Could AI Have Prevented the Houston Metro Bus Incident?

AI technology is helping improve public safety, which can prevent another accident like the Houston Metro bus incident.
Source : SmartData Collective Read More

AI technology is helping improve public safety, which can prevent another accident like the Houston Metro bus incident.
Source : SmartData Collective Read More

Smart factories offer a number of new solutions for manufacturing companies trying to bolster their bottom lines.
Source : SmartData Collective Read More
AI technology has created a number of new opportunities for the education sector, which is creating new career opportunities as well.
Source : SmartData Collective Read More
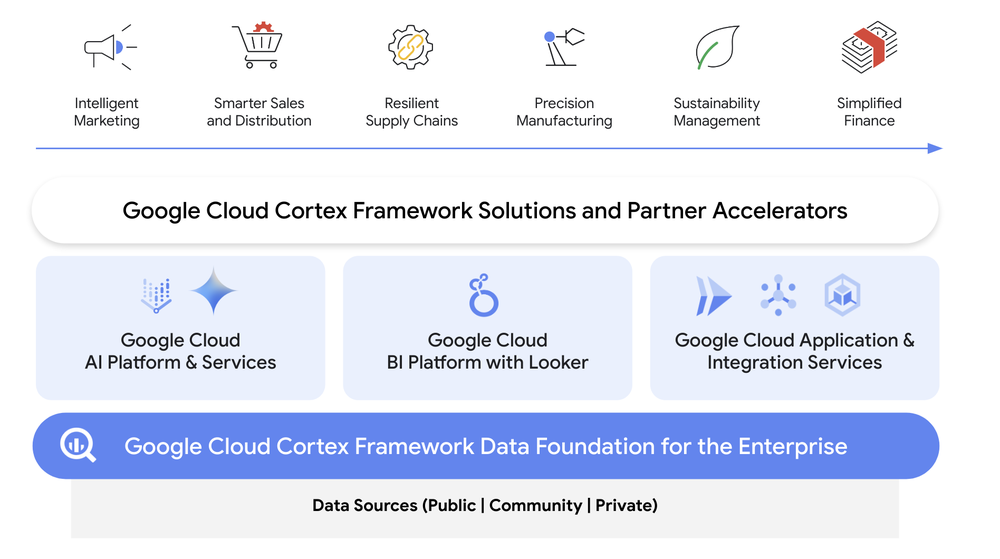
In today’s AI era, data is your competitive edge.
There has never been a more exciting time in technology, with AI creating entirely new ways to solve problems, engage customers, and work more efficiently.
However, most enterprises still struggle with siloed data, which stifles innovation, keeps vital insights locked away, and can reduce the value AI has across the business.
Google Cloud Cortex Framework accelerates your ability to unify enterprise data for connected insights, and provides new opportunities for AI to transform customer experiences, boost revenue, and reduce costs which can otherwise be hidden in your company’s data and applications.
Built on an AI-ready Data Cloud foundation, Cortex Framework includes what you need to design, build, and deploy solutions for specific business problems and opportunities including endorsed reference architectures and packaged business solution deployment content. In this blog, we provide an overview of Cortex Framework, and highlight some recent enhancements.
Get a connected view of your business with one data foundation
Cortex Framework enables one data foundation for businesses by bridging and enriching private, public, and community insights for deeper analysis.
Our latest release extends Cortex Data Foundation with new data and AI solutions for enterprise data sources including Salesforce Marketing Cloud, Meta, SAP ERP, and Dun & Bradstreet. Together this data unlocks insights across the enterprise and opens up opportunities for optimization and innovation.
New intelligent marketing use cases
Drive more intelligent marketing strategies with one data foundation for your enterprise data, including integrated sources like Google Ads, Campaign Manager 360, TikTok and now — Salesforce Marketing Cloud and Meta connectivity with BigQuery via Cortex Framework, with predefined data ingestion templates, data models and sample dashboards. Together with other business data available like sales and supply chain sources in Cortex Data Foundation, you can accelerate insights and answer questions like: How does my overall campaign and audience performance relate to sales and supply chain?
