Your data is faster together: Your unified data platform for building modern apps

97 zettabytes was the estimated volume of data generated worldwide in 20221. This sort of explosion in data volume is happening in every enterprise. Now imagine being able to access all this data you own from anywhere, at any time, analyze it, and leverage its insights to innovate your products and services? One of the biggest barriers to fulfilling this vision is the complexity inherent in dealing with data trapped across silos in an enterprise. Google Data Cloud offers a unified, open, and intelligent platform for innovation, allowing you to integrate your data on a common architectural platform. Across industries, organizations are able to reimagine their data possibilities in entirely new ways and quickly build applications that delight their customers.
Siloed data: The barrier to speed and innovation
Digital technologies ranging from transaction processing to analytics and AI/ML use data to help enterprises understand their customers better. And the pace of innovation has naturally accelerated as organizations learn, adapt, and race to build the next generation of applications and services to compete for customers and meet their needs. At Next 2022, we made a prediction that the barriers between transactional and analytical workloads will mostly disappear.
Traditionally, data architectures have separated transactional and analytical systems—and that’s for good reason. Transactional databases are optimized for fast reads and writes, and analytical databases are optimized for analyzing and aggregating large data sets. This has siloed enterprise data systems, leaving many IT teams struggling to piece together solutions. The result has been time consuming, expensive, and complicated fixes to support intelligent, data-driven applications.
But, with the introduction of new technologies, a more time-efficient and cost-effective approach is possible. Customers now expect to see personalized recommendations and tailored experiences from their applications. With hybrid systems that support both transactional and analytical processing on the same data, without impacting performance, these systems now work together to generate timely, actionable insights that can be used to create better experiences and accelerate business outcomes.
According to a 2022 research paper from IDC, unifying data across silos via a data cloud is the foundational capability enterprises need to gain new insights on rapidly changing conditions and to enable operational intelligence. The modern data cloud provides unified, connected, scalable, secure, extensible, and open data, analytics, and AI/ML services. In this platform, everything is connected to everything else.
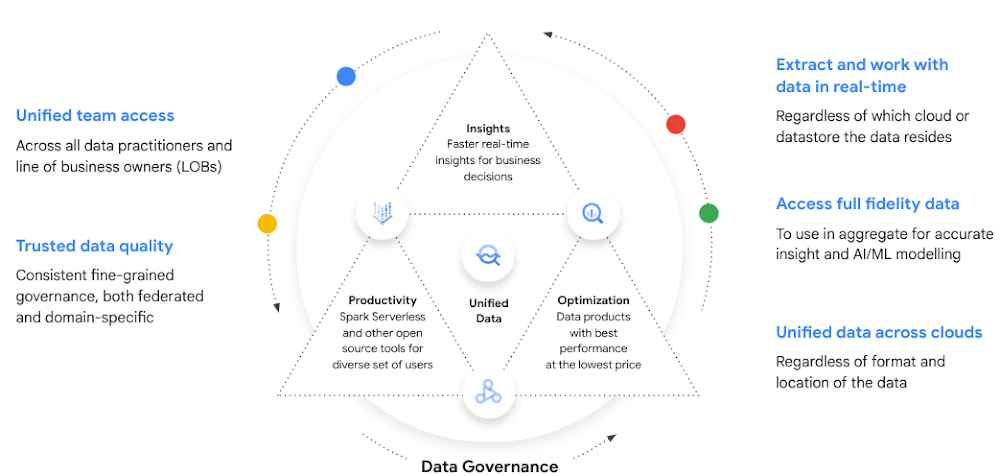
Why reducing data barriers delivers more value
The primary benefit of a unified data cloud is that it provides an intuitive and timely way to represent data and allows easy access to related data points. By unifying their data, enterprises are able to:
Ingest data faster – for operational intelligence
Unify data across silos – for new insights
Share data with partners – for collaborative problem solving
Change forecasting models – to understand and prepare for shifting markets
Iterate with decision-making scenarios – to ensure agile responses
Train models on historical data – to build smarter applications
As generative AI applications akin to Bard, an early experiment by Google, become available in the workplace, it will be more important than ever for organizations to have a unified data landscape to holistically train and validate their proprietary large language models.
With these benefits enterprises can accelerate their digital transformation in order to thrive in our increasingly complex digital environment. A survey of more than 800 IT leaders indicated that using a data cloud enabled them to significantly improve employee productivity, operational efficiency, innovation, and customer experience, among others.
Build modern apps with a unified and integrated data cloud
Google Cloud technologies and capabilities reduce the friction between transactional and analytical workloads and make it easier for developers to build applications, and to glean real-time insights. Here are a few examples.
AlloyDB for PostgreSQL, a fully managed PostgreSQL-compatible database, and AlloyDB Omni, the recently launched downloadable edition of AlloyDB, can analyze transactional data in real time. AlloyDB is more than four times faster for transactional workloads and up to a 100 times faster for analytical queries compared to standard PostgreSQL, according to our performance tests. This kind of performance makes AlloyDB the ideal database for hybrid transactional and analytical processing (HTAP) workloads.
Datastream for BigQuery, a serverless change data capture and replication service, provides simple and easy real time data replication from transactional databases like AlloyDB, PostgreSQL, MySQL and Oracle directly into BigQuery, Google Cloud’s enterprise data warehouse.
And, query federation with Cloud Spanner, Cloud SQL, and Cloud Bigtable, make data available right from the BigQuery console allowing customers to analyze data in real-time in transactional databases.
Speed up deployments and lower costs
By reducing data barriers, we’re taking a fundamentally different approach that allows organizations to be more innovative, efficient, and customer-focused by providing:
Built-in industry leading AI and ML that helps organizations not only build improved insights, but also automate core business processes and enable deep ML-driven product innovation.
Best-in-class flexibility. Integration with open source standards and APIs ensures portability and extensibility to prevent lock-in. Plus, choice of deployment options means easy interoperability with existing solutions and investments.
The most unified data platform with the ability to manage every stage of the data lifecycle, from running operational databases to managing analytics applications across data warehouses and lakes to rich data-driven experiences.
Fully managed database services that free up DBA/DevOps time to focus on high-value work that is more profitable to the business. Organizations that switch from self-managed databases eliminate manual work, realize significant cost savings, reduce risk from security breaches and downtime and increase productivity and innovation. In an IDC survey, for example, Cloud SQL customers achieve an average three-year ROI of 246% because of the value and efficiencies this fully managed service delivers.
Google Data Cloud improves the efficiency and productivity of your teams, resulting in increased innovation across your organization. This is the unified, open approach to data-driven transformation bringing unmatched speed, scale, security, and with AI built in.
In case you missed it: Check out our Data Cloud and AI Summit that happened on March 29th, to learn more about the latest innovations across databases, data analytics, BI and AI. In addition, learn more about the value of managed database services like Cloud SQL in this IDC study.
Source : Data Analytics Read More