Why data clean rooms are key to the future of data sharing and privacy for retailers

Editor’s note: Today we hear from Lytics, whose customer data platform is used by marketers to build personalized digital experiences and one-to-one marketing campaigns using a data science and machine learning decision engine powered by Google Cloud.
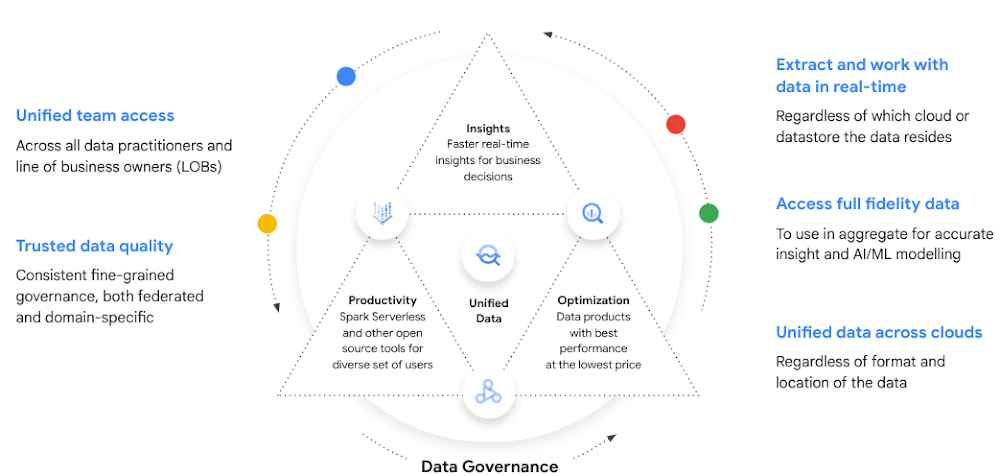
Data clean rooms are a powerful, and often underutilized, tool for leveraging information across a business, between its brands, and with its partners. Think of a data clean room as a data-focused equivalent of a physical clean room, where the objective is to keep what’s inside the clean room protected. From marketing to IT to the C-suite, clean rooms are a way to transform how teams use data, and according to IAB data, are also now essential business solutions for audience insights, measurement, and data activation. Still, this only scratches the surface of what’s possible with clean room technology. And as a result, IAB predicts that companies will invest 29% more in 2023 to make the most of their data clean room capabilities as they look ahead.
Lytics’ customer data platform (CDP) enables organizations to connect more meaningfully with their customers. And together with Google Cloud, we recognize that it’s time to fundamentally reimagine what retailers and consumer packaged goods (CPG) brands can really accomplish with data — and in particular, with data clean rooms.
Why are clean rooms so valuable?
Clean rooms have been used for many years in the finance and health industries to enhance data while maintaining security, but are now becoming increasingly ubiquitous among retail and CPG brands that are navigating a heavily privacy-minded present.
Data, collected by brands directly as opposed to via a third-party, cross-site cookie, is only going to continue to rise in value. Clean rooms make it possible to embrace, with ease and with confidence:
Data sharing and activation. Having better information available to marketing, IT, and executive teams strengthens the entire enterprise. At the same time, you can keep your PII protected and eliminate concerns about data risks.
Enhanced customer profiles. Data today comes from a myriad of sources. By pooling data in clean rooms, you can augment your existing customer profiles with more details, enriching the view of your customers across teams.
Contact sharing. Contact information is critical for outreach. Profiles without accurate contact information are not actionable, so adding these details using clean rooms is invaluable.
Match lists. Comparing lists and matching contacts to certain traits or identities becomes possible, with more data points available.
Joint campaigns. Campaigns run in collaboration with other parts of the enterprise help with efficiency, accuracy, and consistency of message.
Identifying clean room use cases across an enterprise
Data clean rooms are critical to retail and CPG organizations that want to commoditize the information they collect and store, but they often get mistaken as a tool designed primarily to benefit the technical and data teams responsible for enterprise-wide data quality and pipeline health. On the contrary, there are a long list of core benefits of using a data clean room across internal units.
Some of the top use cases for clean rooms as part of your marketing organization include:
1. Ensuring compliance
Compliance is an ever-present, ever-growing aspect of marketing operations today, as the compliance landscape is constantly shifting, adding new updates and mandates to consider. Using a data clean room provider lets marketers eliminate the guesswork of compliance: staying up to speed on all the possible variances and changes. For marketing teams, it’s a tremendous savings of time and money to ensure that your data policies and usage are compliant.
2. Leveraging data anonymization
Imagine the possibilities of gaining information on your customers or groups of customers without knowing their identities. Anonymization is an effective way to market while protecting customer data privacy. In fact, the infamous personalization-privacy paradox can be solved using anonymized data via data clean rooms. Even if that data does contain personally identifiable information, it’s usable because it can be scrubbed via encryption or hashing in the clean room.
