Built with BigQuery: How Datalaksa provides a unified marketing and customer data warehouse for brands in South East Asia
Editor’s note: The post is part of a series highlighting our partners, and their solutions, that are Built with BigQuery.
Datalaksa is a unified marketing and customer data warehouse created by Persuasion Technologies, a Big Data Analytics & Digital Marketing consultancy serving clients throughout South East Asia. It enables marketing teams to optimize campaigns by combining data from across their marketing channels and enabling insight driven actions across marketing automation and delivery systems.
In this post, we explore how they have leveraged Google BigQuery and Google’s other data cloud products to build a solution that is rapid to set-up, highly flexible and able to scale with the needs of their customers.
Through close collaboration with their customers, Persuasion Technologies gained first hand experience of the challenges they face trying to optimize campaigns across multiple channels. “Marketing and CRM teams find it difficult to gain the insights that drive decisions across their marketing channels.” said Tzu Ming Chu, Director, Persuasion Technologies. “An ever-increasing variety of valuable data resides in siloed systems, while the teams that can integrate and analyze that data have never been more in demand. All too frequently this means that campaign planning is incomplete or too slow and campaign execution is less effective, ultimately resulting in lower sales and missed opportunities.”
Marketing teams of all sizes face similar challenges:
Access to technical skills and resources. Integrating data from the various sources requires skilled, and scarce, technical resources to scope out requirements, design solutions, build the pipelines that connect data sources, develop data models and ensure data quality. Machine learning (ML) requires data scientists to develop models to generate advanced insights, and ML Ops engineers to make sure those models are always updated and can be used for scoring at the needed scale.
Access to technology. While smaller companies may not have a data warehouse at all, even in large companies that do, gaining access to it and having resources allocated can be a long and difficult process, often with a lack of flexibility to accommodate local needs and with limitations to what can be provided.
Ease of use. Even a well architected data warehouse may see little usage if data or marketing teams can’t figure out how to deep dive into the data. Without an intuitive data model, an easy to use interface that enables business users to query, transform and visualize data and beverage AI models that automate insights and predict outcomes, the full benefits will not be realized.
Flexibility. Each marketing team is different – they each have their own set of requirements, data sources and use cases, and they continue to evolve and scale over time. Many of-the-shelf solutions lack the flexibility to accommodate the unique needs of each business.
In these challenges, the Persuasion Technologies team saw an opportunity — an opportunity to help their customers in a repeatable way, ensuring they all had easy access to rich data warehouse capabilities, and to enable them to create a new product-centric business and revenue stream.
Datalaksa, a unified marketing and customer data warehouse
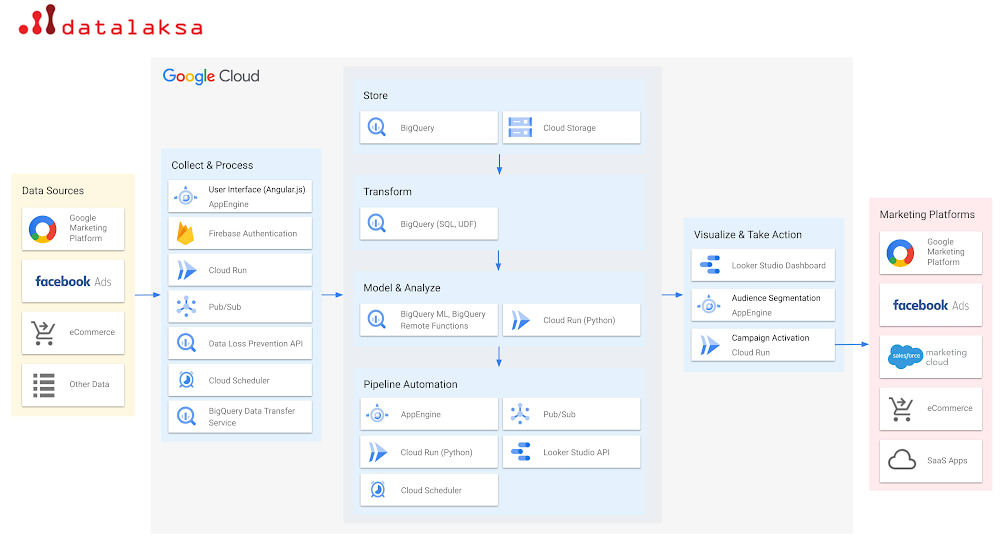
Datalaksa is a solution that enables marketing teams to easily, securely and scalably bring together marketing and customer data from multiple channels into a cloud data warehouse and enables them with advanced capabilities to derive actionable insights and take actions that increase campaign efficiency and effectiveness.
