Big data technology is having a huge impact on the state of modern business. The technology surrounding big data has evolved significantly in recent years, which means that smart businesses will have to take steps to keep up with it. One of the biggest breakthroughs for data-driven businesses has been the development of data activation.
What is Data Activation?
Data activation is a new and exciting way that businesses can think of their data. It’s more than just data that provides the information necessary to make wise, data-driven decisions. It’s more than just allowing access to data warehouses that were becoming dangerously close to data silos. Data activation is about giving businesses the power to make data serve them. That entails a lot of different things, from orchestration and access to automation and tracking.
Data activation is an exciting tool for companies to take advantage of to use their data to its fullest potential. If you have been wondering what data activation is and how it could be helpful. Here is everything you need to know about data activation, which is one of the biggest big data trends of 2022. .
It Started Reverse ETL
Companies will spend over $55 billion on big data this year in the United States alone. This is driving the demand for new data management technologies, which has spurred the need for data activation. ETL is the source of its origin.
To understand how data activation is unique and where it can help your business in powerful ways, you have to start with reverse ETL. ETL is a form of data integration into a warehouse. When a company begins to create data, and it accumulates in a way that is either inaccessible or so disparate that it cannot be useful, it aggregates in what is known as a data silo.
These silos have valuable data that either isn’t in the right format or is just not accessible to the company and poses a problem to companies that wish to use their data productively. The age-old solution to a data silo has always been the data warehouse. This is a solution for taking data out of a silo, transforming it into a uniform, usable format, and then placing it in a warehouse where it is accessible.
ETL itself stands for Extract, Translate, Load. This title mirrored the steps of extracting data from a silo, translating it into an accessible format, and then loading it into a warehouse where it becomes a source of truth across an entire company.
Over time, however, data warehouses and lake houses began to suffer from the same problems that silos did. As a result, this data became hard to access and, in some cases, even impossible for a company to use as a source of truth. There were several factors for this, one of them being that only people who knew SQL could even access this data in the first place.
That is when Hightouch developed a solution that would come to be called reverse ETL. Put simply, this solution helped to move data out of a warehouse and across a company’s departments. This allowed different departments within a company to have access to data vital for making good, customer-based decisions.
Because reverse ETL was so successful, it began to be something that unlocked new possibilities for companies. As they continued to use it, Hightouch was able to stay up to date with how to reverse ETL was impacting a company’s data usage. This led to understanding how things could be improved and what could be added to improve this system.
From Reverse ETL to Data Activation
After nearly two years of working hand in hand with reverse ETL, Hightouch was able to produce what is now being called Data Activation. Data Activation has all the great benefits of Reverse ETL. Still, it continues to give developers, engineers and departments the tools they need to get the most out of the data that belongs to their company.
The shift from reverse ETL to data activation came through operational analytics. Operational analytics focused on not only getting data to a department but giving those departments the ability to make data work. That meant allowing for automation of tasks based on customer interactions.
There was confusion over semantics. Operational Analytics sounded like a solution for retroactive decision-making. Collecting data and looking back over it and using this information to make decisions. Data Activation is more in line with what Operational Analytics is meant to be.
This allowed companies to set automation in motion that helped departments see a clearer, more precise view of their customer in real-time. In addition, this tracked data across an entire company to give departments the ability to improve customer relations as they happened and not only have the looking back at accumulated data.
Conclusion
Hightouch continues to work closely with its clients to make the best tools on the market for helping businesses use their data effectively. Giving companies the tools to use their data to help improve customer experience, win over potential customers, and grow is what Data Activation aims to do.
What if, after all the upheavals and innovations of the past two years, we’re not headed for some new normal but instead an era of no more normal?
“There are big, big challenges that need to be solved every single day by supply chain professionals,” Hans Thalbauer, Google Cloud’s managing director for supply chain and logistics, pointed out during our recent Supply Chain & Logistics Spotlight event. Among the issues Thalbauer ticked off were changes from the pandemic, consumer demand, labor shortages, the climate crisis, geopolitical instability, and energy shortages.
“And the thing is, it’s not just a short term issue, we think it’s a long-term and systemic issue,” Thielbauer said. “There’s a big question out there, which is: How will global trade change? Is it really transforming and translating into something new? Will global trade continue to work as is?”
Even experts at the White House are asking these very questions at this very time. The same day as the Supply Chain & Logistics Spotlight, the president’s Council of Economic Advisors released their annual report with an entire chapter dedicated to supply chain. In it, they noted that once-obscure, and ideally invisible, supply chains had “entered dinner table conversations.” And for good reason. “Because of outsourcing, offshoring, and insufficient investment in resilience, many supply chains have become complex and fragile,” the economists wrote. Nor are they alone in worrying about the future of logistics.
Whatever the outcomes—more global or local, more automated or disintermediated, more agile or fragile—one of the likeliest results is a greater reliance on technology, and especially data, to help handle all the disruptions and interruptions on the horizon.
Leaders in the field, including at The Home Depot, Paack, and Seara Foods, are discovering opportunities in a few key areas: connecting data from end to end; the power of platforms to access and share information; and the importance of predictive analytics to mitigate issues as, or even before, they arise.
“We need to create visibility, flexibility, and innovation,” Thalbauer said. “Too often companies just focus on their orders, forecasts, and inventory, but typically they ignore the rest of the world. We need to bring in the public information, the traffic, weather, climate, and financial risks, connect that with the enterprise data, and we need to actually enable community data to create collaboration between business partners at every tier.”
End-to-end data
Companies have always sought visibility from the factory to the warehouse to the store and now the front door, and all the points in between. Both the challenge and necessity of seeing into all these is that as the data has grown, and our capabilities along with it, so has the complexity. It’s at a scale no humans can manage, which makes the importance not only of data but analytics and AI all the more essential.
Home Depot has had a front row seat to these growing interdependencies—especially when it comes to serving competing yet complimentary clienteles.
The pandemic presented its share of unexpected opportunities, as the combination of soaring home values, disposable income, and DIYers looking for (stay at) home projects led to runs on everything from lumber to sheds-turned-offices to garage doors. Empty shelves can lead to angry customers.
And in this case, it wasn’t just homeowners and renters Home Depot was contending with, explained Chris Smith, vice president of IT Supply Chain at Home Depot, but also an increasingly important base of contractors and even large-scale developers. Both tended to need different materials, at different scales, and shopped in different ways, and these demands have only expanded during the pandemic.
Whatever the future of logistics look like—more global or local, more automated or disintermediated, more agile or fragile—one of the likeliest results is a greater reliance on technology.
“We really have what we call an omnichannel algorithm.” Chris Smith, VP of IT Supply Chain at The Home Depot. “It’s really marrying up the customer’s preferences with our understanding of capacity, assortment, inventory availability, taking all that together, and saying: How do we best meet the customer promise and do it with the most efficient use of our supply chain? So where do we fulfill it from, where is the inventory available, and how do we do that in a way that’s most economical for us while still meeting the promise of the customer,” Smith said.
Paack, a last-mile delivery start-up serving the UK, Spain, France, Portugal, and Italy, is similarly pushing the envelope on fulfillment. The company focuses on combining a wealth of data—from drivers, customers, sensors, weather, and more—to ensure guaranteed delivery. So far, their success rate is approaching 98% of on-time delivery, with special scheduling tools to ensure customers are available to receive their packages.
