
Fresh updates: Google Cloud 2021 Summits

There are a lot of great things happening at Google Cloud, and we’re delighted to share new product announcements, customer perspectives, interactive demos, and more through our Google Cloud Summit series, a collection of digital events taking place over the coming months.
Join us to learn more about how Google Cloud is transforming businesses in various industries, including Manufacturing & Supply Chain, Retail & Consumer Goods, and Financial Services. We’ll also be highlighting the latest innovations in data, artificial intelligence (AI) and machine learning (ML), security and more.
Content will be available for on-demand viewing immediately following the live broadcast of each event. Bookmark this page to easily find updates as news develops, and don’t forget to register today or watch summits on demand by visiting the Summit series website.
Upcoming events
Government & Education Summit | Nov 3-4, 2021
Mark your calendars – registration is open for Google Cloud’s Government and Education Summit, November 3–4, 2021.
Government and education leaders have seen their vision become reality faster than they ever thought possible. Public sector leaders embraced a spirit of openness and created avenues to digital transformation, accepting bold ideas and uncovering new methods to provide public services, deliver education and achieve groundbreaking research. At Google Cloud, we partnered with public sector leaders to deliver an agile and open architecture, smart analytics to make data more accessible, and productivity tools to support remote work and the hybrid workforce.
The pandemic has served as a catalyst for new ideas and creative solutions to long-standing global issues, including climate change, public health, and resource assistance. We’ve seen all levels of government and education leverage cloud technology to meet these challenges with a fervor and determination not seen since the industrial revolution. We can’t wait to bring those stories to you at the 2021 Google Cloud Government and Education Summit.
The event will open doors to digital transformation with live Q&As, problem-solving workshops and leadership sessions, designed to bring forward the strongest talent, the most inclusive teams, and the boldest ideas. Interactive, digital experiences and sessions that align with your schedule and interests will be available, including dedicated sessions and programming for our global audiences.
Register today for the 2021 Google Cloud Government and Education Summit. Moving into the next period of modernization, we feel equipped with not just the technology, but also the confidence to innovate and the experience to deliver the next wave of critical digital transformation solutions.
Digital Manufacturer Summit | June 22, 2021
Together we can transform the future of our industry. At Google Cloud’s Digital Manufacturer Summit customers will hear from Porsche, Renault Group, Doosan Heavy Industries & Construction, GE Appliances and Landis+Gyr who are boosting productivity across their enterprise with digital solutions powered by AI and analytics.
Google Cloud recently launched a report and blog on AI Acceleration, which reveals that the COVID-19 pandemic may have spurred a significant increase in the use of AI and other digital enablers among manufacturers. We will continue this thought leadership in the summit.
Hear from forward-thinking business executives as they discuss the latest trends and the future of the industry. Participate in focused sessions and gain game-changing insights that dive deep into customer experience, product development, manufacturing operations, and supply chain operations.
APAC Technical Series | June 22 – 24, 2021
IT and business professionals located in the Asia Pacific region can continue their cloud technology learnings by taking part in a three-day deep-dive into the latest data and machine learning technologies. This event will help you harness data and unlock innovation to build, iterate, and scale faster and with confidence.
Register now: APAC
Security Summit | July 20, 2021
At Google Cloud Security Summit, security professionals can learn why many of the world’s leading companies trust Google Cloud infrastructure, and how organizations can leverage Google’s cloud-native technology to keep their organization secure in the cloud, on-premises, or in hybrid environments.
During the opening keynote, engaging sessions, and live Q&A, customers will learn about how our Trusted Cloud can help them build a zero-trust architecture, implement shared-fate risk management, and achieve digital sovereignty. Join us to hear from some of the most passionate voices exploring how to make every day safer with Google. Together, we’ll reimagine how security should work in the cloud.
Retail & Consumer Goods Summit | July 27, 2021
Are you ready for the continued growth in digital shopping? Do you understand how leveraging AI and ML can improve your business? Join your peers and thought leaders for engaging keynotes and breakout sessions designed for the Retail and CPG industries at our upcoming Retail and Consumer Goods Summit on July 27th.
You’ll learn how some of the world’s leading retail and consumer goods companies like Ulta, Crate & Barrel, Albertsons, IKEA, and L’Oreal are using Google Cloud AI, machine learning, and data analytics technology to accelerate their digital transformation. In addition, we’ll share announcements on new products and solutions to help retailers and brands succeed in today’s landscape.