New sustainability management use cases
Want more timely insights into environment, social and governance (ESG) risks and opportunities? You can now manage ESG performance and goals with new vendor ESG performance insights using Dun & Bradstreet ESG ranking data connected with your SAP ERP supplier data. Now with predefined data ingestion templates, data models and a sample dashboard focused on sustainability insights, for informed decision making. Answer questions like: “What is my raw material suppliers’ ESG performance against industry peers?” “What is their ability to measure and manage GHG emissions?” and “What is their adherence and commitment to environmental compliance and corporate governance?”
New simplified finance use cases
Simplify financial insights across the business to make informed decisions about liquidity, solvency, and financial flexibility to feed into strategic growth investment opportunities — now with predefined data ingestion templates, data models and sample dashboards to help you discern new insights with balance sheet and income statement reporting on SAP ERP data.
Accelerate AI innovation with secured data access
To help organizations build out a data mesh for more optimized data discovery, access control and governance when interacting with Cortex Data Foundation, our new solution content offers a metadata framework built on BigQuery and Dataplex that:
Organizes Cortex Data Foundation pre-defined data models into business domains
Augments Cortex Data Foundation tables, views and columns with semantic context to empower search and discovery of data assets
Enables natural language to SQL capabilities by providing logical context for Cortex Data Foundation content to LLMs and gen AI applications
Annotates data access policies to enable consistent enforcement of access controls and masking of sensitive columns
With a data mesh in place, Cortex Data Foundation models can allow for more efficiency in generative AI search and discovery, as well as fine-grained access policies and governance.
Data and AI brings next-level innovation and efficiency
Will your business lead the way? Learn more about our portfolio of solutions by tuning in to our latest Next ‘24 session – ANA107 and checking out our website.
Source : Data Analytics Read More
Lawyers are becoming more dependent on AI technology, which is helping them get better settlements for customers in ride-sharing accidents.
Source : SmartData Collective Read More
AI technology has significantly improved image recognition technology, which helps with modern security.
Source : SmartData Collective Read More
A new startups has released some major breakthroughs in blockchain technology by launching the Reactive Network.
Source : SmartData Collective Read More
More insurers are using data analytics to streamline the process for worker’s compensation claimants.
Source : SmartData Collective Read More
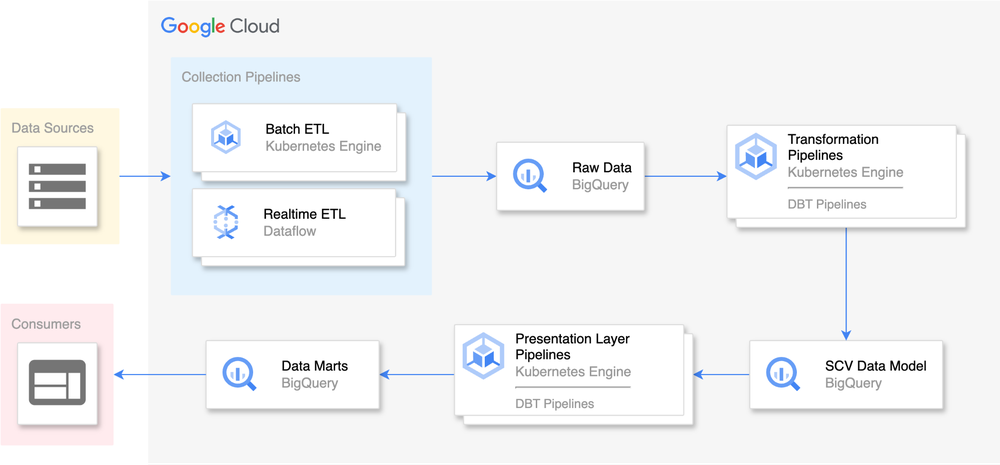
In today’s data-driven world, organizations across industries are seeking ways to gain a deeper understanding of their customers. A Single Customer View (SCV) — also known as a 360-degree customer view — has emerged as a powerful concept in data engineering, enabling companies to consolidate and unify customer data from multiple siloed sources. By integrating various data points into a single, comprehensive view, organizations can unlock valuable insights, drive personalized experiences, and make data-informed decisions. In this blog post, we will take a look at how Telegraph Media Group (TMG) built a SCV using Google Cloud and what we learned from our experience.