Using solutions like the Last Mile Fleet Solution from Google Maps Platform, Paack can manage drivers and customers in real-time.
“The granularity of information we can collect in terms of which routes are being effectively followed by the driver’s route versus planned routes, the ability for them to change directions, because we might know locally of better ways to go, notifications from the customer as to their availability—these really allows us to build a better experience for everyone,” Olivier Colinet, chief product and technology officer for Paack, said. “We want first-time drivers to be the most productive drivers, and this first step allows us to do so.”
Power of platforms
Paack’s success exemplifies the power of building a strong platform for customers and workers, as well as tapping existing platforms, like Google Maps, to bolster your own.
On the other side of the globe, the world’s largest meat supplier is seeking to empower thousands of ranchers and farmers with a platform of their own. Seara, a Brazil-based supplier of pork, chicken and eggs that is part of the globe-spanning JBS conglomerate, launched its SuperAgroTech platform in July 2021.
Though in development for years, the program could hardly have come at a more critical time for the global food supply. The food industry was already coping with pandemic-related shortages and shutdowns, and then came the spillover effects from the war in Ukraine.
“In general, the entire supply chain was affected and the operation had to adapt to new working conditions,” Thiago Acconcia, the director of innovation and strategy at Seara, said. “So in the farms, in the field, the same situations are repeated, and the creation of this digital online platform enters as a facilitator when it gives autonomy to the farmer, providing them with the data input and digital communication.” It’s a level of connectivity the farmers never had with Seara before—and vice versa.
The technology has been deployed to more than 9,000 farms at launch. Through a range of IoT sensors, monitoring devices, and data inputs from farmers, operators and Seara data, teams can track a host of results. These include yields, animal health, profits, and even environmental and social impacts, which are becoming increasingly important features for consumers.
The eventual goal is to reach 100% digital management of the farm.
“So today, we are able to activate any producer in a few seconds, regardless of the location,” Acconcia said. With SuperAgroTech, the platform “doesn’t mind if it’s in the very south of the country, if it’s in the central part. It’s strengthening the relationships with our producers and also promoting a level of personalized attention they’ve never had.”
Such platforms also provide a level of visibility and connectivity rarely enjoyed before, as well as a virtuous cycle between data collection, analysis, and insights put back into action on the platform. In an unpredictable world, this kind of integration is becoming essential.
Stacks of containers
Predictive Analytics
As a company’s digital strategies evolve through integrated data and robust platforms, one of the most exciting opportunities arises around predictive analytics.
While seeing into the future remains science fiction (at least for now), AI, cloud, and even emerging quantum computing are providing robust ways to better reveal trends, make connections, and anticipate both opportunities and interruptions.
Home Depot has looked at ways to quickly adapt its digital stores using consumer data and AI to create better experiences, as well as smoothing out supply chain issues. Home Depot’s Chris Smith pointed to a listing for an out-of-stock appliance or tool, for example, that will quickly offer other locations or items for sale as a convenient alternative.
“We can apply machine learning in many different ways to make better, faster decisions, both in how we support moving inventory through our supply chain or how we understand available capacity to support our customers,” Smith said. “And with automation, from our distribution centers to our forecasting and replenishment systems, we’re going to continue to look at places where we can optimize and automate to make better decisions.”
For Paack, predictions could come in the form of traffic or storms or even the likelihood that a repeat customer will be available or not, without having to prompt them.
And at Seara, the role of data and analytics is not just vital to the business but the very vitality of the world. As climate, supply chains, global conflicts, migration, and other issues continue to constrain the food supply, anticipating issues could be the difference between salvaging a crop or not.
“We started creating advanced analytics by means of AI tools to not only notify real-time problems but also to predict what’s going to happen in the near and long future,” Acconcia said. “We are talking about the world’s food, and SuperAgroTech has the role to feed the world, and to overcome these biggest challenges.”
Astronomical data is the oldest data collected by humankind. The oldest known systematic astronomical observations came from the Babylonians in 1000 BCE. In the second century BCE, the first stellar catalog was compiled by Greek astronomer Hipparchus of Nicaea, which would eventually make it into the hands of Roman astronomer Ptolemy three centuries later.
Old data can be extremely valuable when studied with modern tools. And, when it comes to the cosmos, we have a whole lot of data collected in extensive sky surveys over the last few decades.
Google Cloud worked with researchers from The Asteroid Institute, a program of the non-profit B612 Foundation, to apply modern cloud computing tools and algorithms to old cosmological datasets to find and map asteroids in our solar system. The Asteroid Institute announced today that the new method has found and validated 104 new asteroids, opening the possibility of using this method to find hundreds or thousands of new asteroids hiding in old datasets.
“We’ve proven a new, computationally driven method of discovering asteroids,” said Dr. Ed Lu, Executive Director of the Asteroid Institute and former NASA astronaut, in a conversation with Vint Cerf, VP & Chief Internet Evangelist at Google about the new computation method for discovering asteroids. “The Minor Planet Center confirmed and added these newly discovered asteroids to its registry … opening the door for Asteroid Institute-supported researchers to submit thousands of additional new discoveries. This has never been done before, since previous methods have relied on specific telescopic survey operations. Instead, we’ve been able to identify and track asteroids using enormous computational power.”
ADAM and THOR: Hunting the sky together
The Asteroid Institute employs a cloud-based astrodynamics platform called the Asteroid Discovery Analysis and Mapping (ADAM) to hunt for asteroids in our solar system. ADAM is an open-source computational system that runs astrodynamics algorithms at massive scale in Google Cloud.
The novel algorithm used to discover these new asteroids is called Tracklet-less Heliocentric Orbit Recovery (THOR). The algorithm links points of light in different sky images that are consistent with asteroid orbits, trying to identify the orbits of asteroids that can be seen in old data. As such, THOR does not need a telescope to observe the sky to look for asteroids, but rather can hunt through old images to look for the familiar patterns. THOR can identify asteroids and calculate their orbits meeting criteria by the Minor Planet Center to recognize them as tracked asteroids.
For its initial demonstration, researchers from the Asteroid Institute and the University of Washington searched a 30-day window of images from the NOIRLab Source Catalog (NSC), a collection of nearly 68 billion observations taken by the National Optical Astronomy Observatory telescopes between 2012 and 2019.
Finding and tracking asteroids is a difficult problem for a few reasons. Space is huge, even when we know where we are supposed to look. The relative luminosity (the intrinsic brightness of a celestial object) is low in comparison to planets in our solar system or faraway stars. Also, the Earth is constantly moving through the solar system, as are the asteroids. Linking different images of the sky to previous signals in the data increases the variables and makes the entire endeavor extremely computationally expensive when dealing with large datasets.
“First, linking asteroid detections across multiple nights is difficult due to the sheer number of possible linkages, made even more challenging by the presence of false positives,” researchers wrote in a paper onthe introduction of THOR in May 2021. “Second, the motion of the observer makes the linking problem nonlinear as minor planets will exhibit higher order motion on the topocentric sky over the course of weeks.”
