The Implications of Blockchain Technology on Big Data

Big data technology has played a huge role in driving the demand for blockchain in recent years.
Source : SmartData Collective Read More

Big data technology has played a huge role in driving the demand for blockchain in recent years.
Source : SmartData Collective Read More
We are excited to announce that differential privacy enforcement with privacy budgeting is now available in BigQuery data clean rooms to help organizations prevent data from being reidentified when it is shared.
Differential privacy is an anonymization technique that limits the personal information that is revealed in a query output. Differential privacy is considered to be one of the strongest privacy protections that exists today because it:
is provably private
supports multiple differentially private queries on the same dataset
can be applied to many data types
Differential privacy is used by advertisers, healthcare companies, and education companies to perform analysis without exposing individual records. It is also used by public sector organizations that comply with the General Data Protection Regulation (GDPR), the Health Insurance Portability and Accountability Act (HIPAA), the Family Educational Rights and Privacy Act (FERPA), and the California Consumer Privacy Act (CCPA).
With differential privacy, you can:
protect individual records from re-identification without moving or copying your data
protect against privacy leak and re-identification
use one of the anonymization standards most favored by regulators
BigQuery customers can use differential privacy to:
share data in BigQuery data clean rooms while preserving privacy
anonymize query results on AWS and Azure data with BigQuery Omni
share anonymized results with Apache Spark stored procedures and Dataform pipelines so they can be consumed by other applications
enhance differential privacy implementations with technology from Google Cloud partners Gretel.ai and Tumult Analytics
call frameworks like PipelineDP.io
BigQuery differential privacy is three capabilities:
Differential privacy in GoogleSQL – You can use differential privacy aggregate functions directly in GoogleSQL
Differential privacy enforcement in BigQuery data clean rooms – You can apply a differential privacy analysis rule to enforce that all queries on your shared data use differential privacy in GoogleSQL with the parameters that you specify
Parameter-driven privacy budgeting in BigQuery data clean rooms – When you apply a differential privacy analysis rule, you also set a privacy budget to limit the data that is revealed when your shared data is queried. BigQuery uses parameter-driven privacy budgeting to give you more granular control over your data than query thresholds do and to prevent further queries on that data when the budget is exhausted.
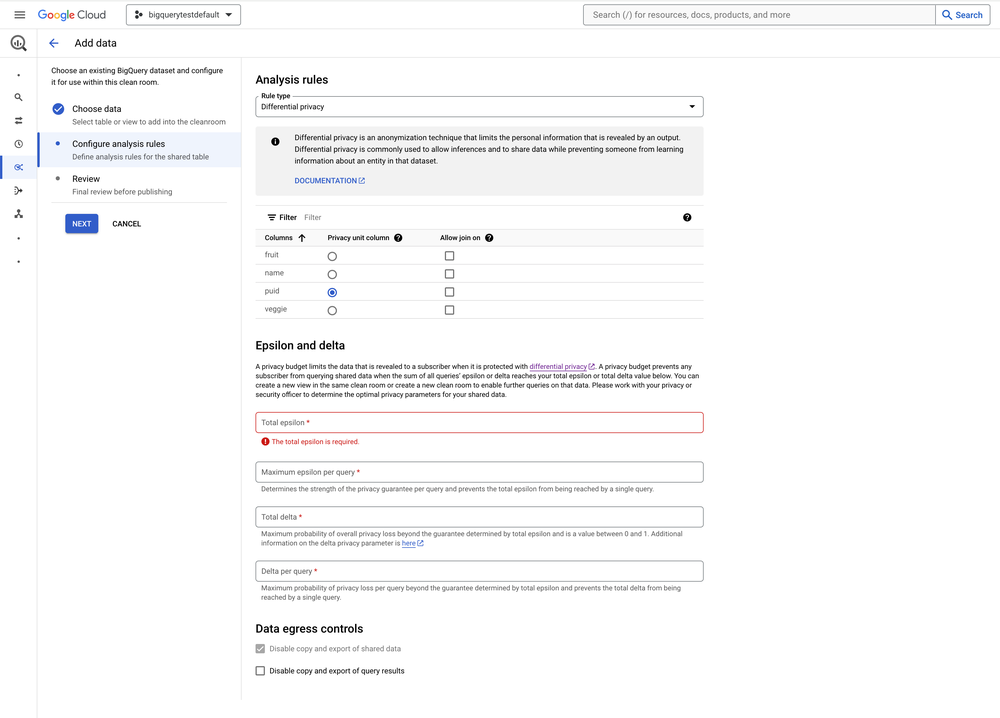
Here’s how to enable the differential privacy analysis rule and configure a privacy budget when you add data to a BigQuery data clean room.