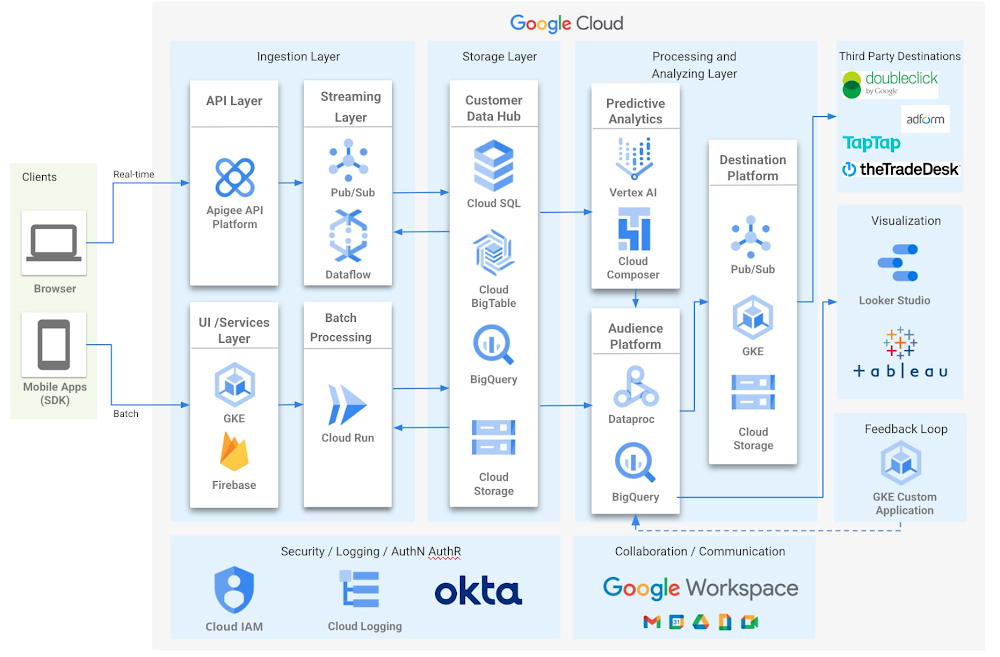
Out of the box, Datalaksa includes data connectors that enable data to be imported from a wide range of platforms such as Google Marketing Platform, Facebook Ads and eCommerce systems, which means that marketing teams can unify data from across channels quickly and easily without reliance on scarce and costly technical resources to build and maintain integrations.
To accelerate time-to-insight, Datalaksa provides pre-built data models, machine learning models and analytical templates for key marketing use cases such as cohort analyses, customer clustering, campaign recommendation and lifetime value models, all wrapped within an simple and intuitive user interface that enables marketing teams to easily query, transform, enrich and analyze their data – decreasing the time from data to value.
It’s often said that “insight without action is worthless” — to ensure this is not the case for Datalaksa users, the solution prompts action through notifications and enables audience segmentation tools and integrations back to marketing automation systems such as Salesforce Marketing Cloud, Google Ads and eCommerce systems.
For example, teams can set thresholds and conditions using SQL queries to send notification emails for ‘out of stock’ or `low stock’ to relevant teams and automatically update product recommendation algorithms to offer in-stock items. Through built-in connectors, customer audience segments can be activated by automatically updating ad buying audiences in platforms including Tik Tok, Google Ads, Linkedin and Facebook or Instagram. These can be scheduled and updated regularly.
All of this is built using Google’s BigQuery and data cloud suite of products.
Why Datalaksa chose Google Cloud and BigQuery
The decision to use Google Cloud and BigQuery for Datalaksa was an easy one according to Tzu, “Not only did it accelerate our ability to provide our customers with industry leading data warehousing and analytical capabilities, it’s incredibly easy to integrate with many key marketing systems, including those from Google. This equates directly to saved time and cost, not just during the initial design and build, but in the ongoing support and maintenance.”
Persuasion Technologies story is one of deep expertise, customer empathy and innovative thinking, but BigQuery and Google Cloud’s end to end platform for building data driven applications is also key part of their success:
World class analytics. By leveraging BigQuery as the core of Datalaksa, they were immediately able to provide their customers with a fully-managed, petabyte-scale, world class analytics solution with a 99.99% SLA. Additionally, integrated, fully managed services like Cloud Data Loss Prevention help their users discover, classify, and protect their most sensitive data. This is a huge advantage for a startup, and enables them to focus their time on creating value for their customers by building their expertise into their product.
Built-in industry leading ML/AI. To deliver advanced machine learning capabilities to its customers, Datalaksa uses BigQuery ML. As the name suggests, BigQuery ML is built right into BigQuery, so not only does it enable them to easily leverage a wide range of advanced ML models, it further decreases development time and cost by eliminating the need to move data between the data warehouse and separate ML system, while enabling people no coding skills to gain extra insights by developing machine learning models using SQL constructs.
Serverless scalability and efficiency. As all of the services that Datalaksa uses are serverless or fully managed services, they offer high levels of resiliency and effortlessly scale up and down with their customers’ needs while keeping the total cost of ownership low by minimizing the operational overheads.
Simplified data integration. Datalaksa is rapidly adding connections to Google data sources such as Google Ads and YouTube, and hundreds of other SaaS services, through BigQuery Data Transfer Service (DTS), and through access to a wide range of 3rd party connectors in the Google Cloud Marketplace including Facebook Ads and eCommerce cart connectors.
The Built with BigQuery advantage for ISVs
Through Built with BigQuery, Google is helping tech companies like Persuasion Technologies build innovative applications on Google’s data cloud with simplified access to technology, helpful and dedicated engineering support, and joint go-to-market programs. Participating companies can:
Get started fast with a Google-funded, pre-configured sandbox.
Accelerate product design and architecture through access to designated experts from the ISV Center of Excellence who can provide insight into key use cases, architectural patterns, and best practices.
Amplify success with joint marketing programs to drive awareness, generate demand, and increase adoption.
BigQuery gives ISVs the advantage of a powerful, highly scalable data warehouse that’s integrated with Google Cloud’s open, secure, sustainable platform. And with a huge partner ecosystem and support for multi cloud, open source tools and APIs, Google provides technology companies the portability and extensibility they need to avoid data lock-in.
Click these links to learn more about Datalaksa and Built with BigQuery.
Source : Data Analytics Read More