The way asteroid detection has been performed before was to use surveys from terrestrial telescopes and look for the tracks made by the asteroids that showed up in the data in multiple observations over time. This required time on expensive telescopes that often have other priorities, and a regular cadence of observations. It’s an inefficient and time consuming process. What THOR does is try to remove the need to rely on the asteroid tracklets in the data (thus “Tracklet-less”) and narrow the scope of the observation field to a dynamically selected series of “test orbits.” By focusing on a specific area through a portion of the NSC dataset (only 0.5%), the data becomes more linear and easier to manage, picking out potential asteroids with clustering and line-detection algorithms.
“This provides a path to scanning an otherwise voluminous 6D phase space with a finite number of test orbits and at feasible computational cost,” researchers wrote.
One of the primary benefits of the THOR approach is that it can be used on datasets beyond the scope of just one celestial survey, opening up the possibility of investigating a diverse array of datasets and making connections between them. Thus, THOR becomes an independent agent from the observer (the telescope survey data) and able to make connections between different datasets from different times.
One interesting note from THOR is that it is not based on machine learning or neural networks. The power of THOR is in taking data from the test orbits and applying statistics plus physics, through linear and clustering algorithms and then utilizing a massive amount of computational power through the cloud. One area where machine learning can be applied in the future will be in making the search through the infinite possible orbits smarter and faster, in the same way that DeepMind’s AlphaGo algorithm efficiently determines which move to make next on a Go board among a very large number of possibilities.
Scaling ADAM with Google Cloud
THOR runs on the ADAM, which is The Asteroid Institute’s astrodynamics-as-a-service platform powered by Google Cloud, including the scalable computational and storage capabilities in Compute Engine, Cloud Storage, and Google Kubernetes Engine.
In 2019 and 2020, Google Cloud’s Office of the CTO conducted architectural sessions and organized hackathons with solution architects at Google Cloud to find the best way to implement ADAM on Google Cloud at scale. Google Cloud also provided cloud credits and technical support for the ADAM platform’s current development and future work.
“The potential of this software ecosystem also stretches far beyond historical data – with additional development, ADAM::THOR will be able to perform real-time asteroid discovery on observations as they come in from telescopes around the globe,” said Joachim Moeyens, co-creator of THOR and an Asteroid Institute Fellow
While THOR makes digging through existing astronomical datasets computationally feasible, it is important to consider that the data consists of a massive amount of space, searching for continuous orbits. It’s still a very large number of candidate orbits that need to be searched and thus requires the type of storage capacity and computing resources that only the public cloud can provide. The raw astronomical data is stored in Google Cloud Storage, with refined data later abstracted into BigQuery. Google Cloud enables ADAM to scale by allowing it to run on thousands of machines simultaneously, which results in the ability to analyze the data in a reasonable amount of time.
One of the most powerful aspects of the partnership between B612 and Google Cloud is to make ADAM a “discovery-as-a-service” platform available for future researchers.
“With the arrival of the public cloud, researchers can now get access to large computational resources when they need them with much less overall cost and time penalty,” said Cerf. “And we’re seeing that large data sets can be applied to new problems.”
One of the most buzzing terminologies of this decade has got to be “data analytics.” Companies generate unlimited data every day, and there is no end to the data collected over time. This content can be in the form of log content, transactional content, social media data, and customer—related data.
Companies need all of this data in a structured manner to improve their decision—making capabilities. Additionally, one can derive the most value out of this data by using it to boost their career performance. Data analytics helps in meeting these goals.
Data analytics consists of processes examining data sets to find trends and conclusions from the information. The speed and efficiency of your business improve once you notice patterns and discover insightful data needed for business predictions. Therefore, data analytics is undoubtedly the most sought—after science field today.
How can data analytics be used for bolstering career performance?
It never hurts to have extra skills to make work easier, which is why professionals seek the help of data analytics to recognize work patterns. The analysis helps them understand how the quality of work can be improved and change the present circumstances in the workplace. For career prospects also, companies are turning towards analytics to make safer decisions.
The following reasons make it easier to understand why more businesses are incorporating data analytics to enhance performance:
1. Data analytics is prevalent in all sectors
The top industries that rely heavily on data analytics are Information Technology services, Manufacturing and Retail businesses, and Finance and Insurance companies. However, data analytics is now used across all domains and sectors.
For better career prospects, data analytics can aid in predicting upcoming developments in different industries. As a result, you can look for opportunities in the sector you are interested in. You can avail yourself of the benefits of career development before anyone else.
2. Data analytics acts as a catalyst for artificial intelligence
Artificial intelligence is another buzzing terminology of today. Most people don’t know that data analytics serves as a foundation for companies that want to develop artificial intelligence—related projects. This is because AI uses the same techniques and processing capabilities that data analytics resources use.
3. Data analytics makes marketing strategies successful
Data analytics takes a big chunk of information, derives valuable insights, and tests the results on a sample audience group. Marketing strategies can use the same method to understand consumer trends and behaviors. Companies can thereby produce compelling pitches for their products/services and develop sure—shot marketing strategies.
4. Data analytics increases the revenue of the business
As data analytics helps see the changing dynamics much ahead of time, companies can upgrade themselves accordingly. This ensures that the company is always at the top of its game and never loses brilliant opportunities. Eventually, everything works towards generating more revenue for the business.
How can companies use data analytics for their employees?
If you are running on a money and time budget, using data analytics to speed up work is the best call you can take. When you bridge the gap between job tasks and quantitative abilities, you will get a tangible input of what level of performance is required to accomplish the job.
Organizations can use the following strategies to apply data analytics at work for better performance management:
1. Generate accurate employee feedback
The future of performance management includes both employee feedback and data analytics. For example, instead of providing work reviews at scheduled times during the year, companies can apply real—time reviews and check—ins to improve engagement.
Resources like HR assessments and PR reviews can help employees understand their shortcomings and biggest strengths. Additionally, Leapsome’s feedback examples can be used for effective employee feedback management. The human touch will always be an integral part of the process, even if data analytics takes over completely.
2. Measure employee performance
Companies can use data analytics tools to set benchmarks for employee performance. Apart from professional data, inputs on travel data and billing hours can help them plan both professional and personal priorities, significantly when it impacts their wellness. Employees meeting those benchmarks can guide others in an optimal career performance.
3. Apply analytical diligence
You can apply data analytics to plan talent and work on the performance management of your employees. With the results, you can invest in the right tools needed to sharpen the skills and enhance the productivity of those falling back. In addition, this analysis can help the HR department describe their job requirements accurately and find the right people for the job.
4. Personalize workforce environment
Data analysis can help understand employee data and provide them with a unique workplace environment. Letting people know that their data is used for analysis helps retain their trust. Eventually, you will be able to create a safe space for your employees where they can work as per their suitability.
5. Perform unbiased recruitment processes
Data analytics can help in recognizing those groups that face unconscious bias. By representing those groups, you will be able to broaden the talent pool in your workspace. In addition, analytics and digital engagement can help understand those algorithms and decisions concerning the company.
6. Inform employees about promotion and salary decisions
Nothing puts off an individual more than seeing an undeserving candidate get what they deserve, especially in a workplace. However, promoting the wrong candidate can demotivate the rest of the team members. Data analytics can help managers rate the proficiency and the capability of those employees who either deserve a promotion or a raise.
7. Understand attrition and increase retention
Performance—based analytics can be applied to foresee those employees that are likely to leave their jobs and what factors can contribute to attrition. For example, money may not always be the factor to be blamed. Other factors like smaller teams or longer wait for promotions or raises can be equally responsible.