Subscribers of that clean room must then use differential privacy to query your shared data.
Subscribers of that clean room cannot query your shared data once the privacy budget is exhausted.
BigQuery differential privacy is configured when a data owner or contributor shares data in a BigQuery data clean room. A data owner or contributor can share data using any compute pricing model and does not incur compute charges when a subscriber queries that data. Subscribers of a data clean room incur compute charges when querying shared data that is protected with a differential privacy analysis rule. Those subscribers are required to use on-demand pricing (charged per TB) or the Enterprise Plus edition (charged per slot hour).
Create a clean room where all queries are protected with differential privacy today and let us know where you need help.
Source : Data Analytics Read More
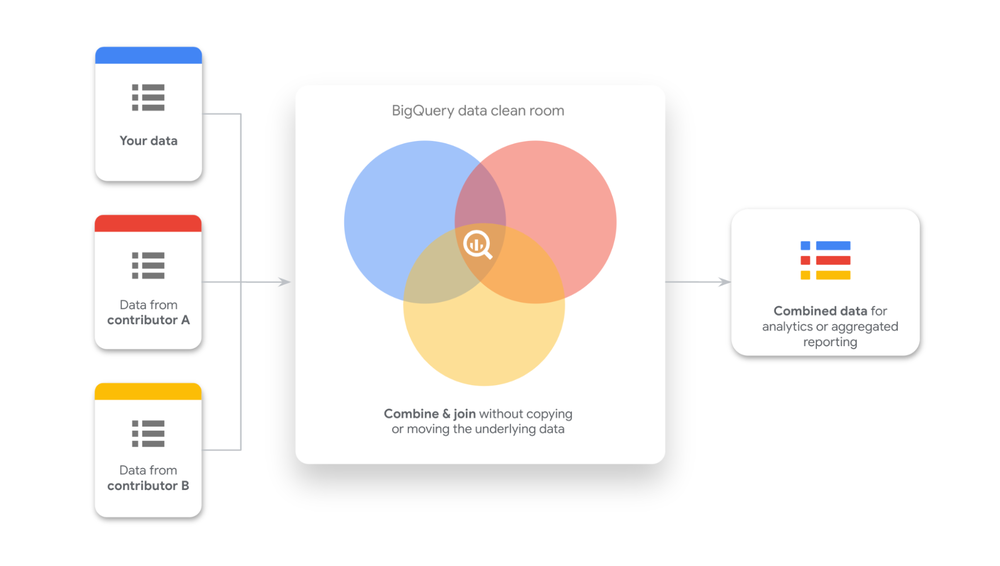
The rise of data collaboration and use of external data sources highlights the need for robust privacy and compliance measures. In this evolving data ecosystem, businesses are turning to clean rooms to share data in low-trust environments. Clean rooms enable secure analysis of sensitive data assets, allowing organizations to unlock insights without compromising on privacy.
To facilitate this type of data collaboration, we launched the preview of data clean rooms last year. Today, we are excited to announce that BigQuery data clean rooms is now generally available.
Backed by BigQuery, customers can now share data in place with analysis rules to protect the underlying data. This launch includes a streamlined data contributor and subscriber experience in the Google Cloud console, as well as highly requested capabilities such as:
Join restrictions: Limits the joins that can be on specific columns for data shared in a clean room, preventing unintended or unauthorized connections between data.
Differential privacy analysis rule: Enforces that all queries on your shared data use differential privacy with the parameters that you specify. The privacy budget that you specify also prevents further queries on that data when the budget is exhausted.
List overlap analysis rule: Restricts the output to only display the intersecting rows between two or more views joined in a query.
Usage metrics on views: Data owners or contributors see aggregated metrics on the views and tables shared in a clean room.
Using data clean rooms in BigQuery does not require creating copies of or moving sensitive data. Instead, the data can be shared directly from your BigQuery project and you remain in full control. Any updates you make to your shared data are reflected in the clean room in real-time, ensuring everyone is working with the most current data.
BigQuery data clean rooms are available in all BigQuery regions. You can set up a clean room environment using the Google Cloud console or using APIs. During this process, you set permissions and invite collaborators within or outside organizational boundaries to contribute or subscribe to the data.