TMG is the publisher of The Daily Telegraph, The Sunday Telegraph, The Telegraph Magazine, Telegraph.co.uk, and the Telegraph app. We operate as a subscription-based business, offering news content through a combination of traditional print media and digital channels, including a website and various mobile applications. TMG initially operated a free-to-air, advertising-based revenue model, but over time, this model became increasingly challenging. Like many news media publishers, we saw long-term trends, such as a declining print readership, diminishing ad yields for content publishers, and volatility in ad revenue — all of which make revenue projections uncertain and growth unpredictable.
In 2018, we set out a bold vision to become a subscriber-first business, with quality journalism at our heart, to build deeper connections with our subscribers at scale. By embracing a subscription approach, TMG aimed to establish a more predictable revenue stream and enhance its advertising offerings, which yield higher returns. Our goal was to reach one million subscriptions within five years, and we reached our milestone in August 2023.
The SCV platform we have engineered leverages two primary data resources: a customer’s digital behavior across all digital domains and TMG’s subscription data. Additionally, it integrates data from third-party sources, such as partner shopping websites and engagement products like fantasy football or puzzles. These diverse data sources play a vital role in enriching the platform’s understanding of our audience and delivering a comprehensive news experience.
We can conceptualize the entire process of building the SCV in a few stages:
Data collection: The initial stage involves gathering data from various sources and loading it into BigQuery, which serves as a data lake. Data is extracted from a variety of different sources, using multiple methods, such as databases, APIs, or files, and ingested into BigQuery for centralized storage and future processing.
Data transformation: In this stage, the data retrieved from BigQuery is processed and transformed according to defined business rules. The data is cleansed, standardized, and enriched to ensure its quality and consistency. The data is stored in a new dataset within BigQuery in a structured format known as the SCV data model, where it can be easily accessed and analyzed.
Data presentation: Once the data has been transformed and stored in the BigQuery data lake, it can be organized into smaller, specialized datasets, known as data marts. These data marts serve specific user groups or departments and provide them with tailored and pre-aggregated data for consumption by third-party activation tools, such as email marketing systems, alongside reporting and visualization tools that enable internal decision-making processes.
All of TMG’s subscription data is stored in Salesforce. We implemented a streamlined process to gather this data and store it in BigQuery.
First, we utilize a pipeline comprising containerized Python applications that run on Apache Airflow (specifically, Cloud Composer) every minute. This pipeline retrieves updated data from the Salesforce API and transfers it to Pub/Sub, a messaging service within Google Cloud.
Second, we created a real-time pipeline with DataFlow that reads data from Pub/Sub and promptly updates various tables in BigQuery, enabling us to gain real-time insights into the data.
We also perform a daily batch ingestion from Salesforce to ensure data integrity. This practice allows us to have a comprehensive and complete view of the data, compensating for any potential data loss that may occur during real-time ingestion.
We employ a similar approach to ingesting data from both Adobe Analytics, which monitors user behavior on TMG websites and apps, and Adobe Campaign, which tracks user behavior on communication channels. Since real-time availability is not essential for these datasets, batch processing is deemed sufficient for their ingestion and processing. Additionally, similar ingestion methods are applied to other data sources to ensure a consistent and unified data pipeline.
We employ the open-source Data Build Tool (DBT) for transforming our data, utilizing the power of BigQuery through SQL. By leveraging DBT, we translate all of our business rules into SQL for efficient data transformation. The DBT pipelines are containerized applications that run on an hourly basis and are orchestrated using Cloud Composer, which is built on Apache Airflow. As a result, the output of these data pipelines is a relational model that resides in BigQuery, delivering streamlined and organized data for further analysis and processing. During data transformation, we employ several important pipelines, including:
Salesforce Snapshot: This pipeline generates a snapshot of the Salesforce data from both real-time and batch tables. The snapshot reflects the latest available data in Salesforce and serves as a valuable source for other pipelines in the transformation process.
Source: This pipeline creates a table to store the source data, including source original customer ID and new customer ID. This information plays a crucial role in identifying customers in the original data source.
Customer: This pipeline creates a table that captures and presents detailed information, providing a comprehensive view of their attributes and characteristics.
Contact: This pipeline creates multiple tables that store various contact details of the customers.
Content Interaction: This pipeline generates a table that captures the digital behavior of customers, including their interactions with different content, enabling deeper analysis of customer engagement and preferences.