Summarizing data analytics and its effect on career performance
While intelligent data analytics metrics certainly help HR professionals, it still doesn’t take away the importance of the human role in upgrading career performance. The most successful way of integrating data analytics is through a proper organizational design. This design will guide future decisions, specify skillsets needed and upskill employees to perform well in their chosen career path.
Editor’s note: The post is part of a series highlighting our partners, and their solutions, that are Built with BigQuery.
To fully leverage the data that’s critical for modern businesses, it must be accurate, complete, and up to date. Since 2007, ZoomInfo has provided B2B teams with the accurate firmographic, technographic, contact, and intent data they need to hit their marketing, sales, and revenue targets. While smart-analytics teams have used ZoomInfo data sets in Google BigQuery to integrate them with other sources to deliver reliable and actionable insights powered by machine learning, Google Cloud and ZoomInfo recently have partnered to give organizations even richer data sets and more powerful analytics tools.
Today, customers now have instant access to ZoomInfo data and intelligence directly within Google BigQuery. ZoomInfo is available as a virtual view in BigQuery, so analysts can explore the data there even before importing it. Once ZoomInfo data has been imported into BigQuery, data and operations teams will be able to use it in their workflows quickly and easily, saving their sales and marketing teams time, money, and resources. ZoomInfo data sets include:
Contact and company. Capture essential prospect and customer data — from verified email addresses and direct-dial business phone and mobile numbers, to job responsibilities and web mentions. Get B2B company insights, including organizational charts, employee and revenue growth rates, and look-alike companies.Technographics and scoops. Uncover the technologies that prospects use — and how they use them — to inform your marketing and sales efforts. Discover trends to shape the right outreach messaging and determine a buyer’s needs before making the first touch. Buyer intent. ZoomInfo’s buyer intent engine captures real-time buying signals from companies researching relevant topics and keywords related to your business solution across the web.Website IP traffic. Enrich data around traffic from your digital properties, so your customer-facing teams can take immediate action and turn traffic into sales opportunities.
In the future, ZoomInfo data sets will be available in the Google Cloud Marketplace as well as Google Cloud Analytics Hub (now in preview) alongside popular Google and third-party data sets including Google Trends, Google Analytics, and Census Bureau data.
The new features will help ZoomInfo and Google Cloud customers such as Wayfair Professional, one of the world’s largest home retailers. Wayfair Professional is a long-time user of ZoomInfo’s Company Data Brick, API, and enrichment services. Wayfair Professional has historically accessed ZoomInfo data through file transfer, which involved shuffling encrypted CSVs back and forth over SFTP and manual file processing to ingest it into Google BigQuery. Ryan Sigurdson, senior analytics manager at Wayfair Professional, shared that moving their monthly offline company enrichment workflow to BigQuery could save them weeks of manual work and maintenance every month.
Built with BigQuery
ZoomInfo is one of over 700 tech companies powering their products and businesses using data cloud products from Google, such as BigQuery, Looker, Spanner, and Vertex AI. Recently at the Data Cloud Summit, Google Cloud announced Built with BigQuery, which helps ISVs like ZoomInfo get started building applications using data and machine learning products. By providing dedicated access to technology, expertise, and go to market programs, this initiative can help tech companies to accelerate, optimize, and amplify their success.
ZoomInfo’s SaaS solutions have been built on Google Cloud for years. By partnering with Google Cloud, ZoomInfo can leverage an all-in-one cloud platform to develop its data collection, data processing, data storage, and data analytics solutions.
“Enabling customers to gain superior insights and intelligence from data is core to the ZoomInfo strategy. We are excited about the innovation Google Cloud is bringing to market and how it is creating a differentiated ecosystem that allows customers to gain insights from their data securely, at scale, and without having to move data around,” says Henry Schuck, ZoomInfo’s chief executive officer. “Working with the Built with BigQuery team enables us to rapidly gain deep insight into the opportunities available and accelerate our speed to market.”
Google Cloud provides a platform for building data-driven applications like ZoomInfo, from simplified data ingestion, processing, and storage to powerful analytics, AI/ML, and data sharing capabilities, all integrated with the open, secure, and sustainable Google Cloud platform. With a diverse partner ecosystem and support for multicloud, open source tools, and APIs, Google Cloud provides technology companies the portability and extensibility they need to avoid data lock-in.
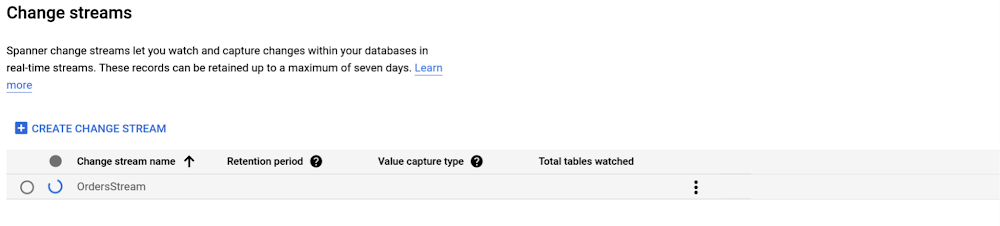
At this year’s Google Data Cloud Summit, we announced Cloud Spanner change streams. Today, we are thrilled to announce the general availability of change streams. With change streams, Spanner users are now able to track and stream out changes (inserts, updates, and deletes) from their Cloud Spanner database in near real-time.
Change streams provides a wide range of options to integrate change data with other Google Cloud services. Common use cases include:
Analytics: Send change events to BigQuery to ensure that BigQuery has the most recent data available for analytics. Event triggering: Send data change events to Pub/Sub for further processing by downstream systems. Compliance: Save the change events in Google Cloud Storage for archiving purposes.
Getting started with change streams
This section walks you through a simple example of creating a change stream, reading its data, and sending the data to BigQuery for analytics.
If you haven’t already done so, get yourself familiar with Cloud Spanner basics with the Spanner Qwiklab.
Creating a change stream
Spanner change streams are created with DDL, similar to creating tables and indexes. Change stream DDL requires the same IAM permission as any other schema change (spanner.databases.updateDdl).
A change stream can track changes on a set of columns, a set of tables, or an entire database. Each change stream can have a retention period of anywhere from one day to seven days, and you can set up multiple change streams to track exactly what you need for your specific objectives. Learn more about creating and managing change streams.
