choice. These include:
Launching a new capability to analyze unstructured and streaming data in BigQuery.
Adding support for major data formats in the industry, including Apache Iceberg, and the upcoming support for Linux Foundation Delta Lake, Apache Hudi.
A new integrated experience in BigQuery for Apache Spark.
Expanding the capabilities of Dataplex for automated data quality and data lineage to help ensure customers have greater confidence in their data.
Unifying our business intelligence portfolio under the Looker umbrella to begin creating a deep integration of Looker, Data Studio, and core Google technologies like AI and machine learning (ML).
Launching Vertex AI Vision, a new service that can make powerful computer vision and image recognition AI more accessible to data practitioners.
Expanding our integrations with many of the most popular enterprise data platforms, including Collibra, Elastic, MongoDB, Palantir Foundry, and ServiceNow to help remove barriers between data and give customers more choice and prevent data lock-in.
You can read more about each of these exciting updates below.
Unifying data, across source systems, with major formats
We believe that a data cloud should allow people to work with all kinds of data, no matter its storage format or location. To do this, we’re adding several exciting new capabilities to Google’s Data Cloud.
First, we’re adding support for unstructured data in BigQuery to help significantly expand the ability for people to work with all types of data. Most commonly, data teams have worked with structured data, using BigQuery to analyze data from operational databases and SaaS applications like Adobe, SAP, ServiceNow, and Workday as well as semi-structured data such as JSON log files.
But this represents a small portion of an organization’s information. Unstructured data may account for up to 90 percent of all data today, like video from television archives, audio from call centers and radio, and documents of many formats. Beginning now, data teams can manage, secure, and analyze structured and unstructured data in BigQuery, with easy access to many of Google Cloud’s capabilities in ML, speech recognition, computer vision, translation, and text processing, using BigQuery’s familiar SQL interface.
Second, we’re adding support for major data formats in use today.Our storage engine, BigLake, adds support for Apache Iceberg and support for Linux Foundation Delta Lake, and Apache Hudi will be added soon. By supporting these widely adopted data formats, we can help organizations gain the full value from their data faster.
“Google Cloud’s support for Delta is a testament to the demand for an open, multicloud lakehouse that gives customers the flexibility to leverage all of their data, regardless of where it resides,” said David Meyer, senior vice president of products at Databricks. “This partnership further exemplifies our joint commitment to open data sharing and the advancement of open standards like Delta Lake that make data more accessible, portable, and collaborative across teams and organizations.”
Third, we’re announcing a new integrated experience in BigQuery for Apache Spark, a leading open-source analytics engine for large-scale data processing. This new Spark integration, launching in preview today, allows data practitioners to create procedures in BigQuery, using Apache Spark, that integrate with their SQL pipelines. Organizations like Walmart use Google Cloud to improve Spark processing times by 23% and have reduced time to close financial books from five days to three.
In addition, we’ve launched Datastream for BigQuery which will help organizations more effectively replicate data in real-time, from sources including AlloyDB, PostgreSQL, MySQL and third-party databases like Oracle — directly into BigQuery. By helping to accelerate the ability to bring data from an array of sources into BigQuery, we enable you to get more insights from your data in real time. To learn more about these announcements read our dedicated post about key innovations with Google Databases.
Finally, a data cloud should enable organizations to manage, secure, and observe their data, which helps ensure their data is high quality and enable strong, flexible data management, and governance capabilities. To address data management, we’re announcing updates to Dataplex that will automate common processes associated with data quality. For instance, users will now be able to easily understand data lineage — where data originates and how it has transformed and moved over time — which can reduce the need for manual, time consuming processes.
The ability to let our customers work with all kinds of data, in the formats they choose, is the hallmark of an open data cloud. We’re committed to delivering the support and integrations that customers need to remove limits from their data and avoid data lock-in across clouds.
Supporting all styles of analysis and empowering analysts with AI
More than 10 million users access Google Cloud’s business intelligence solutions each month, including Looker and Google Data Studio. Now, we’re unifying these two popular tools under the Looker umbrella to start creating a deep integration of Looker, Data Studio, and core Google technologies like AI and ML. As part of that unification, Data Studio is now Looker Studio. This solution will help you go beyond dashboards and infuse your workflows and applications with the intelligence needed to help make data-driven decisions. To learn more about the next evolution of Looker and business intelligence, please read our dedicated post on Looker’s future.
We’re committed to enabling our customers to work with the business intelligence tools of their choice. We’ve already announced integrations between Looker and Tableau, and today we’re announcing enhancements for Looker and BigQuery with Microsoft Power BI — another significant step forward in providing customers with the most open data cloud. This means that Tableau and Microsoft customers can easily analyze trusted data from Looker and simply connect with BigQuery.
Increasingly, AI and ML are becoming important tools for modeling and managing data – particularly as organizations find ways to put these capabilities in the hands of users. Already, Vertex AI helps you get value from data more quickly by simplifying data access and ingestion, enabling model orchestration, and deploying ML models into production.
We are now releasing Vertex AI Vision to extend the capabilities of Vertex AI to be more accessible to data practitioners and developers. This new end-to-end application development environment helps you ingest, analyze, and store visual data: streaming video in manufacturing plants, for example, to help ensure safety, or streams from store shelves to improve inventory analysis, or following traffic lights for management of busy intersections. Vertex AI Vision allows you to easily build and deploy computer vision applications to understand and utilize this data.