Subscription Interaction: This pipeline creates a table that tracks and stores subscription-related events and their associated details, providing insights into customer subscription behavior and patterns.
Campaign Interaction: This pipeline creates a table that stores detailed information about events related to communication behavior within different channels, enabling analysis of customer engagement with campaigns and marketing initiatives.
Similar to the transformation layer, DBT pipelines play a crucial role in transforming data from the SCV data model into different data marts. These data marts serve as valuable resources for further analysis and are also consumed by third-party applications. Presently, the three main consumers of the SCV data are Adobe Campaign, Adobe Experience Platform, and Permutive.
Adobe Campaign utilizes the SCV data to effectively target customers by sending relevant campaigns and personalized offers. By leveraging the comprehensive customer insights derived from this data, Adobe Campaign optimizes customer engagement and facilitates targeted marketing efforts.
Adobe Experience Platform leverages the SCV data to deliver tailored experiences to customers visiting the website. By utilizing the rich customer information available, the Adobe Experience Platform customizes the website experience to cater to individual customer preferences, enhancing customer satisfaction and engagement.
Permutive primarily relies on SCV demographic data to target customers with tailored advertisements on the Telegraph website and application. Permutive creates customer segments and integrates with Google Ad Manager to deliver personalized ads.
Prior to the implementation of the SCV, these consumers depended on various data sources, which often resulted in using data that was several days old. This delay imposed limitations on their ability to target customers multiple times within a day. However, with the integration of the SCV, they now have direct access to near real-time data, allowing them to consume and utilize the data as frequently as every 30 minutes. This significant improvement in data freshness empowers TMG to deliver more timely and relevant experiences to our target audiences.
Building a Single Customer View brings forth various challenges, particularly in constructing a data model that meets current requirements while remaining adaptable for future needs. To address this, we prioritize careful extension of the data model, aiming to incorporate new requirements within the existing framework whenever possible. Additionally, determining the appropriate data to include in the SCV is also critical. While businesses may desire to include all customer data, we recognize the importance of avoiding noise and include only relevant and valuable data to maintain a clean SCV.
Managing customer preferences for communication is another significant issue to resolve. Within the SCV, for example, customer preferences dictate how TMG is authorized to engage with them. However, these preferences can vary across different channels, including third-party platforms, potentially conflicting with the preferences stored in our first-party data. To mitigate this, we establish and implement hierarchical rules to carefully define permissions for each communication channel, ensuring compliance and minimizing legal implications.
Efficiently matching customers from third-party data to TMG’s first-party data is also crucial for unifying customers across multiple sources. To tackle this challenge, we employ a combination of exact and fuzzy matching techniques. We implement fuzzy matching using BigQuery User-Defined Functions (UDFs), which allows us to apply various algorithms. However, processing fuzzy matching on large data volumes can be time-consuming. We are actively exploring different approaches to strike a balance between accuracy and processing time, optimizing the matching process and facilitating more efficient customer data integration.
In conclusion, implementing a SCV on Google Cloud empowers TMG to leverage customer data effectively, helping us to drive growth, enhance customer satisfaction, and stay competitive. By harnessing the rich insights derived from a SCV, companies can make data-informed decisions and deliver personalized experiences that resonate with their customers. Overcoming the challenges inherent in building an SCV enables businesses to unlock the full potential of their data and achieve meaningful outcomes.
Source : Data Analytics Read More

Organizations are increasingly adopting streaming technologies, and Google Cloud offers a comprehensive solution for streaming ingestion and analytics. Cloud Pub/Sub is Google Cloud’s simple, highly scalable and reliable global messaging service. It serves as the primary entry point for you to ingest your streaming data into Google Cloud and is natively integrated with BigQuery, Google Cloud’s unified, AI-ready data analytics platform. You can then use this data for downstream analytics, visualization, and AI applications. Today, we are excited to announce recent Pub/Sub innovations answering customer needs for simplified streaming data ingestion and analytics.
Multi-cloud workloads are becoming a reality for many organizations where customers would like to run certain workloads (e.g., operational) on one public cloud and want to run their analytical workloads on another. However, it can be a challenge to gain a holistic view of their business data. Through data consolidation in one public cloud, you can run analytics across their entire data footprint. For Google Cloud customers it is common to consolidate data in BigQuery, providing a source of truth for the organization.