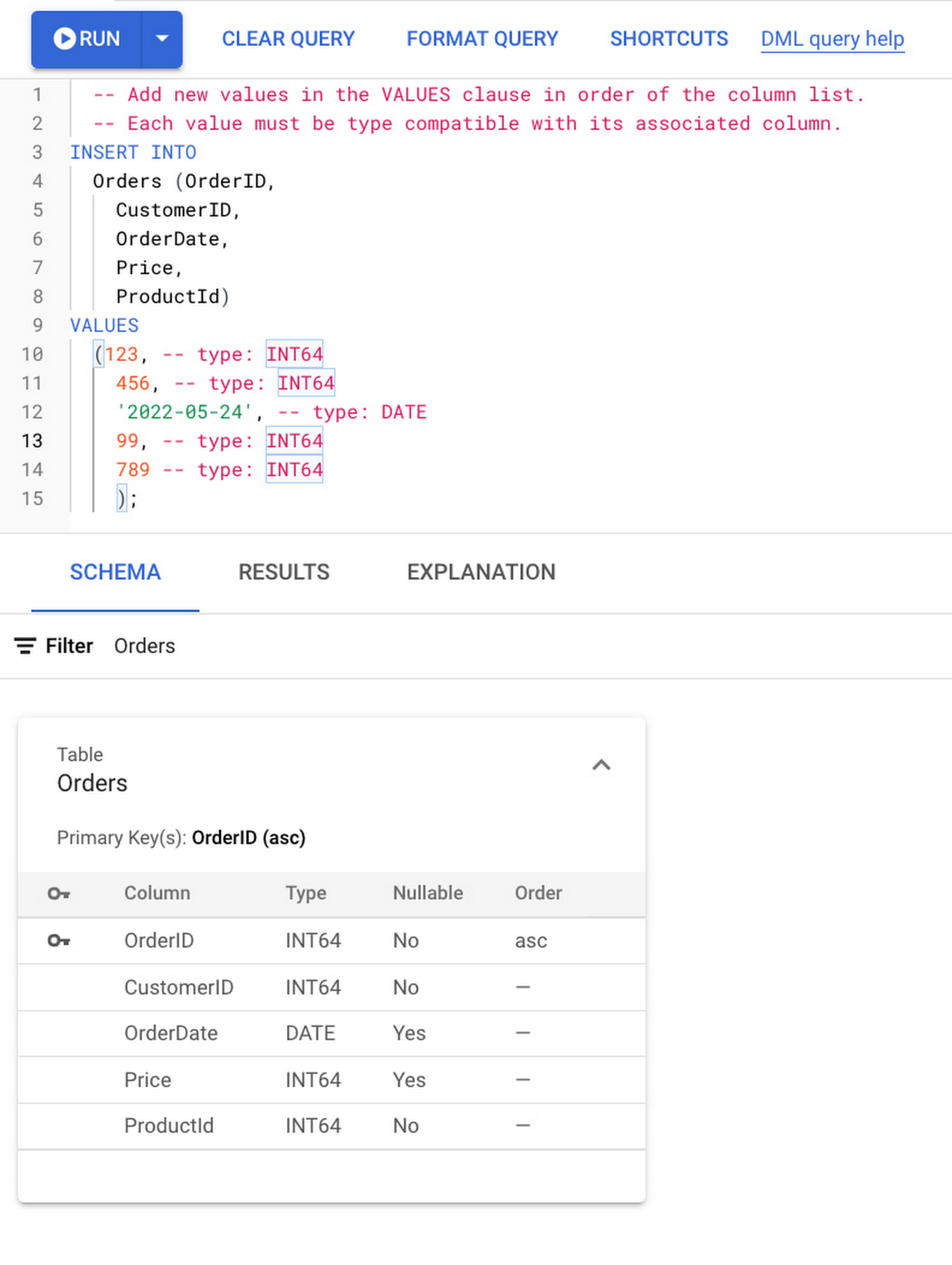
Suppose you have a table Orders like this:
code_block[StructValue([(u’code’, u’CREATE TABLE Orders (rn OrderID INT64 NOT NULL,rn CustomerID INT64 NOT NULL,rn ProductId INT64 NOT NULL,rn OrderDate DATE,rn Price INT64,rn) PRIMARY KEY(OrderID);’), (u’language’, u”)])]
The DDL to create a change stream that tracks the entire Orders table with a (implicit) default retention of 1 day would be defined as:
code_block[StructValue([(u’code’, u’CREATE CHANGE STREAM OrdersStream FOR Orders;’), (u’language’, u”)])]
Creating change streams is a long running operation. You can check the progress on the change streams page in the Cloud console:
Once created, you can click on the change stream name to view more details:
Your database DDL should look something like:
Now that the change stream has been created, you can process the change stream data.
Streaming data to BigQuery
There are several ways to process change stream data. The easiest way is to use the Spanner connector for Apache Beam which allows you to build scalable data processing pipelines for Google Cloud Dataflow. We provide Dataflow templates for processing and writing change data to BigQuery or Google Cloud Storage respectively. Learn more about how Cloud Spanner change streams work with Dataflow.
First, navigate to your project’s Dataflow Jobs page in the Google Cloud Console. Click on CREATE JOB FROM TEMPLATE, choose the Change streams to BigQuery template, then fill in the required fields:
Click RUN JOB, and wait for Dataflow to build the pipeline and launch the job. Once your Dataflow pipeline is running, you can view the job graph, execution details, and metrics on the Dataflow Jobs page:
Now let’s write some data into the tracked table Orders:
Under the hood, when Spanner detects a data change in a data set tracked by a change stream, it writes a data change record synchronously with that data change, within the same transaction. Spanner co-locates both of these writes so they are processed by the same server, minimizing write processing. Learn more about how Spanner writes and stores change streams.
Finally, when you view your BigQuery dataset, you will see the row that you just inserted, with some additional information from the change stream records.
You are all set! As long as your Dataflow pipeline is running, the data changes to the tracked tables will be seamlessly streamed to your BigQuery dataset. Learn more about monitoring your pipeline.
More ways to process change stream data
Instead of using the Google-provided Dataflow templates for BigQuery and Google Cloud Storage, you can choose to build a custom Dataflow pipeline to process change data with Apache Beam. For this case, we provide the SpannerIO Dataflow connector that outputs change data as an Apache Beam PCollection of DataChangeRecord objects. This is a great choice if you want to define your own data transforms, or want a different sink than BigQuery or Google Cloud Storage. Learn more about how to create custom Dataflow pipelines that consume and forward change stream data.
Alternatively, you can process change streams with the Spanner API. This approach, which is particularly well-suited for more latency-sensitive applications, does not rely on Dataflow. The Spanner API is a powerful interface that lets you read directly from a change stream to implement your own connector and stream changes to the pipeline of your choice. With the Spanner API, a change stream is divided into multiple partitions, each of which can be used to query a change stream in parallel for higher throughput. Spanner dynamically creates these partitions based on load and size. Each partition is associated with a Spanner database split, allowing change streams to scale as effortlessly as the rest of Spanner. Learn more about using the change stream query API.
What’s next
Spanner change streams is available to all customers today at no additional cost – you’ll pay only for any extra compute and storage of the change stream data at the regular Spanner rates. Since change streams are built right into Spanner, there’s no software to install, and you get external consistency, industry-leading availability, and effortless scale with the rest of the database.
One of the most stunning facts revealed by the new coronavirus pandemic (COVID-19) has been our acceptance of polluted air. Skies in the world’s largest cities turned a color that astonished many residents when personal vehicle miles plummeted dramatically. At the same time, scientists discovered that poor air quality might raise coronavirus susceptibility.
Big data technology has helped us make these findings. It will also help develop solutions.
These findings underscore how years of awareness-raising about the dangers of climate change have turned into action to protect public health. It also reveals how little we still understand about how our air quality affects our health. In the wake of the pandemic, it is more important than ever to invest in research to improve our understanding of the link between air quality and health so that we can take steps to protect ourselves from future pandemics.
Now that some parts of the world are starting to look like they did before the lockdown, people are talking about trying to keep this improvement in air quality. Lots of people want better air quality, so cities might need better data on air quality to make new decisions about policy.