When sharing data into a clean room, you can configure analysis rules to protect the underlying data and determine how the data can be analyzed. BigQuery data clean rooms support multiple analysis rules including aggregation, differential privacy, list overlap, and join restrictions. The new user experience within Cloud console lets data contributors configure these rules without needing to use SQL.
Lastly, by default, a clean room employs restricted egress to prevent subscribers from exporting or copying the underlying data. However, data contributors can choose to allow the export and copying of query results for specific use cases, such as activation.
The data owner or contributor is always in control of their respective data in a clean room. At any time, a data contributor can revoke access to their data. Additionally, as the clean room owner, you can adjust access using subscription management or privacy budgets to prevent subscribers from performing further analysis. Additionally, data contributors receive aggregated logs and metrics, giving them insights into how their data is being used within the clean room. This promotes both transparency and a clearer understanding of the collaborative process.
Customers across all industries are already seeing tremendous success with BigQuery data clean rooms. Here’s what some of our early adopters and partners had to say:
“With BigQuery data clean rooms, we are now able to share and monetize more impactful data with our partners while maintaining our customers’ and strategic data protection.” – Guillaume Blaquiere, Group Data Architect, Carrefour
“Data clean rooms in BigQuery is a real accelerator for L’Oréal to be able to share, consume, and manage data in a secure and sustainable way with our partners.” – Antoine Castex, Enterprise Data Architect, L’Oréal
“BigQuery data clean rooms equip marketing teams with a powerful tool for advancing privacy-focused data collaboration and advanced analytics in the face of growing signal loss. LiveRamp and Habu, which independently were each early partners of BigQuery data clean rooms, are excited to build on top of this foundation with our combined interoperable solutions: a powerful application layer, powered by Habu, accelerates the speed to value for technical and business users alike, while cloud-native identity, powered by RampID in Google Cloud, maximizes data fidelity and ecosystem connectivity for all collaborators. With BigQuery data clean rooms, enterprises will be empowered to drive more strategic decisions with actionable, data-driven insights.” – Roopak Gupta, VP of Engineering, LiveRamp
“In today’s marketing landscape, where resources are limited and the ecosystem is fragmented, solutions like the data clean room we are building with Google Cloud can help reduce friction for our clients. This collaborative clean room ensures privacy and security while allowing Stagwell to integrate our proprietary data to create custom audiences across our product and service offerings in the Stagwell Marketing Cloud. With the continued partnership of Google Cloud, we can offer our clients integrated Media Studio solutions that connect brands with relevant audiences, improving customer journeys and making media spend more efficient.” – Mansoor Basha, Chief Technology Officer, Stagwell Marketing Cloud
“We are extremely excited about the General Availability announcement of BigQuery data clean rooms. It’s been great collaborating with Google Cloud on this initiative and it is great to see it come to market.. This release enables production-grade secure data collaboration for the media and advertising industry, unlocking more interoperable planning, activation and measurement use cases for our ecosystem.” – Bosko Milekic, Chief Product Officer, Optable
Whether you’re an advertiser trying to optimize your advertising effectiveness with a publisher, or a retailer improving your promotional strategy with a CPG, BigQuery data clean rooms can help. Get started today by using this guide, starting a free trial with BigQuery, or contacting the Google Cloud sales team.
Source : Data Analytics Read More
AI technology is leading to major breakthroughs in telehealth, which will be very beneficial for healthcare providers across the world.
Source : SmartData Collective Read More
Big data technology has significantly changed the state of American politics.
Source : SmartData Collective Read More
Big data has led to major breakthroughs in the web development profession in recent years.
Source : SmartData Collective Read More

Google Cloud Next ’24 lands in Las Vegas on April 9, ready to unleash the future of cloud computing! This global event is where inspiration, innovation, and practical knowledge collide.
Data cloud professionals, get ready to harness the power and scalability of Google Cloud operational databases – AlloyDB, Cloud SQL, and Spanner – and leverage AI to streamline your data management and unlock real-time insights. You’ll learn how to master BigQuery for lightning-fast analytics on massive datasets, visualize your findings with the intuitive power of Looker, and use generative AI to get better insights from your data. With these cutting-edge Google Cloud tools, you’ll have everything you need to drive better, more informed decision-making.
Here are 10 must-attend sessions for data professionals to add to your Google Cloud Next ’24 agenda:
Dive into the world of Google Cloud databases and discover next-generation innovations that will help you modernize your database estate to easily build enterprise generative AI apps, unify your analytical and transactional workloads, and simplify database management with assistive AI. Join us to hear our vision for the future of Google Cloud databases and see how we’re pushing the boundaries alongside the AI ecosystem.