To ingest streaming data from external sources such as AWS Kinesis Data Streams into Google Cloud, you need to configure, deploy, run, manage and scale a custom connector. You also need to monitor and maintain the connector to ensure the streaming ingestion pipeline is running as expected. Last week, we launched a no-code, one-click capability to ingest streaming data into Pub/Sub topics from external sources, starting with Kinesis Data Streams. The Import Topics capability is now generally available (GA) and offers multiple benefits:
Simplified data pipelines: You can streamline your cross-cloud streaming data ingestion pipelines by using the Import Topics capability. This removes the overhead of running and managing a custom connector.
Auto-scaling: Streaming pipelines created with managed import topics scale up and down based on the incoming throughput.
Out-of-the-box monitoring: Three new Pub/Sub metrics are now available out-of-the-box to monitor your import topics.
Import Topics will support Cloud Storage as another external source later in the year.
Apache Flink is an open-source stream processing framework with powerful stream and batch processing capabilities, with growing adoption across enterprises. Customers often use Apache Flink with messaging services to power streaming analytics use cases. We are pleased to announce that a new version of the Pub/Sub Flink Connector is now GA with active support from the Google Cloud Pub/Sub team. The connector is fully open source under an Apache 2.0 license and hosted on our GitHub repository. With just a few steps, the connector allows you to connect your existing Apache Flink deployment to Pub/Sub.
The connector allows you to publish an Apache Flink output into Pub/Sub topics or use Pub/Sub subscriptions as a source in Apache Flink applications. The new GA version of the connector comes with multiple enhancements. It now leverages the StreamingPull API to achieve maximum throughput and low latency. We also added support for automatic message lease extensions to enable setting longer checkpointing intervals. Finally, the connector supports the latest Apache Flink source streaming API.
Pub/Sub has two popular export subscriptions — BigQuery and Cloud Storage. BigQuery subscriptions can now be leveraged as a simple method to ingest streaming data into BigLake Managed Tables, BigQuery’s recently announced capability for building open-format lakehouses on Google Cloud. You can use this method to transform your streaming data into Parquet or Iceberg format files in your Cloud Storage buckets. We also launched a number of enhancements to these export subscriptions.
BigQuery subscriptions support a growing number of ways to move your structured data seamlessly. The biggest change is the ability to write JSON data into columns in BigQuery without defining a schema on the Pub/Sub topic. Previously, the only way to get data into columns was to define a schema on the topic and publish data that matched that schema. Now, with the use table schema feature, Pub/Sub can write JSON messages to the BigQuery table using its schema. Basic types are supported now and support for more advanced types like NUMERIC and DATETIME is coming soon.
Speaking of type support, BigQuery subscriptions now handle most Avro logical types. BigQuery subscriptions now support non-local timestamp types (compatible with the BigQuery TIMESTAMP type) and decimal types (compatible with the BigQuery NUMERIC and BIGNUMERIC types, coming soon). You can use these logical types to preserve the semantic meaning of fields across your pipelines.
Another highly requested feature coming soon to both BigQuery subscriptions and Cloud Storage subscriptions is the ability to specify a custom service account. Currently, only the per-project Pub/Sub service account can be used to write messages to your table or bucket. Therefore, when you grant access, you enable anyone who has permission to use this project-wide service account to write to the destination. You may prefer to limit access to a specific service account via this upcoming feature.
Cloud Storage subscriptions will be enhanced in the coming months with a new batching option allowing you to batch Cloud Storage files based on the number of Pub/Sub messages in each file. You will also be able to specify a custom datetime format in Cloud Storage filenames to support custom downstream data lake analysis pipelines. Finally, you’ll soon be able to use topic schema to write data to your Cloud Storage bucket.
We’re excited to introduce a set of new capabilities to help you leverage your streaming data for a variety of use cases. You can now simplify your cross-cloud ingestion pipelines with Managed Import. You can also leverage Apache Flink with Pub/Sub for streaming analytics use cases. Finally, you can now use enhanced Export Subscriptions to seamlessly get data in either BigQuery or Cloud Storage. We are excited to see how you use these Pub/Sub features to solve your business challenges.
Source : Data Analytics Read More