Fortunately, the past five years have seen significant progress in air quality monitoring for smart cities. Big data is going to make or break smart cities and it can help solve environmental challenges they face. Smart cities should follow the guidelines outlined below when capturing air quality data:
1. Increase data resolution
In order to improve air quality, cities need to have better data resolution. This means that cities need to measure the air quality at many different locations instead of just a few. This is important because the concentrations of pollutants can vary a lot from one place to another in a city.
For years, the only way to measure air quality was to take samples of the air and send them to a laboratory for analysis. However, this process was slow and expensive. In recent years, sensors that can measure air quality in real-time have been developed. These sensors are typically small and portable, making them easy to use in a variety of settings. In addition, they are relatively inexpensive, making them a valuable tool for monitoring air quality.
While many cities rely on physically deployed sensors to collect data, there are other options available that come with their own advantages and disadvantages. One option is mobile surveying, which can provide a much larger albeit less complete profile over time. These surveys usually involve the use of car-mounted sensors, but some cities are breaking the trend by using municipal trucks, drones, and bike-share bikes for mobile surveying.
As cities wrestle with the problem of air pollution, some are looking to cutting-edge technology for help. Air quality sensors are becoming increasingly commonplace, providing valuable data on local conditions. However, these sensors can only cover a limited area, leaving gaps in the data. Environmental data companies are now using fluid dynamics models to fill in these gaps and predict air quality for any point. This method is still in its infancy, and there are concerns about its accuracy. However, it is an inexpensive option that could be used in conjunction with other methods to improve air quality data.
2. Measure ROI of air quality sensors
Air quality monitoring is an important tool for cities to protect public health, but the question of how to pay for it can be difficult to answer. There are many different air quality measurement technologies available, and each has its own benefits and drawbacks. Some technologies are more expensive than others, but they may also be more accurate or provide more data. Ultimately, the decision of which technology to use depends on the specific needs of the city and the availability of funding. Here isa good guide on how to measure air quality.
There are many options for financing air quality monitoring projects, including grants, loans, and private investment. The best option for any given city will depend on the available resources and the level of need. Whatever the method of financing, it is important that cities invest in air quality monitoring to protect public health and improve air quality.
ROI can be measured in different ways. One way is to look at the economic benefits that come from people not getting sick as often. This includes things like less time spent at the doctor or hospital, and less money spent on medicine. Another way to measure ROI is to look at how much air pollution costs our economy every year. Air pollution cost the US economy around $900 billion in 2019, equivalent to 5% of GDP.
Reducing air pollution could therefore have a significant positive impact on a city’s economy. In addition, improving air quality would also lead to better health outcomes for residents, which would also reduce healthcare costs. As cities continue to grapple with the effects of air pollution, it is important to consider both the human and economic costs of this public health crisis.
3. Explore new ways to put data to good use
Data from air quality sensors can be used in a number of innovative ways. For example, the city of Leeds in the U.K. has equipped its fleet of hybrid vehicles with quality sensing and geofencing technology. This allows the vehicles to automatically switch to electric-only mode when they enter areas with poor air quality. As a result, the city’s fleet of hybrid vehicles is able to significantly reduce emissions in areas where air pollution is a problem.
Similarly, cities can use data from their air quality sensor network to map hot spots of fine particulate matter. They can then work with residents in these areas to identify sources of the pollution and develop strategies for reducing emissions. By finding innovative uses for data from air quality sensors, cities can take steps to improve air quality and protect public health.
Big data technology is changing our lives in countless ways. Due to the many benefits that data provides, more companies are investing in it. Global companies are expected to spend over $234 billion by 2026. This is a great opportunity for companies that develop big data applications for customers and businesses alike.
If you are interested in creating a successful big data application, then you could have a very profitable business model on your hands. However, profitable big data companies are not born. They require a lot of planning and hard work. You have to have the right elements of success before you launch your company.
As you know by now, running a company is no easy feat. Creating a successful big data company can be even harder, since there is so much competition and the barriers to entry are so high.
You need to have the right mindset, the right tools, and most importantly, the right team. To make it through the day, you’ll need to focus on tasks and not worry about your company’s goals. You also need an impeccable understanding of big data.
In this article, you will learn about four areas of running a company that you can master.
1. Mission Statement
A mission statement is something that every business needs because it gives your company a purpose and direction. If you are selling a data analytics platform for financial traders, you need to have a mission statement that will help your company figure out what it is trying to accomplish.
Your mission statement also helps employees understand how they can contribute to your company’s success. If working hard and being diligent is one of the core values in your company, an employee who works hard but not diligently may feel like they are not contributing enough to the success of the company.
As a big data startup, you should emphasize the importance of technological development. Your company needs to make technological competence a core part of its mission statement, since your brand won’t be able to survive without it. You should emphasize how you will use big data to stand out, since this is crucial for modern companies.
2. Business Brand
Your brand is the image that your business has created for itself. This can also include the logo, advertising campaigns, and other marketing material. A good way to create a good brand would be to have an employee who is creative create a logo and make it available to all employees so that they can use it in their official business cards and other company materials.
When you are creating a brand for a big data startup, you have to make sure it emphasizes the technological competence of your team. Customers won’t trust a technology startup that doesn’t demonstrate the importance of big data.
You can also learn how to design a logo and create what you love most, and something that clients can resonate with.
3. Core Values
Big data technology is constantly changing, so your business will always have to adapt to these changes. However, your company’s core values will remain the same, regardless of trends in the big data sector.
Core values are important for every company as they set the standard for your employees and customers. These core values should not just be written on a piece of paper. They should be ingrained into every employee and customer’s mind so that they can become part of your company’s culture.
For example, if honesty is one of your company’s core values, every employee and customer should know that they can trust you with their money or their life savings because they know that you are honest with them at all times. Additionally, core values help employees understand what is expected of them at work and outside work.
4. Culture
You might rely heavily on automation to run a big data startup. However, the employees running your company are still humans. They will create a company culture that will affect the future of your business.
Company culture is the set of values that your business and your employees live by their beliefs and morals. It can be tough to create a good culture because every business is different, and every employee is different.
However, if you want to ensure that your employees are happy where they are working, you need to know how they feel about certain things in the company so that you can create a good culture. It also contributes to a good working environment.
Do Your Due Diligence When Creating a Data-Driven Business
Running a data-driven business doesn’t have to be a daunting experience. You only have to take all of the information you have gathered during this process and put it to good use.
You should be able to create a plan for your business, brainstorm ideas for new products, and set up your finances to make your business successful. Hopefully, this article has helped you get started on the right foot.
The typical smart factory is said to produce around 5 petabytes of data per week. That’s equivalent to 5 million gigabytes, or roughly 20,000 smartphones.
Managing such vast amounts of data in one facility, let alone a global organization, would be challenging enough. Doing so on the factory floor, in near-real-time, to drive insights, enhancements, and particularly safety, is a big dream for leading manufacturers. And for many, it’s becoming a reality, thanks to the possibilities unlocked with edge computing.
Edge computing brings computation, connectivity, and data closer to where the information is generated, enabling better data control, faster insights, and actions. Taking advantage of edge computing requires the hardware and software to collect, process, and analyze data locally to enable better decisions and improve operations.