3. Embracing better profile optimization
Data clean rooms let you analyze, manipulate and filter data contained in consumer profiles. For example, you can strip away third-party data and look at just first-party data, or take your existing first-party data and overlay it with third-party data. Clean rooms let you consider different factors, such as groups that may respond to one email message or product feature but not another. For A/B testing, segmenting and list building, the data clean room gives you powerful capabilities. All the while, data will remain protected and secure.
For IT and data teams, clean rooms offer possibilities that can enhance and expand the impact of your data:
1. Leveling up your data privacy and security
Privacy and security are top of mind for IT professionals across industries, but especially in retail and CPG where customer-centricity is critical to success. Every day, new cyberthreats emerge that can jeopardize business operations and brand reputations. A compromised system due to a ransomware attack or a data loss can be exceedingly costly. A data clean room can offer your brand a safe environment in which the business can manage, organize and use data. It’s a powerful solution that allows you to work with data while reducing the risk of exposure or compromise.
2. Enhancing machine learning (ML)
Artificial intelligence and machine learning are increasingly used across IT teams in multiple applications. The key is to have enough data to feed into the algorithms to improve learning. Data clean rooms offer expansive arrays of rich, actionable information. This information can help improve how machines learn and adapt, building better models that are smarter and more accurate. With better models, you’ll be able to expand the insights provided and generate better results.
For executives and leadership teams, the list of use cases continues:
1. Driving more revenue and reducing costs
Data sharing means opportunity, both in the costs of managing data and the financial possibilities. For one, streamlining your data management processes means organizations can significantly lower data management expenses. It will also lower your operational costs through the efficient access, analysis, and use of the data you have.
2. Locking in more partnerships
By partnering in the sharing of data, organizations are able to create new relationships that can safely and richly expand the brand. With new data partners and new datasets, you can find new commonalities that can create new and unforeseen business opportunities. The potential impacts on the organization are expansive. Retailers can, for example, leverage the data and relationships to forge new opportunities in product development, customer service, marketing and sales.
All of that data inevitably will lead to deeper insights and discoveries. These new observations can lead to new income streams that monetize data in heretofore unimaginable ways. These may be new streams, new products and services, and, in some cases, new business models.
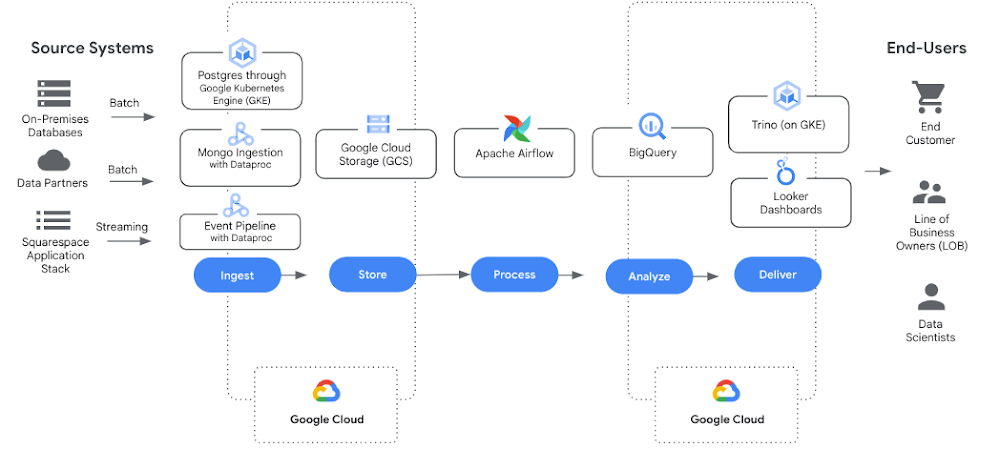
About the Lytics Clean Room Solution, built with BigQuery
Lytics and Google Cloud have developed a scalable and repeatable offering for securely sharing data, utilizing Analytics Hub, a secure data exchange, within BigQuery and the Lytics Platform.
Lytics Clean Room Solution is a secure data sharing and enrichment offering from Lytics that runs on Google Cloud. The solution boasts an integration with BigQuery that makes Lytics an ideal application to simplify and unlock data sharing by unifying and coalescing datasets that help businesses to build or expand existing BigQuery data warehouses. With Analytics Hub, Lytics offers capabilities that improve data management needs on behalf of organizations focused on maximizing the value of that data, and can decrease the time to value in complex data sharing scenarios, meaning that partnership collaboration is safe and secure — and cross-brand activation can be done in just a few hours.
With the Lytics Clean Room Solution, retailers and CPG brands alike can securely share data hosted on BigQuery and activate shared data into customer profiles. The solution provides tighter control of mission critical data for faster activation, and can also be leveraged to comply with stringent privacy constraints, industry compliance standards and newer regulations.
Data clean rooms provide an extraordinary opportunity to transform the way you do business and connect with customers. Especially in retail, technologies that are complementary, integrated and scalable, like clean rooms, allow you to maximize their capabilities and turn your enterprise data tools into business accelerators — but only if you have the foresight to make (and maximize) the investment.
Read the new ebook from Lytics and Google Cloud to learn more about how retail and consumer brands can unlock business value with data that is connected, intelligent and secure.
Source : Data Analytics Read More