>> Add to my agenda <<
With the surge of new generative AI capabilities, companies and their customers can now interact with systems and data in new ways. To activate AI, organizations require a data foundation with the scale and efficiency to bring business data together with AI models and ground them in customer reality. Join this session to learn the latest innovations for data analytics and business intelligence, and see why tens of thousands of organizations are fueling their journey with BigQuery and Looker.
>> Add to my agenda <<
Learn how AI has the potential to revolutionize the way applications interact with databases and explore the exciting future of Google Cloud‘s managed databases, including Cloud SQL, AlloyDB, and Spanner. We will also delve into the most intriguing frontiers on the horizon, such as vector search capabilities, natural language processing in databases, and app migration with large language model-powered code migration.
>> Add to my agenda <<
Join this session to explore all the latest BigQuery innovations to support all structured or unstructured data, across multiple and open data formats, and cross-clouds; all workloads, whether Cloud SQL, Spark, or Python; and new generative AI use cases with built-in AI to supercharge the work of data teams. Learn how you can take advantage of BigQuery, a single offering that combines data processing, streaming, and governance capabilities to unlock the full power of your data.
>> Add to my agenda <<
Powered by Google-embedded storage for superior performance with full PostgreSQL compatibility, AlloyDB offers the best of the cloud. With scale-out architecture, a no-nonsense 99.99% availability SLA, intelligent caching, and ML-enabled adaptive systems, it’s got everything you need to simplify database management. In this session, we’ll cover what’s new in AlloyDB, plus take a deep dive into the technology that powers it.
>> Add to my agenda <<
In the era of multimodal generative AI, a unified, governance-focused data platform powered by Gemini is now paramount. Join this session to learn how BigQuery fuels your data and AI lifecycle, from training to inference, by unifying all your data — structured or unstructured — while addressing security and governance.
>> Add to my agenda <<
Customers use Cloud SQL to run their business-critical applications. The session will dive deep into Enterprise Plus edition features, how Cloud SQL achieves near-zero downtime maintenance, and behaviors that affect availability and mitigations — all of which will prepare you to be an expert in configuring and monitoring Cloud SQL for maximum availability.
>> Add to my agenda <<
Join experts from Databricks, MongoDB, Confluent, and Dataiku for an exclusive executive discussion on harnessing generative AI’s transformative potential. We’ll explore how generative AI breaks down multicloud data silos to enable informed decision-making and unlock your data’s full value. Discover strategies for integrating generative AI, addressing challenges, and building a future-proof, innovation-driven data culture.
>> Add to my agenda <<
Imagine running your non-relational workloads at relational consistency and unlimited scale. Yahoo! dared to dream it, and with Google Spanner, it plans to make it a reality. Dive into its modernization plans for the Mail platform, consolidating diverse databases, and unlocking innovation with unprecedented scale.
>> Add to my agenda <<
Getting insights from your business data should be as easy as asking Google. That is the Looker mission – instant insights, timely alerts when it matters most, and faster, more impactful decisions, all powered by the most important information: yours. Join this session to learn how AI is reshaping our relationship with data and how Looker is leading the way.
>> Add to my agenda <<
Source : Data Analytics Read More

AI technology has led to major changes in mobile technology and has made it easier for mobile developers to monetize their apps.
Source : SmartData Collective Read More
Drupal 9 has a lot of great AI features, but you have to set it up correctly to enjoy their benefits.
Source : SmartData Collective Read More
Data engineers know that eventing is all about speed, scale, and efficiency. Event streams — high-volume data feeds coming off of things such as devices such as point-of-sale systems or websites logging stateless clickstream activity — process lightweight event payloads that often lack the information to make each event actionable on its own. It is up to the consumers of the event stream to transform and enrich the events, followed by further processing as required for their particular use case.
Key-value stores such as Bigtable are the preferred choice for such workloads, with their ability to process hundreds of thousands of events per second at very low latencies. However, key value lookups often require a lot of careful productionisation and scaling code to ensure the processing can happen with low latency and good operational performance.