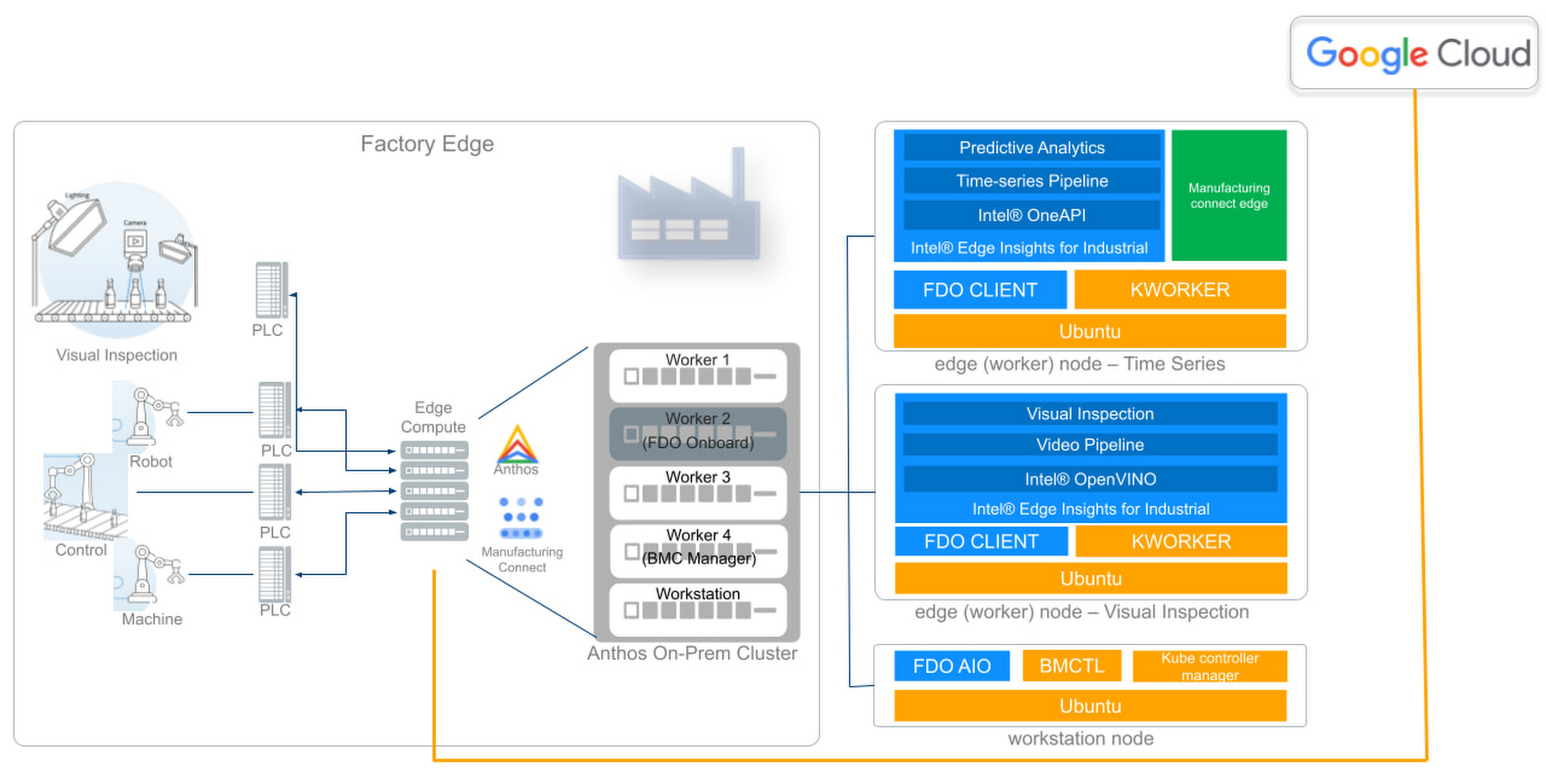
At Hannover Messe 2022, Intel and Google Cloud will demonstrate a new technology implementation that combines the latest generation of Intel processors with Google Cloud’s data and AI expertise to optimize production operations from edge to cloud. This proof-of-concept project is powered by the Edge Insights for Industrial platform (EII), an industry-specific platform from Intel; and a pair of Google Cloud solutions: Anthos, Google Cloud’s managed applications platform, and the newly-launched Manufacturing Data Engine.
Edge computing exploits the untapped gold mine of data sitting on-site and is expected to grow rapidly. The Linux Foundation’s “2021 State of the Edge” predicts that by 2025, edge-related devices will produce roughly 90 zettabytes of data. Edge computing can help provide greater data privacy and security, and can accomodate the reduced bandwidth needs between local storage and the cloud.
Imagine a world in which the power of big data and AI-driven data analytics is available at the point where the data is gathered to inform, make, and implement decisions in near real-time.
This could be anywhere on the factory floor, from a welding station to a painting operation or more. Data would be collected by monitoring robotic welders, for example, and analyzed by industrial PCs (IPCs) located at the factory edge. These edge IPCs would detect when the welders are starting to go off spec, predicting increased defect rates even before they appear, and adding preventive maintenance to correct the errors without any direct intervention. Real time, predictive analytics using AI could substantially prevent defects before they happen. Or the same IPCs could use digital cameras for visual inspection to monitor and identify defects in real-time, allowing them to be addressed quickly.
Edge computing has powerful potential applications in assisting with data gathering, processing, storage and analysis in many manufacturing sectors, including automotive, semiconductor and electronics manufacturing, and consumer packaged goods. Whether modeling and analysis is done and stored locally or in the cloud, or is predictive, simultaneous, or lagged, technology providers are aligning to meet these needs. This is the new world of edge computing.
The joint Intel and Google Cloud proof of concept aims to extend the Google Cloud capabilities and solutions to the edge. Intel’s full breadth of industrial solutions, hardware and software, are coming together in this edge-ready solution, encompassing Google Cloud industry-leading tools. The concept shortens the time to insights, streamlining data analytics and AI at the edge.
Intel’s Edge Insight for Industrial and FIDO Device Onboarding (FDO) at the edge running Google Anthos on Intel® NUCs.
The Intel-Google Cloud proof of concept demonstrates how manufacturers can gather and analyze data from over 250 factory devices using Manufacturing Connect from Google Cloud, providing a powerful platform to run data ingestion and AI analytics at the edge.
In this demonstration in Hannover, Intel and Google Cloud show how manufacturers can capture time-series data from robotic welders to inspect welding quality and show how predictive analytics can benefit the factory operators. In addition, the video and image data is captured from a factory camera to show how visual inspection can highlight anomalies on plastic chips with model scoring. The demo also features zero-touch device onboarding using FIDO Device Onboard (FDO) to illustrate the ease with which additional computers could be added to the existing Anthos cluster.
By combining Google Cloud’s expertise in data, AI/ML and Intel’s Edge Insight’s for Industrial platform that was optimized to run on Google Anthos, manufacturers can run and manage their containerized applications at the edge, in on-premise data center, or in public clouds using an efficient and secure connection to the Manufacturing Data Engine from Google Cloud. It forges a complete edge-to-cloud solution.