Vertex AI Vision can reduce the time to create computer vision applications from weeks to hours at one-tenth the cost of current offerings. To help you achieve these efficiencies, Vertex AI Vision provides an easy-to-use, drag-and-drop interface and a library of pre-trained ML models for common tasks such as occupancy counting, product recognition, and object detection. It also provides the option to import your existing AutoML or custom ML models, from Vertex AI, into your Vertex AI Vision applications. As always, our new AI products also adhere to our AI Principles.
Plainsight, a leading provider of computer vision solutions, is using Google Cloud to increase speed and cost efficiency. “Vertex AI Vision is changing the game for use cases that for us were previously not viable at scale,” Elizabeth Spears, co-founder and chief product officer at Plainsight, said. “The ability to run computer vision models on streaming video with up to a 100-times cost reduction for Plainsight is creating entirely new business opportunities for our customers.”
Supporting an open data ecosystem
Giving customers flexibility to work across the data platforms of their choice is critical to prevent data lock-in. To keep Google’s data cloud open, we’re committed to partnering with major open data platforms, including companies like Collibra, Databricks, Elastic, Fivetran, MongoDB, Sisu Data, Reltio, Striim, and many others to ensure that help our joint customers can use these products with Google’s data cloud. We’re also working with the 17 members of the Data Cloud Alliance to promote open standards and interoperability in the data industry, and continuing our support for open-source database engines like MongoDB, MySQL, PostgreSQL, and Redis, in addition to Google Cloud databases like AlloyDB for PostgreSQL, Cloud Bigtable, Firestore, and Cloud Spanner.
At Next, we’re announcing important new updates and integrations with several of these partners, to help you more easily move data between the platforms of your choice and bring more of Google’s data cloud capabilities to partner platforms.
Collibra will integrate with Dataplex to help customers more easily discover data in business context, understand data lineage, and apply consistent controls on data stored across major clouds and on-premises environments.
Elasticis bringing its Elasticsearch capabilities to Google’s data cloud, giving customers the ability to federate their search queries to their data lakes on Google Cloud. This expands upon the existing integration already available to directly ingest data from BigQuery into Elastic for search use cases. We’re also extending Looker support to the Elastic platform, which can easily embed search insights into data-driven applications.
MongoDB is launching new templates to significantly help accelerate customers’ ability to move data between Atlas and BigQuery. This will also open up new use cases for customers to apply Google Cloud AI and ML capabilities to MongoDB using Vertex AI.
Palantir is certifying BigQuery as an engine for Foundry Ontology which connects underlying data models to business objects, predictive models, and actions which can enable customers to turn data into intelligent operations.
ServiceNow plans to work with mutual customers and build use case specific integrations with BigQuery to help customers aggregate diverse, external data with data residing in their ServiceNow instance. The integration will help customers create greater insights and value from data residing in the ServiceNow instance, like IT service management data, customer service records, or order management data and move data to BigQuery where the customers can use Google’s analytics capabilities to process and analyze data from these multiple sources.
Sisu Data will collaborate with Google Cloud’s business intelligence solutions to help automate finding root causes 80% faster than traditional approaches to provide augmented analytics for more customers.
Reltio’s integration with BigQuery can improve the customer experience by consolidating, cleansing, and enriching data in real-time with master data management capabilities, and then enable intelligent action with Vertex AI.
Striim’s managed service for BigQuery can reduce time to insight, allowing customers to replicate data from a variety of operational sources with automatic schema creation, coordinated initial load, and built-in parallel processing for sub-second latency. With faster insights can come faster decision-making across the organization.
Watchthe Google Cloud Next ‘22 broadcast or dive into our on-demand sessionsand learn more about how you can use these latest innovations to turn data into value.
Source : Data Analytics Read More





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
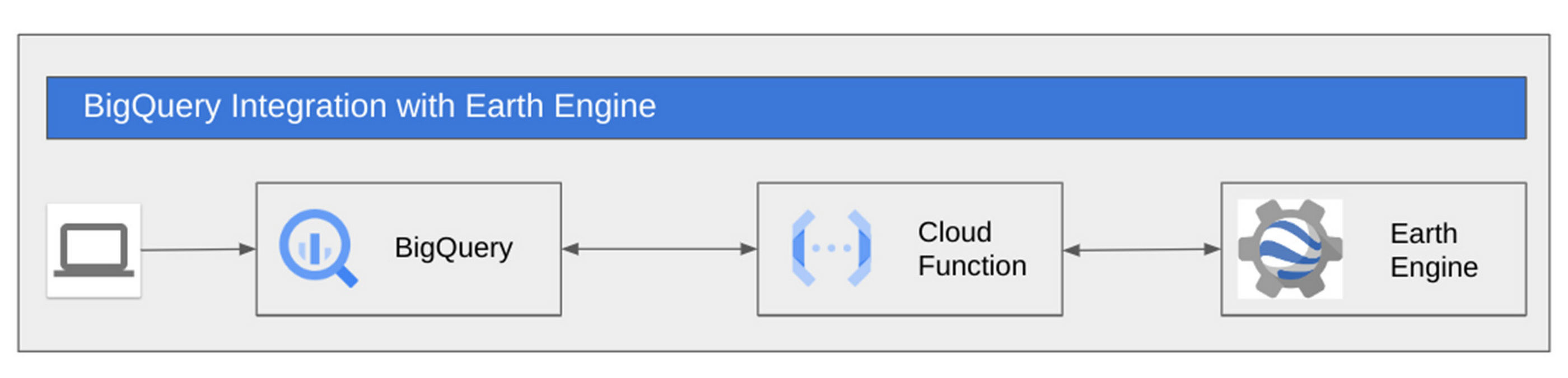{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}