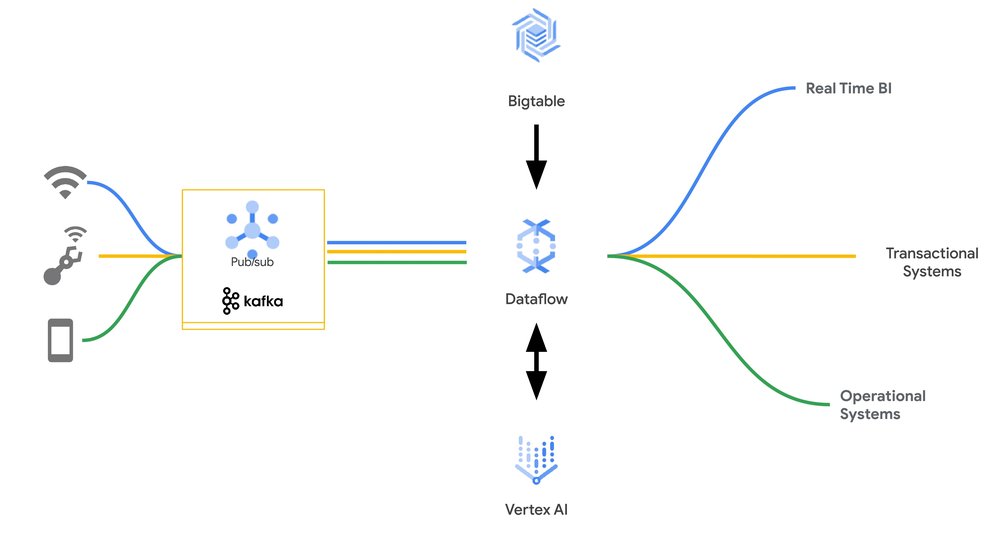
With the new Apache Beam Enrichment transform, this process is now just a few lines of code, allowing you to process events that are in messaging systems like Pub/Sub or Apache Kafka, and enrich them with data in Bigtable, before being sent along for further processing.
This is critical for streaming applications, as streaming joins enrich the data to give meaning to the streaming event. For example, knowing the contents of a user’s shopping cart, or whether they browsed similar items before, can bring valuable context to clickstream data that feeds into a recommendation model. Identifying a fraudulent in-store credit card transaction requires much more information than what’s in the current transaction, for example, the location of the prior purchase, count of recent transactions or whether a travel notice is in place. Similarly, enriching telemetry data from factory floor hardware with historical signals from the same device or overall fleet statistics can help a machine learning (ML) model predict failures before they happen.
The Apache Beam enrichment transform can take care of the client-side throttling to rate-limit the number of requests being sent to the Bigtable instance when necessary. It retries the requests with a configurable retry strategy, which by default is exponential backoff. If coupled with auto-scaling, this allows Bigtable and Dataflow to scale up and down in tandem and automatically reach an equilibrium. Beam 2.5.4.0 supports exponential backoff, which can be disabled or replaced with a custom implementation.
Lets see this in action:
The above code runs a Dataflow job that reads from a Pub/Sub subscription and performs data enrichment by doing a key-value lookup with Bigtable cluster. The enriched data is then fed to the machine learning model for RunInference.
The pictures below illustrate how Dataflow and Bigtable work in harmony to scale correctly based on the load. When the job starts, the Dataflow runner starts with one worker while the Bigtable cluster has three nodes and autoscaling enabled for Dataflow and Bigtable. We observe a spike in the input load for Dataflow at around 5:21 PM that leads it to scale to 40 workers.
This increases the number of reads to the Bigtable cluster. Bigtable automatically responds to the increased read traffic by scaling to 10 nodes to maintain the user-defined CPU utilization target.
The events can then be used for inference, with either embedded models in the Dataflow worker or with Vertex AI.
This Apache Beam transform can also be useful for applications that serve mixed batch and real-time workloads from the same Bigtable database, for example multi-tenant SaaS products and interdepartmental line of business applications. These workloads often take advantage of built-in Bigtable mechanisms to minimize the impact of different workloads on one another. Latency-sensitive requests can be run at high priority on a cluster that is simultaneously serving large batch requests with low priority and throttling requests, while also automatically scaling the cluster up or down depending on demand. These capabilities come in handy when using Dataflow with Bigtable, whether it’s to bulk-ingest large amounts of data over many hours, or process streams in real-time.
With a few lines of code, we are able to build a production pipeline that translates to many thousands of lines of production code under the covers, allowing Pub/Sub, Dataflow, and Bigtable to seamlessly scale the system to meet your business needs! And as machine learning models evolve over time, it will be even more advantageous to use a NoSQL database like Bigtable which offers a flexible schema. With the upcoming Beam 2.55.0, the enrichment transform will also have caching support for Redis that you can configure for your specific cache. To get started, visit the documentation page.
Source : Data Analytics Read More