Simplified device onboarding is available using Fido Device Onboard (FDO)—an open IoT protocol that brings fast, secure, and scalable zero-touch onboarding of new IoT devices to the edge. FDO allows factories to easily deploy automation and intelligence in their environment without introducing complexity into their OT infrastructure.
The Intel-Google Cloud implementation can analyze that data using localized Intel or third-party AI and machine learning algorithms. Applications can be layered on the Intel hardware and Anthos ecosystem, allowing customized data monitoring and ingestion, data management and storage, modeling, and analytics. This joint PoC facilitates and support improved decision making and operations, whether automated or triggered by the engineers on the front lines.
Intel collaborates with a vibrant ecosystem of leading hardware partners to develop solutions for the industrial market by using the latest generation of Intel processors. These processors can run data intensive workloads at the edge with ease.
Intel Industrial PC Ecosystem Partners
Putting data and AI directly into the hands of manufacturing engineers can improve quality inspection loops, customer satisfaction, and ultimately the bottom line.
The new manufacturing solutions will be demonstrated in person for the first time at Hannover Messe 2022, May 30–June 2, 2022. Visit us at Stand E68, Hall 004, or schedule a meeting for an onsite demonstration with our experts.
Blockchain is one of the most disruptive technologies of the 21st Century. A growing number of industries are using blockchain to operate more efficiently or boost security.
However, blockchain is still most important in the realm of cryptocurrencies. Bitcoin has become very popular since its inception in 2008 and that is largely due to the power of blockchain. Blockchain has made investing in bitcoin much more secure than ever.
Are you interested in buying bitcoin? You need to understand the general process and the role that blockchain plays in it.
How Does Blockchain Fit into the Process of Buying Bitcoin?
It may seem a complicated task to invest in bitcoin. However, it can be easier with the proper knowledge and breaking it down into steps. You will need to understand the general process, as well as the role that blockchain plays in it.
If you want to trade or invest in bitcoin, you need to have a cryptocurrency service account, secure internet connection, method of payment, and personal identification documents. Initially, things may seem confusing to you, but you will surely not regret buying the bitcoin.
You also need a personal wallet outside in addition to your account with a bitcoin exchange if you want to buy bitcoins. The valid payment methods for the process include credit cards, debit cards, and bank accounts. Also, you can buy bitcoin through P2P exchanges and specialized ATMs that connect directly to the blockchain.
Security and privacy are important factors that you need to consider before buying a bitcoin. You need to get private keys to a public address as it will enable you to authorize transactions on the bitcoin blockchain. The blockchain has made trading bitcoin extremely secure, but you still need to protect your digital coins by securing your wallet and account.
Keeping private keys secret is a must as criminals and scammers can attempt to steal them. You have to be careful while using the balance of a public address. Without further ado, let’s explore how you can buy bitcoin over the blockchain.
1. Choose Crypto Trading Service
Initially, you have to choose a crypto trading venue or service. Some of the well-known trading services that you can choose to buy BTC include payment services, brokerages, and cryptocurrency exchanges. You need to make sure that these are legitimate services that actually connect to the blockchain. Out of all these options, you should go for cryptocurrency exchanges as it has a wide range of features that ensures a great level of convenience.
By signing up for a cryptocurrency exchange, you can sell, buy, and hold cryptocurrency. Usually, bitcoin buyers prefer this option because it allows them to withdraw crypto from their personal wallets safely. As long as it is a service that legitimately connects to the blockchain, the transactions themselves will be highly secure. However, it is still important to make sure that the bitcoins stored on the exchanges will be secured as well.
There are different types of cryptocurrency exchanges. Some exchanges allow users to not provide personal information while some need it. The exchanges that enable users to stay anonymous are decentralized and operate autonomously. It means they do not have any central point of control. Such systems can serve the unbanked population of the world. Refugees or people living with no banking structure can use anonymous exchanges that can help them enter the mainstream economy. The blockchain has given them the opportunity to use a much more efficient currency.
2. Connect your Exchange to Payment Method
Once you have chosen the exchange, you need to connect the exchange to the payment option. You need to ensure that you have all the required documents to do that. It includes a driving license picture or social security card that depends on the type of exchange that you choose. You may also have to provide information about your employer and source of income. The exact process depends on your region where you live and the laws that apply there. The procedure is almost the same as setting up a brokerage account.
Once the exchange verifies your identity, you can connect to the payment option and will be ready to start placing transactions over the blockchain. You can directly connect to your bank account, debit, or credit card in most exchanges. Although, it is not a good idea to buy bitcoin through a credit card because price volatility can inflate the overall purchasing coin cost. Bank can also ask you some questions, so you have to be prepared. You should check in advance to ensure that your bank allows deposits at the exchange you have chosen. The deposit fees of banks through debit, bank account, and credit cards can vary.
3. Place the Order
After choosing the exchange and connection payment option, you are all set to buy bitcoin. In the recent past, cryptocurrency exchanges have become mainstream as they have grown massively in terms of features and liquidity. The cryptocurrency exchanges have reached a point where they have the same features as stock brokerage. The blockchain is so efficient at processing these transactions that bitcoins can be purchased nearly instantaneously.
Crypto exchanges offer many order types and methods to invest. Apart from different types of orders, exchanges also allow clients to set up recurring investments. For example, Coinbase enables users to set recurring purchases on a daily, weekly, and monthly basis.
4. Safe Storage
The blockchain has made the process of buying, selling and transferring bitcoins very secure. However, there are security issues that it can’t address, because it only plays a role during the transfer process. Namely, the blockchain can’t protect coins in your wallet. You have to have a secure storage option.
Bitcoin wallets allow you to keep your digital assets secure. If you have cryptocurrency outside of the exchange, then your personal wallet ensures that only you have access to the private key to control your funds. It also enables you to store funds from the exchange and also mitigates the risk of getting your exchange hacked. In this way, it ensures security, so you do not lose your funds.
Most of the exchanges offer wallets for their users, but security is not their major preference. You should not use such type of exchanges wallet that does not guarantee security. Some wallets have more storage features as compared to others, so you should take a look at each of them. You can consider choosing from different types of bitcoin wallets. The hot wallets are known as online wallets, while cold wallets are known as hardware or paper wallets.
You can access hot wallets on internet-connected devices, including phones, tablets, and computers. It can cause vulnerability because these wallets produce the private keys to your coins on devices that you use. Although using a hot wallet is a convenient option that allows you to make transactions efficiently and quickly with your assets.
Also, it allows you to store your private key on internet-connected devices. On the other hand, cold wallets are not connected to the internet, so there is less risk involved in it. You may consider these wallets as hardware or offline wallets. These wallets store your private keys on anything which is not connected to the internet.
According to experts, cold wallets are a more secure option for storing bitcoin or any other cryptocurrencies. You can generate these wallets by using certain websites that provide you with private and public keys.
The Blockchain Plays a Crucial Role in the Process of Buying and Selling Bitcoins
The blockchain has a very important role in the process of buying bitcoin. Trading and buying bitcoin has become one of the major trends that have completely transformed many people’s lives, due to the benefits the blockchain has provided. It provides you with a great opportunity to attain financial freedom and change your lifestyle. But you need to have complete awareness before buying the bitcoin to avoid any risks of losing the funds.
Getting professional assistance from bitcoin or crypto experts can make the bitcoin buying process easier for you. It will also help you know about the different aspects that can be beneficial for you in the long term.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}