Register now: Global
Now available on demand
Data Cloud Summit | May 26, 2021
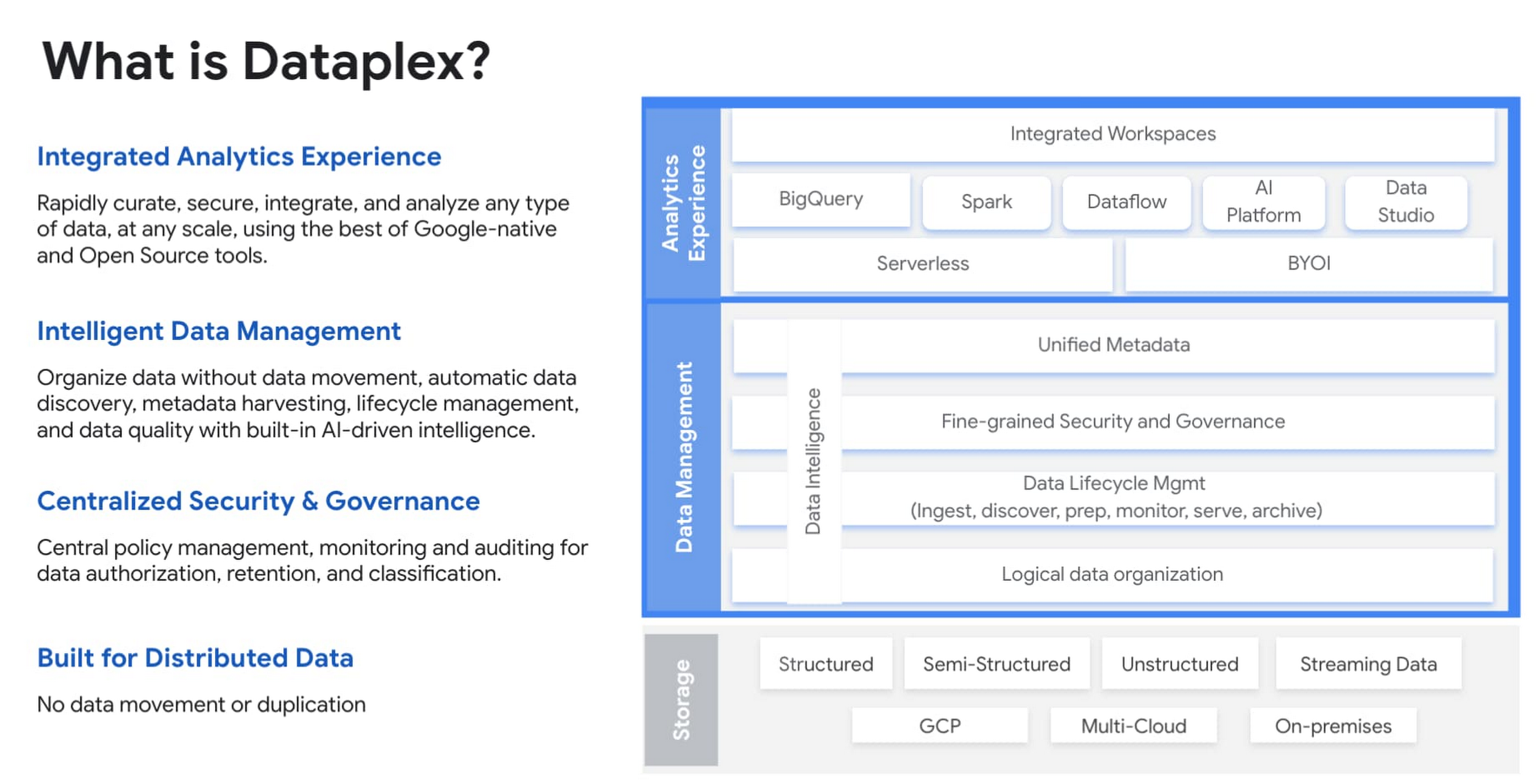
In case you missed it, check out content from the Google Data Cloud Summit, which featured the launch of three new solutions – Dataplex, Analytics Hub and Datastream – to provide organizations with a unified data platform. The summit also featured a number of engaging discussions with customers including Zebra Technologies, Deutsche Bank, Paypal, Wayfair and more.
Watch on-demand now: Global
Financial Services Summit | May 27, 2021
We launched Datashare at the Financial Services Summit; this solution is designed to help capital markets firms share market data more securely and efficiently. Attendees can also view sessions on a range of topics including sustainability, the future of home buying, embedded finance, dynamic pricing for insurance, managing transaction surges in payments, the market data revolution, and more. Customers such as Deutsche Bank, BNY Mellon, HSBC, Credit Suisse, PayPal, Global Payments, Roostify, AXA, Santander, and Mr Cooper shared their insights as well.
Watch on-demand now: NORTHAM & EMEA
We have also recently launched several new blog posts tied to the Financial Services Summit:
Google Cloud for financial services: driving your transformation cloud journey
How insurers can use severe storm data for dynamic pricing
Why embedding financial services into digital experiences can generate new revenue
Applied ML Summit | June 10, 2021
The Google Applied ML Summit featured a range of sessions to help data scientists and ML engineers explore the power of Google’s Vertex AI platform, and learn how to accelerate experimentation and production of ML models. Besides prominent Google AI/ML experts and speakers, the event also featured over 16 ML leaders from customers and partners like Spotify, Uber, Mr. Cooper, Sabre, PyTorch, L’Oreal, Vodafone and WPP/Essence.
Watch on-demand now: Global
Source : Data Analytics Read More







{kind=link}
{kind=link}
{kind=link}